




引言
随着人工智能技术的飞速发展,AI 绘画工具逐渐走进了大众视野,成为创意工作者和爱好者的新宠。其中,Stable Diffusion 作为一款免费、开源的 AI 图像生成器,因其高效、易用的特点而备受关注。它不仅为艺术家们提供了新的创作手段,也为普通用户带来了前所未有的图像生成体验。本文将全面介绍 Stable Diffusion 的基本概念、发展历程以及核心技术原理,帮助读者深入了解这一强大的工具,并探索其在实际应用中的无限可能。

(一)基本定义与发展历程
Stable Diffusion 是一款免费、开源的 AI 图像生成器,它在 AI 绘画领域引发了广泛关注。这款工具由 Stability AI、CompVis 和 Runway 等团队合作开发,于 2022 年 8 月正式推出。
背景与起源
Stable Diffusion 的诞生源于当时对更高效、更易应用的 AI 模型的需求。最初的 Latent Diffusion 模型由慕尼黑大学的机器学习研究小组 CompVis 和纽约的 Runway 团队共同研发。该模型具备生成速度快、计算资源消耗低的优势,但训练成本较高。Stability AI 提供了资源支持,加入到后续的研发中,推动了 Stable Diffusion 的诞生。
发展历程
- 2022 年 7 月底:经过训练的 Stable Diffusion 模型首次亮相,相较于 Latent Diffusion,它采用了更多数据训练,图像尺寸更大,并使用了更好的 CLIP 编码器,使得生成模型更加准确。
- 2022 年 8 月 22 日:Stable Diffusion 正式开源,迅速吸引了大量开发者和用户,帮助 Stability AI 获得了 1 亿美元融资,估值约 10 亿美元。
- 2022 年:推出了 Stable Diffusion 2.0 版本,新算法更高效,图像生成质量显著提升,默认支持 512x512 和 768x768 像素分辨率的图像,还包含了 Upscaler Diffusion 和 depth2img 深度图像扩散模型。
- 2024 年:发布了 Stable Diffusion 3.5 版本,包含 Large、Large Turbo 和即将推出的 Medium 版本,以满足不同用户需求。其中,Stable Diffusion 3.5 Large 拥有 80 亿个参数,适用于专业应用场景。
(二)核心技术基础
Stable Diffusion 基于潜在扩散模型(Latent Diffusion Model),该模型是在传统扩散模型基础上发展而来的高级模型。传统扩散模型在像素空间中进行运算,需要处理大量高维数据,对硬件要求极高。而潜在扩散模型通过将图像缩小 48 倍进行运算,再恢复到原始尺寸,大幅减少了数据量,提高了运算速度,降低了硬件要求。

Stable Diffusion 通过三个核心组件实现用文本来控制生成图像:
- 自动编码器(VAE):用于将高维数据映射到低维空间,压缩和降维。
- U-Net 神经网络:辅助提取并解构训练图像的特征,提升生成图像的精确性。
- 文本编码器(ClipText):解析提示词,建立文本与图像之间的对应关系。
二、技术原理详解
(一)核心组件功能

1. 自动编码器(VAE)
自动编码器(Variational Autoencoder, VAE) 是一种无监督学习模型,广泛应用于数据压缩和生成任务中。其主要作用是将高维数据(如图像中的像素信息)映射到低维的潜在空间(Latent Space)。VAE 由编码器(Encoder)和解码器(Decoder)两部分构成:

- 编码器:将输入图像转换为潜在空间中的表示形式,捕捉图像的关键特征。编码器通过多层神经网络逐步提取图像的高层次抽象特征,最终输出一个低维向量。
- 解码器:将潜在空间中的低维向量重新转换回原始图像。解码器的作用类似于图像的 “还原器”,能够基于经过处理和运算后的潜在数据,重建出原始图像,并且在实际应用中还能修饰最终图像的色彩和质感,类似于给图像添加调色滤镜。
具体工作流程:
- 训练阶段:编码器将输入图像转换为潜在空间中的表示形式,解码器则尝试从这些表示形式中重建原始图像。通过最小化重构误差(如均方误差),使模型学会如何有效地压缩和解压图像。
- 推理阶段:在生成新图像时,解码器接收来自潜在空间的随机向量或特定向量,根据这些向量生成新的图像。
优点:
- 数据压缩:有效减少数据维度,降低存储和传输成本。
- 图像生成:可以用于生成逼真的图像,广泛应用于图像合成、修复等领域。
2. U-Net 神经网络
U-Net 是一种卷积神经网络架构,最初设计用于生物医学图像分割任务。它的结构呈 U 形,具有对称的编码器 - 解码器结构,中间通过跳跃连接(skip connections)传递特征图。这种设计使得 U-Net 能够保留丰富的上下文信息,在图像相关任务中表现出色。
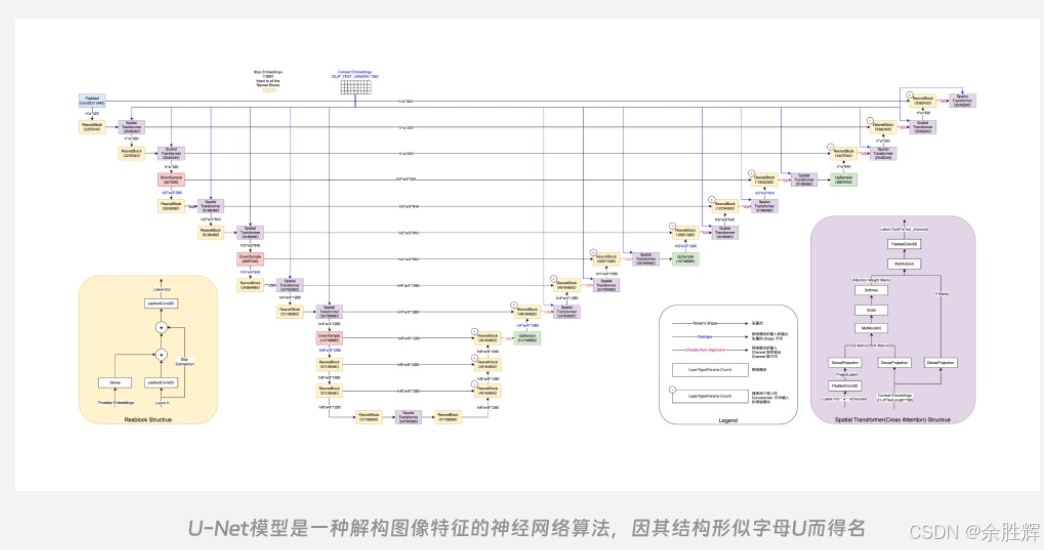
具体工作流程:
- 编码器阶段:通过多个卷积层逐步提取图像的高层次特征,同时下采样(downsampling)图像以减少空间维度。
- 跳跃连接:在每一层编码器中保存的特征图会被传递到相应的解码器层,确保在解码过程中保留更多的细节信息。
- 解码器阶段:通过上采样(upsampling)逐步恢复图像的空间维度,结合跳跃连接传递的特征图,生成高质量的输出图像。
在 Stable Diffusion 中的应用:
- 特征提取:U-Net 对训练图像进行特征提取和解构,即便在训练样本较少的情况下也能帮助模型获得准确多样的数据信息,提升最终出图结果的精确性。
- 噪声去除:在逆向降噪过程中,U-Net 分析当前噪声图像,预测每一步需要去除的噪声成分,逐步恢复出清晰的图像。
- 交叉注意力机制:U-Net 结合文本编码器提供的文本信息,通过 Cross Attention 操作将图像信息和文本信息融合,整体遵循 Transformer 流程,使得生成的图像更符合用户输入的提示词内容。
优点:
- 细节保留:通过跳跃连接,能够在不同层次的图像处理中保留丰富的细节信息。
- 灵活性:适用于多种图像处理任务,如图像生成、分割、修复等。
3. 文本编码器(ClipText)
文本编码器(ClipText) 是基于 OpenAI 开发的 Clip 模型的一部分,用于解析提示词并建立文本与图像之间的对应关系。Clip 模型包括文本编码和图像编码两个部分,通过搜集大量网络上的图像和文字信息进行训练,从而建立起文本和图像之间的关联。

具体工作流程:
- 文本解析:文本编码器首先对用户输入的提示词进行分词处理,将句子中的词语或短语转换为一个个 token(标记),然后针对这些 token 进行编码操作,生成相应的特征向量。
- 特征传递:这些特征向量承载着文本提示词中的关键语义、风格、主体等信息,随后被传递给图像生成器,使得模型能够依据这些文本特征生成与之匹配的图像。
- 图像生成引导:例如,当用户输入描述性的提示词时,文本编码器能提取出场景(如海边)、元素(如晚霞)、风格(如绚丽)等关键特征,并转化为对应的向量传递给后续组件,引导模型生成符合描述的图像。
在 Stable Diffusion 中的应用:
- 文本控制:通过文本编码器,用户可以通过输入自然语言描述来精准控制生成图像的内容和风格。
- 多模态融合:文本编码器与 U-Net 等组件协同工作,实现了多模态数据(文本 + 图像)的融合,提升了生成图像的质量和多样性。
(二)扩散模型工作流程
1. 前向扩散过程
前向扩散过程是扩散模型运作的起始阶段,其核心在于向训练图像不断添加噪声,直至图像变为纯噪声图。这一过程可以形象地类比为在干净的水中滴入一滴墨汁,墨汁会逐渐扩散,使得原本清澈的水变得浑浊,直至整个水体都被均匀染黑,再也分辨不出原来的状态。
具体工作流程:
- 噪声添加:从初始图像开始,逐步添加噪声,每次迭代都会引入一定比例的新噪声,使得图像逐渐失去原有的特征和结构。
- 路径记录:模型记录每一次添加噪声后图像的状态变化及相应参数设置,构建了一个从原始图像到纯噪声图像的变化路径数据库。
- 学习噪声模式:通过多次训练,模型能够学习到图像在不同噪声程度下的变化情况,为后续的逆向降噪过程提供参考依据。
意义:
- 数据增强:通过前向扩散过程,模型可以在不同的噪声水平下学习图像的特征,增强了模型的泛化能力。
- 逆向降噪准备:为后续的逆向降噪过程提供了必要的数据基础,使得模型能够依据噪声情况推测出原始图像的模样。
2. 逆向降噪过程
逆向降噪过程是从已经变成纯噪声的图像开始,逐步恢复为清晰图像的过程。这一过程对应着我们在使用 AI 绘画时看到的图像从模糊、充满噪声逐渐变为清晰、符合预期的呈现过程。
具体工作流程:
- 初始状态:从一张纯噪声图像开始,模型尝试逐步去除噪声,恢复图像的原有特征。
- 噪声去除:在每一次迭代降噪步骤中,模型依据输入的文本提示词所转化的特征向量及当前噪声图像的状态,通过 U-Net 等组件计算出需要减去的噪声量,并对图像进行调整。
- 参数调节:采样算法根据设定的参数(如降噪的步骤、随机性控制等)配合 U-Net 进行操作,决定如何具体地从噪声图像中去除噪声。不同的参数设置会对生成图像产生影响,如降噪步骤的多少直接关系到图像最终的精细程度。
技术挑战与解决方案:
- 细节保留:在噪声去除过程中,保持图像的细节和结构是一个重要挑战。U-Net 的跳跃连接和 Cross Attention 机制有助于解决这一问题,确保生成的图像既清晰又符合用户输入的提示词内容。
- 随机性控制:通过灵活调节采样算法中的随机性参数,可以让每次生成的图像在细节上略有不同,增加了生成图像的多样性和创造性。
参考文献
[1] “Stable Diffusion Documentation,” Stability AI
[2] “Latent Diffusion Models,” CompVis
[3] “Runway ML,” Runway
[4] “Variational Autoencoders,” Wikipedia,
[5] “U-Net: Convolutional Networks for Biomedical Image Segmentation,” arXiv,
[6] “CLIP: Connecting Text and Images,” OpenAI
未觉池塘春草梦,阶前梧叶已秋声。

学习是通往智慧高峰的阶梯,努力是成功的基石。
我在求知路上不懈探索,将点滴感悟与收获都记在博客里。
要是我的博客能触动您,盼您 点个赞、留个言,再关注一下。
您的支持是我前进的动力,愿您的点赞为您带来好运,愿您生活常暖、快乐常伴!
希望您常来看看,我是 秋声,与您一同成长。
秋声敬上,期待再会!

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









