




建表:
CREATE TABLE `product_comment` (
`comment_id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '评论ID',
`product_id` int(10) unsigned NOT NULL COMMENT '商品ID',
`order_id` bigint(20) unsigned NOT NULL COMMENT '订单ID',
`customer_id` int(10) unsigned NOT NULL COMMENT '用户ID',
`title` varchar(50) NOT NULL COMMENT '评论标题',
`content` varchar(300) NOT NULL COMMENT '评论内容',
`audit_status` tinyint(4) NOT NULL COMMENT '审核状态:0未审核1已审核',
`audit_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '评论时间',
`modified_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后修改时间',
PRIMARY KEY (`comment_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='商品评论表'
插入数据:
INSERT INTO product_comment(product_id,order_id,customer_id,title,content,audit_status) VALUES(1,108310,1,'鼠标','罗技鼠标不错',0);
INSERT INTO product_comment(product_id,order_id,customer_id,title,content,audit_status) VALUES(2,108311,2,'键盘','小米键盘good',0);
INSERT INTO product_comment(product_id,order_id,customer_id,title,content,audit_status) VALUES(3,108312,3,'U盘','华为U盘不错',0);
INSERT INTO product_comment(product_id,order_id,customer_id,title,content,audit_status) VALUES(3,108313,4,'U盘','华为U盘不错2',0);
查询sql:
EXPLAIN
SELECT customer_id,title,content FROM `product_comment` WHERE audit_status=0 AND product_id=3 LIMIT 0,3;

没加索引之前见上面图片,问题是加复合索引的话,audit_status 和 product_id 那个放在最左边??
参考58同城30条军规:

如何区分最佳做前缀位置
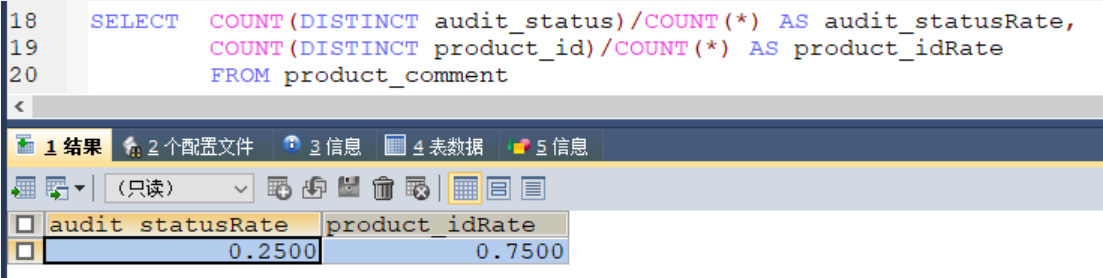
| SELECT COUNT(DISTINCT audit_status)/COUNT() AS audit_statusRate, COUNT(DISTINCT product_id)/COUNT() AS product_itRate FROM product_comment |
|---|
那个字段越接近于1,那个就是区分度更好的,就放在最左边。
-- 建索引
CREATE INDEX idx_product_id_audit_status ON product_comment(product_id,audit_status)
--删索引
DROP INDEX idx_product_id_audit_status ON product_comment


















 1328
1328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











