






 本文深入探讨了MySQL中的联合索引原理,包括最左匹配原则及其在查询中的应用。通过示例展示了如何在不同查询场景下利用联合索引提高查询效率,如索引生效、范围查询以及回表、索引覆盖和索引下推等概念。理解这些知识对于优化数据库性能至关重要。
本文深入探讨了MySQL中的联合索引原理,包括最左匹配原则及其在查询中的应用。通过示例展示了如何在不同查询场景下利用联合索引提高查询效率,如索引生效、范围查询以及回表、索引覆盖和索引下推等概念。理解这些知识对于优化数据库性能至关重要。
索引相关的基础知识可以移步至:数据库索引漫谈https://mp.weixin.qq.com/s/Xy4AmYN5eys2vbp0AGCANw
这篇文章主要针对索引进阶内容。
联合索引
联合索引是指对表上的多个列进行索引,联合索引也是一棵B+树,这里的索引键值数量大于等于2;
创建语句:
create TABLE com_table(
id int not null,
name VARCHAR(20) not null,
age int not null,
constraint comb_key PRIMARY KEY(id,name,age)
);
插入三条数据:
insert into com_table values(1,'lili',10);
insert into com_table values(2,'xiaowang',20);
insert into com_table values(3,'liming',30);
插入数据后索引是这个样子的:
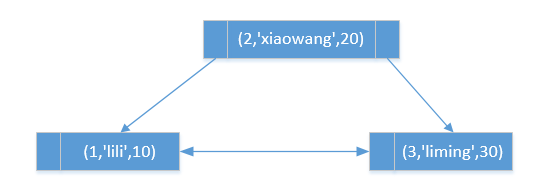
讲联合索引,一定要说到最左匹配;
什么是最左匹配:
在MySQL建立联合索引时会遵守最左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。
我们针对上面这个表以及联合索引进行一些实践:
1、索引生效
select * from com_table where age = 30;

这里是全表扫描,没有用到索引,同步只使用age也不会使用到索引;
select * from com_table where id= 3 and age = 30;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l4lPGfHp-1619651583043)(D:\学习总结\数据库\联合索引\4.png)]
命中了索引,说明符合最左前缀规则。
2、使用and 联合查询
select * from com_table where age = 30 and id = 3;

在执行sql的时候,优化器会帮我们调整where后age,id,name的顺序和索引一致,让我们用上索引,所以and情况下,只要有索引顺序第一个字段存在,就可以命中索引。
3、范围查询
select * FROM com_table where id > 2;

表示范围查询,没有命中索引。
select * FROM com_table where id = 2 and age > 10;

该条语句命中了索引;
当遇到范围查询(>、<、between、like)就会停止匹配,但是停止匹配的是使用范围的字段,比如上述中age>10,最终索引匹配终止在age字段,但是前面的字段还可以使用索引。
回表、索引覆盖、索引下推
讲述上述三个知识点的时候,我么先来创建一个表和实例,这样更好的说明其中的细节。
创建表:
CREATE TABLE T_table(
id int not NULL AUTO_INCREMENT PRIMARY KEY ,
name VARCHAR(20) not null,
age int not null
)engine=Innodb;
创建普通索引:
create index index_T on T_table(name);
表的结构:
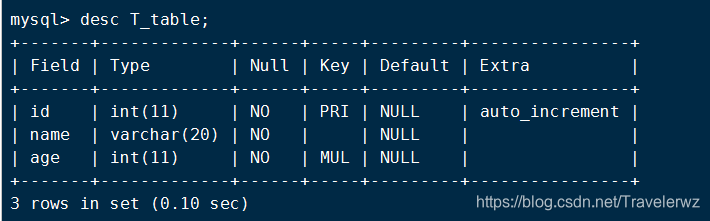
插入数据:
insert into T_table(name,age) values('lili',10);
insert into T_table(name,age) values('xiaowang',20);
insert into T_table(name,age) values('liming',30);
insert into T_table(name,age) values('yuli',50);
insert into T_table(name,age) values('kilo',70);
此时,我们的索引树有两颗,即:
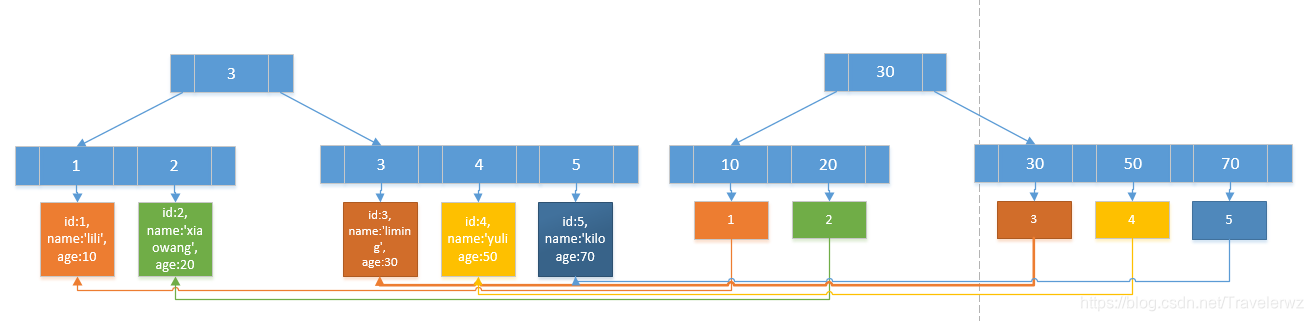
我们可以根据叶子节点的内容,索引的类型分为主键索引和非主键索引;
上图左边的是主键索引,叶子节点存储的是整行数据,右边非主键索引的叶子节点存储的是主键索引的中的一条数据,所以非主键索引也叫做二级索引。
回表:
我们先看两条语句:
select * from T_table where id = 3;
select * from T_table where age = 30;
- 第一条语句可以直接使用主键索引进行查询,通过主键索引可以直接拿到这一行的数据。
- 第二条语句是通过非聚集索引查询数据,先通过非主键索引查询主键索引,然后再搜索一次找到聚集索引的行数据。
上面第二种其实就是回表操作,也就是说非主键索引比主键索引多查询一棵树。
索引覆盖:
上面提到,我们使用非聚集索引的时候,需要多查询一个树,这样其实造成了效率会比较低,所以在什么情况下可以避免回表操作。
我们还是用刚才的语句进行修改:
select id from T_table where age = 30;
这条语句是根据上述的回表语句的变形,由于这次查询的id已经是存储在索引树上了,所以可以直接使用索引查询,不需要回表操作。
在这个查询中,索引age已经覆盖了查询请求,所以这也叫作索引覆盖。
索引下推:
上面我们讨论过联合索引,我们将(name,age)建立联合索引,这里我们再写一条sql来看下场景:
select * from T_table where name like 'l%' and age >10;
这个有两种情况,分别说下:
1、根据联合索引(name,age)查询到所有满足'l%'开头的索引,然后回表查询到所有的数据,再次进行筛选数据。这里如果name字段匹配多条数据的话,需要回表多次,效率较低。
2、根据联合索引(name,age)查询到所有满足'l%'开头的索引,并且根据age字段进行筛选,然后再进行回表操作,这样大大的提升了效率。
在上述情况2中,就是索引下推,在mysql5.6 之后,默认是索引下推的。在使用InnoDB存储引擎的数据表中,索引下推只能用于二级索引。
多条数据的话,需要回表多次,效率较低。
2、根据联合索引(name,age)查询到所有满足'l%'开头的索引,并且根据age字段进行筛选,然后再进行回表操作,这样大大的提升了效率。
在上述情况2中,就是索引下推,在mysql5.6 之后,默认是索引下推的。在使用InnoDB存储引擎的数据表中,索引下推只能用于二级索引。


















 6780
6780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









