




在棉花加工和生产过程中,棉花的质量直接影响到最终产品的品质。然而,在传统的棉花梳理和整理过程中,常常会遇到一些问题,例如棉花中可能混有异物,或者在平铺过程中出现空洞,导致平铺不均匀。这些问题不仅会影响后续床褥等产品的质量,还会增加生产成本和时间。为了解决这些问题,传统的生产方式主要依赖人工检查和处理,但这种方法不仅效率低下,而且容易出现疏漏。随着智能化技术的快速发展,越来越多的生产领域开始引入智能化解决方案,棉花生产也不例外。
智能化技术在棉花生产中的应用
1. 视频摄像头的安装与实时监测 在棉花生产线的厂房内安装高清视频摄像头,这些摄像头能够实时监控棉花的梳理和整理过程。通过这些摄像头,可以对棉花进行全方位的监测,捕捉每一个细节。摄像头的位置和角度经过精心设计,确保能够覆盖棉花生产的关键环节,从而全面监测棉花的质量问题。
2. 实时计算与异物检测 借助先进的图像处理技术和机器学习算法,系统能够对摄像头捕捉到的图像进行实时计算和分析。一旦发现棉花中存在异物或者平铺过程中出现空洞,系统会立即发出警报,提醒工人进行处理。这种实时计算和检测机制能够有效避免人工疏漏,确保每一个问题都能被及时发现和处理。
3. 报警提醒与快速定位 当系统检测到异物或空洞时,会自动触发报警机制,提醒工人进行处理。同时,系统还会提供详细的定位信息,帮助工人快速找到问题所在。这种快速定位功能不仅提高了工作效率,还减少了因寻找问题而浪费的时间,从而实现了降本增效的目标。
智能化技术带来的优势
1. 提高产品质量 通过实时监测和异物检测,智能化系统能够有效避免棉花中混入异物或出现平铺不均匀的问题。这直接提升了棉花产品的质量,确保后续生产的床褥等产品能够达到更高的质量标准,从而增强产品的市场竞争力。
2. 提升生产效率 智能化系统能够快速发现并定位问题,减少了人工检查和处理的时间。工人可以更高效地处理问题,避免因疏漏导致的重复工作。这种效率提升不仅节省了时间和人力成本,还提高了生产线的整体运行效率。
3. 降低生产成本 通过减少人工检查和处理的时间,智能化系统能够显著降低生产成本。同时,由于产品质量的提升,减少了因质量问题导致的返工和浪费,进一步降低了生产成本。
4. 提升工人体验 智能化系统的引入减轻了工人的工作负担,使他们能够更专注于处理系统发现的问题。这种分工明确的工作方式不仅提高了工作效率,还提升了工人的工作体验,减少了工作疲劳感。
在前文中我们已经进行了相关的开发实践,感兴趣的话可以自行移步阅读即可:
《AI助力纺织场景棉花异物空洞预警,基于YOLOv8全系列【n/s/m/l/x】不同参数量级模型开发构建工业纺织场景下棉花中异物、空洞智能化检测识别系统》
《AI助力纺织场景棉花异物空洞预警,基于YOLOv10全系列【n/s/m/b/l/x】参数模型开发构建工业纺织场景下棉花中异物、空洞智能化检测识别系统》
《AI助力纺织场景棉花异物空洞预警,基于YOLOv11全系列【n/s/m/l/x】参数模型开发构建工业纺织场景下棉花中异物、空洞智能化检测识别系统》
《AI助力纺织场景棉花异物空洞预警,基于最新以注意力为核心的YOLOv12全系列【n/s/m/l/x】参数模型开发构建工业纺织场景下棉花中异物、空洞智能化检测识别系统》
《AI助力纺织场景棉花异物空洞预警,基于最新超图增强型自适应视觉感知YOLOv13全系列【n/s/l/x】参数模型开发构建工业纺织场景下棉花中异物、空洞智能化检测识别系统》
本文主要是想要基于LeYOLO全系列的模型来进行相应的开发实践,首先看下实例效果:
接下来看下实例数据情况:
深度神经网络中的计算效率对于目标检测至关重要,尤其是在新模型将速度优先于高效计算(FLOP)的情况下。这种演变在某种程度上已经落后于嵌入式和面向移动的AI对象检测应用程序。这里重点讨论了基于FLOP的高效目标检测计算的神经网络结构的设计选择,并提出了几种优化方法来提高基于YLO的模型的效率。
首先,介绍了一种基于反向瓶颈和信息瓶颈原理的有效主干扩展方法。其次,提出了快速金字塔结构网络(FPAN),旨在促进快速多尺度特征共享,同时减少计算资源。最后提出了一个解耦的网络中网络(DNiN)检测头的设计,以提供快速而轻量级的计算分类和回归任务。
在这些优化的基础上,利用更高效的主干,为对象检测和以YOLO为中心的模型(称为LeYOLO)提供了一种新的缩放范例。在各种资源限制下始终优于现有模型,实现了前所未有的准确性和失败率。值得注意的是,LeYOLO Small在COCO val上仅以4.5次失败(G)获得了38.2%的竞争性mAP分数,与最新最先进的YOLOv9微小模型相比,计算量减少了42%,同时实现了类似的精度。我们的新型模型系列实现了以前未达到的浮点精度比,提供了从超低神经网络配置(<1 GFLOP)到高效但要求苛刻的目标检测设置(>4 GFLOP)的可扩展性,对于0.66、1.47、2.53、4.51、5.8和8.4浮点(G),具有25.2、31.3、35.2、38.2、39.3和41 mAP。
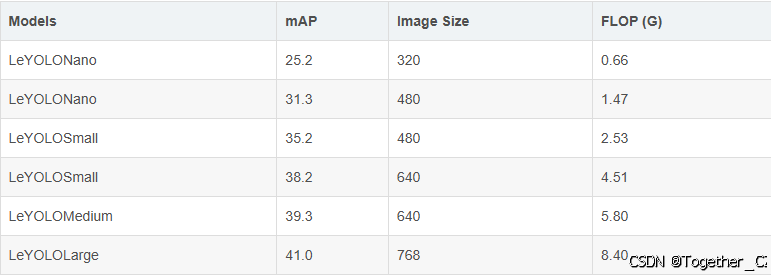
一共提供了n、s、m和l四款不同参数量级的模型。
这里我们保持完全相同的实验参数设置来进行四款模型的开发训练,等待训练完成之后我们来整体进行各项指标的对比分析。
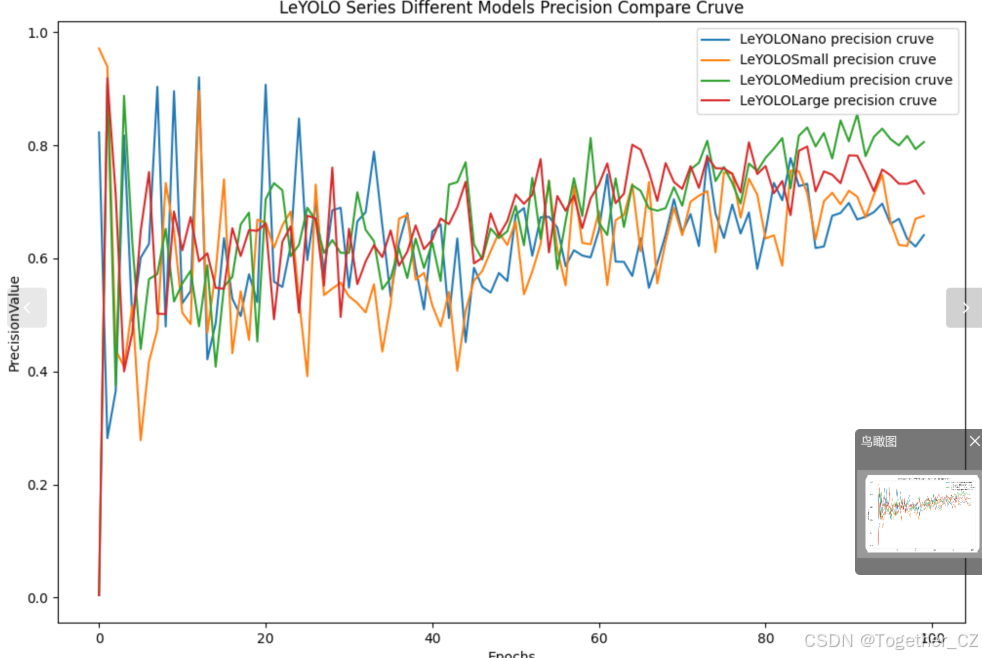
【Precision曲线】
精确率曲线(Precision Curve)是一种用于评估二分类模型在不同阈值下的精确率性能的可视化工具。它通过绘制不同阈值下的精确率和召回率之间的关系图来帮助我们了解模型在不同阈值下的表现。
精确率(Precision)是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。
绘制精确率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率和召回率。
将每个阈值下的精确率和召回率绘制在同一个图表上,形成精确率曲线。
根据精确率曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
通过观察精确率曲线,我们可以根据需求确定最佳的阈值,以平衡精确率和召回率。较高的精确率意味着较少的误报,而较高的召回率则表示较少的漏报。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。
精确率曲线通常与召回率曲线(Recall Curve)一起使用,以提供更全面的分类器性能分析,并帮助评估和比较不同模型的性能。
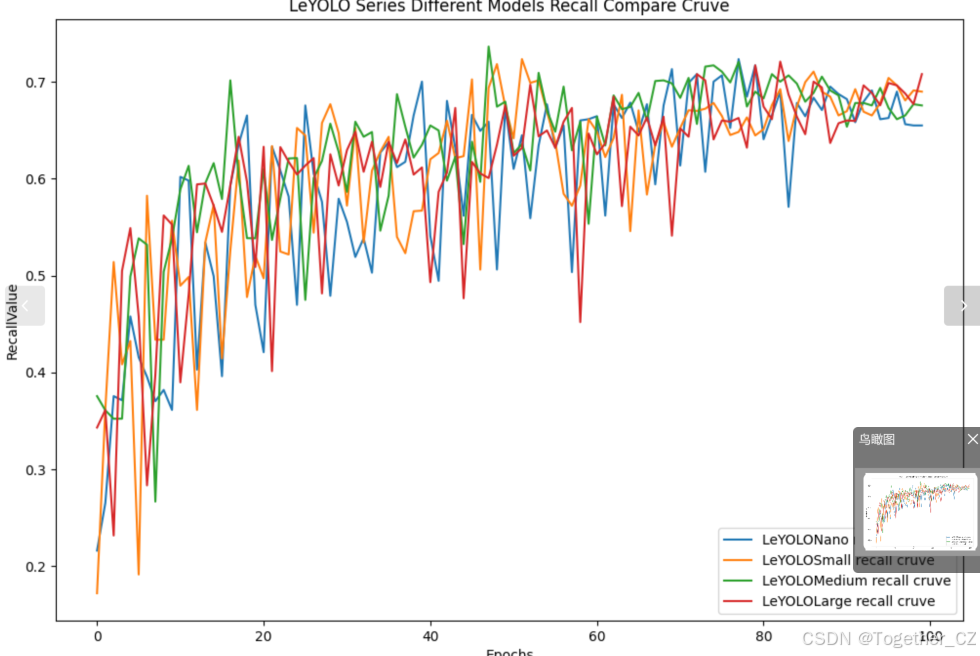
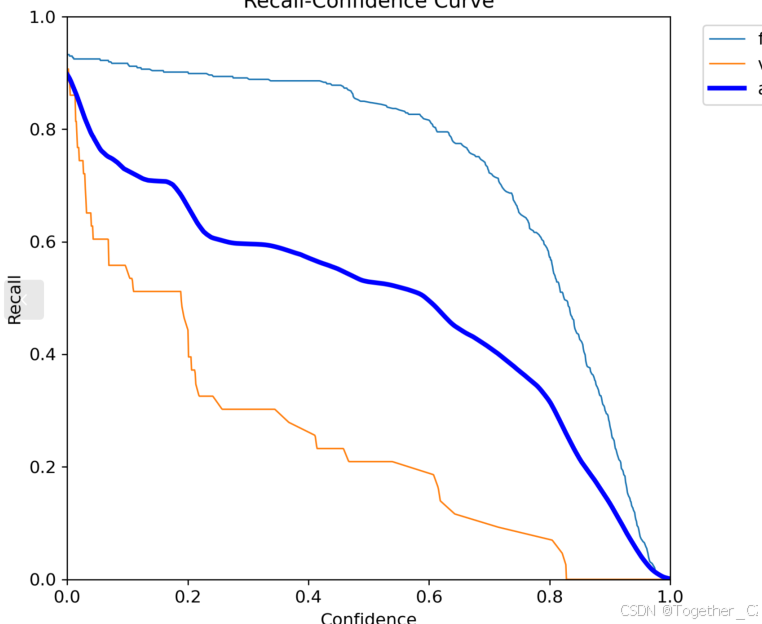
【Recall曲线】
召回率曲线(Recall Curve)是一种用于评估二分类模型在不同阈值下的召回率性能的可视化工具。它通过绘制不同阈值下的召回率和对应的精确率之间的关系图来帮助我们了解模型在不同阈值下的表现。
召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。召回率也被称为灵敏度(Sensitivity)或真正例率(True Positive Rate)。
绘制召回率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的召回率和对应的精确率。
将每个阈值下的召回率和精确率绘制在同一个图表上,形成召回率曲线。
根据召回率曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
通过观察召回率曲线,我们可以根据需求确定最佳的阈值,以平衡召回率和精确率。较高的召回率表示较少的漏报,而较高的精确率意味着较少的误报。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。
召回率曲线通常与精确率曲线(Precision Curve)一起使用,以提供更全面的分类器性能分析,并帮助评估和比较不同模型的性能。
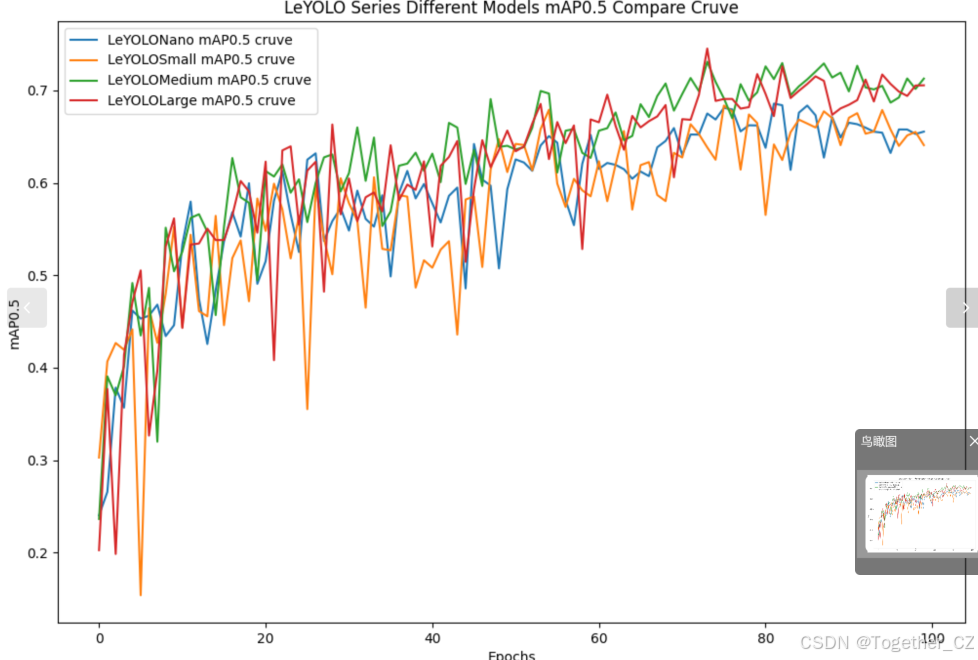
【mAP0.5】
mAP0.5,也被称为mAP@0.5或AP50,指的是当Intersection over Union(IoU)阈值为0.5时的平均精度(mean Average Precision)。IoU是一个用于衡量预测边界框与真实边界框之间重叠程度的指标,其值范围在0到1之间。当IoU值为0.5时,意味着预测框与真实框至少有50%的重叠部分。
在计算mAP0.5时,首先会为每个类别计算所有图片的AP(Average Precision),然后将所有类别的AP值求平均,得到mAP0.5。AP是Precision-Recall Curve曲线下面的面积,这个面积越大,说明AP的值越大,类别的检测精度就越高。
mAP0.5主要关注模型在IoU阈值为0.5时的性能,当mAP0.5的值很高时,说明算法能够准确检测到物体的位置,并且将其与真实标注框的IoU值超过了阈值0.5。
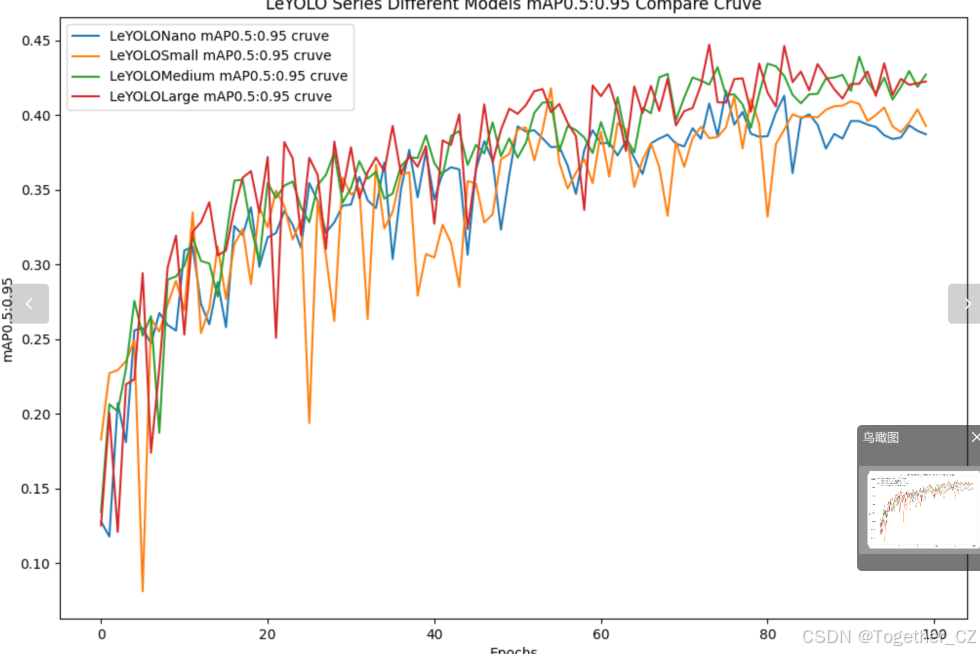
【mAP0.5:0.95】
mAP0.5:0.95,也被称为mAP@[0.5:0.95]或AP@[0.5:0.95],表示在IoU阈值从0.5到0.95变化时,取各个阈值对应的mAP的平均值。具体来说,它会在IoU阈值从0.5开始,以0.05为步长,逐步增加到0.95,并在每个阈值下计算mAP,然后将这些mAP值求平均。
这个指标考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。当mAP0.5:0.95的值很高时,说明算法在不同阈值下的检测结果均非常准确,覆盖面广,可以适应不同的场景和应用需求。
对于一些需求比较高的场合,比如安全监控等领域,需要保证高的准确率和召回率,这时mAP0.5:0.95可能更适合作为模型的评价标准。
综上所述,mAP0.5和mAP0.5:0.95都是用于评估目标检测模型性能的重要指标,但它们的关注点有所不同。mAP0.5主要关注模型在IoU阈值为0.5时的性能,而mAP0.5:0.95则考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。
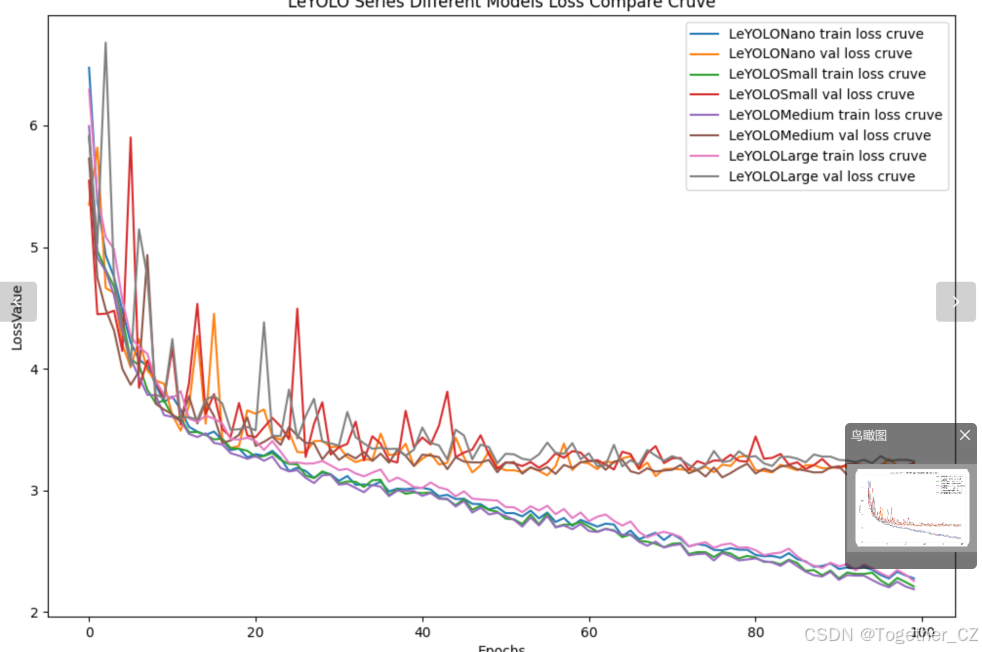
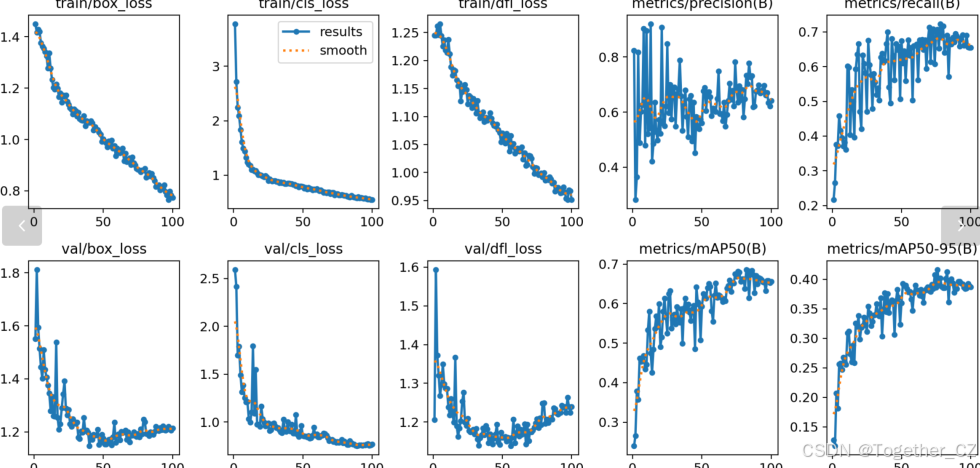
【loss曲线】
在深度学习的训练过程中,loss函数用于衡量模型预测结果与实际标签之间的差异。loss曲线则是通过记录每个epoch(或者迭代步数)的loss值,并将其以图形化的方式展现出来,以便我们更好地理解和分析模型的训练过程。
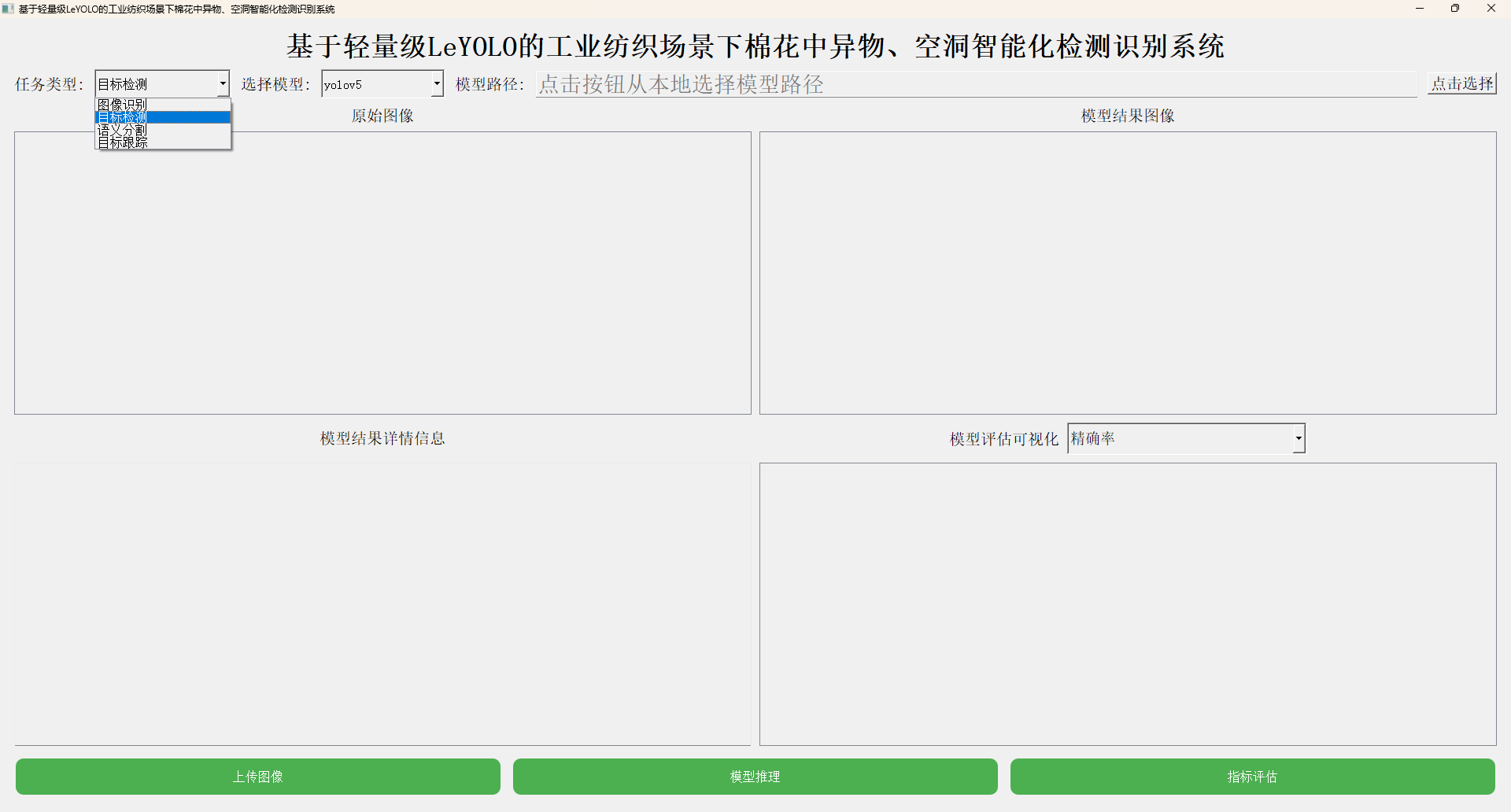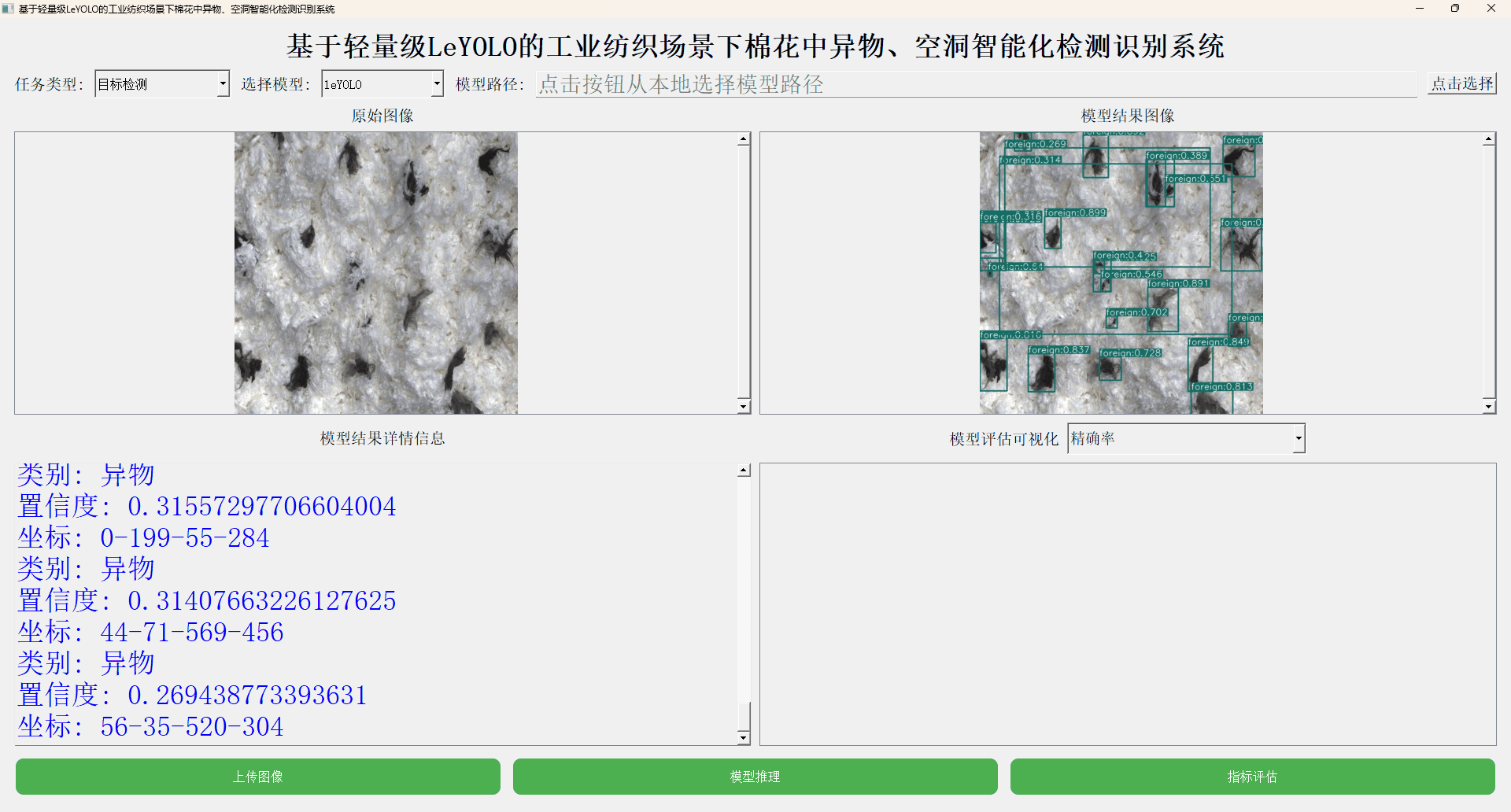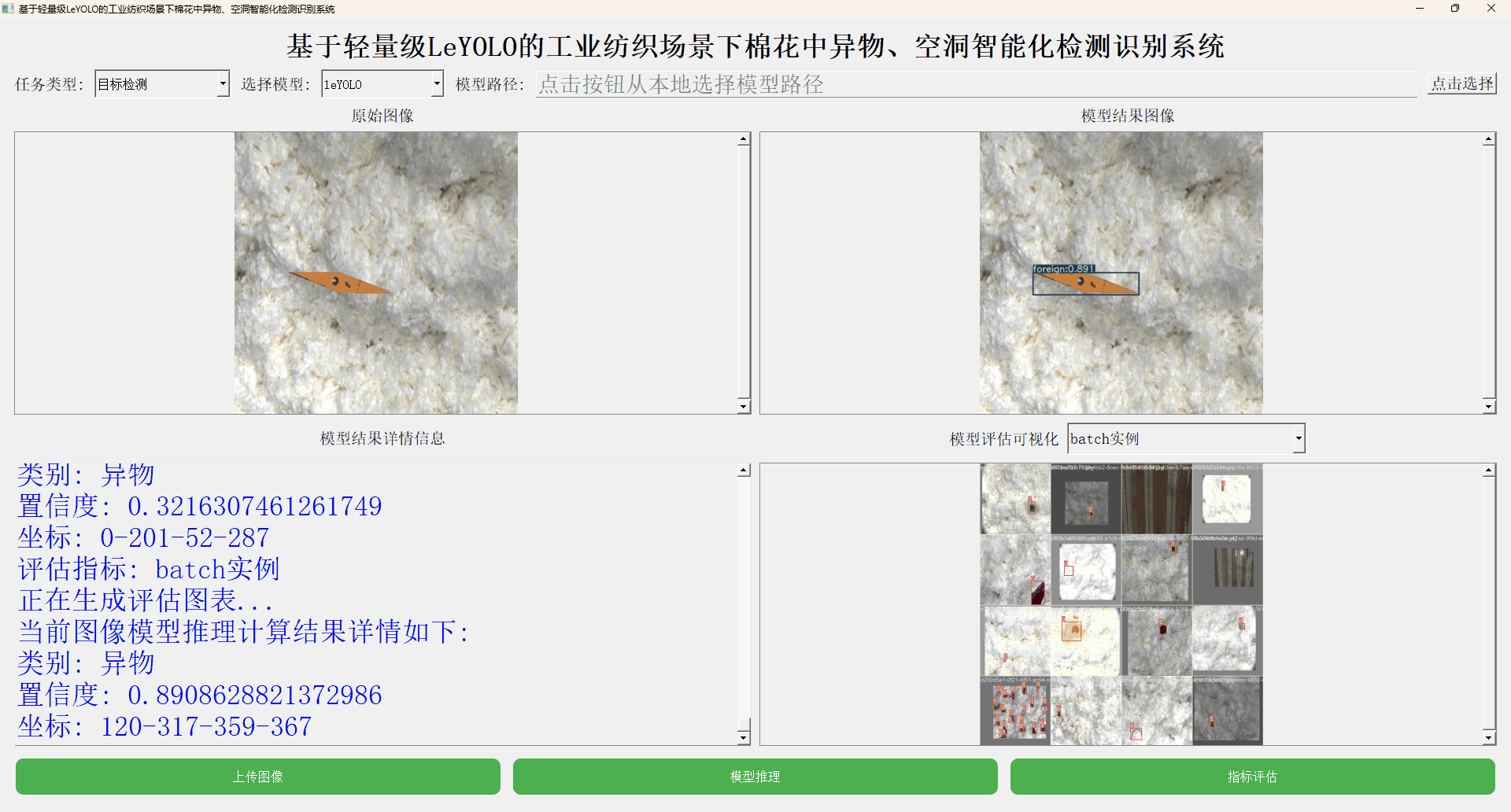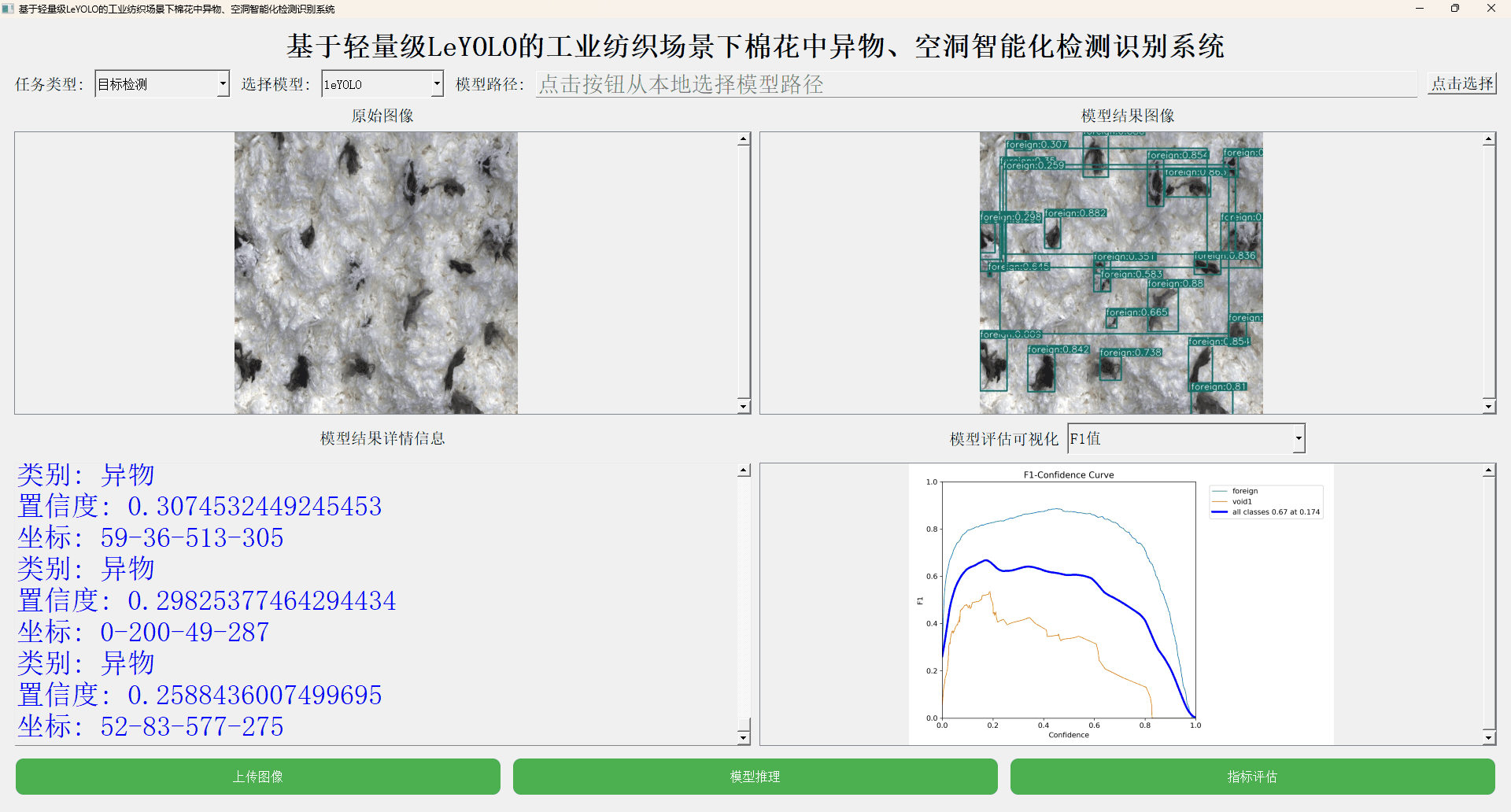
【F1值曲线】
F1值曲线是一种用于评估二分类模型在不同阈值下的性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)、召回率(Recall)和F1分数的关系图来帮助我们理解模型的整体性能。
F1分数是精确率和召回率的调和平均值,它综合考虑了两者的性能指标。F1值曲线可以帮助我们确定在不同精确率和召回率之间找到一个平衡点,以选择最佳的阈值。
绘制F1值曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率、召回率和F1分数。
将每个阈值下的精确率、召回率和F1分数绘制在同一个图表上,形成F1值曲线。
根据F1值曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
F1值曲线通常与接收者操作特征曲线(ROC曲线)一起使用,以帮助评估和比较不同模型的性能。它们提供了更全面的分类器性能分析,可以根据具体应用场景来选择合适的模型和阈值设置。
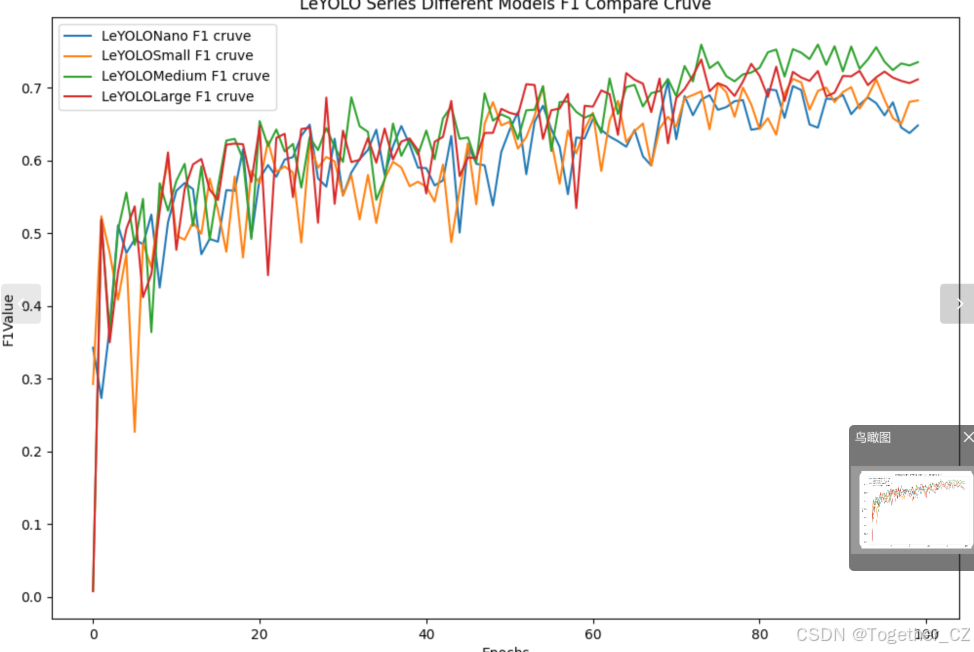
整体对比分析来看:不难发现四款不同参数量级的模型最终达到了较为相似的结果,没有拉开非常大的差距,这里综合参数量考虑我们最终选定了s系列的模型来作为线上的推理计算模型。接下来看下s系列模型的详细情况。
【离线推理实例】

【Batch实例】

【混淆矩阵】
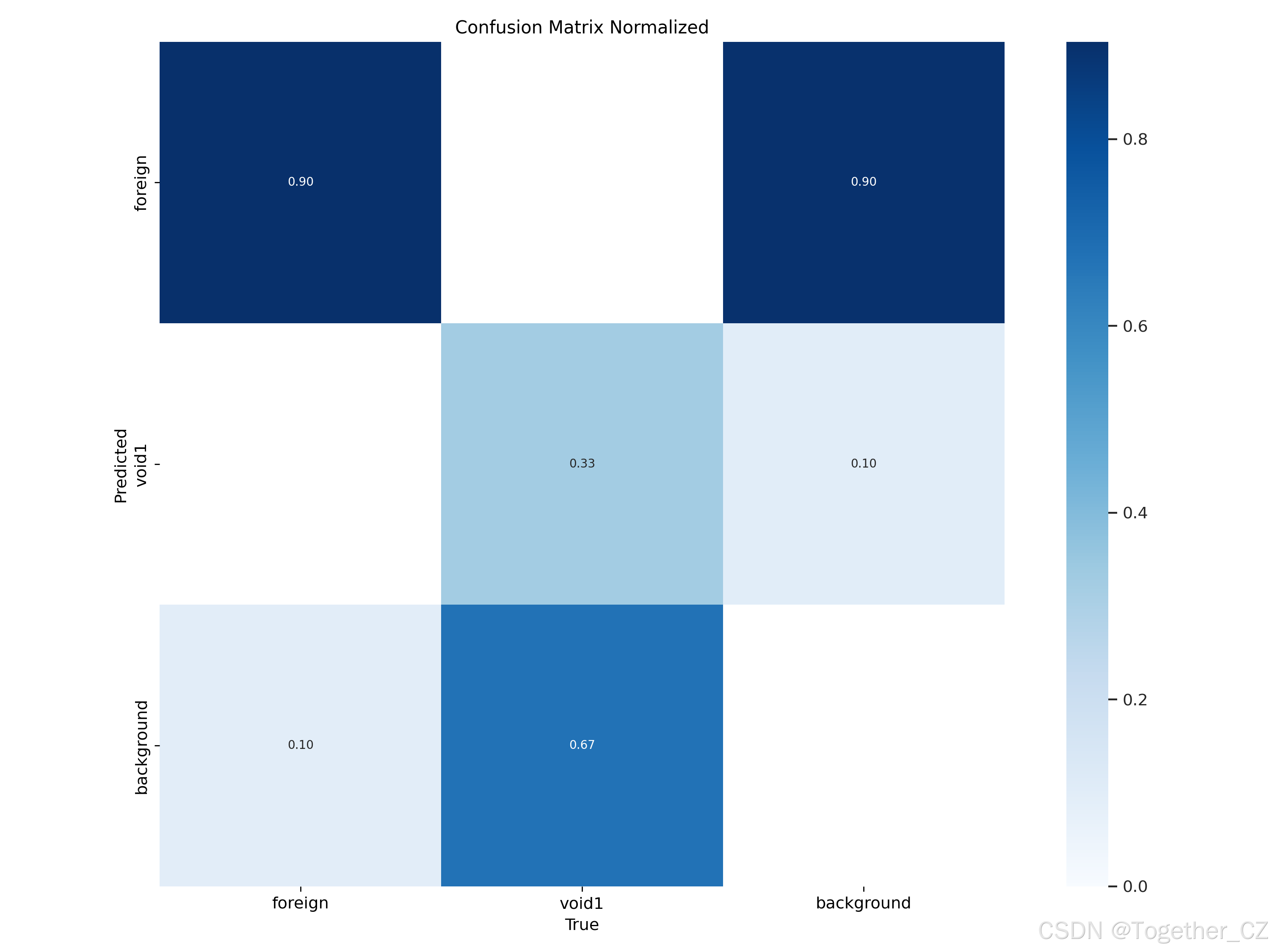
【F1值曲线】
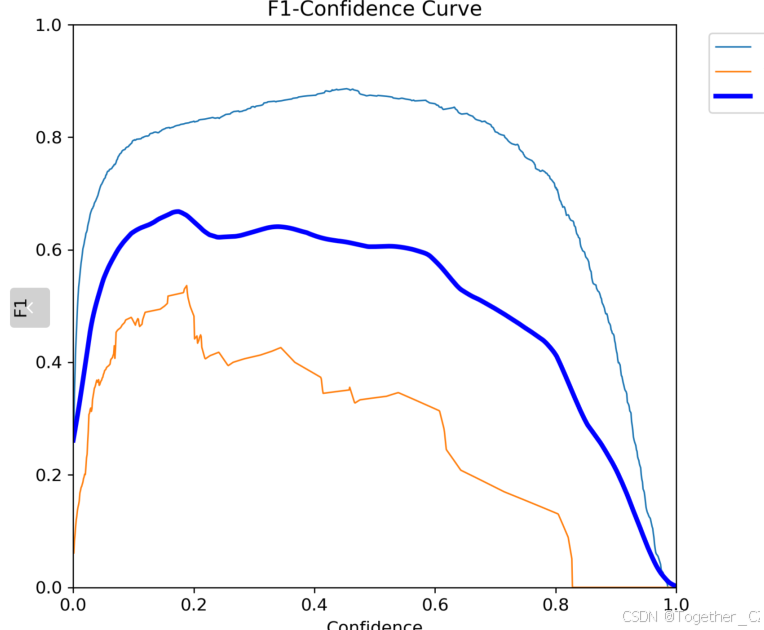
【Precision曲线】
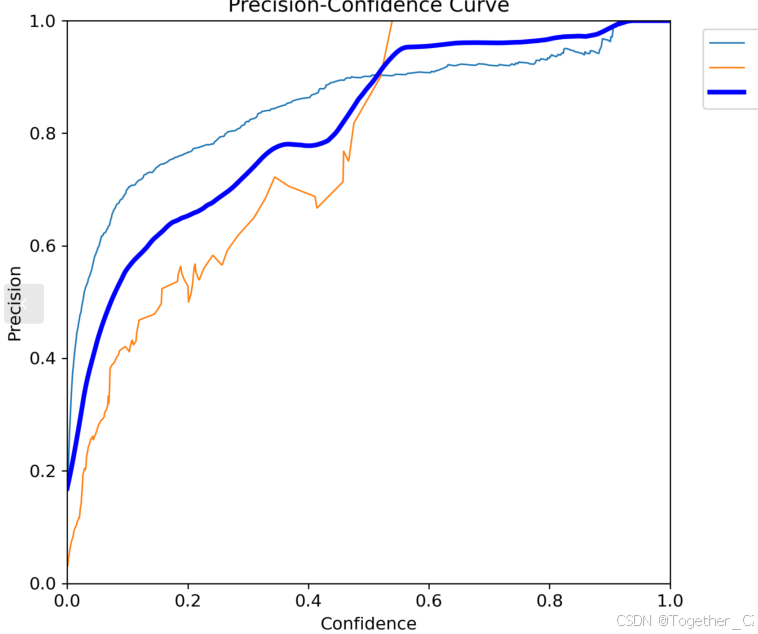
【PR曲线】
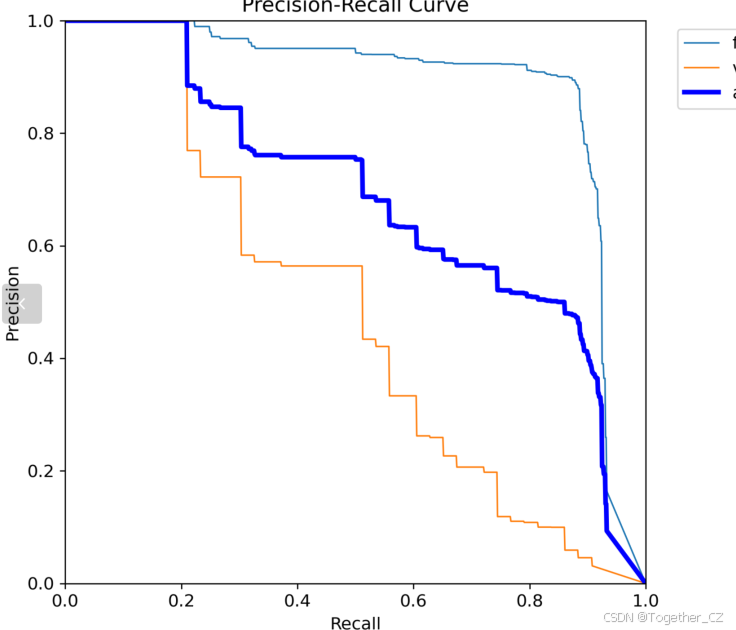
【Recall曲线】
【训练可视化】
然而,智能化技术在棉花生产中的应用仍面临一些挑战。例如,摄像头的维护和数据传输的稳定性需要进一步提高,以确保系统的长期稳定运行。同时,检测算法的准确性和可靠性也需要不断优化,以适应不同生产环境下的复杂情况。
展望未来,随着技术的不断进步和应用的不断深入,智能化技术将在棉花生产中发挥更大的作用。它将与物联网、大数据等技术相结合,形成一个更加智能化、自动化的生产系统。通过智能化技术的赋能,棉花生产将更加高效、精准和科学,为企业的可持续发展提供有力保障。
总之,智能化技术在棉花生产中的应用是行业发展的必然趋势。它不仅能够有效提升产品质量和生产效率,还能降低生产成本,提升工人的工作体验。随着技术的不断发展和应用的不断拓展,智能化技术将在更多棉花生产企业得到推广和应用,为行业的高质量发展贡献重要力量。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











