




这篇文章介绍了 DINO-X,一个由 IDEA 研究团队开发的统一视觉模型,旨在推动开放世界目标检测和理解领域的发展。以下是文章的主要内容总结:
-
模型概述:
-
DINO-X 是一个以目标为中心的视觉模型,支持多种开放世界感知和目标级理解任务,包括目标检测、分割、短语定位、视觉提示计数、姿态估计、无提示目标检测与识别、密集区域描述等。
-
DINO-X 基于 Transformer 的编码器-解码器架构,扩展了输入选项,支持文本提示、视觉提示和自定义提示,使得长尾目标检测更加容易。
-
-
核心创新:
-
多提示支持:DINO-X 支持文本提示、视觉提示和自定义提示,能够覆盖更广泛的长尾检测场景。
-
大规模数据集:构建了包含超过 1 亿个高质量定位样本的 Grounding-100M 数据集,用于提升模型的开放词汇检测性能。
-
多任务支持:通过集成多个感知头(如框头、掩码头、关键点头、语言头),DINO-X 能够同时支持多种目标感知和理解任务。
-
-
模型变体:
-
DINO-X Pro:提供增强的感知能力,适用于多种场景。
-
DINO-X Edge:优化了推理速度,更适合在边缘设备上部署。
-
-
实验与评估:
-
DINO-X Pro 在 COCO、LVIS-minival 和 LVIS-val 零样本目标检测基准上取得了显著的性能提升,尤其在长尾目标检测方面表现突出。
-
DINO-X Edge 在推理速度上进行了优化,能够在边缘设备上实现实时目标检测。
-
-
应用场景:
-
DINO-X 展示了在开放世界目标检测、长描述短语定位、视觉提示计数、无提示目标检测与识别、密集区域描述、人体与手部姿态估计等多种任务中的强大能力。
-
-
未来工作:
-
文章指出,DINO-X 的分割性能仍有提升空间,未来将进一步优化掩码头的性能。
-
DINO-X 是一个功能强大且灵活的视觉模型,能够处理多种开放世界目标检测和理解任务,并在多个基准测试中取得了最先进的性能。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

官方项目地址在这里,如下所示:
摘要
一个击球手正准备挥棒击球,而捕手则蹲在本垒板后方。裁判站在捕手后面,准备做出判罚。
1 DINO-X

图 1: DINO-X 是一个统一的以目标为中心的视觉模型,支持多种开放世界感知和目标级理解任务,包括开放世界目标检测与分割、短语定位、视觉提示计数、姿态估计、无提示目标检测与识别、密集区域描述等。
摘要
本文介绍了 DINO-X,这是由 IDEA 研究团队开发的一个统一的以目标为中心的视觉模型,具有迄今为止最佳的开放世界目标检测性能。DINO-X 采用了与 Grounding DINO 1.5 [47] 相同的基于 Transformer 的编码器-解码器架构,旨在为开放世界目标理解提供目标级表示。为了使长尾目标检测变得容易,DINO-X 扩展了其输入选项,支持文本提示、视觉提示和自定义提示。通过这种灵活的提示选项,我们开发了一种通用目标提示,支持无提示的开放世界检测,使得用户无需提供任何提示即可检测图像中的任何目标。为了增强模型的核心定位能力,我们构建了一个包含超过 1 亿个高质量定位样本的大规模数据集,称为 Grounding-100M,以提升模型的开放词汇检测性能。在此大规模定位数据集上进行预训练,形成了一个基础的目标级表示,使得 DINO-X 能够集成多个感知头,同时支持多种目标感知和理解任务,包括检测、分割、姿态估计、目标描述、基于目标的问答等。DINO-X 包含两个模型:Pro 模型,提供增强的感知能力,适用于多种场景;Edge 模型,优化了推理速度,更适合在边缘设备上部署。实验结果表明,DINO-X 表现出卓越的性能。具体来说,DINO-X Pro 模型在 COCO、LVIS-minival 和 LVIS-val 零样本目标检测基准上分别达到了 56.0 AP、59.8 AP 和 52.4 AP。值得注意的是,它在 LVIS-minival 和 LVIS-val 基准的稀有类别上分别获得了 63.3 AP 和 56.5 AP,比之前的 SOTA 性能提高了 5.8 AP 和 5.0 AP。这一结果突显了其在识别长尾目标方面的显著改进能力。
1 引言
近年来,目标检测逐渐从封闭集检测模型 [74, 28, 4] 发展到开放集检测模型 [33, 29, 76],这些模型能够识别与用户提供的提示相对应的目标。此类模型具有众多实际应用,例如增强机器人在动态环境中的适应性,帮助自动驾驶车辆快速定位并应对新目标,提升多模态大语言模型 (MLLMs) 的感知能力,减少其幻觉并提高其响应的可靠性。
本文介绍了 DINO-X,这是由 IDEA 研究团队开发的一个统一的以目标为中心的视觉模型,具有迄今为止最佳的开放世界目标检测性能。基于 Grounding DINO 1.5 [47],DINO-X 采用了相同的 Transformer 编码器-解码器架构,并将开放集检测作为其核心训练任务。
为了使长尾目标检测变得容易,DINO-X 在模型的输入阶段引入了更全面的提示设计。传统的仅支持文本提示的模型 [33, 47, 29] 虽然取得了很大进展,但由于难以收集足够多样化的训练数据以覆盖各种应用场景,仍然难以覆盖足够广泛的长尾检测场景。为了克服这一不足,在 DINO-X 中,我们扩展了模型架构,支持以下三种类型的提示。(1) 文本提示:根据用户提供的文本输入识别所需目标,这可以覆盖大多数检测场景。(2) 视觉提示:除了文本提示外,DINO-X 还支持视觉提示,如 T-Rex2 [18] 中所示,进一步覆盖了无法通过文本很好描述的检测场景。(3) 自定义提示:为了支持更多的长尾检测问题,我们特别在 DINO-X 中引入了自定义提示,可以通过预定义或用户调整的提示嵌入来实现,以满足定制需求。通过提示调优,我们可以为不同领域创建领域定制的提示,或为各种功能需求创建功能特定的提示。例如,在 DINO-X 中,我们开发了一种通用目标提示,支持无提示的开放世界目标检测,使得用户无需提供任何提示即可检测图像中的任何目标。
为了获得强大的定位性能,我们从多种来源收集并整理了超过 1 亿个高质量的定位样本,称为 Grounding-100M。在此大规模定位数据集上进行预训练,形成了一个基础的目标级表示,使得 DINO-X 能够集成多个感知头,同时支持多种目标感知和理解任务。除了用于目标检测的框头外,DINO-X 还实现了三个额外的头:(1) 掩码头:用于预测检测目标的掩码,(2) 关键点头:用于预测特定类别的更具语义意义的关键点,(3) 语言头:用于为每个检测目标生成细粒度的描述性标题。通过集成这些头,DINO-X 可以提供对输入图像的更详细的目标级理解。在图 1 中,我们列出了 DINO-X 支持的各种目标级视觉任务的示例。
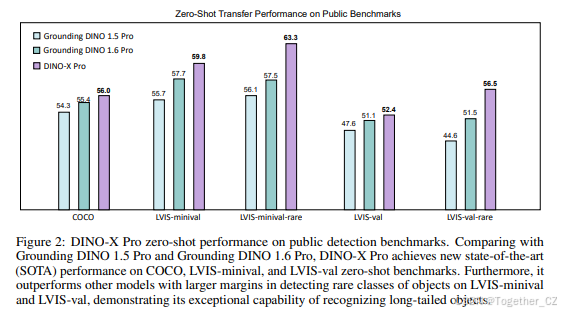
与 Grounding DINO 1.5 类似,DINO-X 也包含两个模型:DINO-X Pro 模型,提供增强的感知能力,适用于多种场景;DINO-X Edge 模型,优化了推理速度,更适合在边缘设备上部署。实验结果表明,DINO-X 表现出卓越的性能。如图 2 所示,我们的 DINO-X Pro 模型在 COCO、LVIS-minival 和 LVIS-val 零样本迁移基准上分别达到了 56.0 AP、59.8AP 和 52.4 AP。值得注意的是,它在 LVIS-minival 和 LVIS-val 基准的稀有类别上分别获得了 63.3 AP 和 56.5 AP,比 Grounding DINO 1.6 Pro 提高了 5.8 AP 和 5.0 AP,比 Grounding DINO 1.5 Pro 提高了 7.2 AP 和 11.9 AP,突显了其在识别长尾目标方面的显著改进能力。
2 方法
模型架构
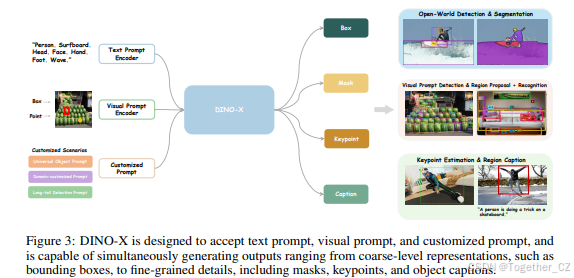
DINO-X 的整体框架如图 3 所示。与 Grounding DINO 1.5 类似,我们也开发了两个 DINO-X 模型的变体:功能更强大且更全面的“Pro”版本 DINO-X Pro,以及速度更快的“Edge”版本 DINO-X Edge,它们将分别在 2.1.1 和 2.1.2 节中详细介绍。
2.1.1 DINO-X Pro
DINO-X Pro 模型的核心架构与 Grounding DINO 1.5 [47] 类似。我们使用预训练的 ViT [12] 模型作为其主要视觉骨干,并在特征提取阶段采用深度早期融合策略。与 Grounding DINO 1.5 不同的是,为了进一步扩展模型的长尾目标检测能力,我们在 DINO-X Pro 的输入阶段扩展了提示支持。除了文本提示外,我们还扩展了 DINO-X Pro 以支持视觉提示和自定义提示,以覆盖各种检测需求。文本提示可以覆盖日常生活中常见的大多数目标检测场景,而视觉提示则增强了模型在文本提示由于数据稀缺和描述限制而不足的情况下的检测能力 [18]。自定义提示被定义为一组可以通过提示调优 [26] 技术进行微调的专用提示,以在不影响其他能力的情况下扩展模型在更多长尾、领域特定或功能特定场景中的检测能力。通过大规模定位预训练,我们从 DINO-X 的编码器输出中获得了基础的目标级表示。这种强大的表示使我们能够通过引入不同的感知头来无缝支持多个目标感知或理解任务。因此,DINO-X 能够生成从粗粒度(如边界框)到更细粒度(包括掩码、关键点和目标描述)的不同语义级别的输出。
我们将在以下段落中首先介绍 DINO-X 中支持的提示。
文本提示编码器:Grounding DINO [33] 和 Grounding DINO 1.5 [47] 都使用 BERT [9] 作为文本编码器。然而,BERT 模型仅在文本数据上进行训练,这限制了其在需要多模态对齐的感知任务(如开放世界检测)中的有效性。因此,在 DINO-X Pro 中,我们使用预训练的 CLIP [65] 模型作为文本编码器,该模型在广泛的多模态数据上进行了预训练,从而进一步提高了模型在各种开放世界基准上的训练效率和性能。
视觉提示编码器:我们采用了 T-Rex2 [18] 中的视觉提示编码器,通过使用用户定义的视觉提示(以框和点格式)来增强目标检测。这些提示通过正弦-余弦层转换为位置嵌入,然后投影到统一的特征空间中。模型使用不同的线性投影分离框提示和点提示。然后,我们采用与 T-Rex2 相同的多尺度可变形交叉注意力层,从多尺度特征图中提取视觉提示特征,条件为用户提供的视觉提示。
自定义提示:在实际使用案例中,经常会遇到需要为定制场景微调模型的情况。在 DINO-X Pro 中,我们定义了一系列专用提示,称为自定义提示,可以通过提示调优 [26] 技术进行微调,以覆盖更多长尾、领域特定或功能特定的场景,而不会影响其他能力。例如,我们开发了一种通用目标提示,支持无提示的开放世界检测,使得用户无需提供任何提示即可检测图像中的任何目标,从而扩展了其在屏幕解析 [35] 等领域的潜在应用。
图 3: DINO-X 设计为接受文本提示、视觉提示和自定义提示,并能够同时生成从粗粒度表示(如边界框)到细粒度细节(包括掩码、关键点和目标描述)的输出。
给定输入图像和用户提供的提示(无论是文本、视觉还是自定义提示嵌入),DINO-X 在提示和从输入图像中提取的视觉特征之间进行深度特征融合,然后应用不同的头进行不同的感知任务。更具体地说,实现的头将在以下段落中介绍。
框头:与 Grounding DINO [33] 类似,我们采用语言引导的查询选择模块来选择与输入提示最相关的特征作为解码器目标查询。每个查询随后被输入到 Transformer 解码器中,并逐层更新,然后通过一个简单的 MLP 层预测每个目标查询的相应边界框坐标。与 Grounding DINO 类似,我们使用 L1 损失和 G-IoU [49] 损失进行边界框回归,同时使用对比损失将每个目标查询与输入提示对齐以进行分类。
掩码头:遵循 Mask2Former [4] 和 Mask DINO [28] 的核心设计,我们通过融合 1/4 分辨率的骨干特征和从 Transformer 编码器上采样的 1/8 分辨率特征来构建像素嵌入图。然后,我们对 Transformer 解码器中的每个目标查询与像素嵌入图进行点积,以获得查询的掩码输出。为了提高训练效率,骨干的 1/4 分辨率特征图仅用于掩码预测。我们还遵循 [24, 4],仅在最终掩码损失计算中为采样点计算掩码损失。
关键点头:关键点头将 DINO-X 中与关键点相关的检测输出(例如人体或手部)作为输入,并利用单独的解码器解码目标关键点。每个检测输出被视为一个查询,并扩展为多个关键点,然后发送到多个可变形 Transformer 解码器层,以预测所需的关键点位置及其可见性。此过程可以视为简化的 ED-Pose [68] 算法,它不需要考虑目标检测任务,而只专注于关键点检测。在 DINO-X 中,我们实例化了两个关键点头,分别用于人体和手部,分别有 17 个和 21 个预定义关键点。
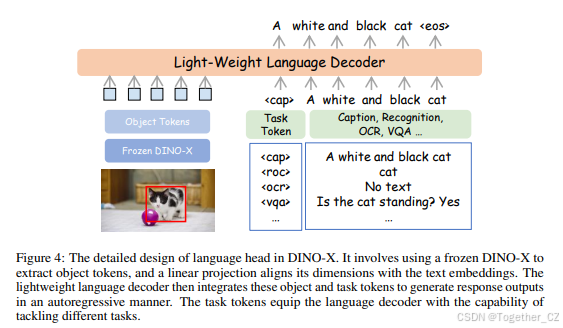
语言头:语言头是一个任务可提示的生成式小语言模型,用于增强 DINO-X 的区域上下文理解能力,并执行超越定位的感知任务,如目标识别、区域描述、文本识别和基于区域的视觉问答 (VQA)。我们的模型架构如图 4 所示。对于 DINO-X 中的任何检测目标,我们首先使用 RoIAlign [15] 操作符从其骨干特征中提取区域特征,并结合其查询嵌入形成我们的目标标记。然后,我们应用简单的线性投影以确保其维度与文本嵌入对齐。轻量级语言解码器将这些区域表示与任务标记集成,以自回归方式生成输出。可学习的任务标记使语言解码器能够处理各种任务。
2.1.2 DINO-X Edge
与 Grounding DINO 1.5 Edge [47] 类似,DINO-X Edge 也使用 EfficientViT [1] 作为骨干进行高效特征提取,并采用了类似的 Transformer 编码器-解码器架构。为了进一步增强 DINO-X Edge 模型的性能和计算效率,我们在模型架构和训练技术方面进行了多项改进:
更强的文本提示编码器:为了实现更有效的区域级多模态对齐,DINO-X Edge 采用了与 Pro 模型相同的 CLIP 文本编码器。在实践中,文本提示嵌入可以在大多数情况下预先计算,不会影响视觉编码器和解码器的推理速度。使用更强的文本提示编码器通常会带来更好的结果。
知识蒸馏:在 DINO-X Edge 中,我们从 Pro 模型中蒸馏知识,以增强 Edge 模型的性能。具体来说,我们使用了基于特征的蒸馏和基于响应的蒸馏,分别对齐 Edge 模型和 Pro 模型之间的特征和预测 logits。这种知识转移使 DINO-X Edge 相比 Grounding DINO 1.6 Edge 具有更强的零样本能力。
改进的 FP16 推理:我们采用了浮点乘法的归一化技术,使得模型可以量化为 FP16 而不影响精度。这使得推理速度达到了 20.1 FPS,相比 Grounding DINO 1.6 Edge 的 15.1 FPS 提高了 33%,相比 Grounding DINO 1.5 Edge 的 10.7 FPS 提高了 87%。
3 数据集构建与模型训练
数据收集:为了确保核心的开放词汇目标检测能力,我们开发了一个高质量且语义丰富的定位数据集,包含从网络上收集的超过 1 亿张图像,称为 Grounding-100M。我们使用了 T-Rex2 的训练数据以及一些额外的工业场景数据进行视觉提示定位预训练。我们使用开源分割模型(如 SAM [23] 和 SAM2 [46])为 Grounding-100M 数据集的一部分生成伪掩码注释,作为我们掩码头的主要训练数据。我们从 Grounding-100M 数据集中采样了一部分高质量数据,并使用其框注释作为我们的无提示检测训练数据。我们还收集了超过 1000 万条区域理解数据,涵盖目标识别、区域描述、OCR 和区域级问答场景,用于语言头训练。
模型训练:为了克服训练多个视觉任务的挑战,我们采用了两阶段策略。在第一阶段,我们对基于文本提示的检测、基于视觉提示的检测和目标分割进行了联合训练。在此训练阶段,我们没有使用 COCO [32]、LVIS [14] 和 V3Det [57] 数据集中的任何图像或注释,以便我们可以在这些基准上评估模型的零样本检测性能。这种大规模的定位预训练确保了 DINO-X 的出色开放词汇定位性能,并形成了一个基础的目标级表示。在第二阶段,我们冻结了 DINO-X 的骨干,并添加了两个关键点头(用于人体和手部)和一个语言头,每个头分别进行训练。通过添加更多的头,我们大大扩展了 DINO-X 执行更细粒度感知和理解任务的能力,如姿态估计、区域描述、基于目标的问答等。随后,我们利用提示调优技术训练了一个通用目标提示,允许进行无提示的任意目标检测,同时保留模型的其他能力。这种两阶段训练方法有几个优点:(1) 它确保模型的核心定位能力不会因引入新能力而受到影响,(2) 它还验证了大规模定位预训练可以作为以目标为中心的模型的坚实基础,允许无缝迁移到其他开放世界理解任务。
图 4: DINO-X 中语言头的详细设计。它涉及使用冻结的 DINO-X 提取目标标记,并通过线性投影将其维度与文本嵌入对齐。轻量级语言解码器随后将这些目标和任务标记集成,以自回归方式生成响应输出。任务标记使语言解码器能够处理不同的任务。
4 评估
在本节中,我们将 DINO-X 系列模型的各种能力与其相关工作进行了比较。最佳和第二佳结果分别用粗体和下划线表示。
DINO-X Pro
4.1.1 开放世界检测与分割
零样本目标检测与分割基准评估:与 Grounding DINO 1.5 Pro [47] 类似,我们在 COCO [32] 基准上评估了 DINO-X Pro 的零样本目标检测与分割能力,该基准包含 80 个常见类别,以及 LVIS 基准,该基准具有更丰富和更广泛的长尾类别分布。如表 1 所示,DINO-X Pro 相比之前的最先进方法表现出显著的性能提升。具体来说,在 COCO 基准上,DINO-X Pro 相比 Grounding DINO 1.5 Pro 和 Grounding DINO 1.6 Pro 分别提高了 1.7框 AP 和 0.6框 AP。在 LVIS-minival 和 LVIS-val 基准上,DINO-X Pro 分别达到了 59.8 框 AP 和 52.4 框 AP,分别超过了之前表现最佳的 Grounding DINO 1.6 Pro 模型 2.0 AP 和 1.1 AP。值得注意的是,对于 LVIS 稀有类别的检测性能,DINO-X 在 LVIS-minival 和 LVIS-val 上分别获得了 63.3 AP 和 56.5 AP,显著超过了之前的 SOTA Grounding DINO 1.6 Pro 模型 5.8 AP 和 5.0AP,展示了 DINO-X 在长尾目标检测场景中的卓越能力。在分割指标方面,我们将 DINO-X 与最常用的通用分割模型 Grounded SAM [48] 系列在 COCO 和 LVIS 零样本实例分割基准上进行了比较。使用 Grounding DINO 1.5 Pro 进行零样本检测和 SAM-Huge [23] 进行分割,Grounded SAM 在 LVIS 实例分割基准上取得了最佳零样本性能。DINO-X 在 COCO、LVIS-minival 和 LVIS-val 零样本实例分割基准上分别获得了 37.9、43.8 和 38.5的掩码 AP 分数。与 Grounded SAM 相比,DINO-X 在分割性能上仍有显著差距,这表明训练一个统一模型以执行多个任务的挑战。尽管如此,DINO-X 通过为每个区域生成相应的掩码而无需多个复杂的推理步骤,显著提高了分割效率。我们将在未来的工作中进一步优化掩码头的性能。
基于视觉提示的检测基准评估:为了评估 DINO-X 的视觉提示目标检测能力,我们在少样本目标计数基准上进行了实验。在此任务中,每个测试图像都附带三个视觉示例框,表示目标对象,模型需要输出目标对象的计数。我们使用 FSC147 [45] 和 FSCD-LVIS [40] 数据集评估性能,这两个数据集都包含密集小目标的场景。具体来说,FSC147 主要由单目标场景组成,每张图像中只有一种类型的对象,而 FSCD-LVIS 则专注于包含多个对象类别的多目标场景。对于 FSC147,我们报告了平均绝对误差 (MAE) 指标,对于 FSCD-LVIS,我们使用了平均精度 (AP) 指标。根据之前的工作 [17, 18],视觉示例框被用作交互式视觉提示。如表 2 所示,DINO-X 取得了最先进的性能,展示了其在实用视觉提示目标检测中的强大能力。
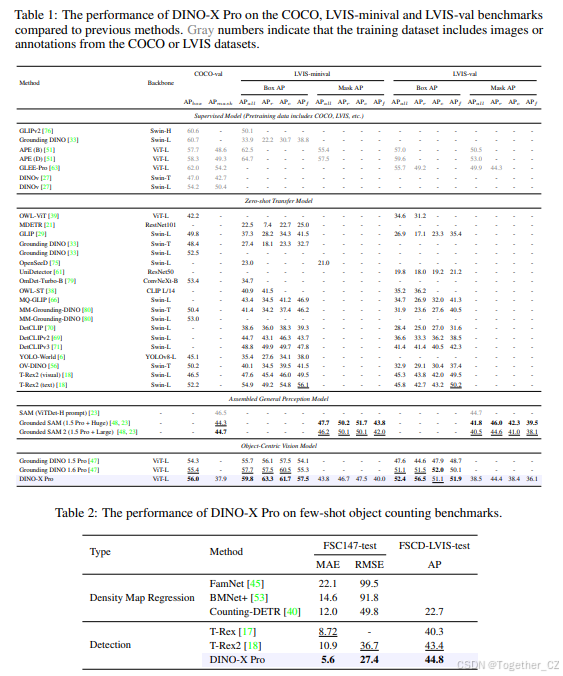
4.1.2 关键点检测
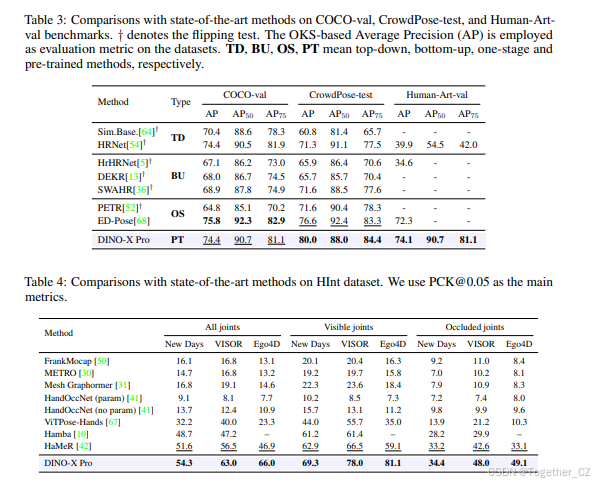
人体 2D 关键点基准评估:我们在 COCO [32]、CrowdPose [52] 和 Human-Art [20] 基准上对 DINO-X 与其他相关工作进行了比较,结果如表 3 所示。我们使用基于 OKS 的平均精度 (AP) [52] 作为主要指标。请注意,姿态头是在 MSCOCO、CrowdPose 和 Human-Art 上联合训练的,因此评估不是零样本设置。但由于我们冻结了 DINO-X 的骨干并仅训练姿态头,因此在目标检测和分割上的评估仍遵循零样本设置。通过在多个姿态数据集上进行训练,我们的模型能够有效预测各种人物风格的关键点,包括日常场景、拥挤环境、遮挡和艺术表现。虽然我们的模型在 AP 上比 ED-Pose 低 1.6(主要是由于姿态头中可训练参数的数量有限),但它在 CrowdPose 和 Human-Art 上分别超过了现有模型 3.4 AP 和 1.8 AP,展示了其在更多样化场景中的显著泛化能力。
人体手部 2D 关键点基准评估:除了评估人体姿态外,我们还在 HInt 基准 [42] 上展示了手部姿态结果,使用正确定位关键点的百分比 (PCK) 作为衡量标准。PCK 是用于评估关键点定位准确性的指标。如果预测的关键点与真实关键点之间的距离低于指定阈值,则认为该关键点正确。我们使用 0.05 框大小的阈值,即 PCK@0.05。在训练过程中,我们结合了 HInt、COCO 和 OneHand10K [59] 训练数据集(与 HaMeR [42] 方法相比的一个子集),并在 HInt 测试集上评估性能。如表 4 所示,DINO-X 在 PCK@0.05 指标上取得了最佳性能,表明其在高度准确的手部姿态估计方面的强大能力。
4.1.3 目标级视觉-语言理解
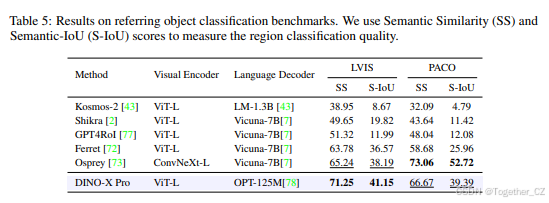
目标识别评估:我们在目标识别基准上验证了语言头的有效性,这些基准需要识别图像中指定区域的对象的类别。与 Osprey [73] 类似,我们使用语义相似度 (SS) 和语义 IoU (S-IOU) [8] 来评估语言头在目标级 LVIS-val [14] 和部分级 PACO-val [44] 数据集上的目标识别能力。如表 5 所示,我们的模型在 LVIS-val 数据集上达到了 71.25% 的 SS 和 41.15% 的 S-IoU,分别超过了 Osprey 6.01% 的 SS 和 2.06% 的 S-IoU。在 PACO 数据集上,我们的模型表现不如 Osprey。请注意,我们没有在语言头训练中包含 LVIS 和 PACO,并且我们的模型的性能是在零样本情况下实现的。在 PACO 上的较低性能可能是由于我们的训练数据与 PACO 之间的差异。此外,我们的模型只有 1% 的可训练参数,而 Osprey 则有更多。
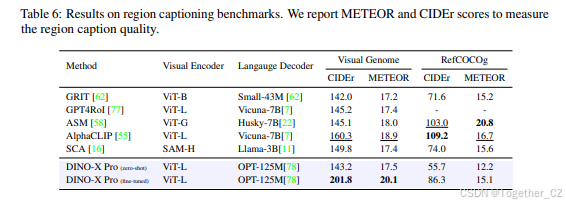
区域描述评估:我们在 Visual Genome [25] 和 RefCOCOg [37] 上评估了我们模型的区域描述质量。评估结果如表 6 所示。值得注意的是,基于冻结的 DINO-X 骨干提取的目标级特征,并且没有使用任何 Visual Genome 训练数据,我们的模型在 Visual Genome 基准上以零样本方式取得了 142.1 的 CIDEr 分数。此外,在 Visual Genome 数据集上进行微调后,我们仅使用轻量级语言头就取得了 201.8 的 CIDEr 分数,创下了新的最先进结果。
DINO-X Edge
零样本目标检测基准评估:为了评估 DINO-X Edge 的零样本目标检测能力,我们在 COCO 和 LVIS 基准上进行了测试,并在 Grounding-100M 上进行了预训练。如表 7 所示,DINO-X Edge 在 COCO 基准上大幅超过了现有的实时开放集检测器。DINO-X Edge 在 LVIS-minival 和 LVIS-val 上分别取得了 48.3 AP 和 42.0 AP,展示了其在长尾检测场景中的出色零样本检测能力。
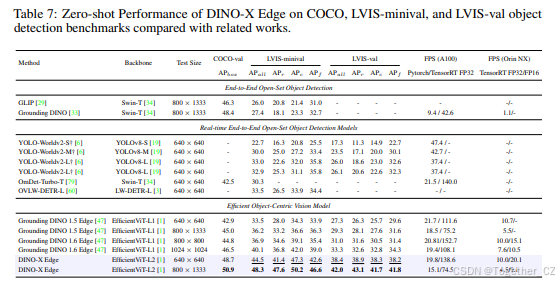
我们使用 FP32 和 FP16 TensorRT 模型在 NVIDIA Orin NX 上评估了 DINO-X Edge 的推理速度,以每秒帧数 (FPS) 衡量性能。PyTorch 模型和 FP32 TensorRT 模型在 A100 GPU 上的 FPS 结果也包括在内。?表示 YOLO-World 结果是使用最新官方代码复现的。
利用浮点乘法的归一化技术,我们可以将模型量化为 FP16 而不影响性能。在输入尺寸为 640x640 的情况下,DINO-X Edge 实现了 20.1 FPS 的推理速度,相比 Grounding DINO 1.6 Edge 的 15.1 FPS 提高了 33%。
5 案例分析与定性可视化
在本节中,我们可视化了 DINO-X 模型在各种现实场景中的不同能力。图像主要来源于 COCO [32]、LVIS [14]、V3Det [57]、SA-1B [23] 和其他公开资源。我们对他们的贡献深表感谢,这些贡献极大地惠及了社区。

开放世界目标检测
如图 5 所示,DINO-X 展示了根据给定文本提示检测任何目标的能力。它能够识别从常见类别到长尾类别以及密集目标场景的广泛目标,展示了其强大的开放世界目标检测能力。
长描述短语定位
如图 6 所示,DINO-X 展示了根据长描述中的名词短语定位图像中相应区域的令人印象深刻的能力。将详细描述中的每个名词短语映射到图像中的特定目标的能力标志着深度图像理解的重大进步。此功能具有重要的实用价值,例如使多模态大语言模型 (MLLMs) 能够生成更准确和可靠的响应。

开放世界目标分割与视觉提示计数
如图 7 所示,除了 Grounding DINO 1.5 [47],DINO-X 不仅支持基于文本提示的开放世界目标检测,还为每个目标生成相应的分割掩码,提供更丰富的语义输出。此外,DINO-X 还支持基于用户定义的视觉提示的检测,通过在目标对象上绘制边界框或点来实现。此功能在目标计数场景中展示了卓越的可用性。

无提示目标检测与识别
在 DINO-X 中,我们开发了一个高度实用的功能,称为无提示目标检测,允许用户在不提供任何提示的情况下检测输入图像中的任何目标。如图 8 所示,当与 DINO-X 的语言头结合时,此功能能够无缝检测和识别图像中的所有目标,而无需任何用户输入。

密集区域描述
如图 9 所示,DINO-X 可以为任何指定区域生成更细粒度的描述。此外,借助 DINO-X 的语言头,我们还可以执行基于区域的问答和其他区域理解任务。目前,此功能仍在开发阶段,将在我们的下一个版本中发布。

人体与手部姿态估计
如图 10 所示,DINO-X 可以通过关键点头根据文本提示预测特定类别的关键点。通过在 COCO、CrowdHuman 和 Human-Art 数据集上的训练,DINO-X 能够预测各种场景中的人体和手部关键点。

与 Grounding DINO 1.5 Pro 的并列比较
我们进行了 DINO-X 与之前最先进模型 Grounding DINO 1.5 Pro 和 Grounding DINO 1.6 Pro 的并列比较。如图 11 所示,基于 Grounding DINO 1.

5 的基础,DINO-X 进一步增强了其语言理解能力,同时在密集目标检测场景中表现出色。
6 结论
本文介绍了 DINO-X,这是一个强大的以目标为中心的视觉模型,旨在推动开放集目标检测和理解领域的发展。旗舰模型 DINO-X Pro 在 COCO 和 LVIS 零样本基准上创下了新纪录,展示了检测准确性和可靠性的显著提升。为了使长尾目标检测变得容易,DINO-X 不仅支持基于文本提示的开放世界检测,还支持基于视觉提示和自定义提示的目标检测,以适应定制场景。此外,DINO-X 将其能力从检测扩展到更广泛的感知任务,包括分割、姿态估计和目标级理解任务。为了在边缘设备上实现实时目标检测,我们还开发了 DINO-X Edge 模型,进一步扩展了 DINO-X 系列模型的实际应用。



















 215
215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











