




"Data hides truth, code finds the future."
2025 年 2 月 17 日,早上好 😸!欢迎来到本周的速据新知周刊 🎉!从大数据到 AI 大模型,从开源工具到教程案例,每一期,我们都致力于为您带来最前沿的行业技动态,以及那些改变世界的技术与故事。
封面揭晓

在大约三周前,摄影师在挪威的灵塞德(Lyngseidet)拍下了这张照片。这或许会是有史以来最大的一只蜂鸟。这一次极光非常明亮,以至于在蓝调时段(日落之后天空呈现深蓝色的一小段时间)也肉眼可见。
📢 行业动态与趋势
💾 大数据相关
国家数据集团终于要来了

据经济观察报从多个权威渠道独家获悉,国家即将组建国家数据集团,标志着数据要素市场化改革迈入深水区。
该集团将整合能源、交通等多领域数据资源,推动跨行业流通与共享,并引入 AI、区块链等技术构建安全交易机制。此前,贵州等地已探索成立地方数据集团,但面临数据孤岛、标准不一等挑战。国家数据局成立后,通过政策体系推动全国数据资源整合,新央企将承接顶层设计,破解数据分散化难题,加速市场化配置,预计撬动千亿级数据要素市场。
Apache StreamPark 正式从孵化器毕业[1]
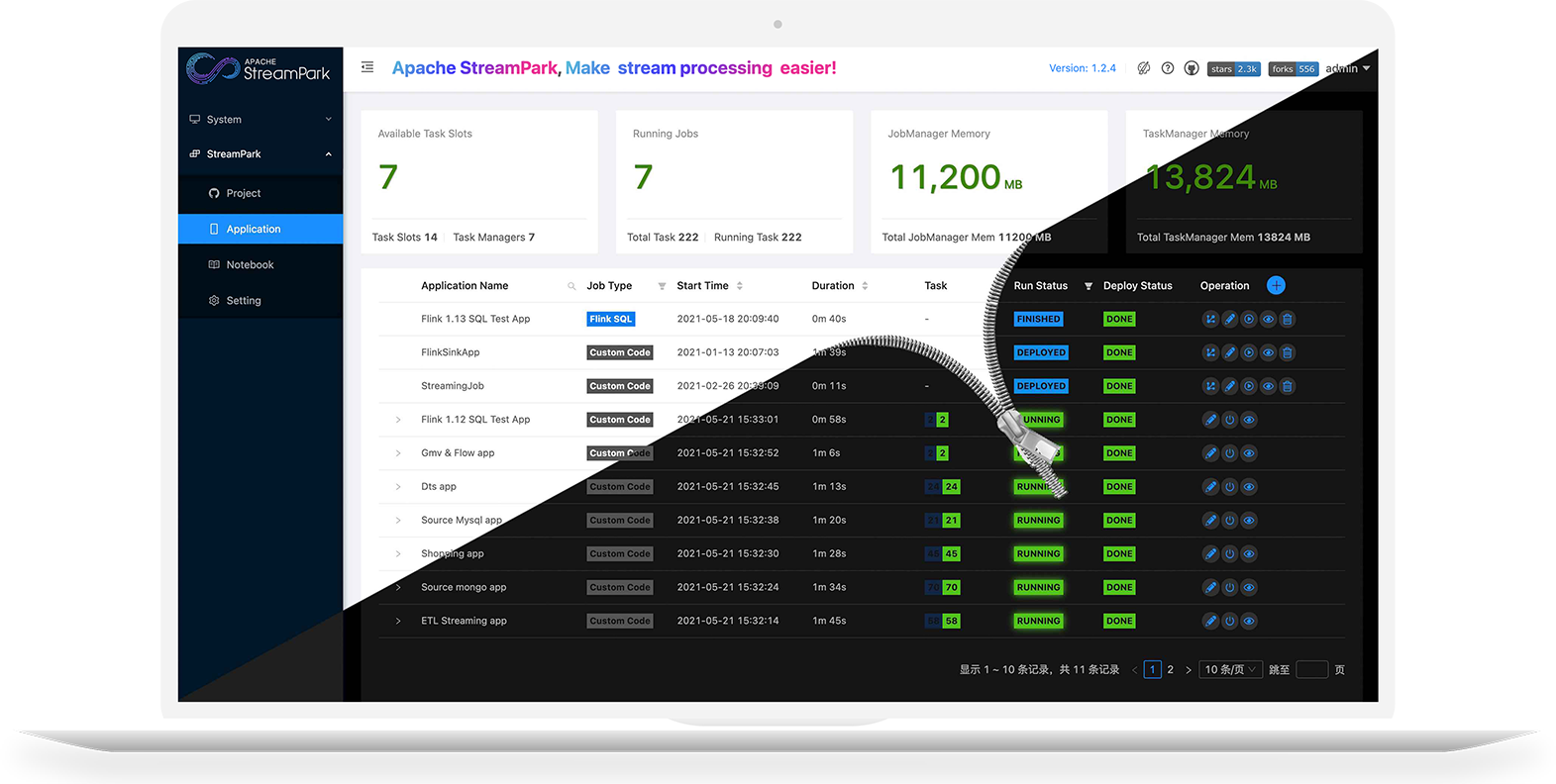
曾经的 streamX,经过两年多的努力,终于从 Apache 软件基金会孵化器毕业,成为顶级项目(TLP)。恭喜恭喜 🎉!
StreamPark 是最流行的开源流计算平台之一,拥有大量的用户和社区活跃度。另一个备受瞩目的流计算平台是 Dinky,也在近期发布了 1.2.1 版本。
Dinky 1.2.1 正式发布[2]

Dinky 1.2.1 更新来啦!新增支持 CALL 语句和 K8S 的 Ingress 功能,修了一堆 bug:比如 Flink Jar 提交异常、全局变量解析失效、血缘分析失败等问题。优化了脚本执行逻辑、暗夜主题的血缘展示、Docker 镜像构建,还调整了文档错误和快速体验指南。
Apache Paimon 1.0.1 发布[3]

这个版本主要是给 1.0.0 打补丁,引入 Catalog 相关的一些生态、加强了快照提交、提升了 Lookup 性能、优化主键表的存储。
🤖 AI 相关
微信正式灰度测试接入 DeepSeek
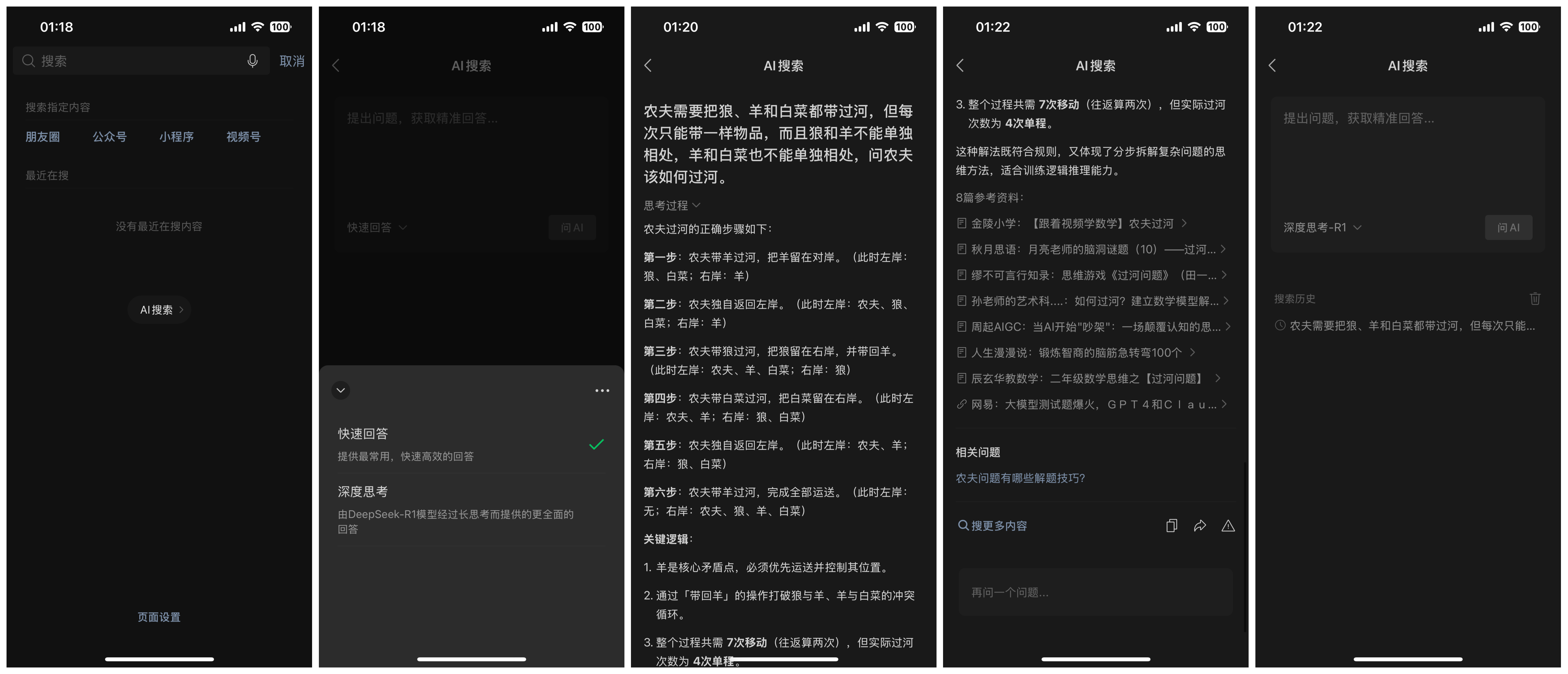
2 月 16 日,微信搜索上线“AI 搜索”功能,并接入 DeepSeek-R1 满血版,支持深度思考,展示思考过程、最终结果、引用链接、相关问题等内容;还支持历史记录。
体验了一下,确实是满血版的,我是经常使用搜一搜的,AI 搜索的加入让体验更上一层楼,希望后面不会“服务器繁忙,请稍后再试”。
VideoWorld 模型正式开源[4]
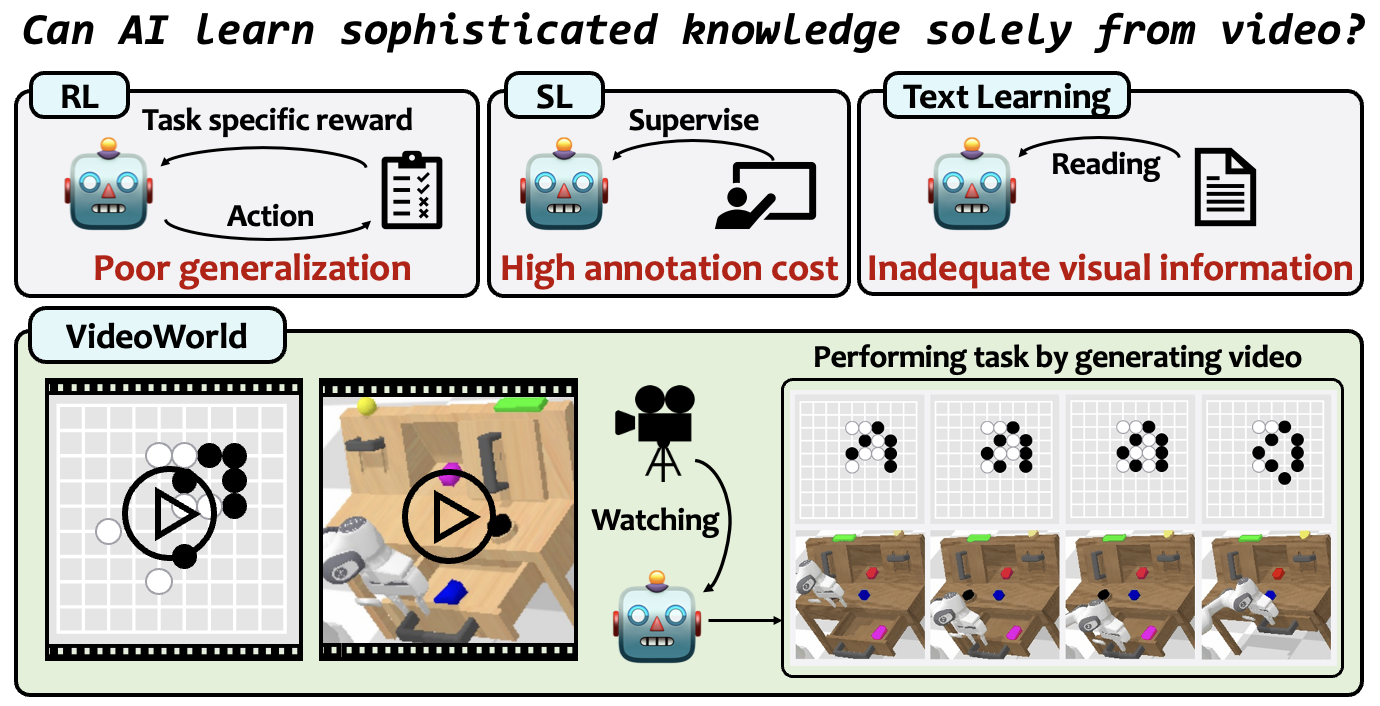
2 月 10 日,豆包 VideoWorld 开源啦!它是业内首个纯靠视觉信号学习推理的 AI 模型,不像 Sora、DALL-E 那些得靠文字标签,它能自己看视频学东西,理解世界更接近人类直觉。具有扩展到自动驾驶和智能监控等应用的潜力。
仅用 1.5b 参数,在流行的数学测试上打败 openai o1-preview[5]
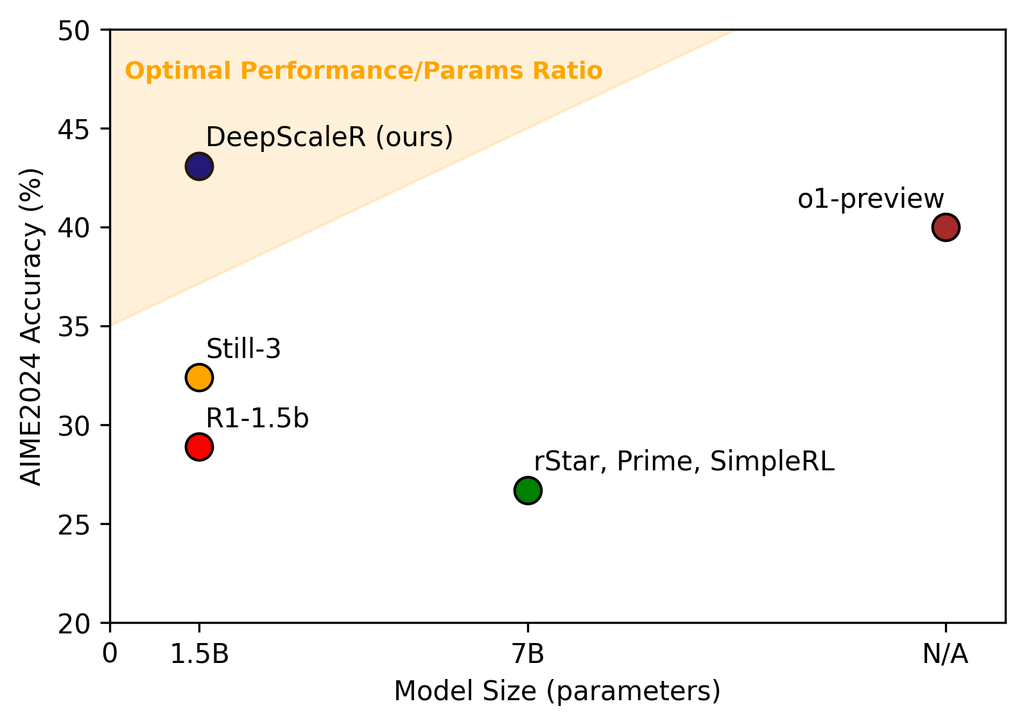
它介绍了一个 1.5B 参数的模型如何通过强化学习(RL)超越了传统的 O1 Preview 方法。文章深入探讨了如何通过扩展 RL 技术来提升模型的性能和效率,特别是在处理复杂任务时表现出色。
这种方法不仅提高了模型的准确性,还优化了资源利用,可以说是突破了「参数越大越牛」的魔咒,这或许是未来大模型的发展方向之一。
👾 工具与开源项目推荐
NPS[6]
一款轻量级、高性能的内网穿透工具。它简单易部署,分为服务端和客户端,提供友好的 Web 界面,支持多种协议,像 TCP、UDP 、HTTP、HTTPS 等。
如果你经常需要远程办公或者搭建个人服务,nps 可以提供很大帮助。
mermaid.live[7]
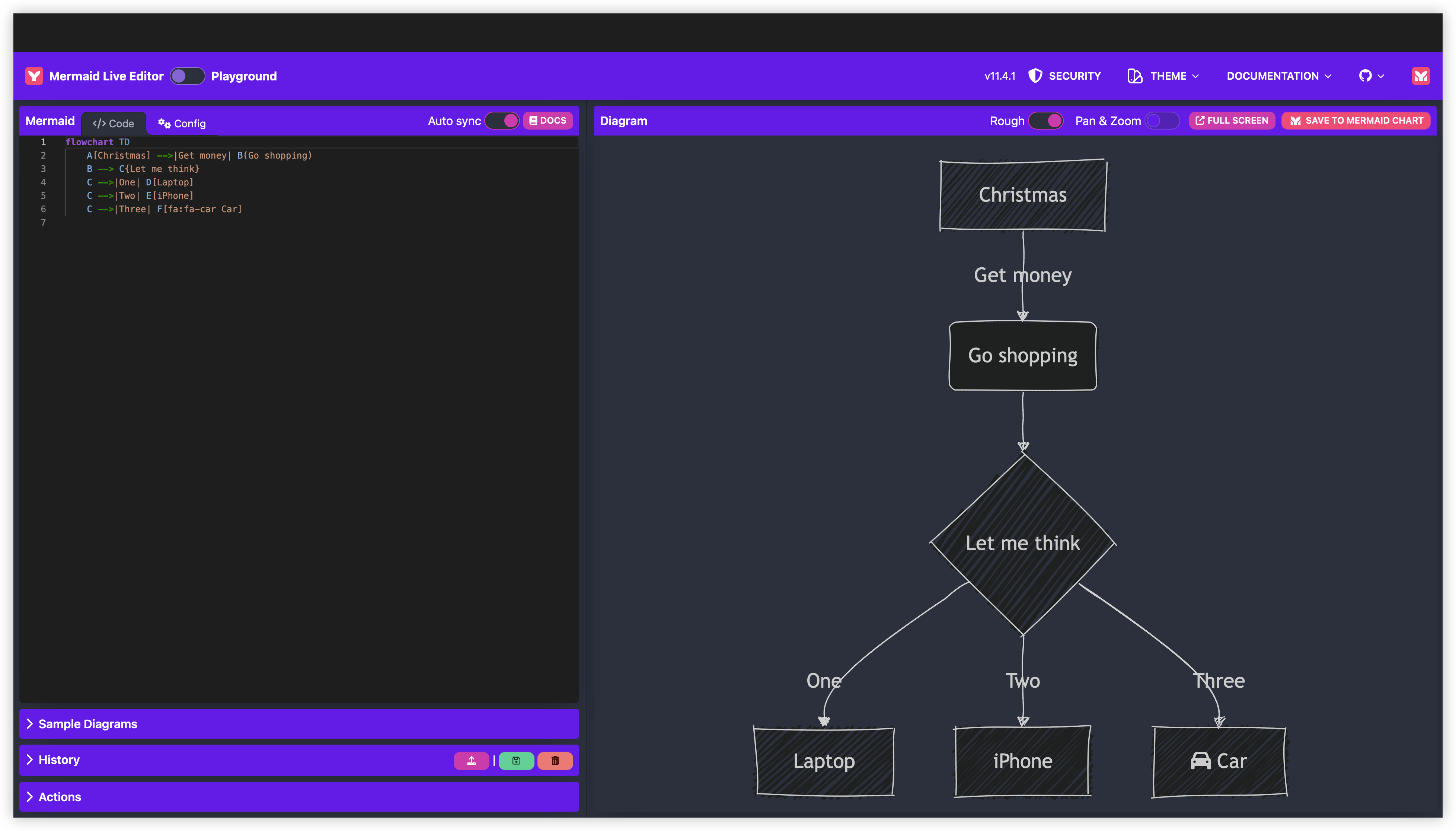
一个在线 Mermaid 语法的图表编辑器,支持流程图、序列图、甘特图等多种类型。这种语法可以在大多数 markdown 编辑器中使用,微信公众号编辑器是不行的。经常需要画流程图的朋友,应该会用到它。
screenshot-to-code[8]
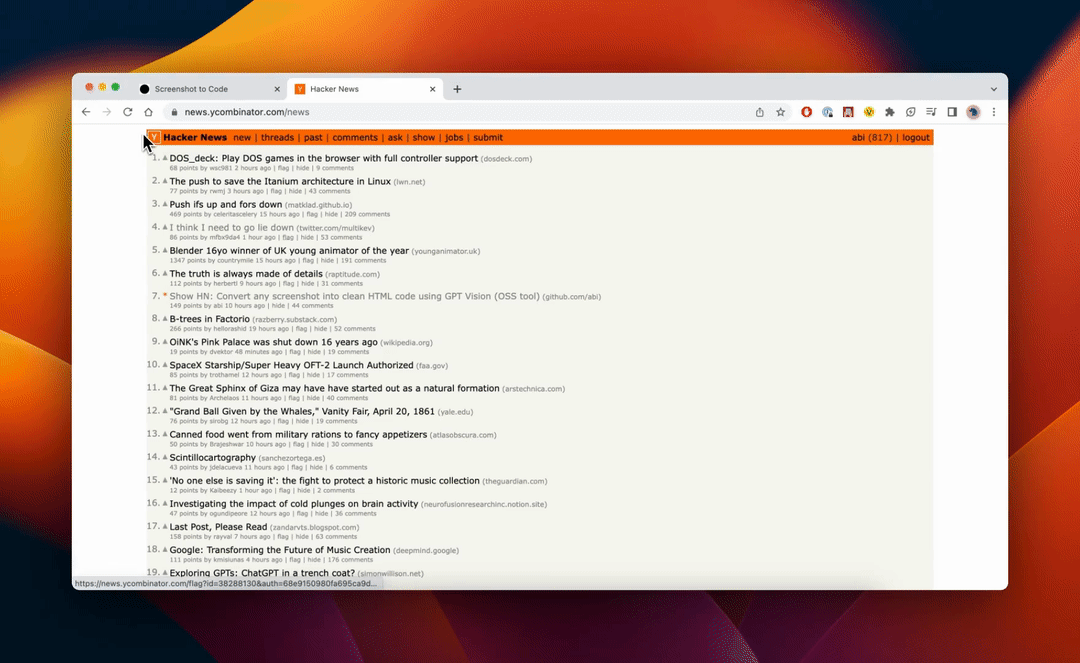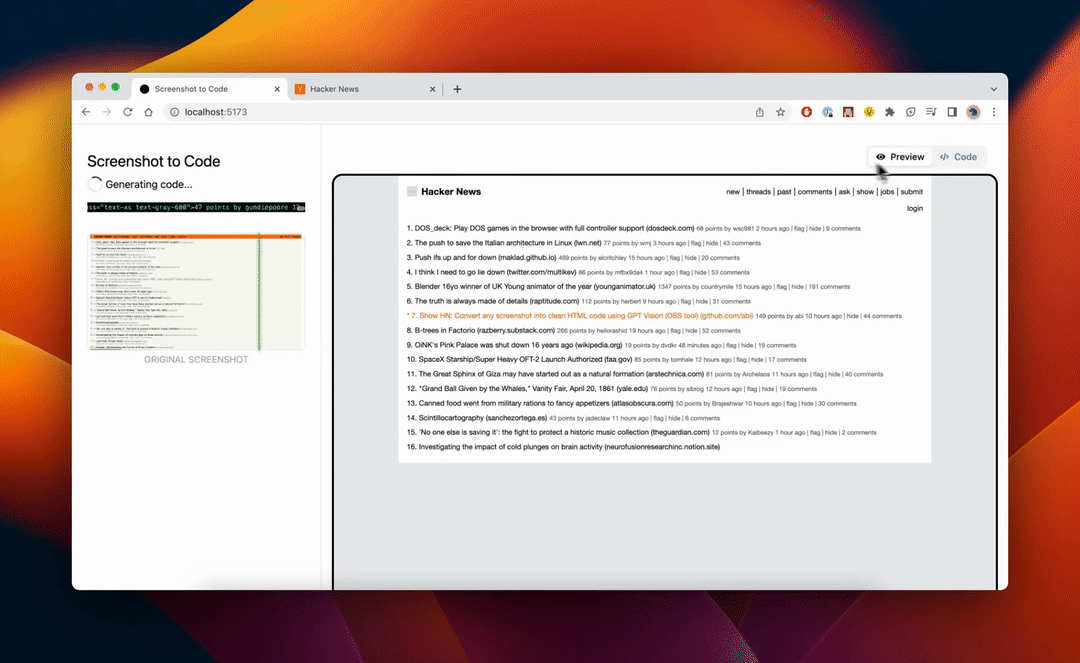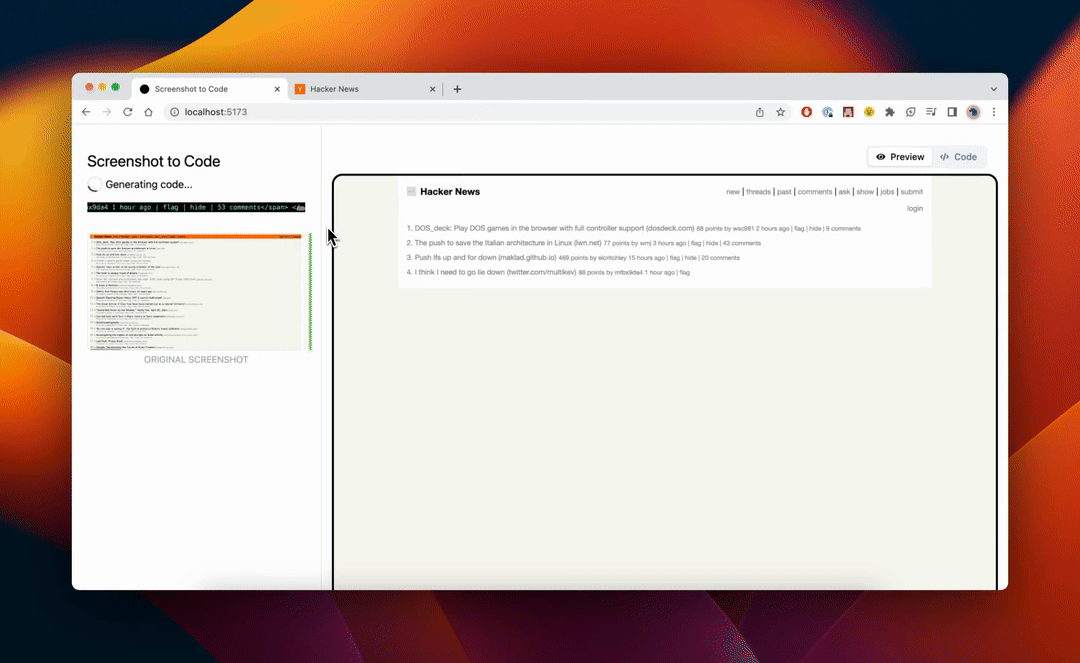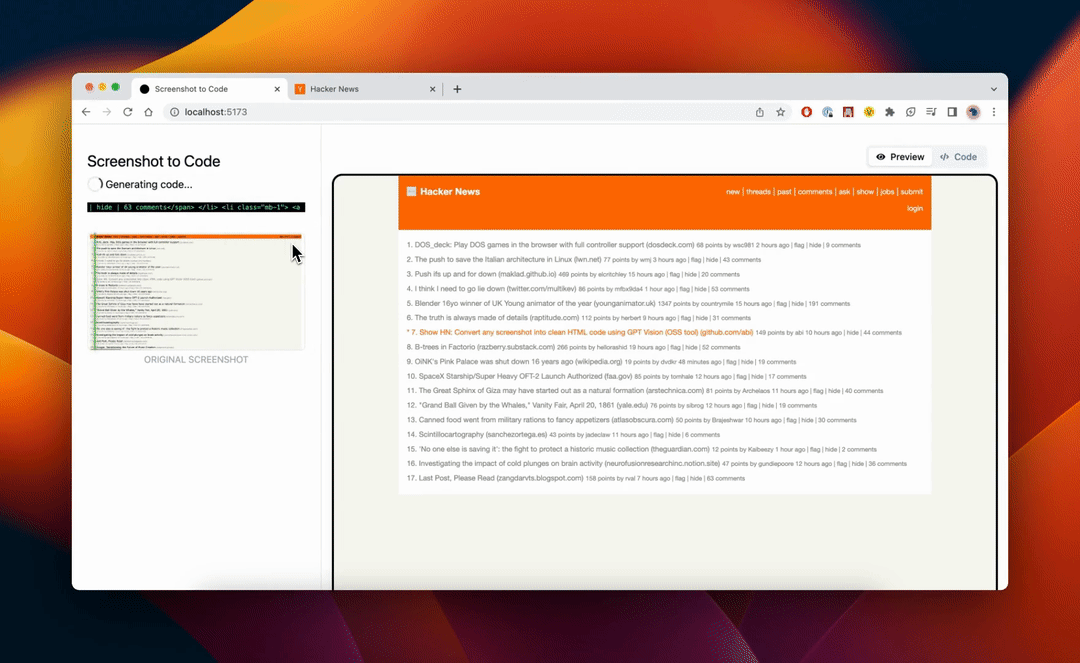
截图即可生成前端:github 上 68.3K stars 项目,有了它,构建 HTML 仅需两步
-
上传截图 -
AI 将逐步构建 HTML,通过反复将生成的代码与屏幕截图进行比较来迭代改进生成的代码。
🤓 教程与实战案例
Apache Kafka 和 Flink 数据流如何驱动金融服务领域十大创新[9]

这篇文章主要讲了 Apache Kafka 和 Flink 这两个工具如何帮助金融机构实时处理数据,从而支持十大创新应用,比如欺诈检测、个性化客户体验和风险管理。看完这 10 个例子,可以大概清楚如何通过实时数据流,银行和金融公司更快地做出决策,提升效率,同时降低成本。
腾讯大数据基于 StarRocks 的向量检索探索[10]
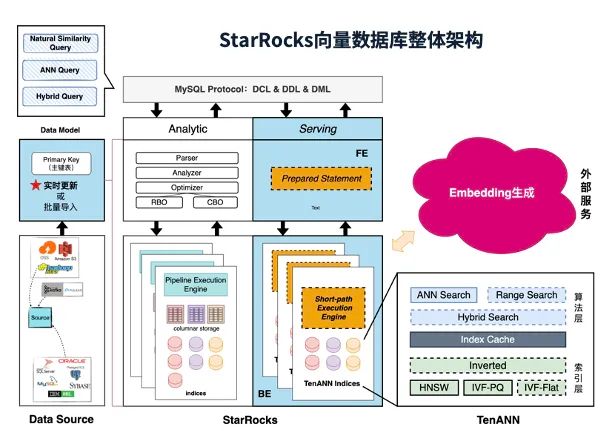
StarRocks 年度峰会上展示了如何用这个数据库玩转向量检索技术,简单来说就是把高维数据(比如图片特征、推荐标签)的搜索速度直接拉满!比如原本要 15 秒的查询,优化后只要 2 秒,成本还降低了三分之二!
meta 的数据血缘处理能给我们带来什么启发[11]
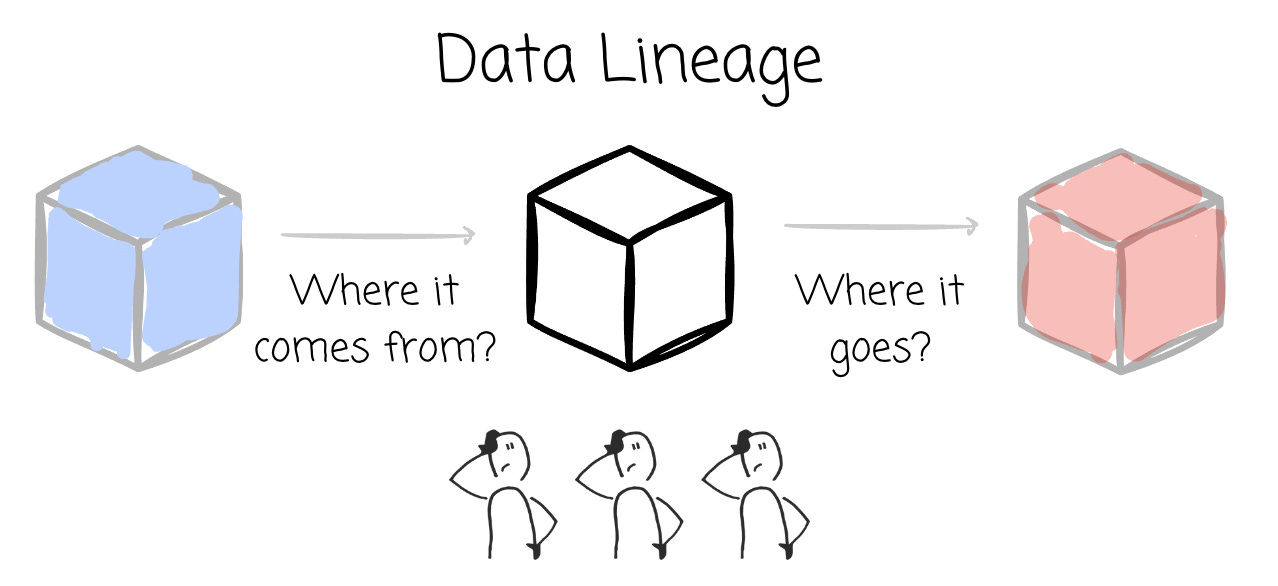
文章主要讲了 Meta 如何通过构建一个高效的数据血缘系统来追踪数据的来源、流转和使用情况。他们利用自动化工具和分布式架构来处理海量数据,确保数据在整个生命周期中的透明性和可追溯性。这不仅帮助 Meta 更好地管理数据质量,还支持了合规性和故障排查。
如果你正在进行数据治理或是感兴趣,这篇文章应该对你有所帮助。
📚️ 文摘
“一个清晰明确的目标是成功的关键,但仅有清晰还不够,目标还必须具有可行性。过于模糊的目标,如‘我要变得更好’,缺乏明确的行动方向,难以指导我们的行为。而不切实际的目标,比如一个从未运动过的人计划一个月内跑完马拉松,虽然清晰却无法实现,容易导致挫折感和放弃。理想的目标应该是在清晰明确的同时,基于自身实际情况,具有一定的挑战性但又切实可行。” --《如何达成目标》(Succeed: How We Can Reach Our Goals)
定目标也是一门学问。日常定目标时,或含糊不清,不知道到底要干啥;或好高骛远,根本不考虑自己能不能做到。或者想着一下子就完成特别难的事,最后发现根本做不到,就容易灰心不干了。
所以定目标时,要确定目标是不是自己努努力就能够实现的,能实现才有奔头,也更容易成功。
🔥 本周话题
数据显示,1 月 20 日 0 时至 2 月 8 日 24 时,有 2,009.2 万名消费者申请了 2,541.4 万件手机等数码产品购新补贴。
你参与这次新国补了吗?买了什么?欢迎到评论区讨论与推荐 🫣
😂 开心一下

欢迎关注Wechat:DataSpeed
Apache StreamPark 正式从孵化器毕业: https://github.com/apache/streampark
[2]Dinky 1.2.1 正式发布: https://dinky.org.cn/download/dinky-1.2.1/
[3]Apache Paimon 1.0.1 发布: https://paimon.apache.org/releases/1.0.1
[4]VideoWorld 模型正式开源: https://maverickren.github.io/VideoWorld.github.io/
[5]仅用 1.5b 参数,在流行的数学测试上打败 openai o1-preview: https://pretty-radio-b75.notion.site/DeepScaleR-Surpassing-O1-Preview-with-a-1-5B-Model-by-Scaling-RL-19681902c1468005bed8ca303013a4e2
[6]NPS: https://github.com/ehang-io/nps/
[7]mermaid.live: https://mermaid.live/
[8]screenshot-to-code: https://github.com/abi/screenshot-to-code
[9]Apache Kafka 和 Flink 数据流如何驱动金融服务领域十大创新: https://www.kai-waehner.de/blog/2025/02/09/how-data-streaming-with-apache-kafka-and-flink-drives-the-top-10-innovations-in-finserv/
[10]腾讯大数据基于 StarRocks 的向量检索探索: https://forum.mirrorship.cn/t/topic/17396
[11]meta 的数据血缘处理能给我们带来什么启发: https://vutr.substack.com/p/how-meta-solves-data-lineage-at-scale


















 3403
3403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











