




目录
1、索引为啥提高查询效率
创建测试表
CREATE TABLE users (
id INT PRIMARY KEY,
username VARCHAR(255),
email VARCHAR(255)
);
存储过程
DELIMITER //
CREATE PROCEDURE InsertTestData()
BEGIN
DECLARE counter INT DEFAULT 1;
DECLARE username VARCHAR(255);
DECLARE email VARCHAR(255);
WHILE counter <= 100000 DO
SET username = CONCAT('user', counter);
SET email = CONCAT('user', counter, '@example.com');
INSERT INTO users (id, username, email) VALUES (counter, username, email);
SET counter = counter + 1;
END WHILE;
END//
DELIMITER ;
CALL InsertTestData();
查询索引没加的查询时间
select * from users where username='user5';
给username添加索引
alter table users add index idx_username(username);
再查看执行时间
select * from users where username='user5';
索引就像一本书的目录
二分查找法(假如把数分成两段,每次判断查找数与中位数对比然后再分两段后再对比每段的中位数)
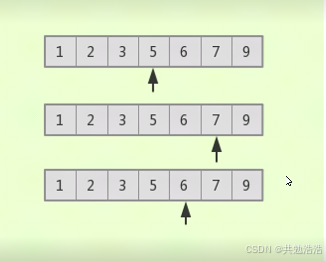
二叉树
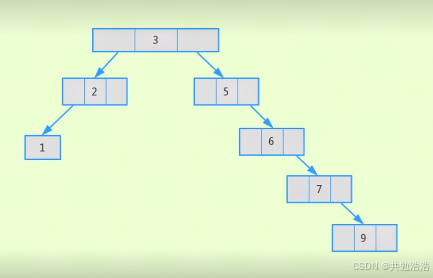
平衡二叉树(缺点,每个节点只有两个分支)
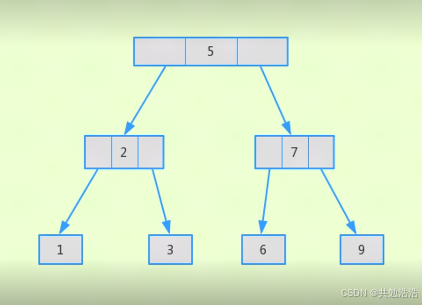
B树
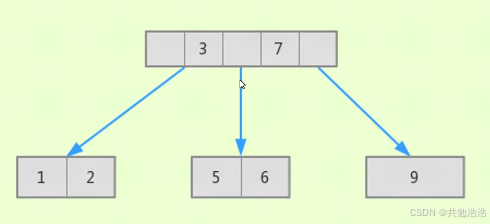
B+树
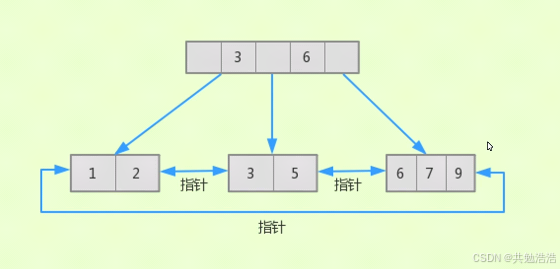
B+树索引特点
由B+树发展而来
高度一般在2~4层
MySQL的B+树索引不能找到一个给定键值的具体行
为什么索引能提高查询效率
减少数据扫描范围、提供有序数据、加速排序和分组操作、提高唯一性约束的检查速度、支持快速分页的操作。
2、MySQL索引类型
聚集索引特点:
聚集索引就是按照每张表的主键构造一颗B+树,
innodb的主键一定是聚集索引,
每张表只能有一个聚集索引,
辅助索引特点:
辅助索引的叶子结点并不会放整行数据,
辅助索引先查到主键,再通过聚集索引查找到行数据,
一个高度为3的辅助索引树查找记录需要至少6次逻辑IO.
唯一索引特点:
数据唯一性
唯一索引的更新不能使用change buffer
(唯一索引要求表中的每一行数据在该索引列上的值必须是唯一的,不允许有重复值。这意味着在对唯一索引进行更新操作时,数据库需要立即检查新值是否违反唯一性约束。
Change Buffer 主要用于缓存对非唯一二级索引的写操作,当对非唯一索引进行插入、删除或更新操作时,InnoDB 存储引擎会将这些操作先记录在 Change Buffer 中,而不是立即更新索引页。
这样做的目的是为了减少磁盘 I/O 操作,提高性能。在未来的某个合适时机,当需要访问相关数据或者数据库进行合并操作时,再将 Change Buffer 中的记录合并到实际的索引页中。)
联合索引
多个字段创建的索引
比如a、b、c三个字段号创建的联合索引,可以单独查a、ab可能走索引,但单独查b或bc不走联合索引
前缀索引
某个字段有较长,只把前一段创建成索引,例如(char,varchar字段太长)
创建
alter table users_info add index idx_email_2(email(2));
全文索引
全文索引是对文本内容进行分词处理,将文本拆分成一个个单词或词组,并建立这些单词或词组与包含它们的行之间的对应关系,从而能够快速地查找包含特定单词或词组的文本记录,主要用于在大量文本数据中进行快速的全文搜索。
再创建一张测试表 use martin; CREATE TABLE `index_test` ( `id` int NOT NULL AUTO_INCREMENT, `a` int NOT NULL, `b` char(2) NOT NULL, PRIMARY KEY (`id`), KEY `idx_a` (`a`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; insert into index_test(a,b) values (1,'a'),(2,'b'),(3,'c'),(5,'e'),(6,'f'),(7,'g'),(9,'i'); 查询所有数据 select * from index_test; 条件查询 select * from index_test where a=3; 他先通过a字段上的索引树,得到主键id=3,再得到id的聚集索引树上找到对应的行数据。 而下面这条SQL select * from index_test where id=3; 查询到的结果是一样的,而执行过程则只需要搜索id 的聚集索引树。我们能看出辅助索引的查询比 主键查询多扫描一颗索引树,所以,我们应该尽量使用主键做为条件进行查询。 建表时添加辅助索引 在建表的时候,我们可以添加好索引,比如 CREATE TABLE users_info ( id INT auto_increment PRIMARY KEY, username VARCHAR(255), email VARCHAR(255), key idx_username(username) );
3、执行计划分析
测试数据
CREATE DATABASE martin; /* 创建测试使用的database,名为martin */ use martin; /* 使用martin这个database */ drop table if exists t1; /* 如果表t1存在则删除表t1 */ CREATE TABLE `t1` ( /* 创建表t1 */ `id` int NOT NULL auto_increment, `a` int DEFAULT NULL, `b` int DEFAULT NULL, `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间', `update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '记录更新时间', PRIMARY KEY (`id`), KEY `idx_a` (`a`), KEY `idx_b` (`b`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; drop procedure if exists insert_t1; delimiter ;; create procedure insert_t1() begin declare i int;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











