






主从数据库
概念
主从数据库是一种数据复制技术,它允许将一个数据库服务器作为主库,将其中的数据自动同步到一个或者多个其他数据库服务器中(从库)。
工作场景
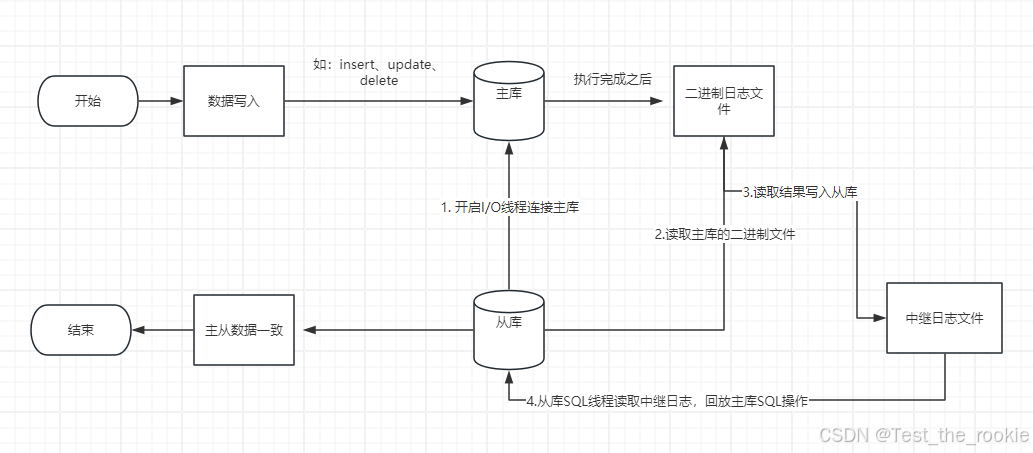
【主库】
作用:主数据负责处理所有的写操作,如 insert、update、delete。
特点:主库唯一,是数据的唯一来源,保证数据一致性。
过程:主库执行完写操作之后,它会将操作记录到一个**“二进制日志”的文件中。
【从库】
作用:负责处理大部分读操作,如select,作为主库的备份库,当主库服务器故障时,从库可以立即转为一个新的主库。
特点:从库可以有多个,用于分担数据读取过程中的负载。
过程:从库会启动一个I/O线程**,连接到主库。请求并接收主库的二进制日志;从库将接收到的日志内容写入到自己的中继日志文件中;从库的SQL线程会读取中继日志,并重新执行其中记录的SQL操作。从而使数据与主库保持一致。
【大致流程】
读写分离
概念
读写分离式在主从数据库架构的基础上,通过一定的规则将应用程序的读请求、写请求分别发送到不同数据库服务器上。
写请求:全部分发到主库;
读请求:分发到一个或者多个从库。
读写分离的作用
如果所有的请求全部打到一个数据库上,很容易造成性能瓶颈。而读写分离能够将请求分别发送到不同的服务器上,从而实现了负载分摊;主库主要执行写操作,从库执行读操作,避免读写锁竞争,进一步提升数据库性能。
如何读写分离
【应用层实现】
写连接:配置为主库地址。
读连接:配置为从库地址。
框架支持:使用框架内置的插件实现。
优点:实现简单,可控性强。
缺点:业务代码耦合性强,数据库架构变更需要修改代码。
【中间件实现】
在应用程序与数据库集群之间,引入数据库中间件。中间件来负责SQL语句的解析以及路由:如果是写操作,则路由到主库,如果是读操作则路由到从库。
优点:代码耦合性低,变更之后应用程序无需修改代码。
缺点:引入了中间件,如果中间件异常则会导致整个读写操作崩溃;在一定程度上增加了维护的成本。
主从复制与读写分离的优缺点
优点
- 提升数据库性能:通过增加从库数量,能够提高数据的读操作的速度,可以拓展数据库的读能力。
- 数据备份与高可用:如果主库服务宕机,从库可以直接升为主库,减少系统停机时间。
- 避免读写锁竞争:主库写,从库读,读写操作发生在不同的数据库中,不会出现读写锁竞争。
- 便于数据分析:在从库执行大量读操作进行数据分析时,不会影响主库的的写入操作。
- 提升用户体验:将读库部署到离用户更近的位置,可以在一定程度上降低网络延迟。
缺点
6. 数据延迟:读写分离是异步任务,会出现微小的时间差。这可能会导致主库已完成数据写入,但是在从库读取数据时,可能无法获取到主库写入的数据。
7. 数据不一致:如果出现网络问题或者从库服务宕机,会导致主库与从库数据出现较大的差异。
8. 主库写入瓶颈:因为写入操作全是主库在处理,所以频繁出现大量写入操作时,主库可能出现性能瓶颈,从而影响系统性能。
常见问题
问:什么是MySQL的主从复制和读写分离?它们在架构中主要解决了什么问题?
答:
主从复制实际上就是一个数据复制的过程:一个库作为主库,主要执行写操作;其他的库作为从库执行读操作。主库执行完写入操作之后,从库会实时的将从主库复制主库的数据变更,使从库的数据与主库保持一致;
读写分离是一种程序控制机制,通过一定的规则分别将读、写请求路由到不同的数据库服务器,从而实现读写分离。
主要解决了性能问题、数据高可用的问题。
性能问题:从库主要负责处理读任务,主库负责写任务,避免了读写锁竞争;并且从库可以有多个,降低资源负载。
数据高可用:当主库宕机之后,从库可以切换为主库,降低因主库宕机导致系统不可用的时间。
问:在主从架构中,一个"写"操作从发起到最后在从库上能被读到,大致经历了怎样的过程?
答:
1.主库在执行一个写操作之后,如insert操作,会将其写入一个二进制日志文件中;
2.从库开启I/O线程连接主库,并且读取主库的二进制文件,并将读取的内容写入中继日志文件中;
3.从库开启SQL线程回放执行中级日志文件中的SQL;
4.此时在从库查询主库插入的数据,则可以获取到对应结果。
问:什么是"主从延迟"?它主要是由什么原因引起的?
答:
主从延迟是主库执行写入操作之后,由于从库从主库同步数据时是一个异步任务,(主从复制过程)。这个过程会消耗一定的时间,从而导致在从库无法立即查到主库的写入的数据。
可能导致主从延迟的原因:
1. 网络延迟
2. 主库执行了大事务(一次性更新了大量的数据)
3. 从库资源负载过大,性能降低
4. 从库硬件低于主库,导致重放日志的速度跟不上主库写入的速度
5. 主库执行了一个时间很长但是未能提交的事务,造成二进制日志文件未能及时清理,导致从库回放日志效率降低
6. 从库的SQL线程是一个单线程,如果主库存在大量并发写入,从库只能串行执行日志回放操作,导致堆积
问:假设公司刚部署好一套主从分离的数据库,现在需要你来进行测试。你的主要测试目标会包括哪些方面?
答:
1. 数据同步是否正常
2. 从库读取的数据是否与主库一致
3. 主从延迟是否在接受的范围
4. 主库宕机之后,从库切换为主库后,主库写、从库读功能是否正常
5. 在一定并发写入的情况下,从库能否正常同步数据
问:如何设计和执行测试用例,来验证"数据确实从主库同步到了从库"?
答:
- 在主库执行一个写操作(insert、delete、update),执行成功之后,去从库查询,检查对应的数据是否更新
- 在主库执行一个事务更新数据,执行成功之后,去从库查询,检查对应的数据是否更新
- 在主库执行一个事务更新数据,执行后不提交,去从库查询,检查对应的数据是否更新
- 针对各种数据类型进行写操作,如NULL值、超长字符串、二进制数据(如图片、文件)、时间戳、枚举类型等。
- 在主库执行大批量的INSERT(如一次性插入1万条数据),验证从库数据是否一致。
问:除了简单的CRUD同步,你会设计哪些边界或异常用例来发现更深层次的数据不一致问题?
答:
1. 在主库开启一个事务,执行多条相关的INSERT和UPDATE,然后提交。观察从库是否要么全部应用,要么全部不应用,即保持事务的原子性。
2. 主库执行一个事务,但在提交前故意制造一个错误使其回滚。验证从库不会同步这个未提交的事务。
3. 模拟主库因某种原因(如插入失败)导致自增ID不连续,观察从库的自增ID是否能与主库保持一致。这是为了测试auto_increment机制的同步。
4. 在主库上执行ALTER TABLE语句(如增加、删除、修改列)。验证从库是否能平滑地同步表结构变更,并且在此过程中,对表的DML操作(增删改)不会丢失或错乱。
5. 同步包含TEXT, BLOB等大字段的数据。同步包含特殊字符(如emoji)的数据,确保主从库的字符集配置一致,不会出现乱码。
6. 执行包含NOW(), UUID(), RAND()等函数的SQL。例如 INSERT INTO log (msg, created_at) VALUES (‘test’, NOW())。由于主从执行的时间点或上下文不同,这些函数的结果可能不同。需要验证同步机制是否能正确处理,或者是否应该禁止这类SQL。
问:如何测试和量化"主从延迟"?如果发现延迟很大,你会从哪些方面向开发或DBA提供排查线索?
答:
- 在主库执行一个写入带有时间戳的数据。写入成功之后,在从库查询。对比两个时间戳的差值。
排查线索:
主从库资源配置差异、网络、从库服务器资源负载提供排查线索
问:现在模拟一个故障场景:主数据库突然宕机。作为测试人员,你需要关注系统的哪些行为?预期的正确结果应该是什么?
答:
1. 写操作:新的写请求应该立即收到明确的错误(如连接失败),或者进入等待队列(取决于中间件策略),而不是返回成功但数据丢失。
2. 读操作:读请求可能还能从从库正常返回(但数据是旧的),也可能全部失败。
3. 用户体验:前端应用是否会显示友好的错误提示?是否会卡死?
4. 自动切换:如果架构包含中间件或MHA等工具,观察是否能自动将一个从库提升为新主库,以及这个过程耗时多久。
5. 如果是手动切换,记录下从发现故障到完成切换的总时间(RTO)
6. 换后,新的主库必须包含原主库宕机前已成功提交的所有事务,不能有数据丢失
7. 当新主库上线后,应用程序的写请求是否能自动或经配置后恢复到新主库?
8. 当原主库修复后,重新作为从库加入集群,它的数据是否能正确地从新主库同步回来?
问:当一个新的从库被添加到集群中时,你需要测试哪些内容来确保它正常工作?
答:
1.验证新从库在完成初始数据全量同步后,其数据与主库是完全一致的。需要对比关键表的记录数和抽样内容。
2.在主库进行持续的、多种类型的写操作,观察新从库是否能实时、准确地同步这些变更。
3.执行 SHOW SLAVE STATUS\G,确保 Slave_IO_Running 和 Slave_SQL_Running 都是 Yes,并且没有报错。
4.验证读写分离中间件(如MyCat, ProxySQL)或应用程序配置,已经正确识别并开始将读流量分发到这个新从库。通过监控或日志,确认有新从库的读QPS。
5.如果有多台从库,验证读请求是否按照预设的负载均衡策略(如轮询、权重)被合理地分配到了所有从库(包括新加入的这台)。
6.在刚加入和后续运行期间,持续监控新从库的复制延迟,确保其稳定在正常范围内。
问:在测试读写分离环境时,你会使用哪些工具或命令来辅助你?
答:
1. SHOW SLAVE STATUS\G:这是最重要的命令,用于检查复制状态、延迟、错误信息。
2. SHOW PROCESSLIST:查看数据库当前正在执行的线程,判断是否有慢查询或阻塞。
3. SHOW MASTER STATUS:查看主库当前的二进制日志位置。
4. 如MySQL Workbench、DBeaver、Navicat。用于方便地同时连接主库和多个从库,快速执行SQL和对比查询结果。
5. Prometheus + Grafana:用于监控和可视化 Seconds_Behind_Master、数据库连接数、QPS、TPS等关键指标,建立仪表盘。
6. pt-table-checksum:Percona Toolkit中的一个著名工具,可以自动检查主从数据的一致性。


















 3345
3345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









