




 本文详细介绍了深度学习中的优化方法,包括Stochastic Gradient Descent(SGD)、Momentum、NAG、AdaGrad、RMSProp、AdaDelta以及Adam。通过这些方法,可以加速学习过程,减少训练震荡,适应不同的学习率需求。在实际应用中,Adam优化器由于其优秀的表现,已成为深度学习模型训练的首选。
本文详细介绍了深度学习中的优化方法,包括Stochastic Gradient Descent(SGD)、Momentum、NAG、AdaGrad、RMSProp、AdaDelta以及Adam。通过这些方法,可以加速学习过程,减少训练震荡,适应不同的学习率需求。在实际应用中,Adam优化器由于其优秀的表现,已成为深度学习模型训练的首选。

深度学习常用的优化方法
参考资料:《Deep Learning》、pytorch 文档
深度学习中,优化算法的 目标函数 通常是一个基于训练集的损失函数,优化的目标在于降低训练误差。
这意味着用训练集上的 经验分布 代替 真实分布。
最小化这种平均训练误差的训练过程,被称为经验风险最小化(empirical risk minimization)
1.Stochastic Gradient Descent
虽然是讲随机梯度下降,但是还是也介绍一下 梯度下降的3兄弟:
●批量梯度下降(Batch Gradient Descent):使用整个训练集的样本,通常是能到达局部最小点的。
●随机梯度下降(Stochastic Gradient Descent):每次只使用单个样本,也被称为online(在线)算法;
会向着局部最小逼近,但是最终无法到达局部最小点
●小批量梯度下降(Mini-Batch GraMini-Batchdient Descent):每次使用一个以上而又不是全部的训练样本
深度学习中一般都是采用的小批量(Mini-Batch)梯度下降,通常简单的将它们称为随机(Stochastic),具体实践中,通常将mini-batch的大小设置为 2的整数次方,例如 2、4、8、16...
算法如下:
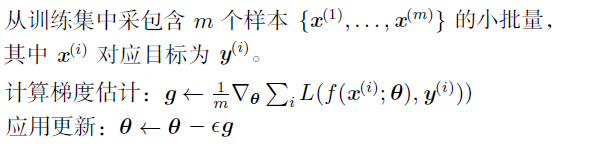
使用SGD算法,最主要的就是要选择合适的Batch_Size,
a. 内存利用率提高了,大矩阵乘法的并行化效率提高。
b. 在一定范围内,一般来说 Batch_Size 越大,其确定的下降方向越准。
pytorch 上有此优化器模块,torch.optim.SGD
2.Momentum 动量
是对随机梯度下降算法的一种优化,目的是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









