




一、哈希表的介绍
哈希表的关键在于哈希函数。哈希函数的作用是将给定的键(key)映射到一个数组索引(即哈希值)。哈希函数应该是确定性的,也就是说相同的输入应该总是产生相同的输出。哈希函数的设计非常重要,因为它影响哈希表的性能。
典型的哈希函数可能是:
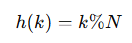
其中 k 是键,N 是哈希表的大小。
哈希冲突
哈希冲突是指两个不同的键经过哈希函数计算后,得到相同的哈希值。由于哈希表是一个数组,它的大小是有限的,因此不可避免地会有冲突发生。
解决哈希冲突的常见方法有:
- 链表法(Chaining):每个哈希槽(数组的一个位置)都存储一个链表,如果多个键具有相同的哈希值,则将它们按链表的形式存储在该槽中。
- 开放寻址法(Open Addressing):当发生冲突时,寻找下一个空槽存储元素,常见的探测策略有线性探测、二次探测等。
动态扩展
当哈希表的负载因子(存储的元素个数与哈希表大小的比例)过高时,可能会导致大量的哈希冲突。为了避免性能下降,哈希表会在元素数量达到一定程度时动态扩展(通常是大小翻倍),并重新计算每个元素的哈希值。
哈希表的操作:
- 插入(Insert):插入操作通过计算键的哈希值,找到对应的索引。如果该索引处没有冲突,就直接插入;如果发生冲突,根据所选的冲突解决方法进行处理。
- 查找(Search):查找操作与插入类似,首先通过哈希函数计算键的哈希值,找到对应的槽。如果发生冲突,根据冲突解决方法查找目标元素。
- 删除(Delete):删除操作通过计算哈希值找到元素,然后将该元素删除。对于开放寻址法,在删除元素时需要特别注意如何保持探测序列的连贯性。
哈希表的优缺点:
优点:
- 快速查找、插入和删除:哈希表在理想情况下,查找、插入和删除操作的时间复杂度是常数时间O(1)。
- 简洁性:哈希表的结构非常简单,易于实现和理解。
缺点:
- 内存浪费:由于哈希表的数组通常需要分配一定的空间来避免冲突,可能会导致内存浪费。
- 哈希冲突:哈希冲突的发生可能导致性能下降。虽然有冲突解决方案,但它们会影响效率。
- 不支持按顺序访问:哈希表本身并不保持键的顺序,如果需要按顺序遍历元素,通常需要额外的操作。
示例代码:
#include <iostream>
#include <unordered_map>
int main() {
// 创建一个哈希表
std::unordered_map<int, std::string> hashTable;
// 插入数据
hashTable[1] = "Apple";
hashTable[2] = "Banana";
hashTable[3] = "Cherry";
// 查找数据
int key = 2;
if (hashTable.find(key) != hashTable.end()) {
std::cout << "Key " << key << " found: " << hashTable[key] << std::endl;
}
// 删除数据
hashTable.erase(1);
// 遍历哈希表
for (const auto& pair : hashTable) {
std::cout << "Key: " << pair.first << ", Value: " << pair.second << std::endl;
}
return 0;
}
二、哈希表的线性探测
线性探测(Linear Probing)是一种开放寻址法解决哈希冲突的策略。在哈希表中,当发生冲突时,线性探测会根据某个规则(通常是线性增加的方式)来寻找下一个可用的位置,直到找到一个空槽或找到目标元素。
线性探测哈希表的原理
线性探测的基本思想是在发生哈希冲突时,依次检查当前槽位之后的位置(按线性步长增加),直到找到一个空槽或者已存储的元素。具体来说,哈希表的操作过程如下:
1.哈希函数
计算哈希值时,使用一个哈希函数 h(k) 来将键 k 映射到数组的某个位置。如果该位置已经被占用(发生了哈希冲突),则线性探测会尝试下一位置,即 (h(k) + 1) % N,然后是 (h(k) + 2) % N,依此类推,直到找到一个空槽或目标元素。
2.冲突解决
当发生冲突时,线性探测会从哈希表的当前位置向后查找,直到找到空位置。公式如下:
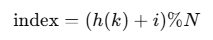
其中,h(k) 是键 k 的哈希值,i 是探测次数(即冲突的次数),N 是哈希表的大小。
3.插入
当插入元素时,首先通过哈希函数计算该元素的哈希值。如果该位置已被占用,则按线性探测规则依次检查下一个位置,直到找到空槽插入元素。
4.查找
查找时,首先计算元素的哈希值。如果当前位置的元素是目标元素,则返回该元素。如果当前位置不匹配,则依次检查下一个位置,直到找到目标元素或遇到空槽(表示元素不存在)。
5.删除
删除元素时,首先找到目标元素的索引,然后将该位置标记为删除。由于其他元素可能仍然通过线性探测访问该位置,删除时需要特别小心,确保不会破坏其他元素的访问。
线性探测的操作
1.插入(Insert)
插入操作首先计算元素的哈希值,然后检查该位置是否已被占用。如果发生冲突,就线性探测下一个位置,直到找到空槽为止。
2.查找(Search)
查找操作与插入类似,首先计算元素的哈希值,然后线性探测后续位置,直到找到目标元素或者遇到空槽为止。
3.删除(Delete)
删除操作通过计算哈希值找到目标元素,然后将该位置标记为删除,并确保之后的元素能够正确访问。
三、链式哈希表
链式哈希表(Chained Hash Table)是开放寻址法中的一种常见的哈希冲突解决方法,它通过在每个哈希表的槽位上存储一个链表来解决哈希冲突。具体来说,当多个元素经过哈希函数计算后得到相同的哈希值(发生冲突时),它们不会直接覆盖原来的值,而是被添加到该位置的链表中。
1.哈希函数
哈希函数的作用是将键映射到哈希表的槽(数组的索引)。哈希函数的输出应该尽可能均匀分布,避免冲突,但在实际应用中,冲突是不可避免的。
int hash(int key) {
return key % tableSize; // 一个简单的哈希函数
}
这里 tableSize 是哈希表的大小。哈希函数将键值 key 映射到哈希表中的一个槽。
2.冲突处理(链表法)
当发生哈希冲突时,链式哈希表不会删除原有元素,而是通过在哈希表每个槽位上存储一个链表来解决冲突。每个槽位存储的是一个链表的头节点,所有映射到该槽的元素都会按链表形式串联在一起。
举个例子,如果两个键 k1 和 k2 经哈希函数映射到相同的槽 i,那么链式哈希表会把它们放到 i 位置的链表中。这样,哈希表的槽每个位置都变成了一个链表。
3.哈希表操作
链式哈希表的操作包括插入、查找和删除,基本步骤如下:
- 插入(Insert):首先计算键的哈希值,然后将元素插入对应哈希槽的链表中。如果链表已经有元素,则将新元素添加到链表的头部或尾部。
- 查找(Search):计算键的哈希值,找到对应槽的链表,然后遍历链表查找目标元素。
- 删除(Delete):计算键的哈希值,找到对应槽的链表,遍历链表删除目标元素
示例代码:
#include <iostream>
#include <list>
#include <vector>
#include <string>
class ChainedHashTable {
private:
std::vector<std::list<std::pair<int, std::string>>> table;
int tableSize;
public:
// 构造函数,初始化哈希表大小
ChainedHashTable(int size) : tableSize(size) {
table.resize(tableSize);
}
// 哈希函数
int hash(int key) {
return key % tableSize;
}
// 插入元素
void insert(int key, const std::string& value) {
int index = hash(key);
table[index].push_back({key, value});
}
// 查找元素
bool search(int key, std::string& value) {
int index = hash(key);
for (const auto& pair : table[index]) {
if (pair.first == key) {
value = pair.second;
return true;
}
}
return false; // 找不到
}
// 删除元素
void remove(int key) {
int index = hash(key);
auto& chain = table[index];
for (auto it = chain.begin(); it != chain.end(); ++it) {
if (it->first == key) {
chain.erase(it);
return;
}
}
std::cout << "Element not found!" << std::endl;
}
// 打印哈希表内容
void print() {
for (int i = 0; i < tableSize; ++i) {
std::cout << "[" << i << "]: ";
for (const auto& pair : table[i]) {
std::cout << "(" << pair.first << ", " << pair.second << ") ";
}
std::cout << std::endl;
}
}
};
int main() {
ChainedHashTable hashTable(7);
// 插入一些数据
hashTable.insert(10, "Apple");
hashTable.insert(20, "Banana");
hashTable.insert(15, "Cherry");
// 查找数据
std::string value;
if (hashTable.search(20, value)) {
std::cout << "Found value for key 20: " << value << std::endl;
}
// 删除数据
hashTable.remove(15);
// 打印哈希表内容
hashTable.print();
return 0;
}
四、哈希表的应用
问题1:找第一个出现重复的数字或者找所有重复出现的数字
#include <iostream>
#include <vector>
#include <unordered_set>
#include <unordered_map>
#include <stdlib.h>
#include <time.h>
using namespace std;
int main() {
vector<int> vec;
srand(time(NULL));
for (int i = 0; i < 10000; i++) {
vec.push_back(rand() % 10000);
}
// 找第一个出现重复的数字
unordered_set<int> s1;
for (auto key : vec) {
auto iter = s1.find(key); // O(1)
if (iter == s1.end()) {
s1.insert(key);
}
else {
std::cout << "key:" << key << std::endl;
break;
}
}
// 统计重复数字以及出现的次数
unordered_map<int, int> m1;
for (int key : vec) {
auto iter = m1.find(key);
if (iter == m1.end()) {
m1.emplace(key, 1);
}
else {
iter->second += 1;
}
}
for (auto pair : m1) {
if (pair.second > 1) {
std::cout << "key:" << pair.first
<< " value:" << pair.second << std::endl;
}
}
// 一组数据有些数字是重复的,把重复的数字过滤掉,每个数字只出现一次
unordered_set<int> s2;
for (auto key : vec) {
s2.emplace(key);
}
// 找出第一个没有重复出现的字符
string src = "jjhfgiyurtytrs";
unordered_map<int, int> m;
for (char ch : src) {
m[ch]++;
}
for (char ch : src) {
if (m[ch] == 1) {
std::cout << "第一个没有重复出现过的字符串:" << ch << std::endl;
return 0;
}
}
std::cout << "所有字符都有重复出现过!" << std::endl;
return 0;
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









