




什么是次梯度?并不是很懂,就抽了一些时间,查了资料(很多资料来自百度百科),总结整理了这个博文,记录下自己的学习过程。
0、前言
次梯度方法(subgradient method)是传统的梯度下降方法的拓展,用来处理不可导的凸函数。它的优势是比传统方法处理问题范围大,劣势是算法收敛速度慢。但是,由于它对不可导函数有很好的处理方法,所以学习它还是很有必要的。
1、导数(Derivative)
导数(Derivative),也叫导函数值。又名微商,是微积分中的重要基础概念。导数是函数的局部性质。一个函数在某一点的导数描述了这个函数在这一点附近的变化率。导数的本质是通过极限的概念对函数进行局部的线性逼近。
对于一般的函数
f
(
x
)
f(x)
f(x),在点
x
0
x_0
x0处的导数为:
f
′
(
x
)
=
lim
Δ
x
→
0
Δ
y
Δ
x
=
lim
Δ
x
→
0
f
(
x
0
+
Δ
x
)
−
f
(
x
0
)
Δ
x
f^{\prime}(x)=\lim _{\Delta x \rightarrow 0} \frac{\Delta y}{\Delta x}=\lim _{\Delta x \rightarrow 0} \frac{f\left(x_{0}+\Delta x\right)-f\left(x_{0}\right)}{\Delta x}
f′(x)=Δx→0limΔxΔy=Δx→0limΔxf(x0+Δx)−f(x0)
等同于
f
′
(
x
)
=
lim
Δ
x
→
0
f
(
x
+
Δ
x
)
−
f
(
x
)
Δ
x
=
lim
Δ
x
→
0
f
(
x
)
−
f
(
x
−
Δ
x
)
Δ
x
f^{\prime}(x)=\lim _{\Delta x \rightarrow 0} \frac{f(x+\Delta x)-f(x)}{\Delta x}=\lim _{\Delta x \rightarrow 0} \frac{f(x)-f(x-\Delta x)}{\Delta x}
f′(x)=Δx→0limΔxf(x+Δx)−f(x)=Δx→0limΔxf(x)−f(x−Δx)
如果不使用增量,
f
(
x
)
f(x)
f(x)在
x
0
x_0
x0处的导数 也可以定义为:当定义域内的变量
x
x
x趋近于
x
0
x_0
x0时,
f
′
(
x
)
=
f
(
x
)
−
f
(
x
0
)
x
−
x
0
f^{\prime}(x)=\frac{f(x)-f\left(x_{0}\right)}{x-x_{0}}
f′(x)=x−x0f(x)−f(x0)
2、次导数(subderivative)
次导数、次切线和次微分的概念出现在凸分析,也就是凸函数的研究中。
设
f
:
I
→
R
f:I→R
f:I→R是一个实变量凸函数,定义在实数轴上的开区间内。这种函数不一定是处处可导的,例如最经典的例子就是
f
(
x
)
=
∣
x
∣
f(x)=|x|
f(x)=∣x∣,在
x
=
0
x=0
x=0处不可导。但是,从下图的可以看出,对于定义域内的任何
x
0
x_0
x0,我们总可以作出一条直线,它通过点
(
x
0
,
f
(
x
0
)
)
(x_0,f(x_0))
(x0,f(x0)),并且要么接触f的图像,要么在它的下方。直线的斜率称为函数的次导数,次导数的集合称为函数
f
f
f在
x
0
x_0
x0处的次微分。

3、次微分(subdifferential)
凸函数
f
:
I
→
R
f:I→R
f:I→R在点
x
0
x_0
x0的次导数,是实数
c
c
c使得:
f
(
x
)
−
f
(
x
0
)
≥
c
(
x
−
x
0
)
f(x)-f\left(x_{0}\right) \geq c\left(x-x_{0}\right)
f(x)−f(x0)≥c(x−x0)
对于所有
I
I
I内的
x
x
x。我们可以证明,在点
x
0
x_0
x0的次导数的集合是一个非空闭区间 [a, b],其中
a
a
a和
b
b
b是单侧极限
a
=
lim
x
→
x
0
−
f
(
x
)
−
f
(
x
0
)
x
−
x
0
a=\lim _{x \rightarrow x_{0}^{-}} \frac{f(x)-f\left(x_{0}\right)}{x-x_{0}}
a=x→x0−limx−x0f(x)−f(x0)
b
=
lim
x
→
x
0
+
f
(
x
)
−
f
(
x
0
)
x
−
x
0
b=\lim _{x \rightarrow x_{0}^{+}} \frac{f(x)-f\left(x_{0}\right)}{x-x_{0}}
b=x→x0+limx−x0f(x)−f(x0)
它们一定存在,且满足
a
≤
b
a≤b
a≤b。所有次导数的集合 [a,b] 称为函数
f
f
f在
x
0
x_0
x0的次微分。
例子:考虑凸函数 f ( x ) = ∣ x ∣ f(x)=|x| f(x)=∣x∣。在原点的次微分是区间 [−1, 1]。 x 0 < 0 x_0<0 x0<0时,次微分是单元素集合 {-1},而 x 0 > 0 x_0>0 x0>0,则是单元素集合{1}。
4、次梯度(subgradient)
在优化问题中,我们可以对目标函数为凸函数的优化问题采用梯度下降法求解,但是在实际情况中,目标函数并不一定光滑、或者处处可微,这时就需要用到次梯度下降算法。
次梯度与梯度的概念类似,凸函数的
F
i
r
s
t
−
o
r
d
e
r
c
h
a
r
a
c
t
e
r
i
z
a
t
i
o
n
First-order characterization
First−ordercharacterization是指如果函数
f
f
f可微,那么当且仅当
d
o
m
(
f
)
dom(f)
dom(f)为凸集,且对于
∀
x
,
y
∈
d
o
m
(
f
)
∀x,y∈dom(f)
∀x,y∈dom(f),使得
f
(
y
)
≥
f
(
x
)
+
∇
f
(
x
)
T
(
y
−
x
)
f(y)≥f(x)+∇f(x)^T(y−x)
f(y)≥f(x)+∇f(x)T(y−x),则函数
f
f
f为凸函数。这里所说的次梯度是指在函数
f
f
f上的点
x
x
x满足以下条件的
g
∈
R
n
g∈R^n
g∈Rn:
f
(
y
)
≥
f
(
x
)
+
g
T
(
y
−
x
)
f(y)≥f(x)+g^T(y−x)
f(y)≥f(x)+gT(y−x)
其中,函数
f
f
f不一定要是凸函数,非凸函数也可以,即对于凸函数或者非凸函数而言,满足上述条件的
g
g
g均为函数在该点的次梯度。但是,凸函数总是存在次梯度(可以利用epigraph和支撑平面理论证明),而非凸函数则不一定存在次梯度,即使
f
f
f可微。该定义说明,用次梯度对原函数做出的一阶展开估计总是比真实值要小。
很明显,凸函数的次梯度一定存在,如果函数 f f f在点 x x x处可微,那么 g = ∇ f ( x ) g=∇f(x) g=∇f(x),为函数在该点的梯度,且唯一;如果不可微,则次梯度不一定唯一。但是对于非凸函数,次梯度则不一定存在,也不一定唯一。
例如,凸函数
∥
x
∥
p
∥x∥_p
∥x∥p范数为凸函数,但不满足处处可微的条件,因此,函数的次梯度不一定唯一,如下图:

-
左图为 ∥ x ∥ 2 ∥x∥_2 ∥x∥2,函数在 x ≠ 0 x≠0 x=0时,次梯度唯一,且 g = x / ∥ x ∥ 2 g=x/∥x∥_2 g=x/∥x∥2;当 x = 0 x=0 x=0时,次梯度为 z : ∥ z ∥ 2 ≤ 1 {z:∥z∥_2≤1} z:∥z∥2≤1中的任意一个元素;
-
右图为 ∥ x ∥ 1 ∥x∥_1 ∥x∥1,函数在 x ≠ 0 x≠0 x=0时,次梯度唯一,且 g = s i g n ( x ) g=sign(x) g=sign(x);当 x = 0 x=0 x=0时,次梯度为 [−1,1] 中的任意一个元素;
同样,绝对值函数
f
(
x
)
=
∣
x
∣
f(x)=∣x∣
f(x)=∣x∣和最大值函数
f
(
x
)
=
m
a
x
{
f
1
(
x
)
,
f
2
(
x
)
}
f(x)=max\{f_1(x),f_2(x)\}
f(x)=max{f1(x),f2(x)}在不可微点处次梯度也不一定唯一,如下图:

- 左函数为绝对值函数 f ( x ) = ∣ x ∣ f(x)=∣x∣ f(x)=∣x∣,其在满足 x = 0 x=0 x=0的点处,次梯度为任意一条直线,在向量 ∇ f 1 ( x ) ∇f_1(x) ∇f1(x)和 ∇ f 2 ( x ) ∇f_2(x) ∇f2(x)之间。;
- 右函数为最大值函数 f ( x ) = m a x { f 1 ( x ) , f 2 ( x ) } f(x)=max\{f_1(x),f_2(x)\} f(x)=max{f1(x),f2(x)},其在满足 f 1 ( x ) = f 2 ( x ) f_1(x)=f_2(x) f1(x)=f2(x)的点处,次梯度为任意一条直线,在向量 ∇ f 1 ( x ) ∇f_1(x) ∇f1(x)和 ∇ f 2 ( x ) ∇f_2(x) ∇f2(x)之间。
5、次梯度的性质
- Scalingf: ∂ ( a f ) = a ⋅ ∂ f ∂(af)=a⋅∂f ∂(af)=a⋅∂f;
- Addition: ∂ ( f 1 + f 2 ) = ∂ f 1 + ∂ f 2 ; ∂(f_1+f_2)=∂f_1+∂f_2; ∂(f1+f2)=∂f1+∂f2;
- Affine composition: 如 果 g ( x ) = f ( A x + b ) , 那 么 ∂ g ( x ) = A T ∂ f ( A x + b ) ; 如果g(x)=f(Ax+b),那么∂g(x)=A^T∂f(Ax+b); 如果g(x)=f(Ax+b),那么∂g(x)=AT∂f(Ax+b);
- Finite pointwise maximum: 如 果 f ( x ) = max i = 1 , … , m f i ( x ) , 那 么 ∂ f ( x ) = conv ( ⋃ i : f i ( x ) = f ( x ) ∂ f i ( x ) ) ; 如果f(x)=\max _{i=1, \ldots, m} f_{i}(x), 那么\partial f(x)=\operatorname{conv}\left(\bigcup_{i : f_{i}(x)=f(x)} \partial f_{i}(x)\right); 如果f(x)=maxi=1,…,mfi(x),那么∂f(x)=conv(⋃i:fi(x)=f(x)∂fi(x));
6、灵魂一问:为什么要计算次梯度?
对于光滑的凸函数而言,我们可以直接采用梯度下降算法求解函数的极值,但是当函数不处处光滑,处处可微的时候,梯度下降就不适合应用了。因此,我们需要计算函数的次梯度。对于次梯度而言,其没有要求函数是否光滑,是否是凸函数,限定条件很少,所以适用范围更广。
次梯度具有以下优化条件:对于任意函数
f
f
f(无论是凸还是非凸),函数在点
x
x
x处取得最值等价于:
f
(
x
∗
)
=
min
x
f
(
x
)
⇔
0
∈
∂
f
(
x
∗
)
f\left(x^{*}\right)=\min _{x} f(x) \Leftrightarrow 0 \in \partial f\left(x^{*}\right)
f(x∗)=xminf(x)⇔0∈∂f(x∗)
即,当且仅当
0
0
0属于函数
f
f
f在点
x
∗
x^∗
x∗处次梯度集合的元素时,
x
∗
x^∗
x∗为最优解。
证明:当次梯度 g = 0 g=0 g=0时,对于所有 y ∈ d o m ( f ) y∈dom(f) y∈dom(f),存在 f ( y ) ≥ f ( x ∗ ) + 0 T ( y − x ∗ ) = f ( x ∗ ) f(y)≥f(x^∗)+0^T(y−x^∗)=f(x^∗) f(y)≥f(x∗)+0T(y−x∗)=f(x∗),所以, x ∗ x^∗ x∗为最优解,即证。
7、次梯度算法(Subgradient method)
次梯度算法与梯度下降算法类似,仅仅用次梯度代替梯度,记
f
:
R
n
→
R
f : \mathbb{R}^{n} \rightarrow \mathbb{R}
f:Rn→R为定义在
R
n
\mathbb{R}^{n}
Rn上的凸函数,即:
x
(
k
+
1
)
=
x
(
k
)
−
α
k
g
(
k
)
,
k
=
1
,
2
,
3
,
…
x^{(k+1)}=x^{(k)}-\alpha_{k} g^{(k)},k=1,2,3,…
x(k+1)=x(k)−αkg(k),k=1,2,3,…
其中
g
(
k
)
g^{(k)}
g(k)表示函数
f
f
f在
x
(
k
)
x^{(k)}
x(k)的次梯度。如果
f
f
f可微,它的次梯度就是梯度向量
∇
f
\nabla f
∇f。有时,
−
g
(
k
)
-g^{(k)}
−g(k)不是函数
f
f
f在
x
(
k
)
x^{(k)}
x(k)的下降方向。因此采用一系列可能的
f
b
e
s
t
f_{b e s t}
fbest来追踪目标函数的极小值点,即
f
b
e
s
t
(
k
)
=
min
{
f
b
e
s
t
(
k
−
1
)
,
f
(
x
(
k
)
)
}
f_{\mathrm{best}}^{(k)}=\min \left\{f_{\mathrm{best}}^{(k-1)}, f\left(x^{(k)}\right)\right\}
fbest(k)=min{fbest(k−1),f(x(k))}
另一点与梯度下降算法不同的是:次梯度算法没有明确的步长选择方法,类似Exact line search和Backtracking line search的方法,只有步长选择准则,具体如下:

8、次梯度算法实例
A. Regularized Logistic Regression
对于逻辑回归的代价函数可记为:
f
(
β
)
=
∑
i
=
1
n
(
−
y
i
x
i
T
β
+
log
(
1
+
exp
(
x
i
T
β
)
)
)
f(\beta)=\sum_{i=1}^{n}\left(-y_{i} x_{i}^{T} \beta+\log \left(1+\exp \left(x_{i}^{T} \beta\right)\right)\right)
f(β)=i=1∑n(−yixiTβ+log(1+exp(xiTβ)))
明显,上式是光滑且凸的,而正则化则是指优化目标函数为:
min
β
∈
R
p
f
(
β
)
+
λ
⋅
P
(
β
)
\min _{\beta \in \mathbb{R}^{p}} f(\beta)+\lambda \cdot P(\beta)
β∈Rpminf(β)+λ⋅P(β)
如果
P
(
β
)
=
∥
β
∥
2
2
P(β)=∥β∥^2_2
P(β)=∥β∥22,则成为岭回归(ridge problem),如果
P
(
β
)
=
∥
β
∥
1
P(β)=∥β∥_1
P(β)=∥β∥1则称为Lasso。对于岭回归,我们仍然可以采用梯度下降算法求解目标函数,因为函数处处可导光滑,而Lasso问题则无法用梯度下降算法求解,因为函数不是处处光滑,具体可参考下面的图,所以,对于Lasso问题需要选用次梯度算法求解。
下图是对于同样数据集下分别对逻辑回归选用岭惩罚和Lasso惩罚求解最优解的实验结果图
(
n
=
1000
,
p
=
20
)
(n=1000,p=20)
(n=1000,p=20):
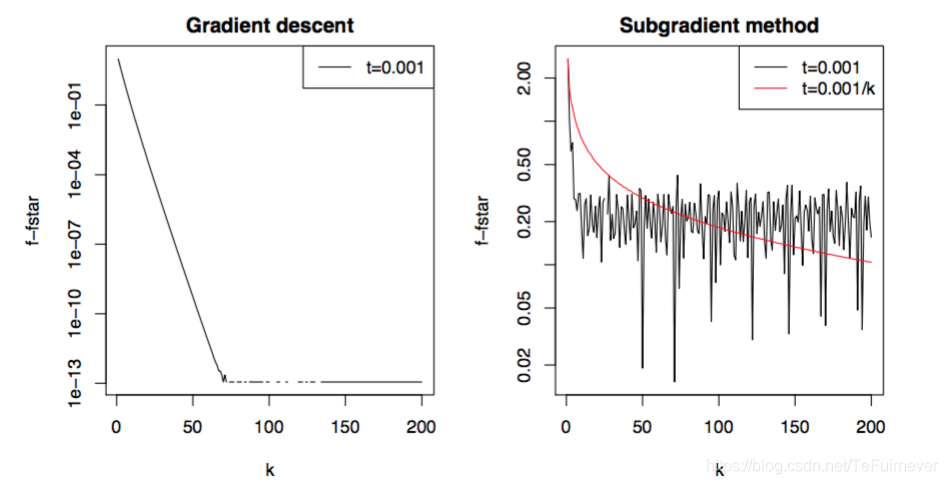
B. 随机次梯度算法
随机次梯度算法(Stochastic Subgradient Method)与次梯度算法(Subgradient Method)相比,每次更新次梯度是根据某一个样本计算获得,而不是通过所有样本更新次梯度。
所以,根据梯度更新的方式不同,次梯度算法和梯度下降算法一般被称为“batch method”。从计算量来讲, m m m次随机更新近似等于一次batch更新,二者差别在于 ∑ i = 1 m [ ∇ f i ( x ( k + i − 1 ) ) − ∇ f i ( x ( k ) ) ] \sum_{i=1}^{m}\left[\nabla f_{i}\left(x^{(k+i-1)}\right)-\nabla f_{i}\left(x^{(k)}\right)\right] ∑i=1m[∇fi(x(k+i−1))−∇fi(x(k))],当 x x x变化不大时,差别可以近似等于0。
对于随机更新次梯度,一般随机的方式有两种:
- Cyclic rule:选择 i k = 1 , 2 , … , m , 1 , 2 , … , m , … i_k=1,2,…,m,1,2,…,m,… ik=1,2,…,m,1,2,…,m,…;
- Randomized rule:均匀随机从 1 , … , m {1,…,m} 1,…,m选取一点作为 i k i_k ik。
与所有优化算法一样,随机次梯度算法能否收敛?
答案是肯定的,这里就不在做证明,有兴趣的同学可以参考boyd教授的论文,这里仅给出收敛结果,如下:
lim
k
→
∞
f
(
x
b
e
s
t
(
k
)
)
≤
f
∗
+
5
m
2
G
2
t
2
\lim _{k \rightarrow \infty} f\left(x_{b e s t}^{(k)}\right) \leq f^{*}+\frac{5 m^{2} G^{2} t}{2}
k→∞limf(xbest(k))≤f∗+25m2G2t
对于Cyclic rule,随机次梯度算法的收敛速度为
O
(
m
3
G
2
/
ϵ
2
)
O(m^3G^2/ϵ^2)
O(m3G2/ϵ2);对于Randomized rule,随机次梯度算法的收敛速度为
O
(
m
2
G
2
/
ϵ
2
)
O(m^2G^2/ϵ^2)
O(m2G2/ϵ2)。
下图给出梯度下降和随机梯度下降算法在同一数据下迭代结果:
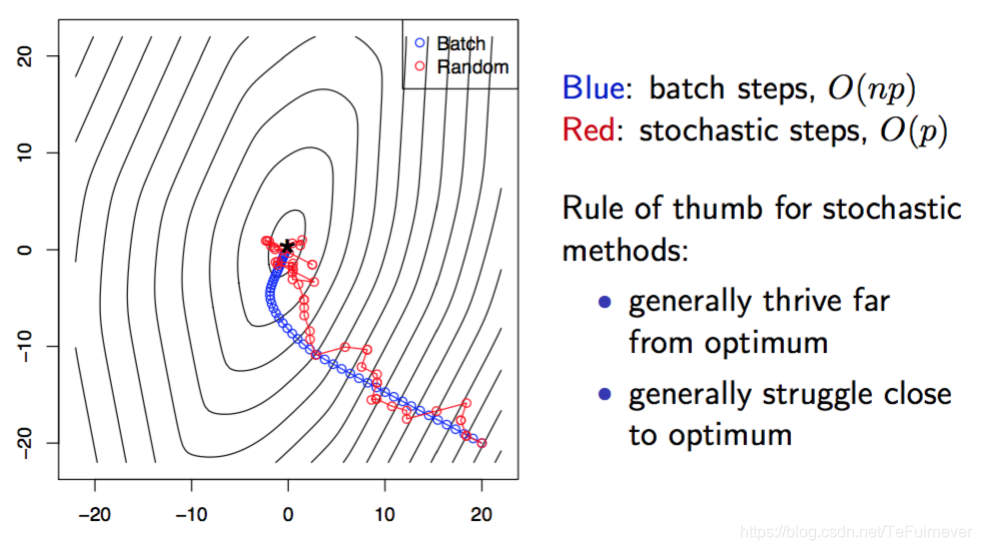
如果想要更多的资源,欢迎关注 @我是管小亮,文字强迫症MAX~
回复【福利】即可获取我为你准备的大礼,包括C++,编程四大件,NLP,深度学习等等的资料。
想看更多文(段)章(子),欢迎关注微信公众号「程序员管小亮」~




















 1193
1193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











