



 本文介绍如何使用Swin Transformer进行语义分割任务,并详细指导读者完成环境配置、数据集准备、代码调整及模型训练等关键步骤。
本文介绍如何使用Swin Transformer进行语义分割任务,并详细指导读者完成环境配置、数据集准备、代码调整及模型训练等关键步骤。
- 1. 按照作者的步骤安装好所需的环境。
- 2. 安装可以运行一下demo看环境是否搭建成功。
- 3. 准备好自己的数据集,我用的是VOC数据集。
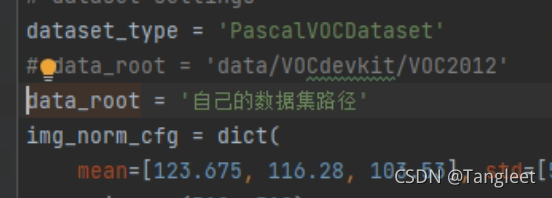
- 4. 修改confis/_base_/datasets/pascal_voc12.py
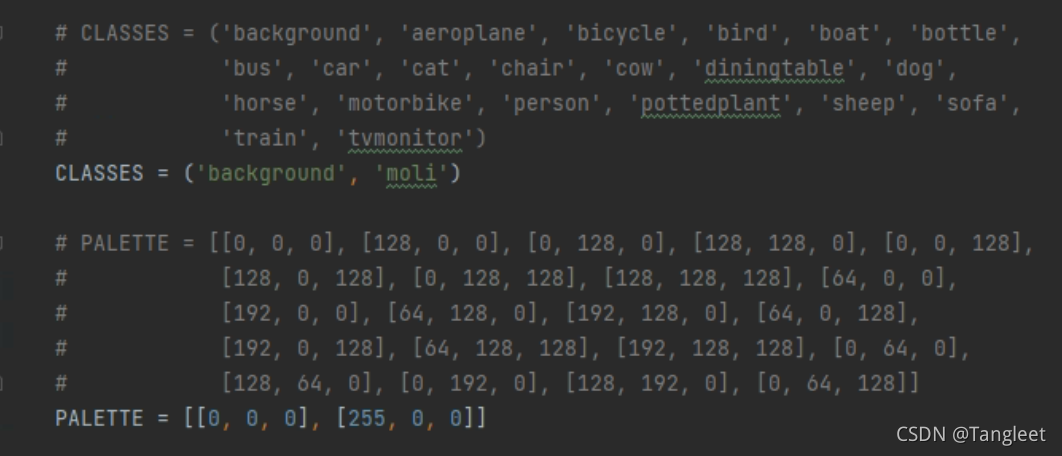
- 5. 修改mmseg/datasets/voc.py标签和颜色rgb
- 6. 修改tools/train.py中的相关参数
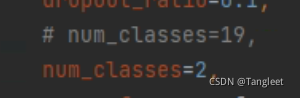
- 7. 修改configs/_base_/models/upernet_swin.py关闭分布式训练,修改分类数

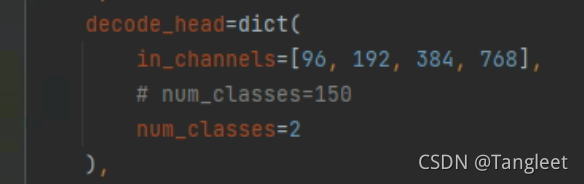
- 8. 修改configs/swin/upernet_swin_tiny_patch4_window7_512x512_160k_ade20k.py中数据集的地址和分类数

- 运行train.py开始训练

















 6088
6088









 到【灌水乐园】发言
到【灌水乐园】发言







