




1、认识URL
虽然说,应用层协议是程序员自己定的,但是已经有大神定义了一些现成的,可供我们直接使用。HTTP协议——超文本传输协议就是其中之一。
在互联网世界中, HTTP(HyperText Transfer Protocol,超文本传输协议)是一个至关重要的协议。它定义了客户端(如浏览器)与服务器之间如何通信,以交换或传输超文本(如 HTML 文档)。
HTTP 协议是客户端与服务器之间通信的基础。客户端通过 HTTP 协议向服务器发送请求,服务器收到请求后处理并返回响应。 HTTP 协议是一个无连接、无状态的协议,即每次请求都需要建立新的连接,且服务器不会保存客户端的状态信息。
平时我们说的网址,其实说的就是URL——Uniform Resource Locator(统一资源定位符):
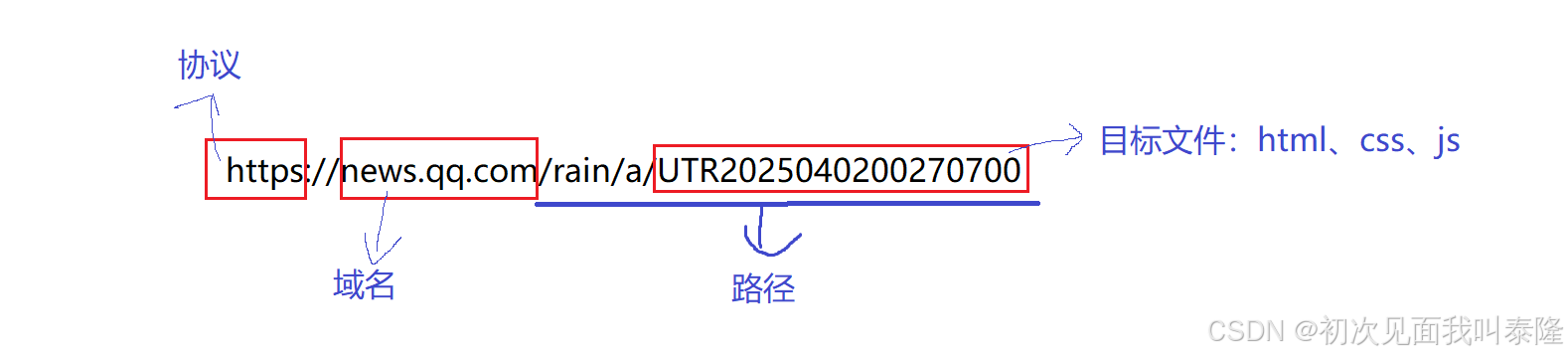
如图,贴出了一个URL。https表示的是协议。然后news.qq.com表示的是域名,域名会被转换成公网IPIP地址。后面的UTR…表示的是服务器上的一个目标文件,可能是html、css、js。然后从/rain往后这就是路径,意思就是请求服务器上的某个路径下的资源。
请求的资源本质上就是文件。这个路径就是Linux下的路径结构。
前置背景理解:
1、我的数据给服务器,服务器的数据给我,就是在做IO。所以我们上网的所有行为都是在做IO。
比如今天我刷抖音,就是向抖音服务器请求视频资源,抖音服务器将视频资源返回给我的客户端,我就能看到视频。再比如我逛淘宝京东,就是淘宝京东的服务器将图片等等信息返回给我的客户端。这就是服务器的数据给我。再比如我今天登录账号,那就是将我的账户密码上传给服务器,这就是将我的数据给服务器。网络通信本质就是进程间通信,而进程间通信本质就是在做IO。
2、我向服务器请求的图片、视频、音频、文本等都是资源。
3、我要向服务器请求资源,就需要确认在哪台服务器上(网络IP),在什么路径下(系统路径)。所以就需要URL。
而我们进行网络通信是通过IP+端口号来实现的,那URL怎么没有体现端口号呢?这是因为http、https已经是很成熟的应用层协议了,所以它们的端口号都是强关联的。比如http协议端口号就是80,https就是443。
4、url中/…不一定是根目录,其实叫做web根目录,这两者不一定是同一个
urlencode和urldecode:
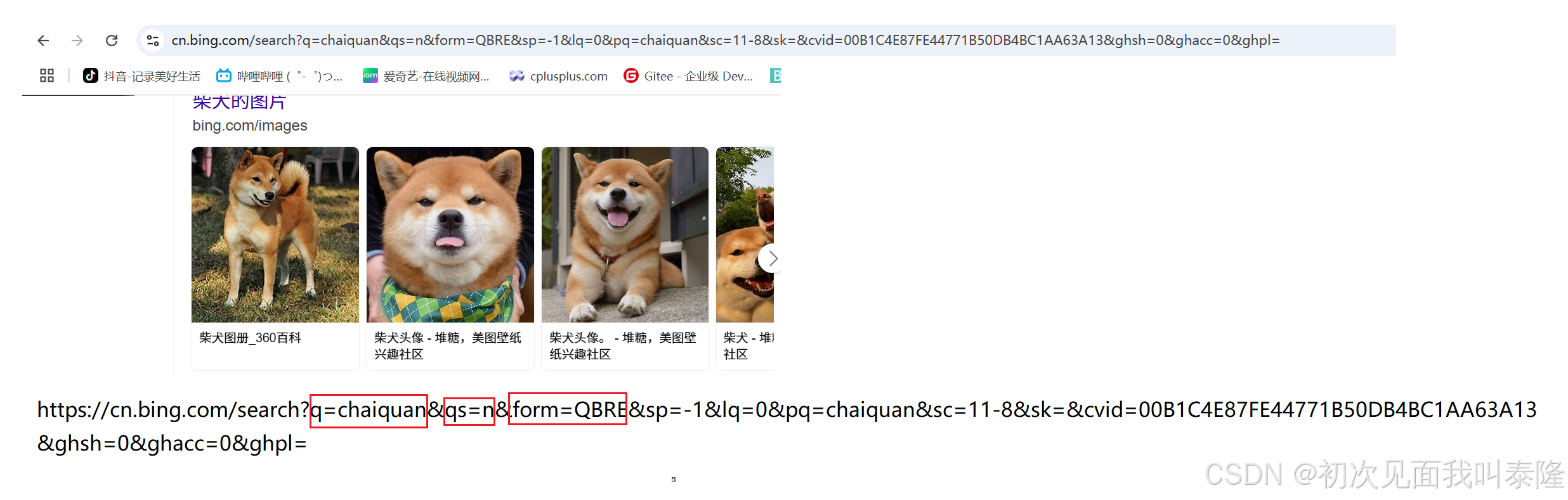
如图,我们在bing中搜索chaiquan,然后上方的URL就是上图中我给出来的这一串。URL后面是可以跟参数的,上图中?后面的内容就是参数,参数以key=value的形式添加在URL后面,如果有多个参数就以&连接。
所以像/、&、=这些字符都是URL中的特殊字符。上面我们搜索的内容chaiquan就是参数q=chaiquan。那如果我搜索的内容中带有/、&、=这些特殊字符呢?
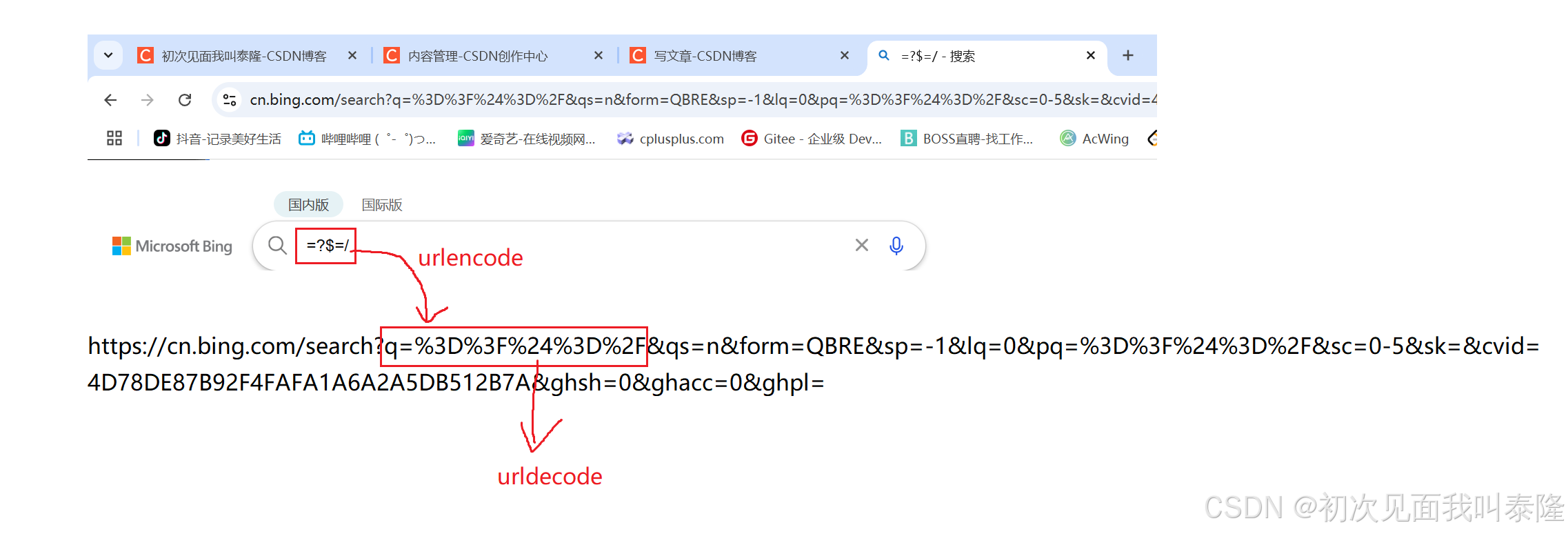
如图,这时候我们搜索的特意用了一些特殊字符。我们发现URL中的参数value的内容发生了变化,不是我们输入的特殊字符。这是因为这些特殊字符已经被url当作特殊意义理解了,所以这些字符不能随意出现,必须对这些字符进行转义。
转移的规则如下:将需要转码的字符转为 16 进制,然后从右到左,取 4 位(不足 4 位直接处理),每2位做一位,前面加上%,编码成%XY格式。
所以我们输入框输入的内容,在URL中的参数中就被转义了,这个过程就叫做urlencode,那么服务器在收到这个请求,将参数提取出来的时候也要将转义的内容再重新转换成字符,这个过程就是urldecode。
2、HTTP协议的宏观格式
http是应用层协议,是基于TCP协议的。
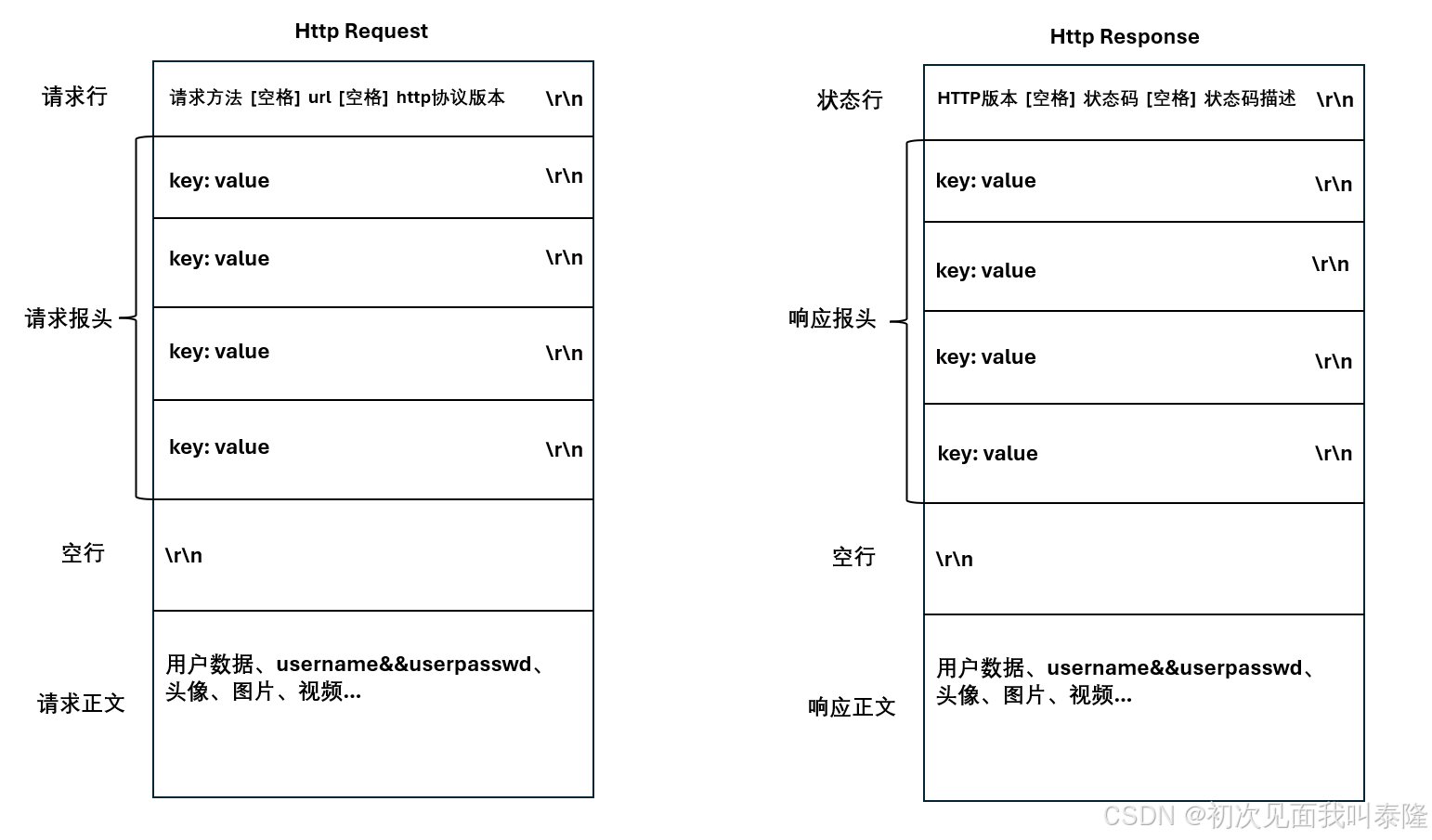
先来看HTTP协议的格式,先看请求的格式:
第一行表示的是请求行,请求行里面有请求方法,然后空格接着跟着的是url,然后再空格,接着是http协议的版本,紧接着以\r\n结尾。请求行之后就是请求报头,也是一行一行的字符串,他们都是以\r\n分隔开的。请求报头里面是key:,接着空格value,记住冒号之后是有空格的。请求报头之后是空行,单纯的\r\n,然后后面就是请求正文的内容了。
再来看响应的格式,响应的格式类似请求,只不过第一行变成了状态行,状态行的内容是:HTTP版本,然后空格接着是状态码,比如状态码404,接着空格跟状态码描述,比如404的状态码描述就是Not Found,后面跟\r\n。下面就是响应报头,也是key: value的形式,然后每行\r\n分隔开,最后有一行空行,空行只有\r\n,后面就是响应正文了。
那么HTTP如何保证收发的完整性?HTTP是基于TCP协议的,而TCP是面向字节流的。
http协议自己已经做了序列化了,通过\r\n将空行前面的字符串合并成一个大字符串,这个大字符串的分隔符是\r\n,所以我们可以直接将HTTP请求作为一个长字符串给对方发送过去。所以要序列化其实就是将这些字符串合并成一个大字符串就行了。
但是我们反序列化如何知道请求正文呢,因为请求正文是没有\r\n的,首先读取一部分,判断第一个\r\n,那么前面的内容就是请求行的内容,接着继续读取内容,通过\r\n可以拆分出一个一个的key: value,当读取到空串,也就是只有\r\n,没有字符串内容,说明我把前面的内容全都读完了,那么剩下的就是请求正文的内容了。但是我们并不知道请求正文的长度,因此在请求报头里面有一个字段:Content-Length: 数字\r\n,这个字段表示的就是请求正文的长度。根据这个长度就可以将请求正文完整的提取出来。
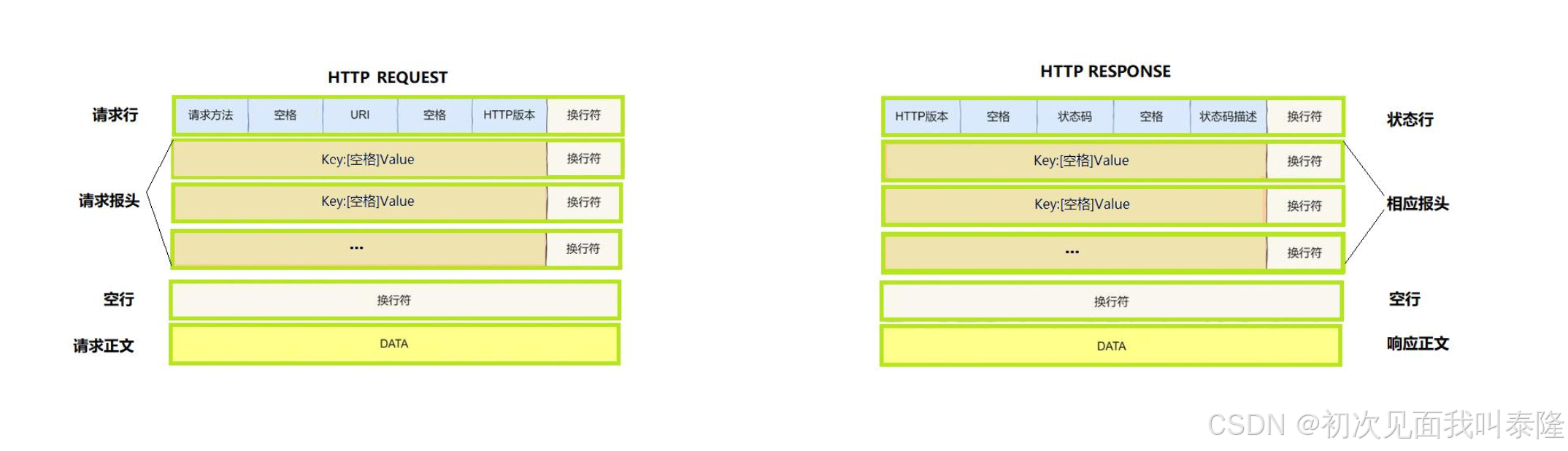
请求方法有:GET、POST等,URI表示请求服务器的资源路径,HTTP版本如:HTTP/1.0、HTTP/1.1…
状态码如:200——OK,404——Not Found,将来响应正文就是请求的图片、视频、html等等资源。
请求和响应的格式是一样的,因此它们序列化和反序列化的方式也是一样的。
3、实现HttpServer服务器
3.1、使用模板方法模式封装Socket.hpp
#pragma once
#include <iostream>
#include <string>
#include <memory>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include "InetAddr.hpp"
#include "Log.hpp"
namespace SocketModule
{
using namespace LogModule;
const int gdefaultsockfd = -1;
const int gdefaultbacklog = 8;
class Socket;
using SockPtr = std::shared_ptr<Socket>;
class Socket
{
public:
virtual ~Socket() = default;
virtual void SocketOrDie() = 0;
virtual void SetSocketOpt() = 0;
virtual bool BindOrDie(int port) = 0;
virtual bool ListenOrDie() = 0;
virtual SockPtr Accepter(InetAddr* client) = 0;
virtual void Close() = 0;
virtual int Recv(std::string* out) = 0;
virtual int Send(const std::string& in) = 0;
virtual int Fd() = 0;
// 提供一个创建TCP套接字的固定方法
void BuildTcpSocketMethod(int port)
{
SocketOrDie();
SetSocketOpt();
BindOrDie(port);
ListenOrDie();
}
// void BuildUdpSocketMethod(int port)
// {
// }
};
// class UdpSocket
// {
// };
class TcpSocket
{
public:
TcpSocket()
:_sockfd(gdefaultsockfd)
{}
TcpSocket(int sockfd)
:_sockfd(sockfd)
{}
~TcpSocket()
{}
virtual int Fd() override
{
}
virtual void SocketOrDie() override
{
}
virtual void SetSocketOpt() override
{
}
virtual bool BindOrDie(int port) override
{
}
virtual bool ListenOrDie() override
{
}
virtual SockPtr Accepter(InetAddr* client) override
{
}
virtual void Close() override
{
}
virtual int Recv(std::string* out) override
{
}
virtual int Send(const std::string& in) override
{
}
private:
int _sockfd;
};
}
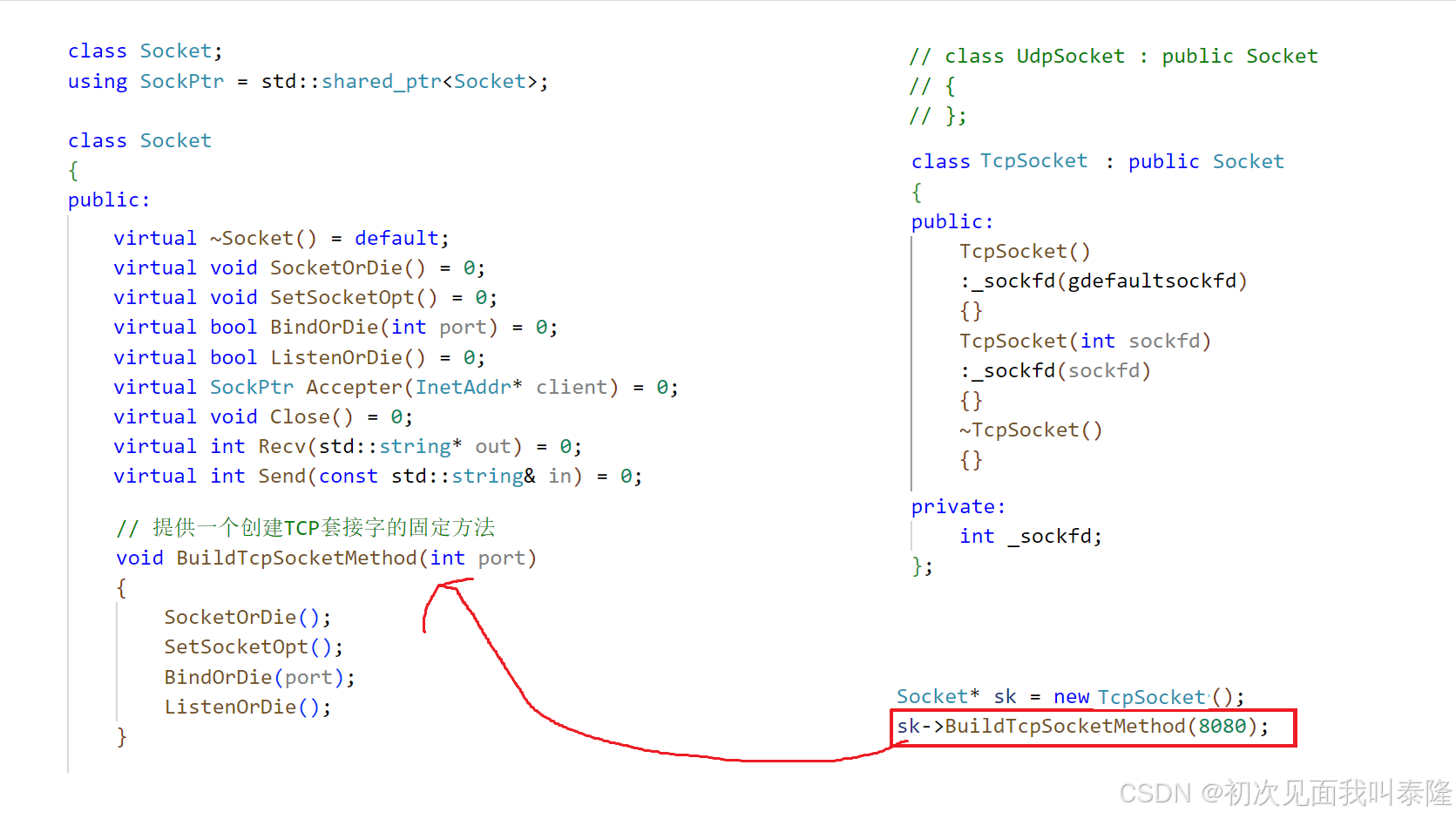
如图,基类Socket定义出一系列方法,然后提供一个或若干个固定模式的socket方法,派生类TcpSocket继承Socket方法实现出一系列具体方法,将来创建出的对象直接调用父类提供的固定方法,立马将子类实现的具体方法按顺序全部调出来,这种模式叫做模板方法模式,它是一种行为类的设计模式。
也就是说我们把一些固定套路的方法实现细节交给子类,但是这些方法在调用的时候组合是固定的,所以我们把这个调用组合的函数在基类实现。将来定义对象调用这些固定组合的方法,直接调用基类实现的固定套路函数即可。
我们也可以实现UdpSocket然后继承Socket,UdpSocket中没有监听和获取新连接,那么ListenOrDie和Accepter我们在派生类中方法体内为空即可,什么都不实现。
下面实现TcpSocket:
#pragma once
#include <iostream>
#include <string>
#include <memory>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include "InetAddr.hpp"
#include "Log.hpp"
namespace SocketModule
{
using namespace LogModule;
const int gdefaultsockfd = -1;
const int gdefaultbacklog = 8;
class Socket;
using SockPtr = std::shared_ptr<Socket>;
// 模板方法
class Socket
{
public:
virtual ~Socket() = default;
virtual void SocketOrDie() = 0;
virtual void SetSocketOpt() = 0;
virtual bool BindOrDie(int port) = 0;
virtual bool ListenOrDie() = 0;
virtual SockPtr Accepter(InetAddr* client) = 0;
virtual void Close() = 0;
virtual int Recv(std::string* out) = 0;
virtual int Send(const std::string& in) = 0;
virtual int Fd() = 0;
// 提供一个创建TCP套接字的固定方法
void BuildTcpSocketMethod(int port)
{
SocketOrDie();
SetSocketOpt();
BindOrDie(port);
ListenOrDie();
}
// void BuildUdpSocketMethod(int port)
// {
// }
};
// class UdpSocket : public Socket
// {
// };
class TcpSocket : public Socket
{
public:
TcpSocket()
:_sockfd(gdefaultsockfd)
{}
TcpSocket(int sockfd)
:_sockfd(sockfd)
{}
~TcpSocket()
{}
virtual int Fd() override
{
return _sockfd;
}
virtual void SocketOrDie() override
{
_sockfd = ::socket(AF_INET, SOCK_STREAM, 0);
if (_sockfd < 0)
{
LOG(LogLevel::ERROR) << "create socket error";
Die(SOCKET_ERR);
}
LOG(LogLevel::INFO) << "create socket success: " << _sockfd;
}
virtual void SetSocketOpt() override
{
}
virtual bool BindOrDie(int port) override
{
if (_sockfd == gdefaultsockfd) return false;
InetAddr server(port);
int n = ::bind(_sockfd, server.NetAddr(), server.NetAddrLen());
if (n < 0)
{
LOG(LogLevel::ERROR) << "bind error";
Die(BIND_ERR);
}
LOG(LogLevel::INFO) << "bind success: " << _sockfd;
return true;
}
virtual bool ListenOrDie() override
{
if (_sockfd == gdefaultsockfd) return false;
int n = ::listen(_sockfd, gdefaultbacklog);
if (n < 0)
{
LOG(LogLevel::ERROR) << "listen error";
Die(LISTEN_ERR);
}
LOG(LogLevel::INFO) << "listen success: " << _sockfd;
return true;
}
virtual SockPtr Accepter(InetAddr* client) override
{
if (!client) return nullptr;
struct sockaddr_in peer;
socklen_t len = sizeof(peer);
int newsockfd = ::accept(_sockfd, CONV(&peer), &len);
if (newsockfd < 0)
{
LOG(LogLevel::WARNING) << "accept error";
return nullptr;
}
client->SetAddr(peer, len);
return std::make_shared<TcpSocket>(newsockfd);;
}
virtual void Close() override
{
if (_sockfd != gdefaultsockfd)
{
::close(_sockfd);
}
}
virtual int Recv(std::string* out) override
{
char buffer[1024 * 8];
int n = ::recv(_sockfd, buffer, sizeof(buffer)-1, 0);
if (n > 0)
{
buffer[n] = 0;
*out = buffer;
}
return n;
}
virtual int Send(const std::string& in) override
{
int n = ::send(_sockfd, in.c_str(), in.size(), 0);
return n;
}
private:
int _sockfd;
};
}
SetSocketOpt先不实现,后面再说。
Accepter中client最为输出型参数将accept获取的客户端信息带出去,所以需要在InetAddr.hpp中实现一个SetAddr函数:
接着返回的对象是SockPtr类型,这是一个shared_ptr的智能指针对象,我们让它指向TcpSocket,并将获取新连接返回的sockfd传进去初始化,将来在上层TcpServer.hpp中通过这个指针指向就可以直接->去调用Recv和Send获取和接收数据。所以将来TcpSocket可能是专门用来获取新连接的,也可能是专门进行IO接收发送数据的。
3.2、实现TcpServer.hpp
#pragma once
#include <functional>
#include <sys/wait.h>
#include "Socket.hpp"
namespace TcpServerModule
{
using namespace SocketModule;
using tcphandler_t = std::function<bool(SockPtr, InetAddr)>;
// 只负责IO, 不对协议进行任何处理
class TcpServer
{
public:
TcpServer(int port)
:_listensockp(std::make_unique<TcpSocket>(port))
,_port(port)
,_isrunning(false)
{}
void InitServer(tcphandler_t handler)
{
_handler = handler;
_listensockp->BuildTcpSocketMethod(_port);
}
void Loop()
{
_isrunning = true;
while (_isrunning)
{
InetAddr clientaddr;
SockPtr sockfd = _listensockp->Accepter(&clientaddr);
if (sockfd == nullptr)
continue;
LOG(LogLevel::INFO) << "get a new client, info is: " << clientaddr.Addr();
pid_t id = fork();
if (id == 0)
{
_listensockp->Close();
if (fork() > 0) exit(0);
_handler(sockfd, clientaddr);
exit(0);
}
sockfd->Close();
waitpid(id, nullptr, 0);
}
_isrunning = false;
}
~TcpServer()
{
_listensockp->Close();
}
private:
std::unique_ptr<Socket> _listensockp;
int _port;
bool _isrunning;
// 回调HttpServer.hpp函数获取请求处理返回响应
tcphandler_t _handler;
};
}
TcpServer中有一个智能指针对象_listensockp指向TcpSocket对象,不过它的_sockfd是监听套接字,专门用来获取新连接,还有一个回调函数_handler。通过InitServer将上层的HttpServer.hpp中的方法传给TcpServer,在Loop函数中获取新连接,创建孙子进程回调_handler去获取请求处理返回响应。
3.3、实现HttpServer.hpp:先实现将固定的html网页信息返回。
#pragma once
#include "TcpServer.hpp"
using namespace TcpServerModule;
const std::string Sep = "\r\n";
const std::string BlankLine = Sep;
class HttpServer
{
public:
HttpServer(int port)
:_tsvr(std::make_unique<TcpServer>(port))
{}
void Start()
{
_tsvr->InitServer([this](SockPtr sockfd, InetAddr client){
return this->HandlerHttpRequest(sockfd, client);
});
_tsvr->Loop();
}
bool HandlerHttpRequest(SockPtr sockfd, InetAddr client)
{
LOG(LogLevel::INFO) << "HttpServer: get a new client: " << sockfd->Fd() << " addr info: " << client.Addr();
std::string http_request;
sockfd->Recv(&http_request);
std::cout << http_request << std::endl;
// 读取请求,对请求进行分析处理 --->文本处理
// 1.读取请求的完整性---暂时不做
// 2.完整http反序列化,http reponse序列化
// demo1: 直接返回一个固定的内容
std::string status_line = "HTTP/1.1 200 OK" + Sep;
std::string body_string = "<!DOCTYPE html>\
<html>\
<body>\
Hello, World!\
</body>\
</html>";
std::string http_response = status_line + BlankLine + body_string;
sockfd->Send(http_response);
return true;
}
~HttpServer()
{}
private:
std::unique_ptr<TcpServer> _tsvr;
};
接着实现HttpServer.cc启动HttpServer:
#include "HttpServer.hpp"
int main(int argc, char* argv[])
{
if (argc != 2)
{
std::cout << "Usage: " << argv[0] << " port" << std::endl;
return 1;
}
auto httpserver = std::make_unique<HttpServer>(std::stoi(argv[1]));
httpserver->Start();
return 0;
}
HttpServer必须要有个TcpServer对象,因为HTTP是基于TCP的。构造函数创建TcpServer智能指针对象,通过Start函数启动服务,将HttpServer中的HandlerHttpRequest函数传入给TcpServer作为回调函数,将来TcpServer的Loop函数中获取新连接,创建孙子进程就会回调HandlerHttpRequest函数,该函数获取请求输出并构建一个简单的响应返回。
下面启动HttpServer进行测试:
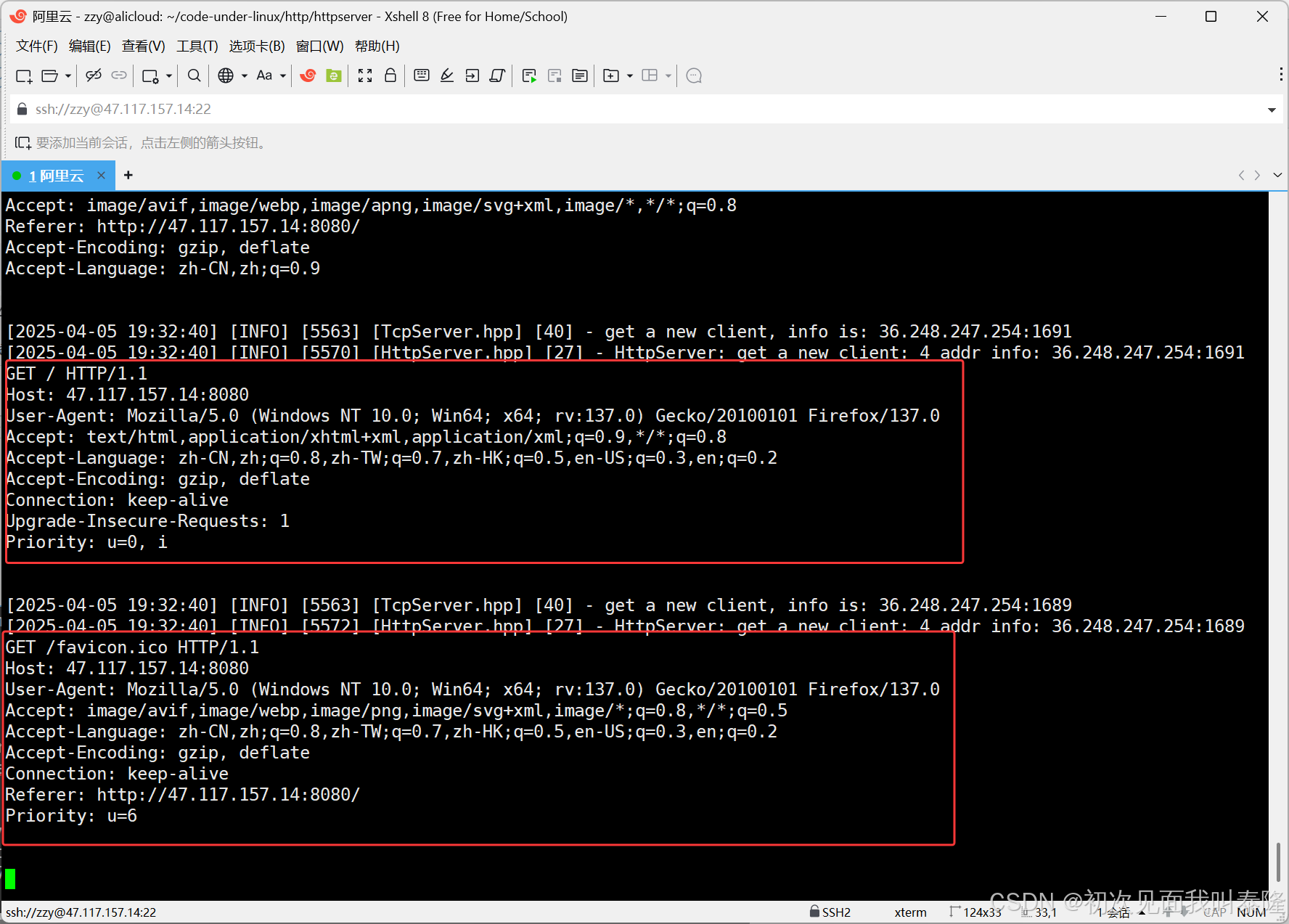

现在我们已经可以获取浏览器发送的请求信息,并构建一个响应返回。浏览器接收到html网页信息,所以显示hello,world!。
但是我们并不想要这种硬编码的直接返回一个html网页,我们想要的是根据不同的请求返回不同的信息,比如网页、图片等等。
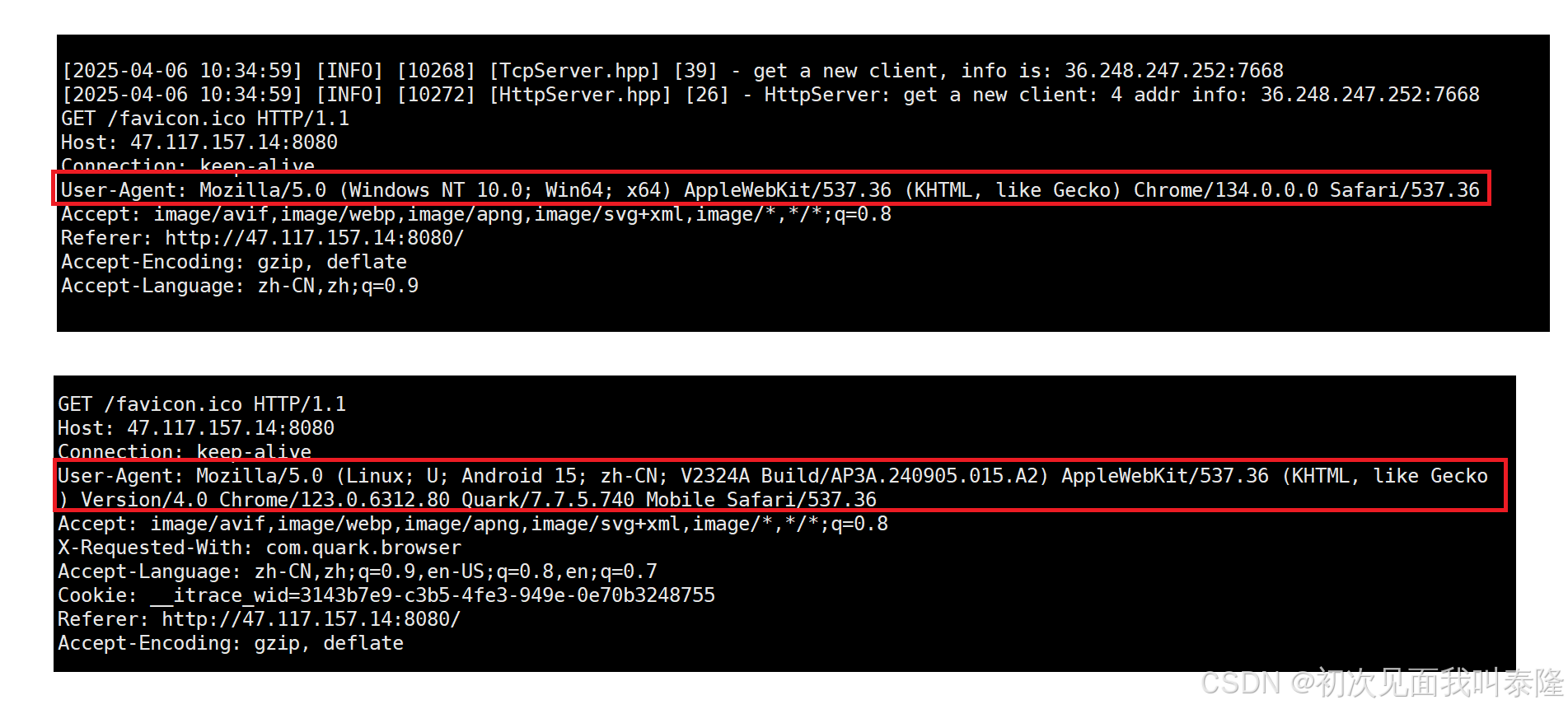
上图是我分别使用电脑浏览器和手机浏览器访问发送的请求,我们来看请求报头的User-Agent字段,上面我使用的是电脑浏览器,可以看到Windows NT 10.0 Win64的字段,下面我使用的是手机的浏览器,可以看到Linux Android 15的字段,因为手机的底层就是Linux操作系统。User-Agent表示的就是用户的客户端,你发起请求的时候就会带上这个信息,这也解释了为什么我们用电脑搜索一个软件默认显示的是电脑的下载安装包,而手机搜索一个软件默认显示的是Android的安装包,就是通过这个来区分的。
3.4、实现HttpProtocol.hpp中HttpRequest对请求信息进行处理和细化。
今天我们假设读取的报文是完整的,不做报文完整性的处理,降低复杂度。
// HttpProtocol.hpp
#pragma once
#include <iostream>
#include <string>
#include <vector>
#include <unordered_map>
#include <sstream>
const std::string Sep = "\r\n";
const std::string LineSep = " ";
const std::string HeaderLineSep = ": ";
const std::string BlankLine = Sep;
class HttpRequest
{
private:
// 将请求行的每个部分细化
void ParseReqLine(const std::string& _req_line, const std::string& sep)
{
std::stringstream ss(_req_line);
ss >> _method >> _uri >> _version;
}
// 将请求报头的KV细化
bool ParseHeaderkv()
{
std::string key, value;
for (auto& header : _req_header)
{
if (SplitString(header, &key, &value, HeaderLineSep))
{
_header_kv.insert(std::make_pair(key, value));
}
}
return true;
}
// 解析出报头尾插到_req_header中--复用ParseOneLine
bool ParseHeader(std::string& req_str)
{
std::string line;
while (true)
{
bool r = ParseOneLine(req_str, &line, Sep);
if (r && !line.empty())
{
_req_header.push_back(line);
}
else if (r && line.empty()) // 读到了空行
{
_blank_line = BlankLine;
break;
}
else
{
return false;
}
}
ParseHeaderkv();
return true;
}
public:
HttpRequest()
{}
~HttpRequest()
{}
void Deserialize(std::string& req_str)
{
if (ParseOneLine(req_str, &_req_line, Sep))
{
ParseReqLine(_req_line, LineSep);
ParseHeader(req_str);
_body = req_str;
}
Print();
}
void Print()
{
std::cout << "_method: " << _method << std::endl;
std::cout << "_uri: " << _uri << std::endl;
std::cout << "_version: " << _version << std::endl;
for (auto& kv : _header_kv)
{
std::cout << kv.first << " # " << kv.second << std::endl;
}
std::cout << "_blank_line: " << _blank_line;
std::cout << "_body: " << _body << std::endl;
}
private:
std::string _req_line; // 请求行
std::vector<std::string> _req_header; // 请求报头
std::string _blank_line; // 空行
std::string _body; // 请求正文
// 细化的内容
std::string _method; // 请求方式
std::string _uri; // 请求资源路径
std::string _version; // HTTP版本
std::unordered_map<std::string, std::string> _header_kv; // 请求报头KV
};
// Common.hpp
// 1.true&&字符串 2.true&&空串 3.false&&空串
bool ParseOneLine(std::string& req_str, std::string* out, const std::string& sep)
{
auto pos = req_str.find(sep);
if (pos == std::string::npos) return false;
*out = req_str.substr(0, pos);
req_str.erase(0, pos + sep.size());
return true;
}
bool SplitString(const std::string& header, std::string* key, std::string* value, const std::string& sep)
{
auto pos = header.find(sep);
if (pos == std::string::npos) return false;
*key = header.substr(0, pos);
*value = header.substr(pos + sep.size());
return true;
}
首先清楚HttpRequest需要有什么内容:请求行、请求报头、空行、请求正文,接着我们继续细化,将请求行的请求方法、请求UIR、HTTP版本都细化出来,再把请求报头KV结构用哈希表保存起来,将来要拿就很方便了。

如图,HttpRequest中实现反序列方法,首先将请求行提取出来,我们实现了一个统一的接口ParseOneLine,每次都根据分隔符\r\n提取一行信息通过输出型参数带出。提取出请求行之后对请求行进行细化处理,提取出请求方法、请求URI、HTTP版本信息。
接着再将请求报头以行的形式尾插到vector容器中,直接调用ParseOneLine每次提取出一行即可。根据ParseOneLine返回值和输出型参数out组合有三种情况:1、提取出一行字符串,返回true。2、提取出空字符串,返回true。3、提取失败返回false。通过返回值和输出型参数是否为空就可以知道是否提取完请求报头,提取完就break,然后继续细化请求报头。
细化请求报头就是将vector容器中的string一行一行拿出来拆分,通过分隔符: 将key和value提取出来,然后插入哈希表中,方便我们后续查找。
下面我们进行测试,是否能解析出信息:
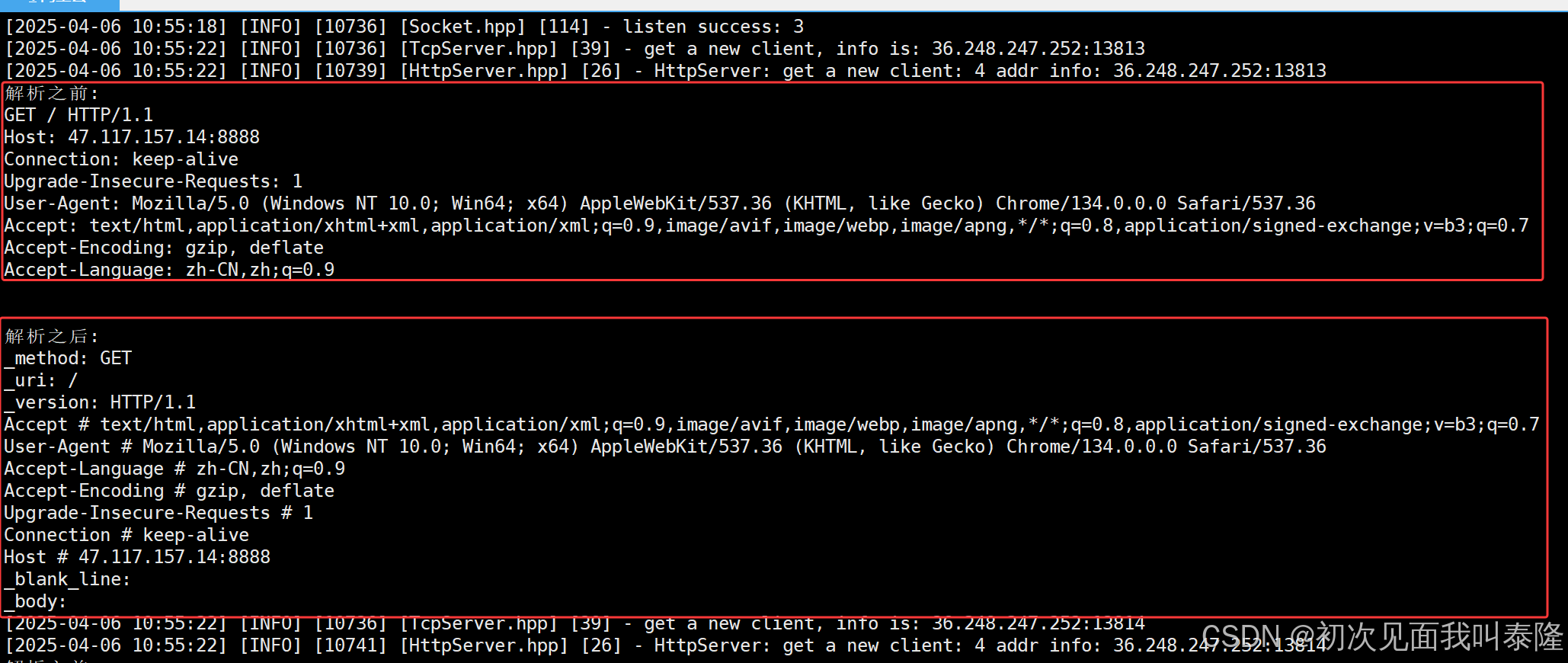
可以看到我们已经将http请求处理细化了。
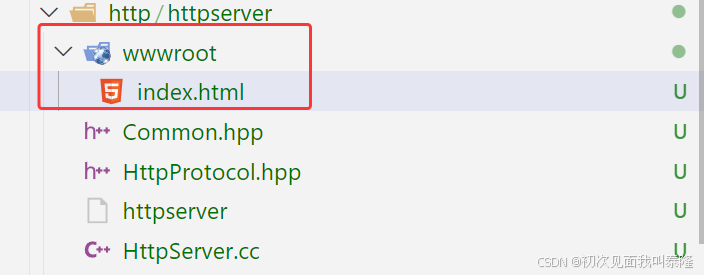
我们要返回网页信息肯定不能直接硬编码到C++代码中的,所以我们在当前目录下创建一个wwwroot文件夹,里面再创建一个index.html,这个文件就是将来访问服务器默认显示的网页信息。wwwroot这个目录我们称为web根目录,这个目录名字可以随便取,因为这个目录不会暴露给用户。
紧接着我们添加index.html信息:这个网页是用AI生成的,如果你有兴趣可以自己写一个。
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>简单电商网站</title>
<style>
body {
font-family: Arial, sans-serif;
margin: 0;
padding: 0;
background-color: #f7f7f7;
}
.header {
background-color: #333;
color: #fff;
padding: 10px 20px;
display: flex;
justify-content: space-between;
align-items: center;
}
.header h1 {
margin: 0;
font-size: 2em;
}
.header nav ul {
list-style: none;
margin: 0;
padding: 0;
display: flex;
}
.header nav ul li {
margin-left: 20px;
}
.header nav ul li a {
color: #fff;
text-decoration: none;
font-size: 1.2em;
}
.header nav ul li a:hover {
text-decoration: underline;
}
.main {
padding: 20px;
}
.product-grid {
display: grid;
grid-template-columns: repeat(auto-fit, minmax(200px, 1fr));
gap: 20px;
}
.product-card {
background-color: #fff;
padding: 10px;
border: 1px solid #ddd;
border-radius: 5px;
text-align: center;
}
.product-card img {
max-width: 100%;
height: auto;
border-radius: 5px;
}
.product-card h3 {
margin: 10px 0;
font-size: 1.2em;
}
.product-card p {
color: #666;
font-size: 0.9em;
margin-bottom: 10px;
}
.product-card button {
padding: 5px 10px;
background-color: #007bff;
color: #fff;
border: none;
border-radius: 5px;
cursor: pointer;
font-size: 1em;
}
.product-card button:hover {
background-color: #0056b3;
}
.footer {
background-color: #333;
color: #fff;
padding: 10px 20px;
text-align: center;
}
</style>
</head>
<body>
<header class="header">
<h1>简单电商网站</h1>
<nav>
<ul>
<li><a href="#">首页</a></li>
<li><a href="#">产品分类</a></li>
<li><a href="#">登录</a></li>
<li><a href="#">注册</a></li>
</ul>
</nav>
</header>
<main class="main">
<h2>热门产品</h2>
<div class="product-grid">
<div class="product-card">
<img src="/1.jpg" alt="产品1">
<h3>产品1</h3>
<p>这是产品1的描述信息。</p>
<button>加入购物车</button>
</div>
<div class="product-card">
<img src="/2.jpg" alt="产品2">
<h3>产品2</h3>
<p>这是产品2的描述信息。</p>
<button>加入购物车</button>
</div>
<div class="product-card">
<img src="/3.jpg" alt="产品3">
<h3>产品3</h3>
<p>这是产品3的描述信息。</p>
<button>加入购物车</button>
</div>
<!-- 可以继续添加更多产品卡片 -->
</div>
</main>
<footer class="footer">
<p>版权所有 © 2025 简单电商网站</p>
</footer>
</body>
</html>
用户请求的资源并不一定都存在,所以我们还需要提供一个404页面,如果用户请求资源不存在就返回404页面:在wwwroot目录下创建404.html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>404 页面未找到</title>
<style>
body {
font-family: Arial, sans-serif;
background-color: #f7f7f7;
margin: 0;
padding: 0;
}
.container {
max-width: 600px;
margin: 50px auto;
padding: 20px;
background-color: #fff;
box-shadow: 0 0 10px rgba(0, 0, 0, 0.1);
text-align: center;
}
h1 {
color: #333;
font-size: 2.5em;
margin-bottom: 20px;
}
p {
color: #666;
font-size: 1.2em;
line-height: 1.6;
margin-bottom: 30px;
}
a {
display: inline-block;
padding: 10px 20px;
background-color: #007bff;
color: #fff;
text-decoration: none;
border-radius: 5px;
font-size: 1.1em;
}
a:hover {
background-color: #0056b3;
}
</style>
</head>
<body>
<div class="container">
<h1>404 页面未找到</h1>
<p>抱歉,您请求的页面不存在。可能是链接错误或页面已被删除。</p>
<a href="/">返回首页</a>
</div>
</body>
</html>
3.5、实现HttpResponse构建响应信息
首先我们需要在HttpRequest中实现一个GetContent函数,将请求的uri资源——本质就是文件,读取出来返回。
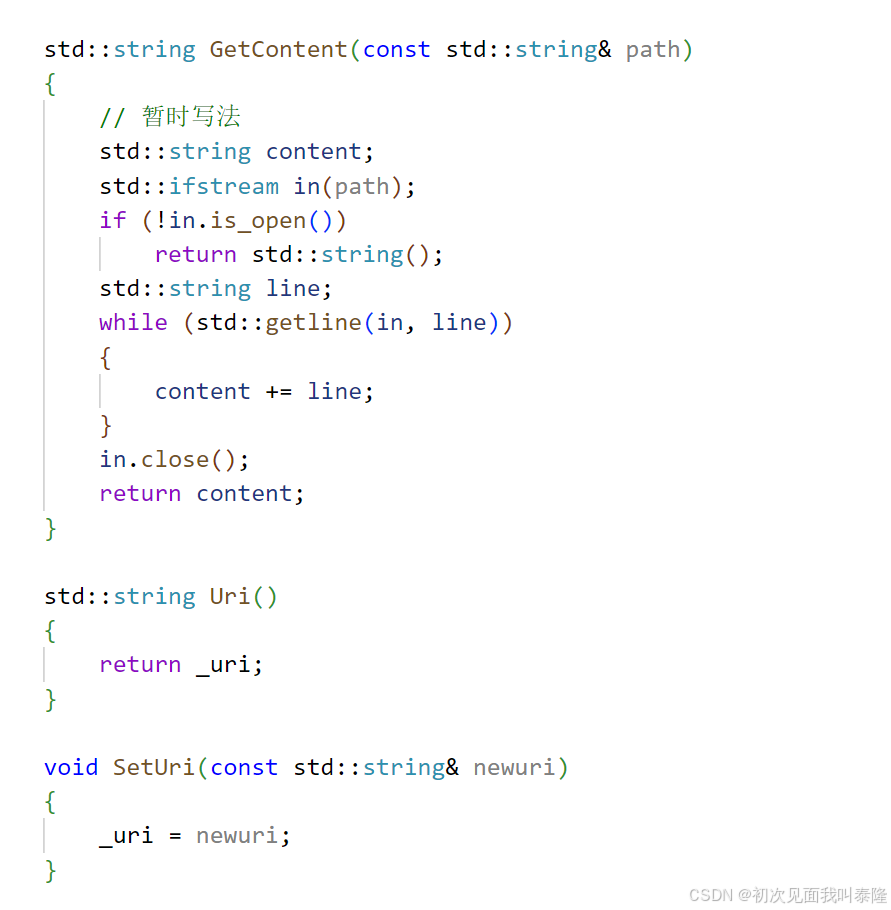
另外我们还需要两个函数,一个是获取HttpRequest的_uri,另一个是设置_uri,后面用得到。
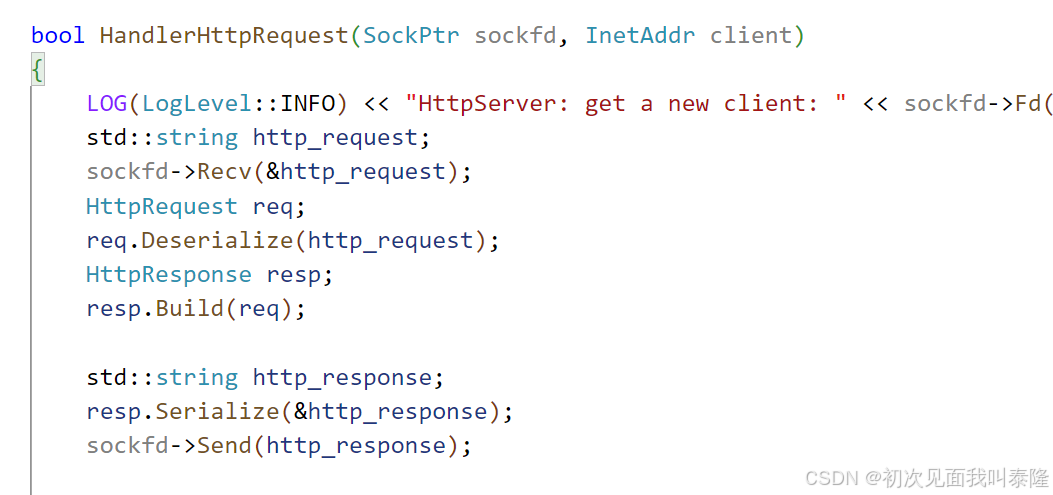
接着我们期望这样:将来在HandlerHttpRequest函数中,先获取请求,然后进行反序列化。紧接着创建一个HttpResponse对象,然后调用Build函数,将HttpRequest传入,Build会根据用户的请求填充HttpResponse对象的属性信息,然后再进行序列化,接着给对方发送过去。
下面就需要实现HttpResponse的部分代码:
class HttpResponse
{
private:
std::string Code2Desc(int code)
{
switch(code)
{
case 200:
return "OK";
case 404:
return "Not Found";
default:
return std::string();
}
}
public:
HttpResponse()
:_version(HttpVersion)
,_blank_line(BlankLine)
{}
~HttpResponse()
{}
void Build(HttpRequest& req)
{
std::string uri = DefaultHomePage + req.Uri();
if (uri.back() == '/')
{
uri += FirstPage;
}
_content = req.GetContent(uri);
if (_content.empty())
{
_status_code = 404;
_content = req.GetContent(Page404);
}
else
{
_status_code = 200;
}
_status_desc = Code2Desc(_status_code);
}
void Serialize(std::string* resp_str)
{
_resp_line = _version + LineSep + std::to_string(_status_code) + LineSep + _status_desc;
for (auto& kv : _header_kv)
{
_resp_header.push_back(kv.first + HeaderLineSep + kv.second);
}
_body = _content;
*resp_str = _resp_line + Sep;
for (auto& line : _resp_header)
{
*resp_str += line + Sep;
}
*resp_str += _blank_line;
*resp_str += _body;
}
private:
// 细化的内容
std::string _version; // HTTP版本
int _status_code; // 状态码
std::string _status_desc; // 状态码描述
std::string _content; // 获取的内容
std::unordered_map<std::string, std::string> _header_kv; // 响应报头KV
std::string _resp_line; // 状态行
std::vector<std::string> _resp_header; // 响应报头
std::string _blank_line; // 空行
std::string _body; // 响应正文
};
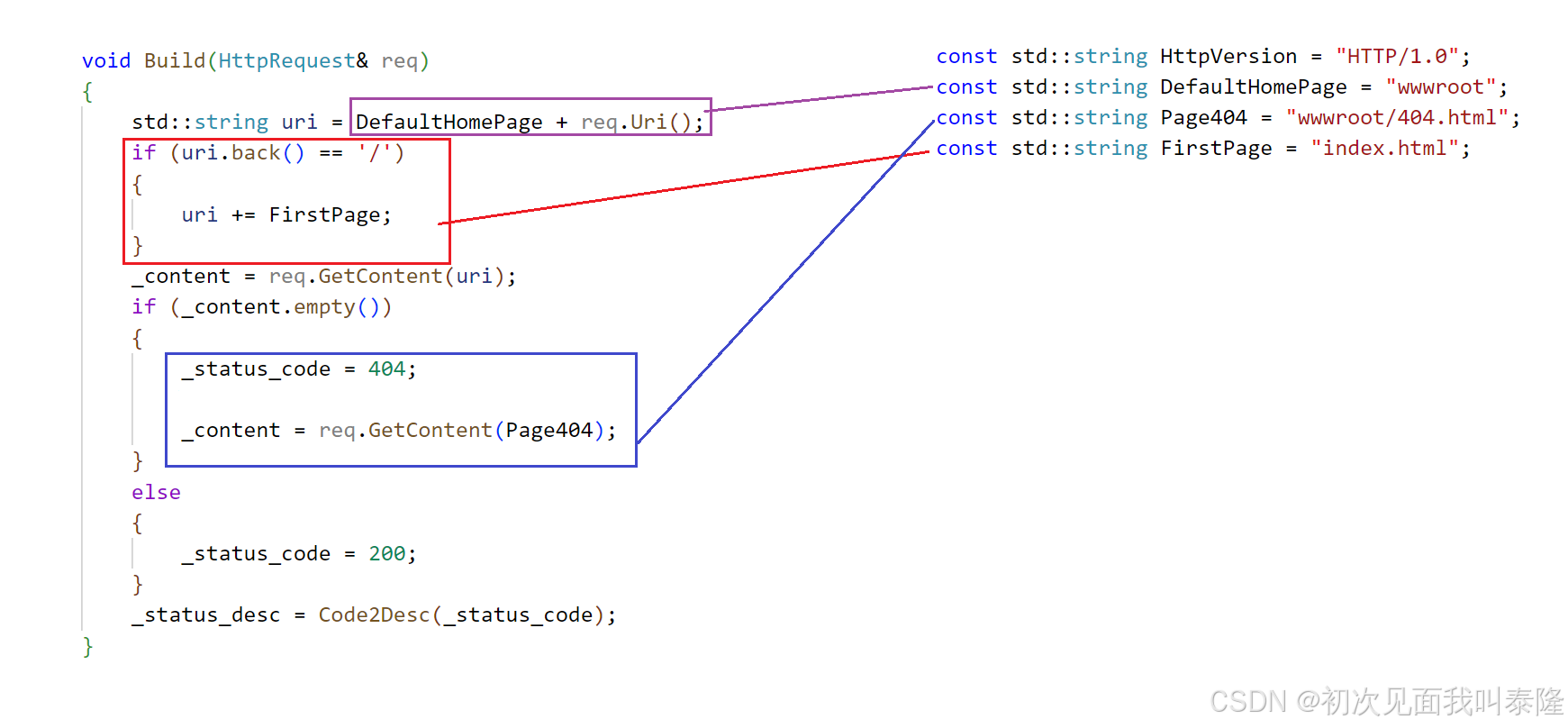
构造函数我们直接初始化版本为HTTP/1.0,Build中响应信息字段,用户传过来的uri可能是/或者/index.html,但是我们是从wwwroot开始的,所以需要在前面加上web根目录。接着判断,如果uri最后一个字符是/,要访问的就是该路径下的index.html文件,所以需要再后面加上index.html。接着我们传入uri读取文件,然后判断是否读取成功,如果读取失败说明不存在该资源,那么就获取404页面资源返回。同时我们需要设置状态码和状态码描述。
对于
对于http,任何请求,都要有应答。
下面先介绍两个状态码和状态码描述:


如果获取的资源存在设置状态码为200,如果不存在设置为404。同时实现一个Code2Desc,将状态码传入获取状态码描述。
最后通过Serialize序列化,然后将数据发送给客户端。
下面进行测试:
先使用telnet进行测试:
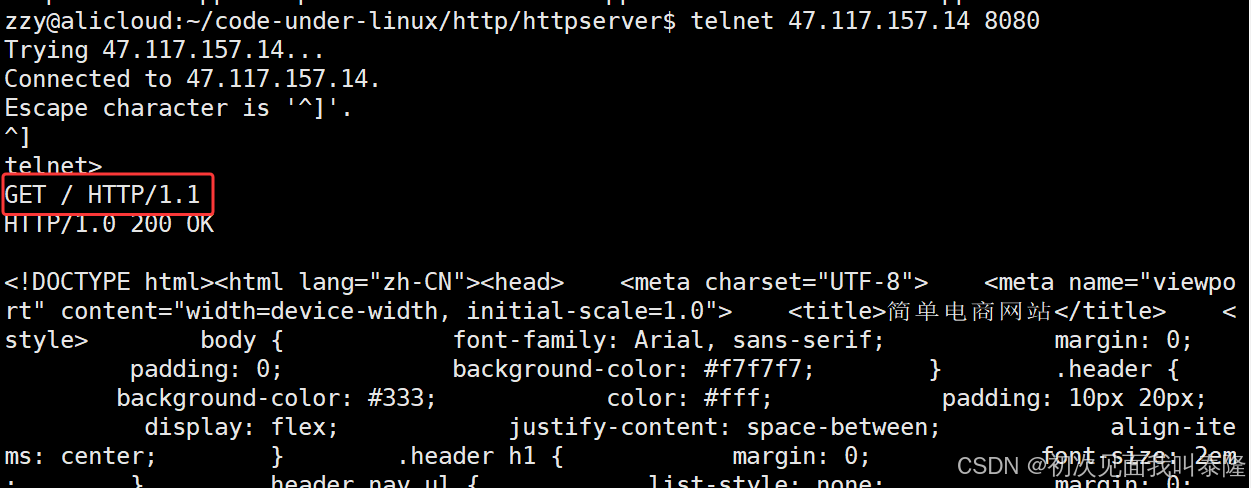
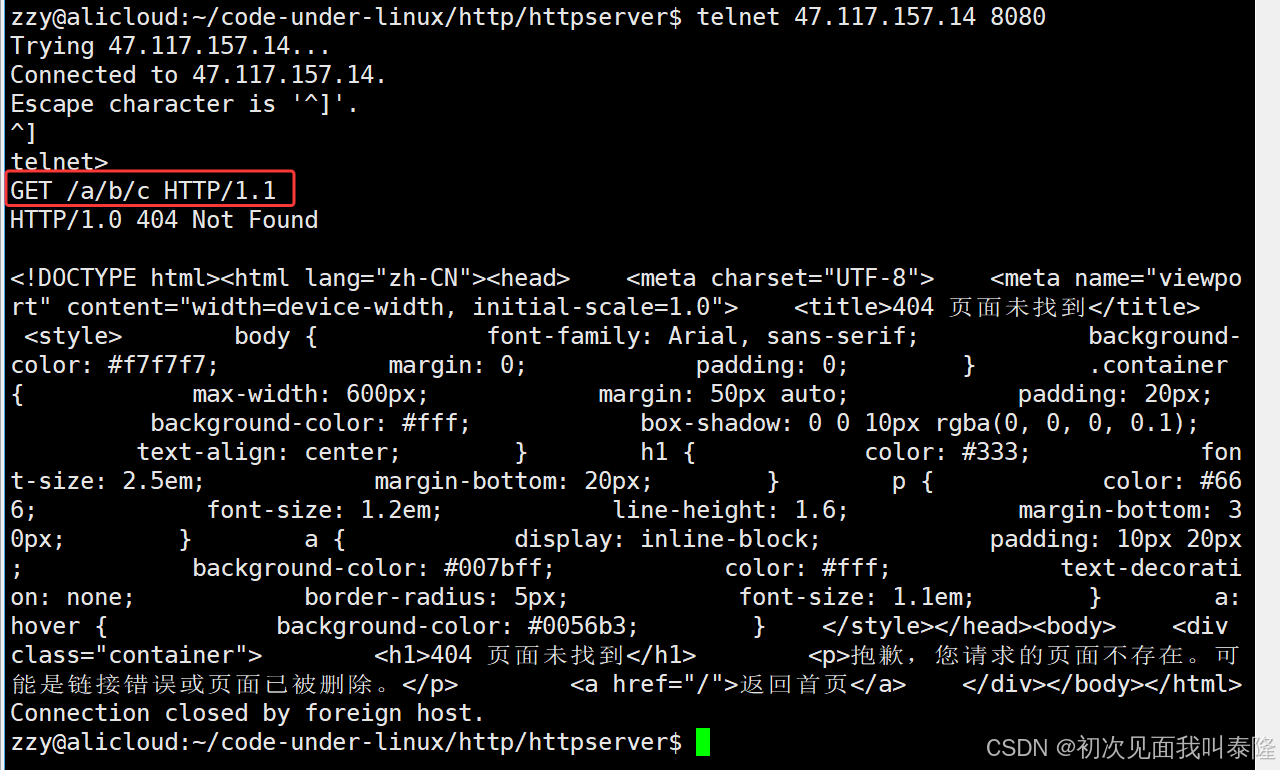
使用telnet进行测试发现没有问题,下面使用浏览器访问:
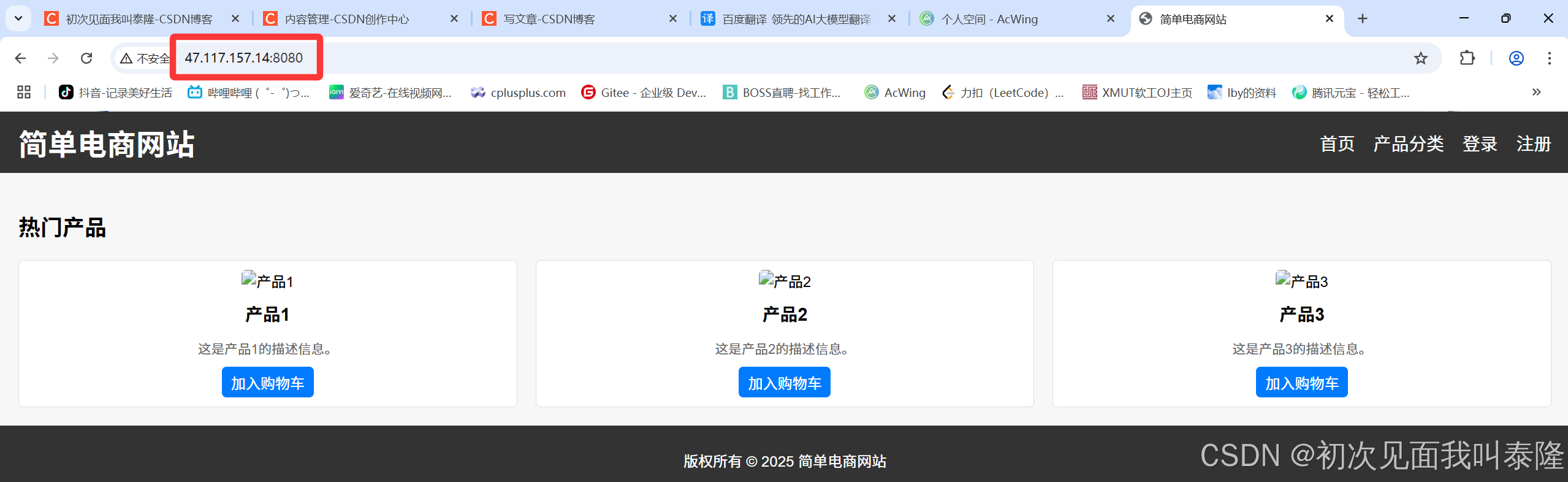
3.6、实现登录和注册页面的跳转
html中的<a>标签用于定义超链接,允许用户从一个页面跳转到另一个页面。
下面我们再实现两个页面,一个登录页面一个注册页面:**
下面是登录页面:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>登录页面</title>
<style>
body {
font-family: Arial, sans-serif;
background-color: #f7f7f7;
margin: 0;
padding: 0;
}
.login-container {
width: 300px;
margin: 100px auto;
padding: 20px;
background-color: #fff;
border: 1px solid #ddd;
border-radius: 5px;
box-shadow: 0 0 10px rgba(0, 0, 0, 0.1);
}
.login-container h2 {
text-align: center;
margin-bottom: 20px;
}
.login-container form {
display: flex;
flex-direction: column;
}
.login-container form label {
margin-bottom: 5px;
}
.login-container form input[type="text"],
.login-container form input[type="password"] {
padding: 10px;
margin-bottom: 10px;
border: 1px solid #ddd;
border-radius: 5px;
}
.login-container form button {
padding: 10px;
background-color: #007bff;
color: #fff;
border: none;
border-radius: 5px;
cursor: pointer;
}
.login-container form button:hover {
background-color: #0056b3;
}
.register-link {
text-align: center;
margin-top: 20px;
}
.register-link a {
color: #007bff;
text-decoration: none;
}
.register-link a:hover {
text-decoration: underline;
}
</style>
</head>
<body>
<div class="login-container">
<h2>登录</h2>
<!-- http://8.137.19.140:8999/login -->
<form action="/login" method="POST">
<label for="username">用户名:</label>
<input type="text" id="username" name="username" required>
<label for="password">密码:</label>
<input type="password" id="password" name="password" required>
<button type="submit">登录</button>
</form>
<div class="register-link">
没有账号?<a href="/register.html">立即注册</a></br>
<a href="/">回到首页</a>
</div>
</div>
</body>
</html>
下面是注册页面:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>注册页面</title>
<style>
body {
font-family: Arial, sans-serif;
background-color: #f7f7f7;
margin: 0;
padding: 0;
}
.register-container {
width: 300px;
margin: 100px auto;
padding: 20px;
background-color: #fff;
border: 1px solid #ddd;
border-radius: 5px;
box-shadow: 0 0 10px rgba(0, 0, 0, 0.1);
}
.register-container h2 {
text-align: center;
margin-bottom: 20px;
}
.register-container form {
display: flex;
flex-direction: column;
}
.register-container form label {
margin-bottom: 5px;
}
.register-container form input[type="text"],
.register-container form input[type="password"],
.register-container form input[type="email"] {
padding: 10px;
margin-bottom: 10px;
border: 1px solid #ddd;
border-radius: 5px;
}
.register-container form button {
padding: 10px;
background-color: #007bff;
color: #fff;
border: none;
border-radius: 5px;
cursor: pointer;
}
.register-container form button:hover {
background-color: #0056b3;
}
.login-link {
text-align: center;
margin-top: 20px;
}
.login-link a {
color: #007bff;
text-decoration: none;
}
.login-link a:hover {
text-decoration: underline;
}
</style>
</head>
<body>
<div class="register-container">
<h2>注册</h2>
<form action="/register" method="post">
<label for="username">用户名:</label>
<input type="text" id="username" name="username" required>
<label for="email">邮箱:</label>
<input type="email" id="email" name="email" required>
<label for="password">密码:</label>
<input type="password" id="password" name="password" required>
<label for="confirm-password">确认密码:</label>
<input type="password" id="confirm-password" name="confirm-password" required>
<button type="submit">注册</button>
</form>
<div class="login-link">
已有账号?<a href="/login.html">立即登录</a><br/>
<a href="/">回到首页</a>
</div>
</div>
</body>
</html>
紧接着修改主页index.html中超链接的路径:
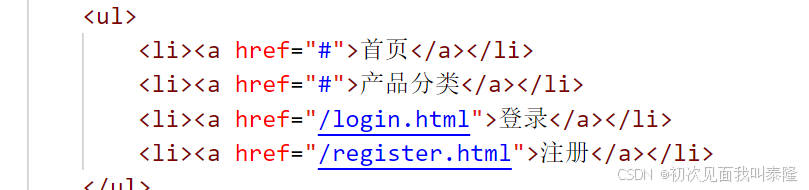
接着就可以实现点击登录、注册按钮实现跳转,并且可以返回主页。
3.7、添加http响应报头
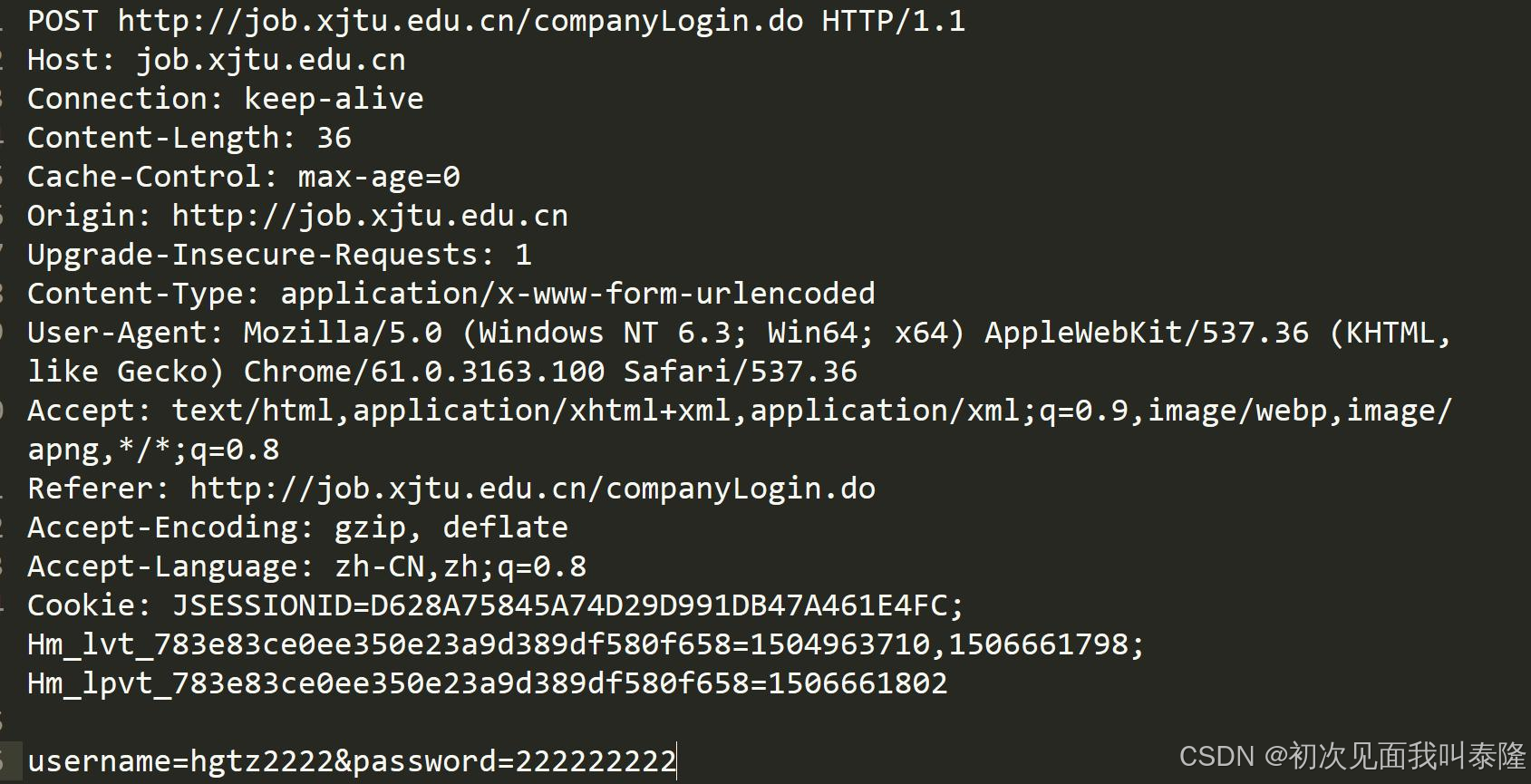
上图我们看到HTTP请求报头中是有许多字段的,比如Host表示主机,Connection表示保活的长连接,再比如Content-Length: 36表示的就是请求正文的长度。Accept表示的是客户端也就是浏览器可以接收的数据类型,Accept-Encoding表示可接受的编码。
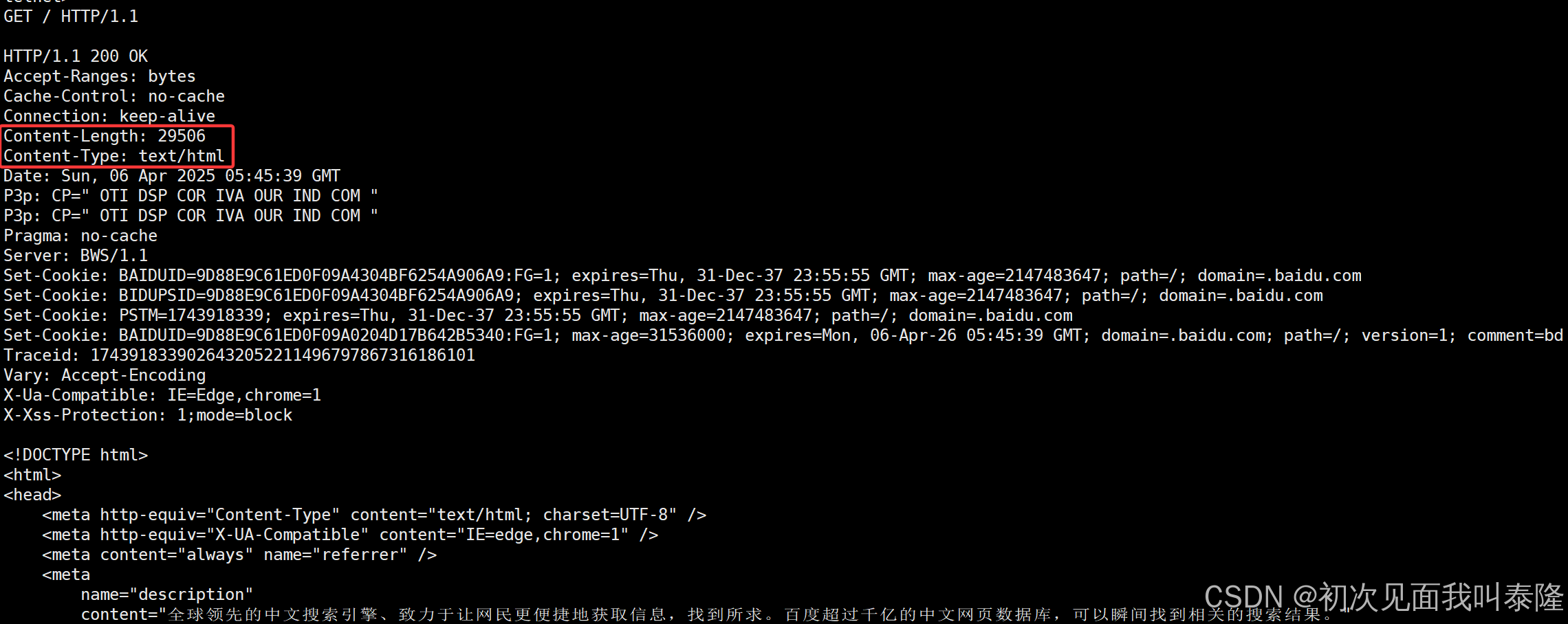
再看一个http响应信息,里面也包含了Content-Length表示的是响应正文的长度,还有Content-Type表示的是响应的内容是什么类型的,这里text/html表示的就是响应的内容是html文本。
因此,我们的http响应不能只有状态行和响应正文,应该再加上一些报头信息。我们先加上Content-Length和Content-Type字段。
添加Content-Length字段很简单,直接添加即可,但是如果要添加Content-Type字段,我们需要根据请求资源的后缀名来判断用户请求的是哪种资源:

现在Request中实现一个Suffix函数获取请求资源的后缀名。查找.然后将后面的内容截取出来就是后缀名了。如果用户访问/根目录,那么就查找不到,而访问/默认就是访问该目录下的首页index.html,因此我们直接返回.html后缀即可。

接着实现后缀转字符串信息,根据映射关系,可以网上查找Content-Type对应表,需要什么添加进来,也可以预处理好一张哈希表,然后需要什么直接通过后缀名映射到Mime-Type快速获取。
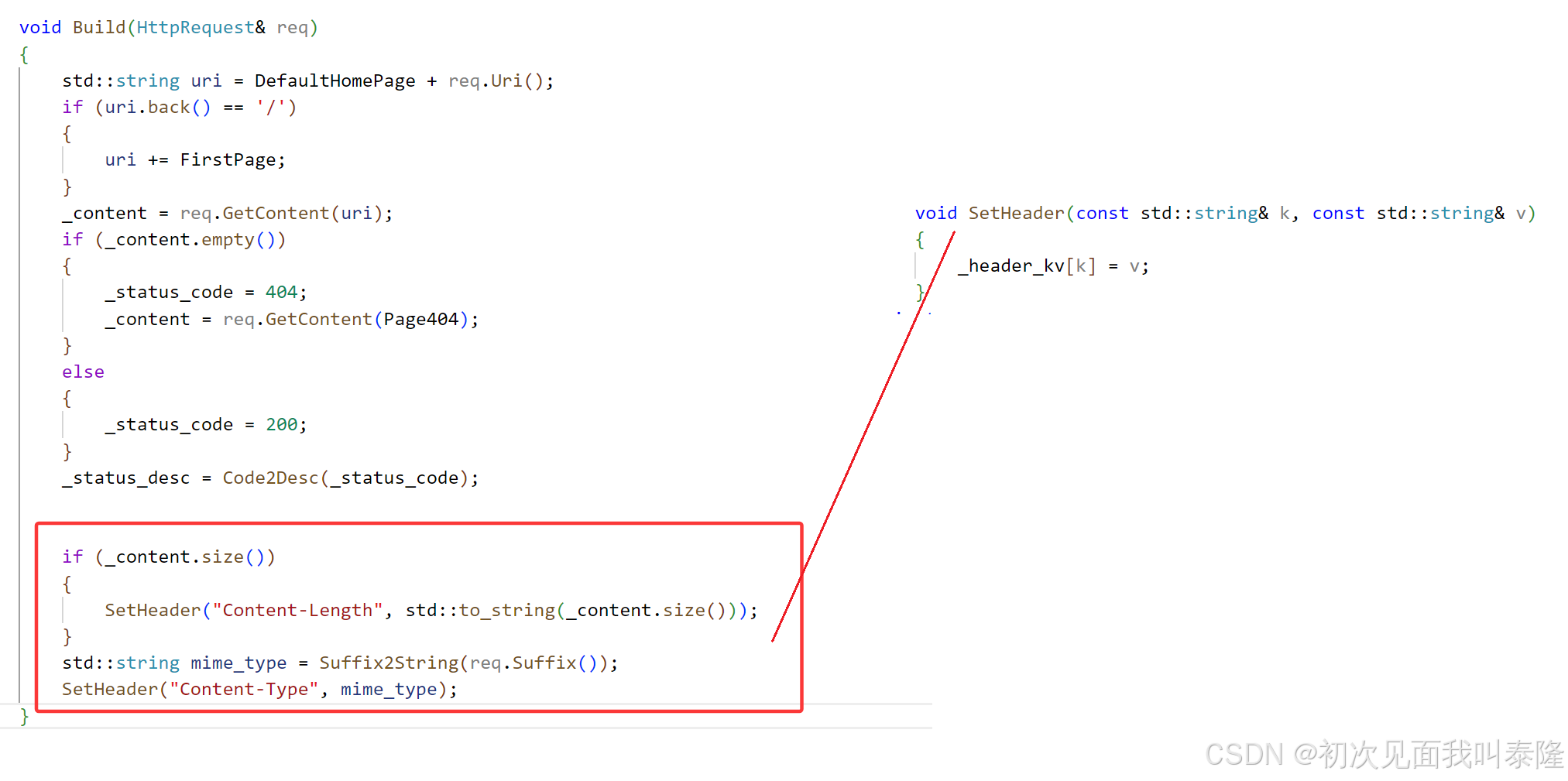
Build函数后面调用SetHeader方法将需要的字段设置进去,SetHeader函数就是直接调用oeprator[]建立key-value映射。
由于我们的html页面中还有图片,所以也添加上图片并设置路径:

那么下面进行测试:
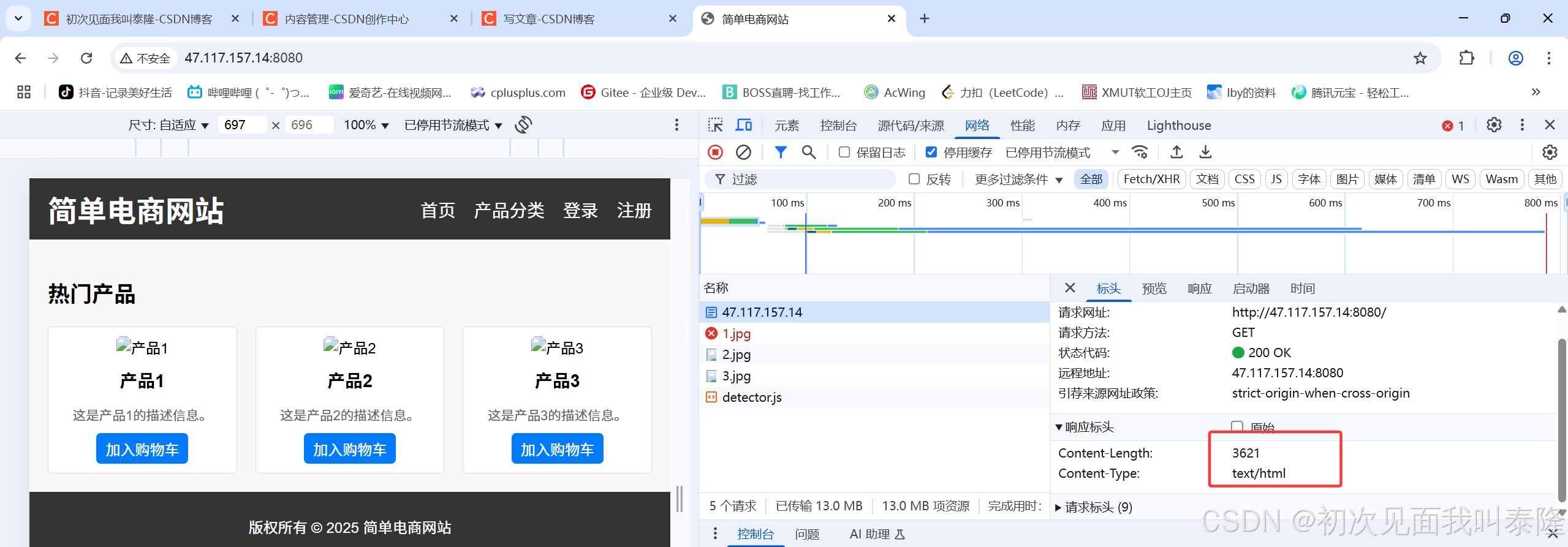
我们确实设置了响应标头了,但是图片还是获取不到,这是为什么?
因为图片是二进制信息,而我们GetContent直接用字符串读取,这样做是有问题的,所以不能直接用字符串读取。

我们使用二进制方式打开文件,然后第一次调用seekg将文件位置设置到结尾,然后获取文件当前位置也就是获取文件的大小,再把位置改到文件开头。然后先给content开filesize大小的空间,接着再将这些数据读到content的缓冲区返回。
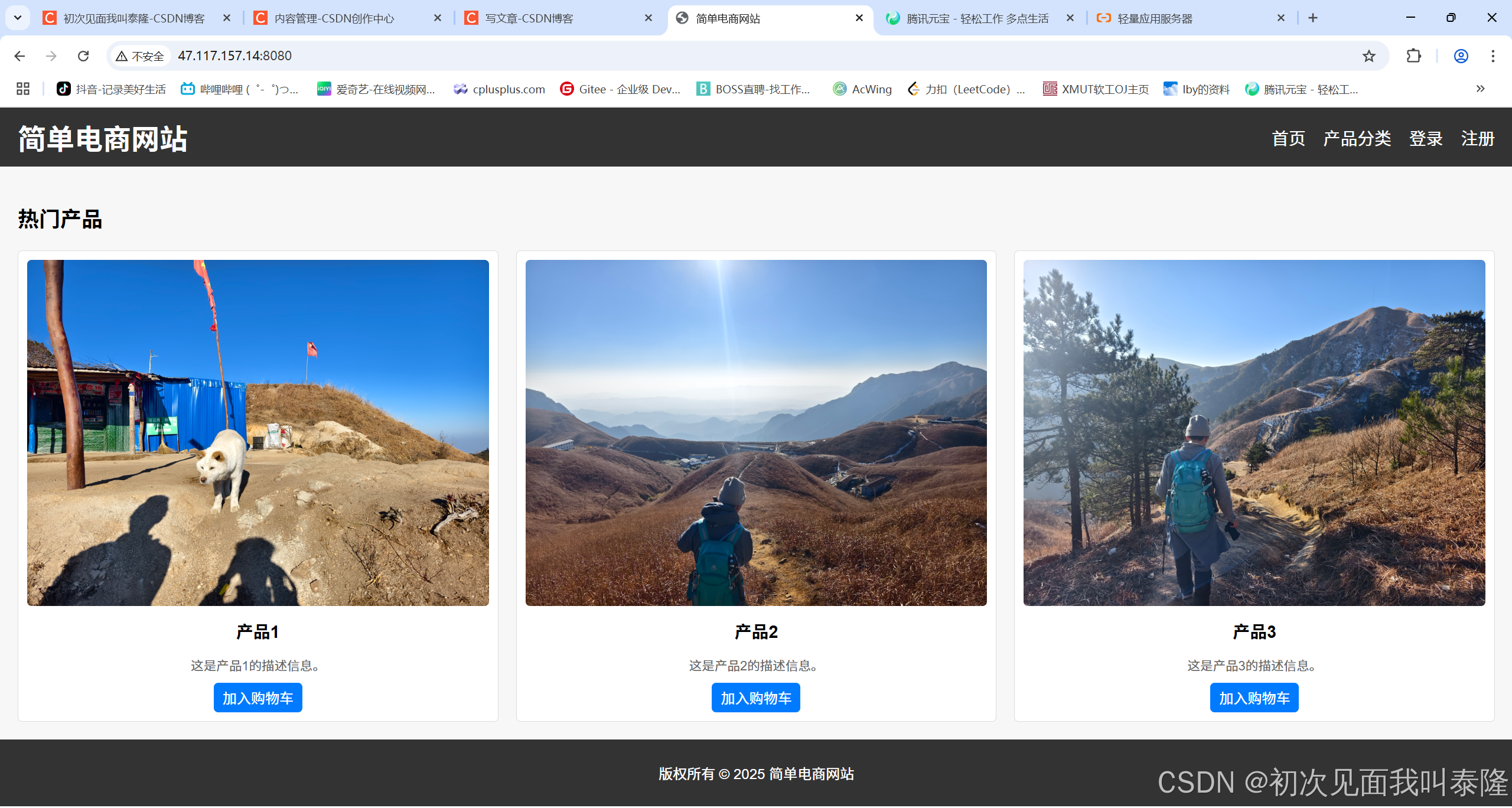
如图,这时候就可以获取图片了。
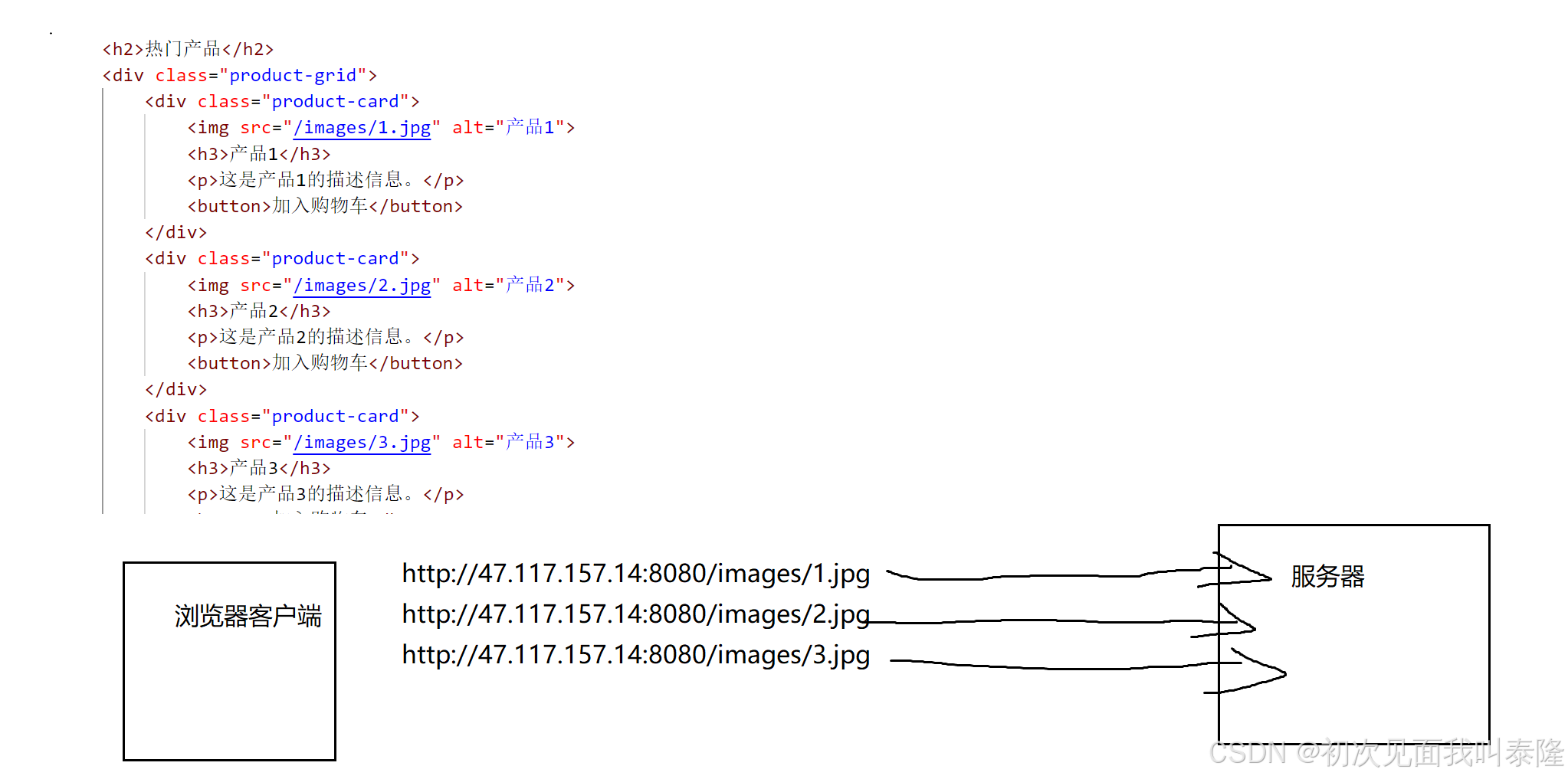
如图,一张网页并不是仅仅只有html文件内容,可能还由其他资源构成,比如图片视频等。上面我们返回的首页还有三张图片信息,所以浏览器也要发起请求这三张图片资源,因此我们响应的时候需要加上Content-Type表明服务器给浏览器客户端返回的响应正文属于什么类型的数据。当然如果不加浏览器也可以获取显示出来,因为现在浏览器的功能是非常强大的。
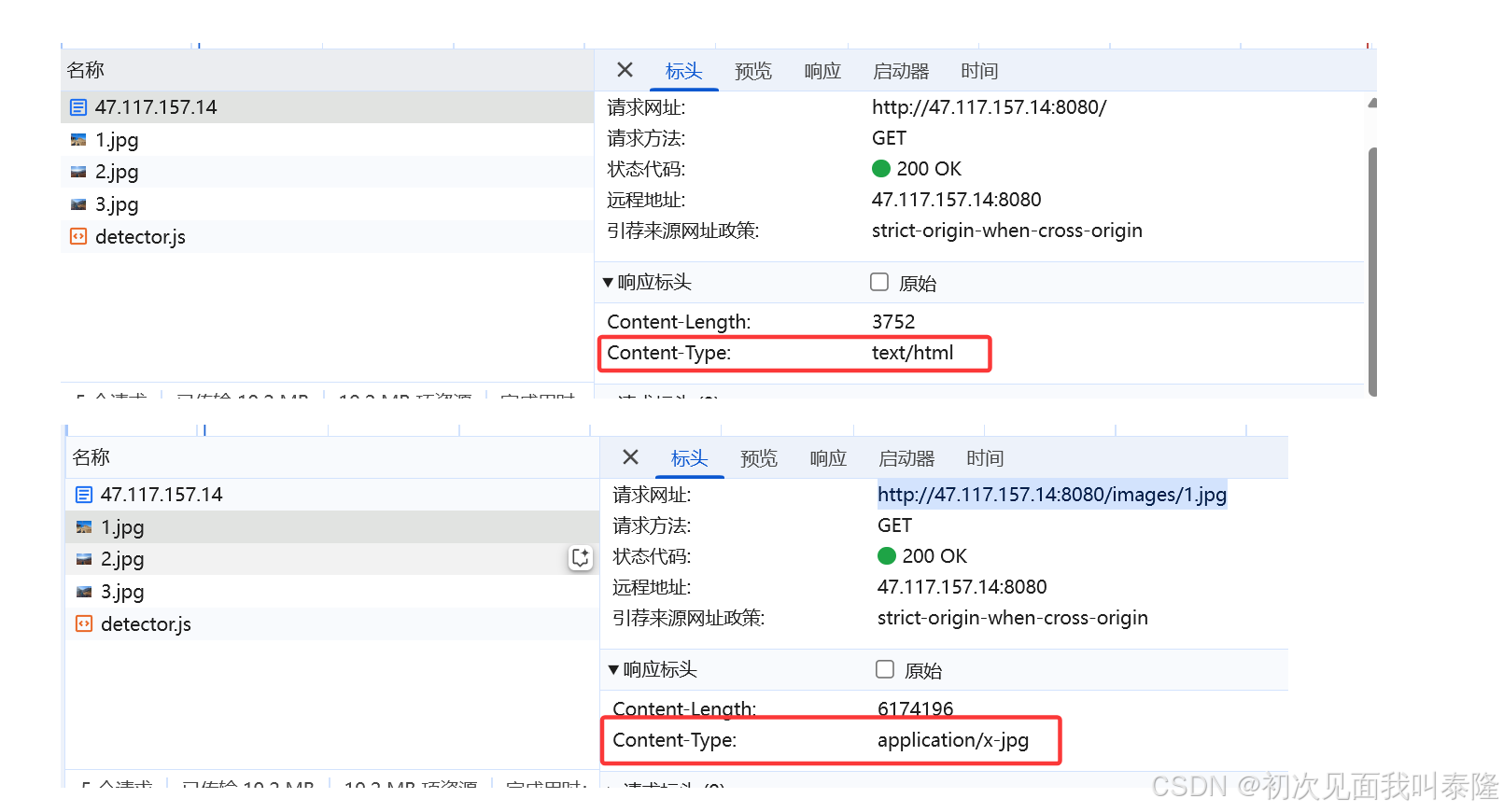
如上图,对于图片和html内容,我们都正确的返回了Content-Type和Content-Length字段信息。如果将来你需要返回其他资源比如视频等,可以继续再Suffix2String中添加其他字段。
3.8、HTTP常见Header
Content-Length: Body的长度。
Host: 客户端告知服务器,所请求的资源是在哪个主机的哪个端口上。
User-Agent: 声明用户的操作系统和浏览器版本信息。
Referer: 当前页面是从哪个页面跳转过来的。
Location: 搭配 3xx 状态码使用,告诉客户端接下来要去哪里访问。
Cookie: 用于在客户端存储少量信息。通常用于实现会话(session)的功能。
Content-Length上面我们已经见过了,用来表示正文内容长度。User-Agent上面我们也已经说过了,下面重点看其他的。
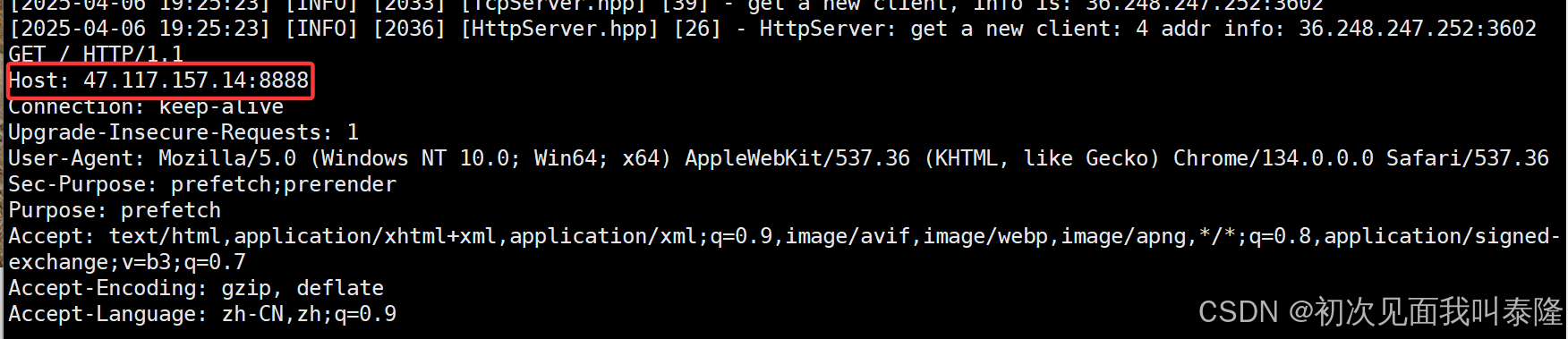
我们发现浏览器发起请求的时候会携带Host,包含了目标IP地址加端口号。那么为什么还要加这个Host字段呢?这不就是给我的服务器的请求吗?网址不是已经有了吗?这是因为今天我们请求的资源就是我这台服务器的资源,但是有没有下面这样一种可能?
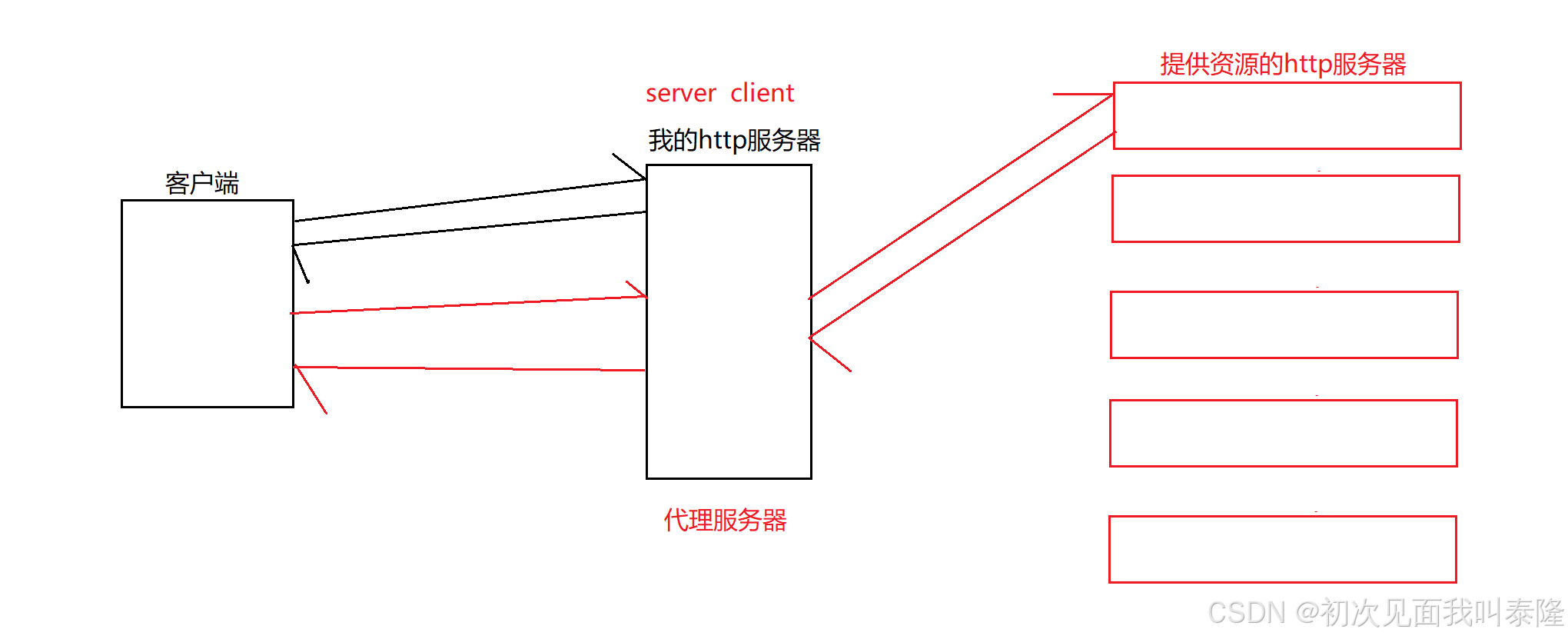
原来客户端也就是浏览器直接向我的http服务器请求资源,然后我的http服务器直接将资源返回给客户端。现在客户端向我的http服务器发起请求,但是今天我的http服务器只做读取请求,然后让我的http服务器再充当客户端向提供资源的http服务器发起请求,然后提供资源的http服务器将资源返回给我的http服务器,然后我的http服务器再返回给客户端。这时候,我的http服务器就是代理服务器。
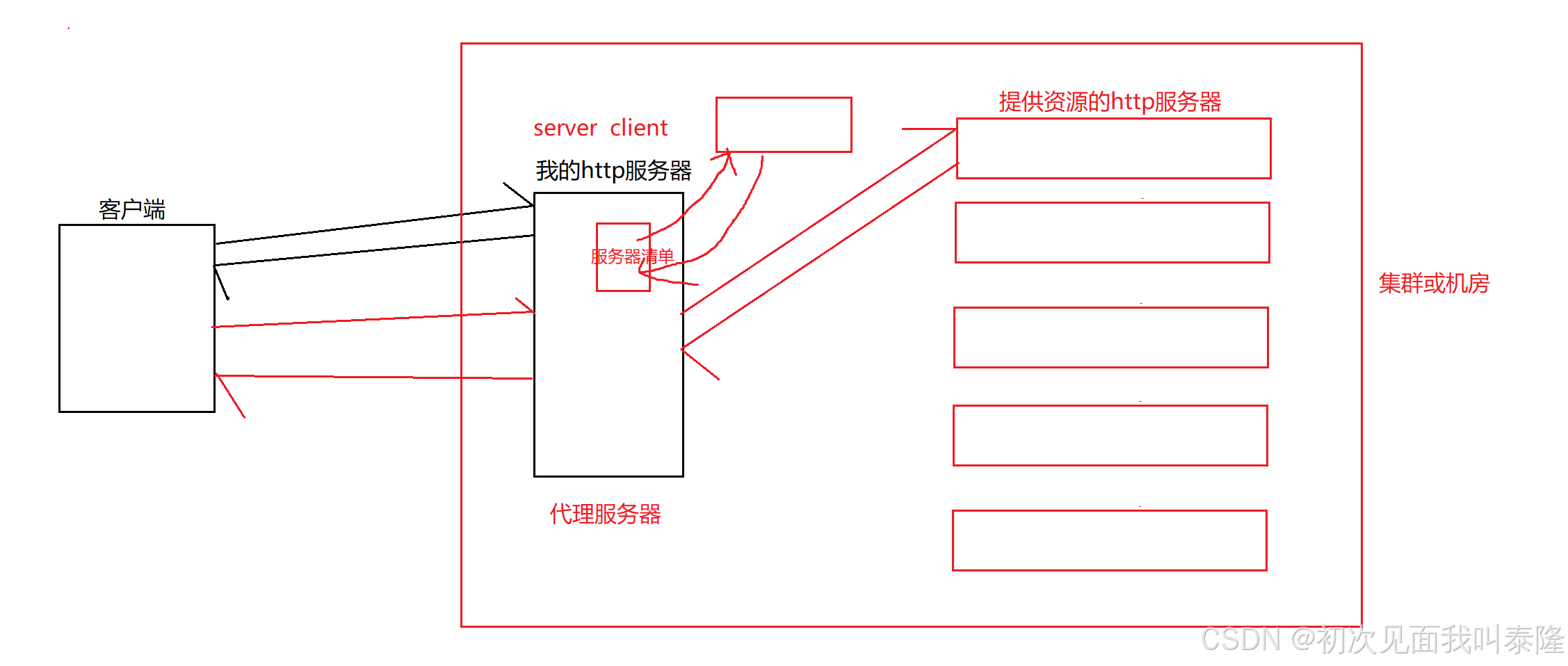
在公司一般都会有集群或机房,当我们请求资源就先到代理服务器,然后代理服务器再将请求通过轮询或随机的方式向其中一台提供资源的服务器请求资源,然后获取资源再返回给用户。这样就可以做到转发与负载均衡。那么代理服务器可以每隔一段时间从一台服务器中将提供资源的服务器清单拉下来,然后就可以将请求分散给不同的服务器。那么提供资源的服务器在启动的时候就将自己的数据写入到服务器中,后面代理服务器拉取清单的时候就会获取到。
Referer表示当前页面是从哪个页面跳转过来的,下面用我的实现的http服务器做测试,我们将用户请求信息打印出来:

上图是从首页点击登录跳转到登录页面的请求,可以看到请求的uri为/login.html,Referer就是根目录。

上图是从登录页面点击注册跳转到注册页面的请求,可以看到uri为/register.html,Referer就是原来的登录页面。
3.9、HTTP状态码
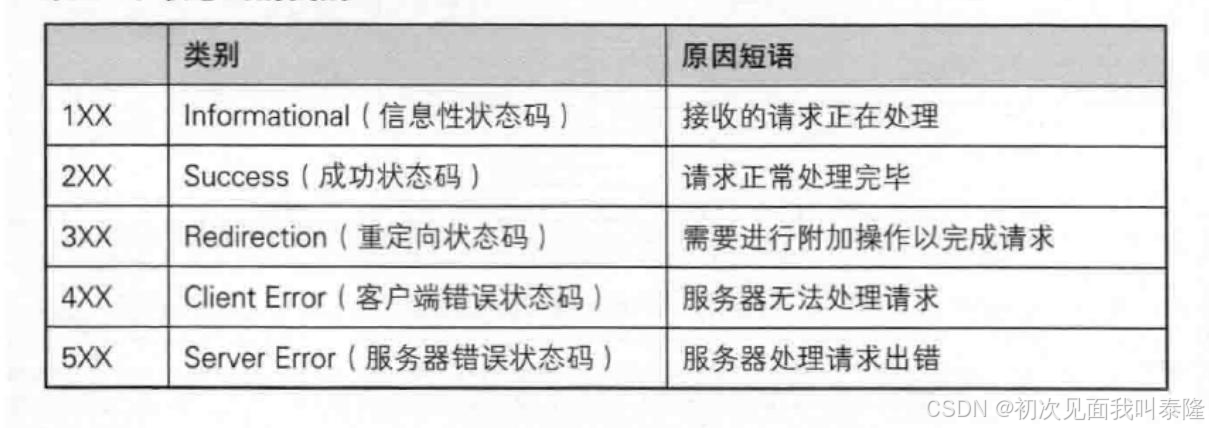

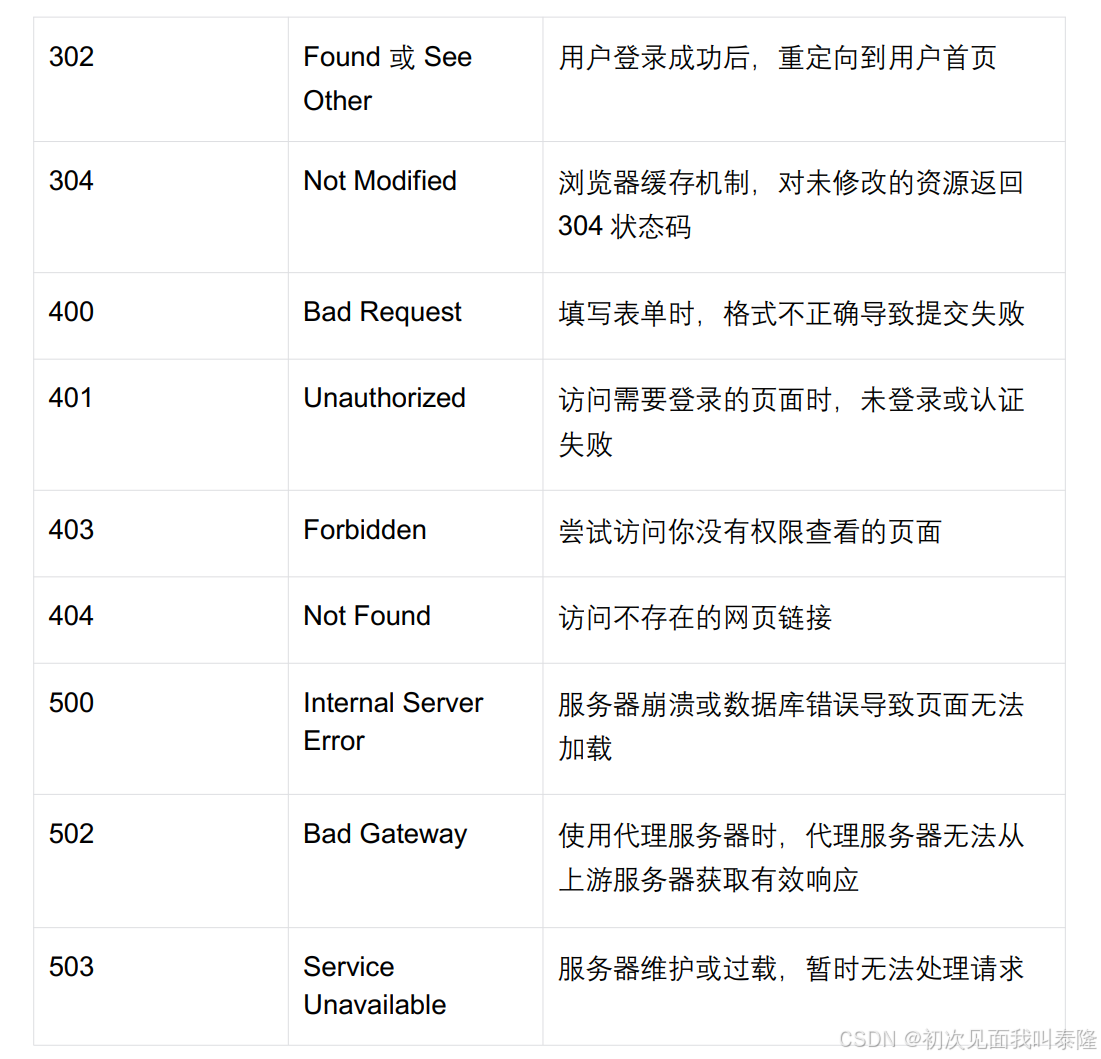
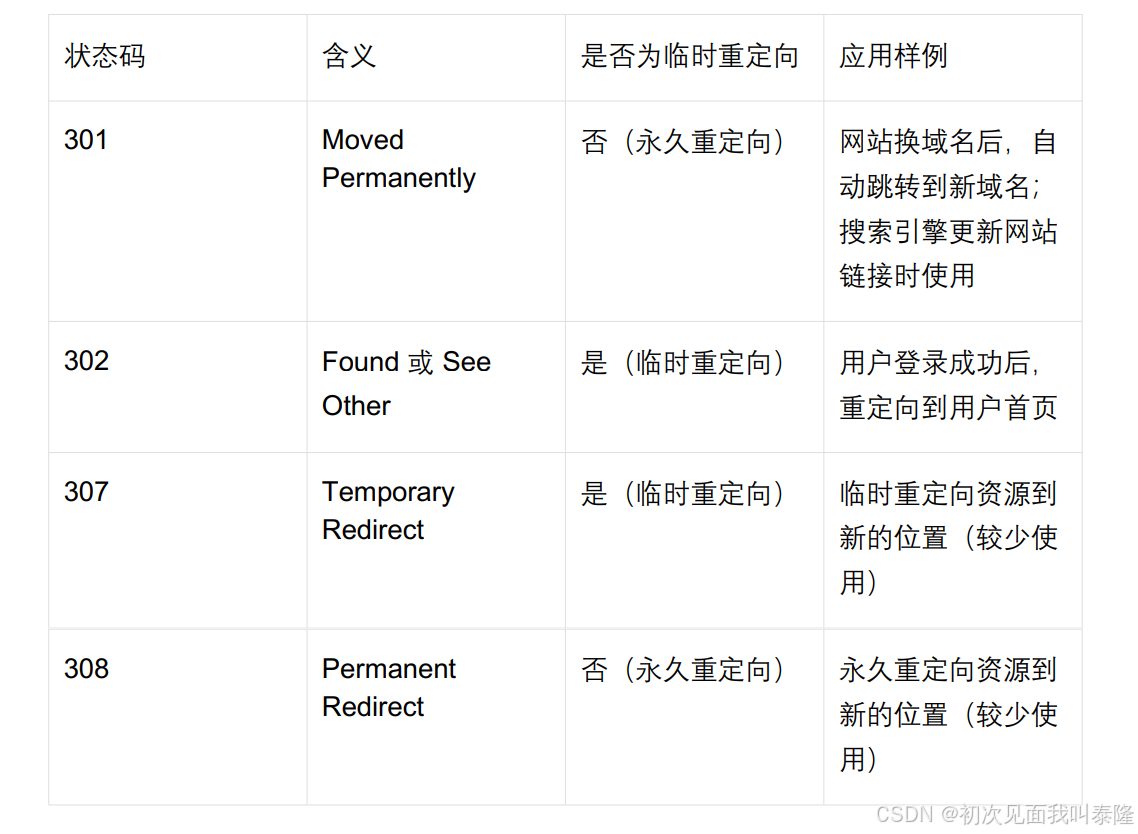
最常见的状态码, 比如 200(OK),404(Not Found),403(Forbidden),302(Redirect, 重定向),504(Bad Gateway)。
HTTP 状态码301(永久重定向)和302(临时重定向)都依赖 Location 选项。以下是关于两者依赖 Location 选项的详细说明:
HTTP 状态码301(永久重定向):
当服务器返回HTTP301状态码时,表示请求的资源已经被永久移动到新的位置。
在这种情况下,服务器会在响应中添加一个 Location 头部,用于指定资源的新位置。这个 Location 头部包含了新的URL地址,浏览器会自动重定向到该地址。
HTTP 状态码302(临时重定向):
当服务器返回HTTP302状态码时,表示请求的资源临时被移动到新的位置。
同样地,服务器也会在响应中添加一个 Location 头部来指定资源的新位置。浏览器会暂时使用新的 URL 进行后续的请求,但不会缓存这个重定向。
下面在我们的代码中添加301和302的状态码描述,然后我们对于所有请求都直接返回一个重定向的状态码和一个Location地址:
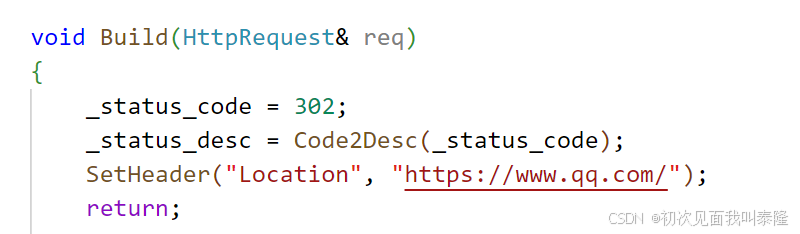
当输入47.117.157.14:8080访问首页时,就会返回302状态码,和Location字段信息。所以会直接重定向到qq网页。
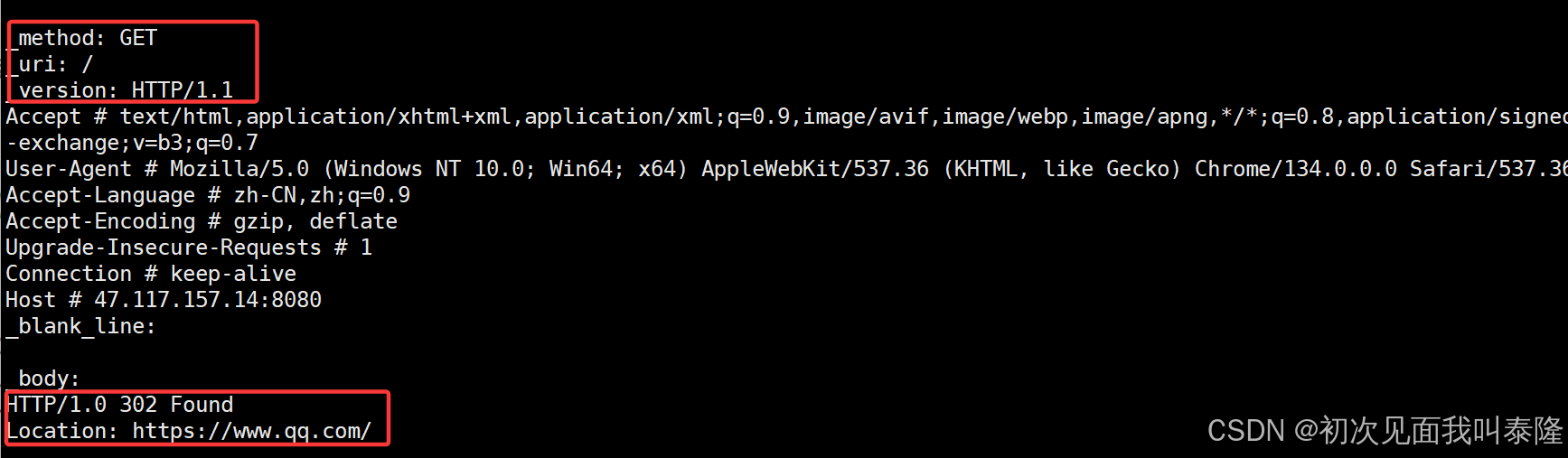
当我们访问服务器时,服务返回信息。然后浏览器根据返回的状态码发现是302,然后找到Location再次去请求qq网页资源。所以就重定向到qq网页了。
302时临时重定向,比如我们用户登录后临时重定向到首页。而301表示永久重定向,比如我的网站域名原来是www.a.com,后来我域名换了变成www.b.com,但是老用户记得都是www.a.com所以它们都会通过这个域名去访问,那么这时候就需要将访问老域名重定向新的域名。这时候就是永久重定向,因为我的老域名已经不再用了。
但是更主要还是用于搜索引擎,搜索引擎需要把一张一张网页信息拉到自己服务器上,然后将他们整理一下,将来用户输入搜索后,就根据用户输入信息跟服务器上的信息比对,然后给用户返回网站信息。而对于一些热门的网站,搜索引擎每隔一段时间都要去P一下,如果发现老域名不用了,重定向到新域名了,就需要将新域名的信息更新到自己的服务器上。
3.10、HTTP的方法
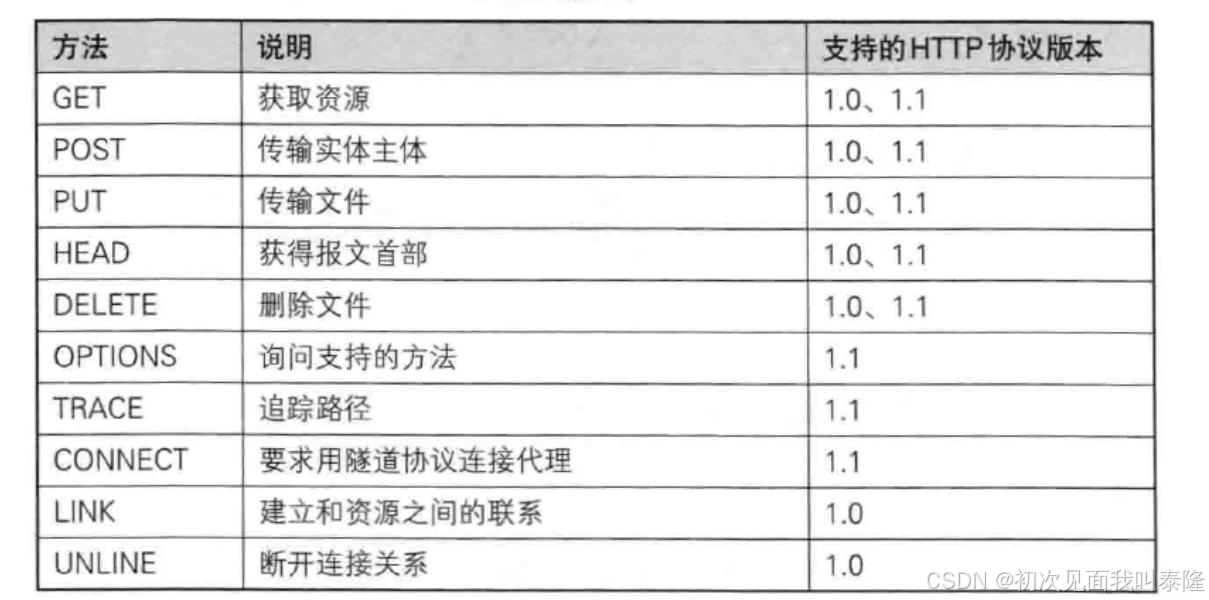
1、GET 方法(重点)
用途:用于请求 URL 指定的资源。
示例: GET /index.html HTTP/1.1
特性:指定资源经服务器端解析后返回响应内容。
2、POST 方法(重点)
用途:用于传输实体的主体,通常用于提交表单数据。
示例: POST /submit.cgi HTTP/1.1
特性:可以发送大量的数据给服务器,并且数据包含在请求体中。
3、PUT 方法(不常用)
用途:用于传输文件,将请求报文主体中的文件保存到请求 URL 指定的位置。
示例: PUT /example.html HTTP/1.1
特性:不太常用,但在某些情况下,如 RESTful API 中,用于更新资源。
4、HEAD 方法
用途:与 GET 方法类似,但不返回报文主体部分,仅返回响应头。
示例: HEAD /index.html HTTP/1.1
特性:用于确认 URL 的有效性及资源更新的日期时间等。
5、DELETE 方法(不常用)
用途:用于删除文件,是 PUT 的相反方法。
示例: DELETE /example.html HTTP/1.1
特性:按请求 URL 删除指定的资源。
6、OPTIONS 方法
用途:用于查询针对请求 URL 指定的资源支持的方法。
示例: OPTIONS * HTTP/1.1
特性:返回允许的方法,如 GET、 POST 等。
以上方法最常见的就是GET和POST方法。
我们获取的html、图片、视频、css、js等都是静态资源。
我们可以从服务器上获取资源,也可以上传我们的数据到服务器,比如登录需要将我的账户密码信息上传。所以如果要上传数据到服务器,那么服务器就需要对我的数据进行处理,这就是交互式网站。
获取资源我们一般采用的是GET方法,上传数据一般采用的是POST方法。当然GET方法也可以上传数据。
那么一般网页中会有input标签,然后我们输入信息后点击提交就会将我们输入的数据上传到服务器,下面来看之前的登录页面:
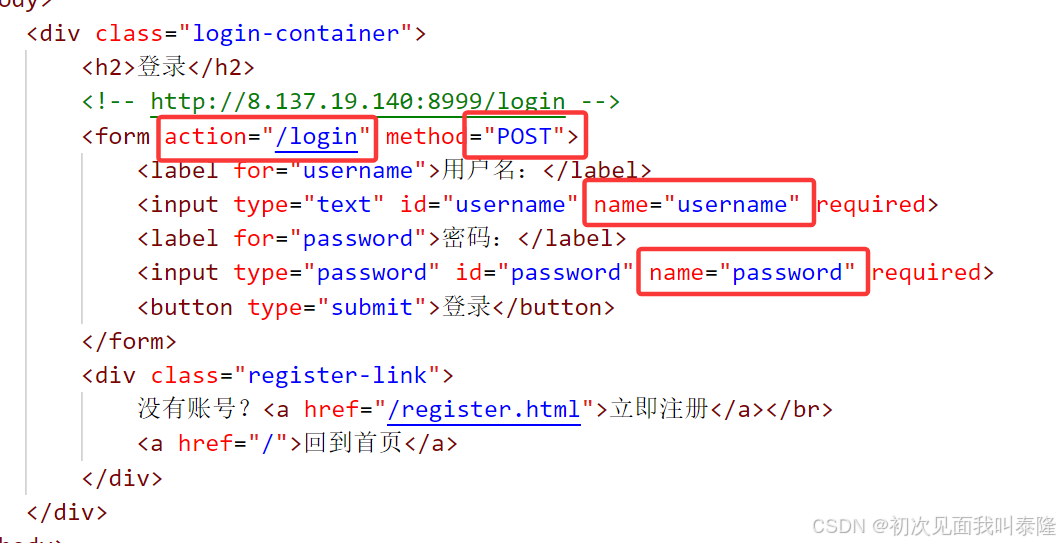
如图,input标签输入的信息,当我们点击登陆后,就会请求action:/login,也就是我们的IP地址+端口号+action->47.117.157.14:8080/login,同时会将输入框的数据作为参数传给服务器。
那么下面我们进行测试,先将表单的提交方式改为GET进行测试:
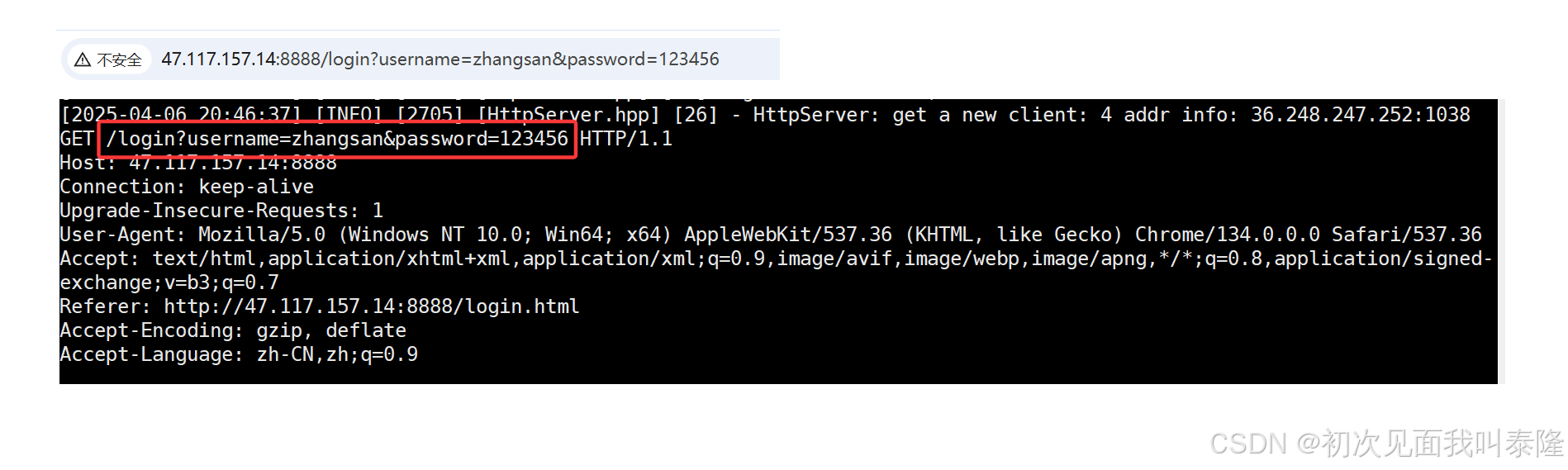
我们在登录页面输入用户名zhangsan,密码为123456,然后点击登录,接着我们发现上方的网址跳转成了/login?..,问号后面的就是参数,有两个参数:username=zhangsan,password=123456。然后在Linux终端我们看到请求的uri后面也带了参数。
通过GET方法提交参数,提交的参数是拼接到url后面的。通过/xxx?k=v&k=v的方式。
下面把提交form表单的方式改成POST继续测试:
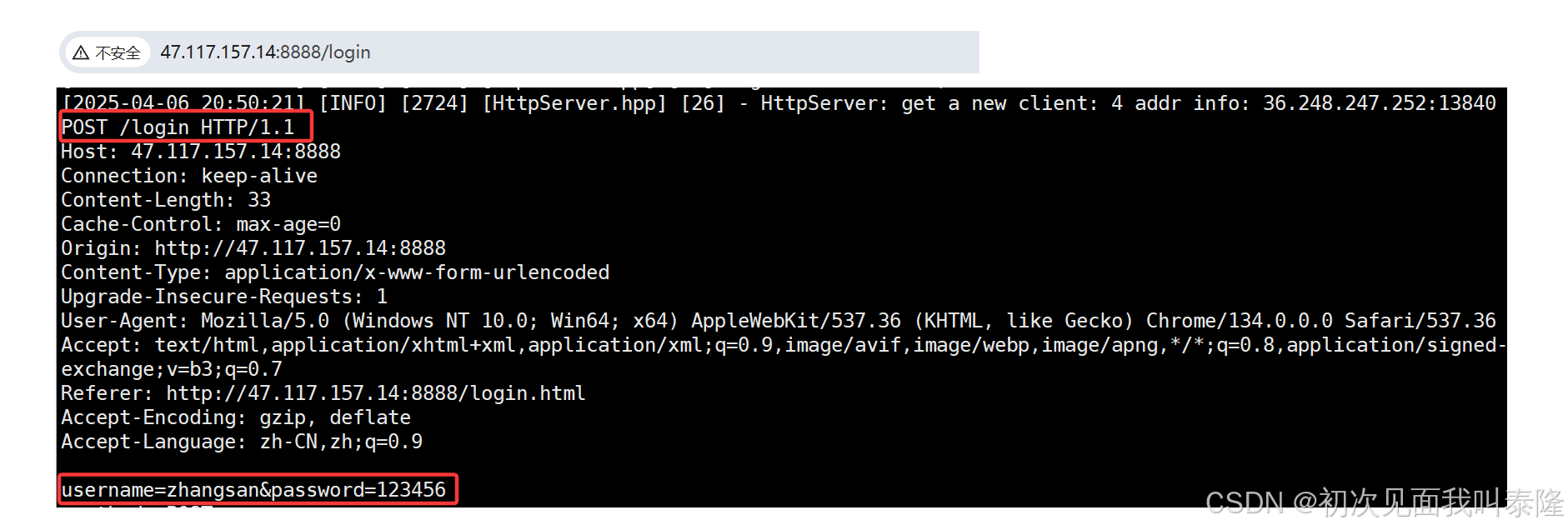
输入的内容不变,然后点击提交。接着我们看到网址变成了/login,然后查看输出的请求信息,我们发现uri就是/login,而参数则是在body部分传递给了服务器。
因此POST方法是通过正文传参的!
GET方法通常获取网页内容,POST通常用来上传数据。
GET传参通过url,POST传参通过body。
不能说POST方法比GET安全,只能说POST方法传参更私密。
3.11、实现HttpServer提供动态功能
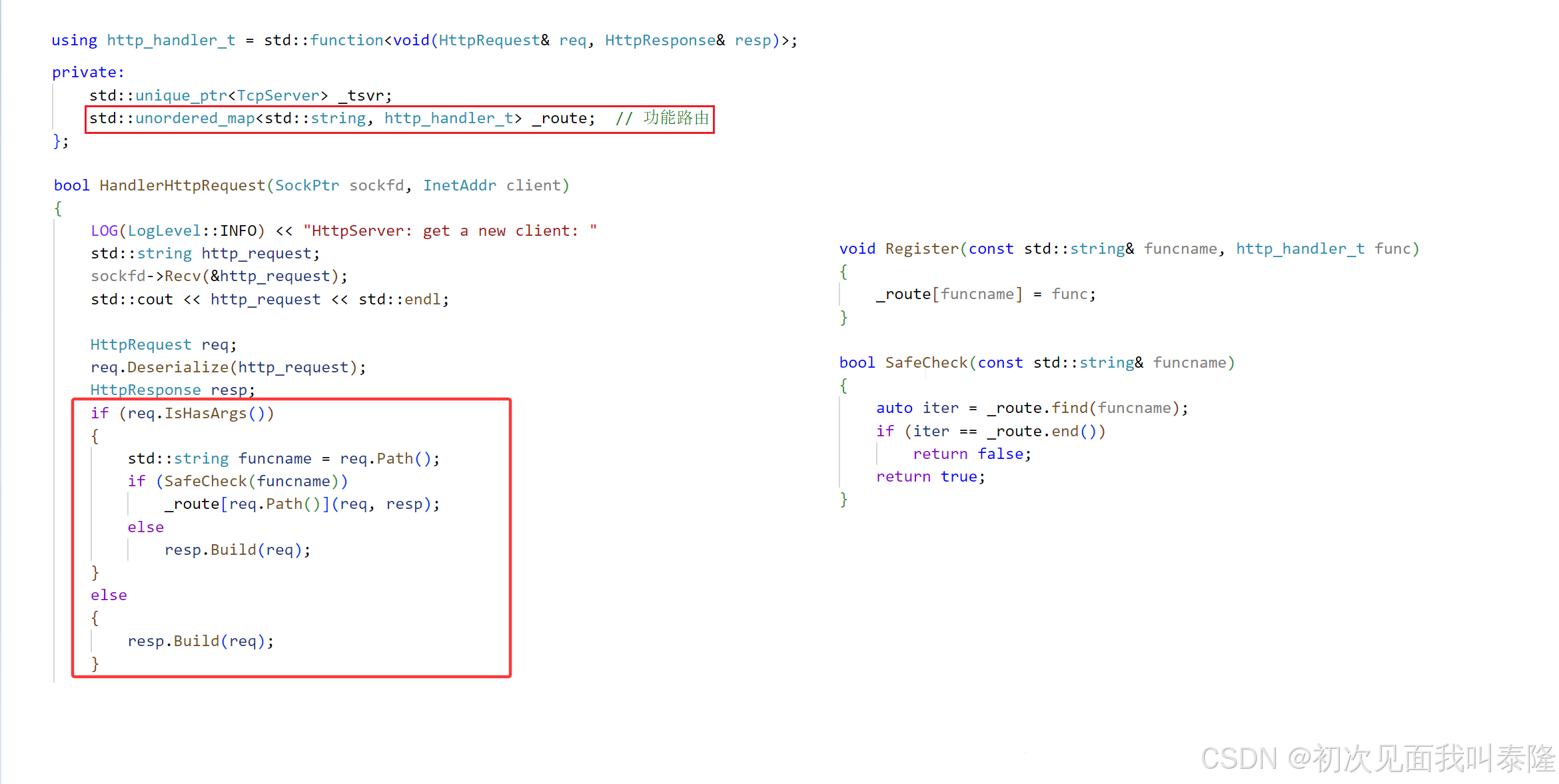
首先定义一个http_handler_t的可执行对象类型,然后再HttpServer中添加一张哈希表,该表是函数名和可执行对象组成的key-value映射。然后再处理请求的时候先调用IsHasArgs判断请求中是否携带有参数,如果有携带参数就判断是否存在可执行对象,如果有就去执行,否则就正常构建响应返回,由于不存在Build构建的时候必定就会返回404。如果不存在参数就走正常的Build。然后最后将序列化后的字符串返回。

接着在HttpRequest中添加三个成员变量,如果请求中存在参数,将来就在反序列中将参数提取出来,请求的路径也会提取出来,并且设置_isexec为true。

在HttpServer.cc中,我们实现了登录、注册、搜索、测试模块四个函数,然后通过Register将他们注册进去,将来获取请求分析如果是带有参数的,就会根据_path查询路由表执行对应函数。然后对应的模块就会根据传进来的req构建resp,然后再反序列化返回给客户端。
接着我们启动服务,然后进入登录页面,输入用户名:zhangsan,密码:123456,然后点击登录。
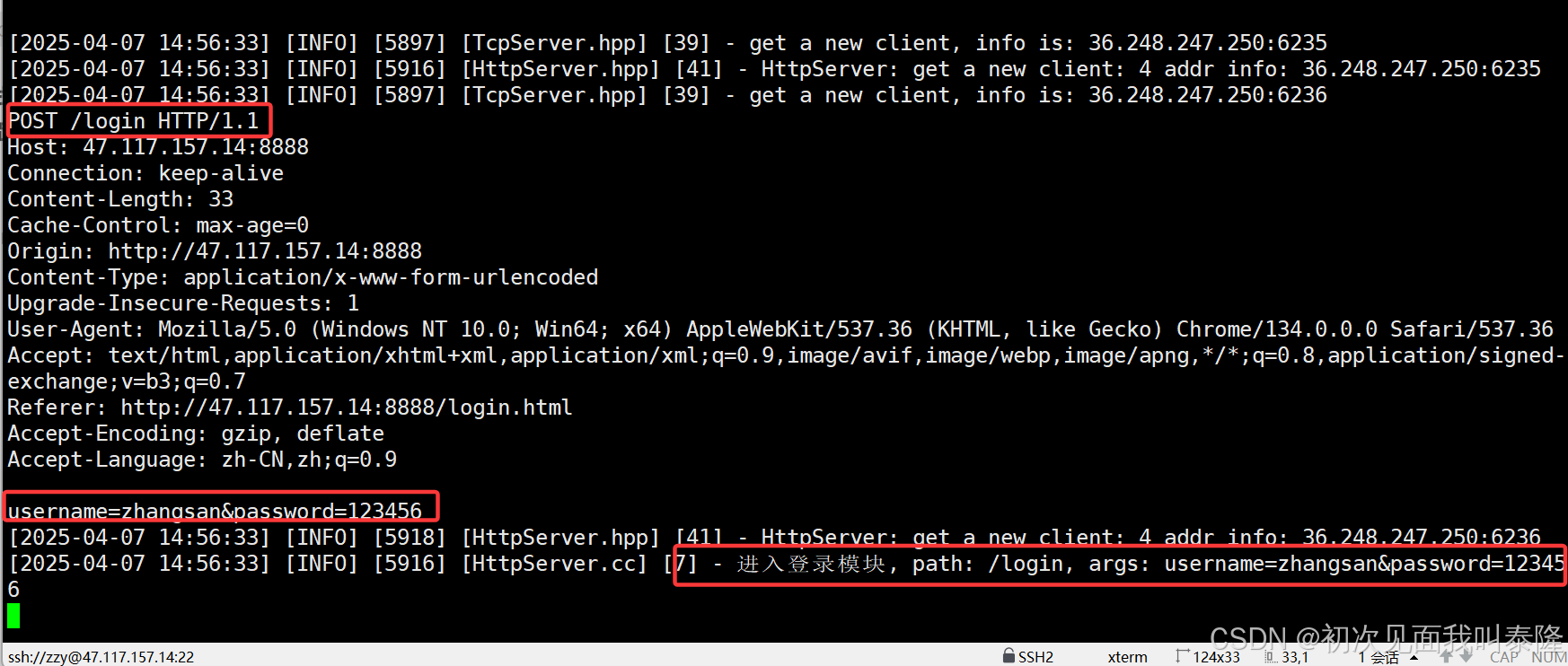
根据打印信息我们发现确实进入了登录模块,服务器获取的请求方法是POST,并且参数在正文中。

另外我们发现如果有时候服务端退出了,再次绑定同一个端口可能会出现上面bind error。这是因为当客户端连接了,服务端退出后,服务端会处于一个TIMEWAIT的状态,这个状态要持续60-120秒,具体细节后面再说。
所以我们可以实现一下之前还没有实现的SetSocketOpt函数:
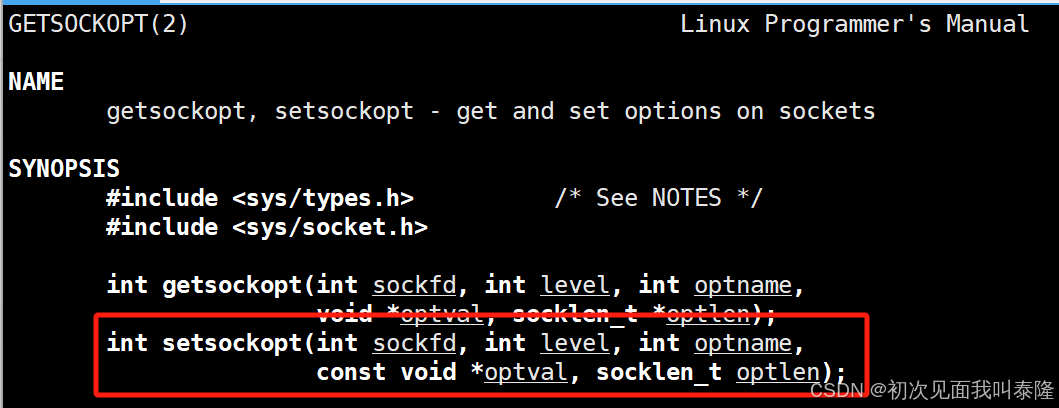

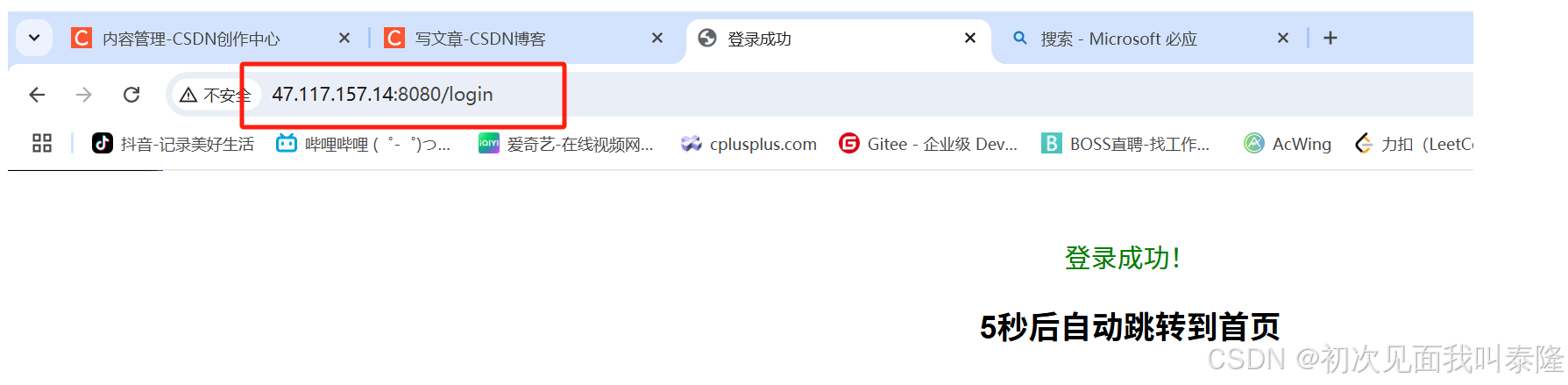
下面我们构建一个html网页信息,当用户登录后跳转到登录成功的网页,然后倒计时五秒后跳转到首页:
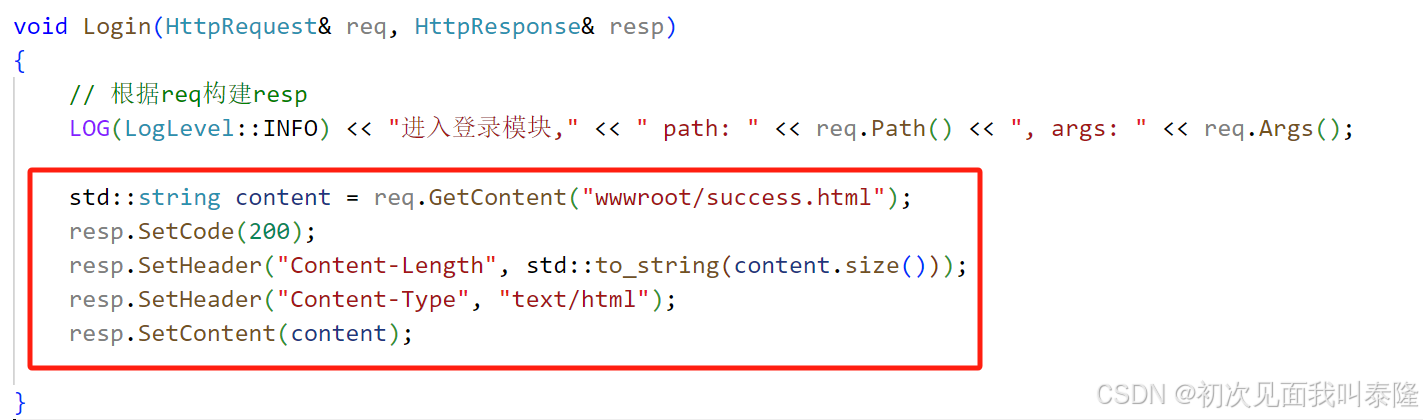

那么当我们在bing中搜索框输入qinghua,然后点击搜索的时候,就是发起了/search请求,通过GET方法发起的,所以参数就拼接在URL后面。那么在后的就是将/search注册到路由中,然后调用Search函数将请求传入,根据参数搜索网址信息构建响应返回。
3.12、Cookie
HTTP Cookie(也称为 Web Cookie、浏览器 Cookie 或简称 Cookie)是服务器发送到用户浏览器并保存在浏览器上的一小块数据,它会在浏览器之后向同一服务器再次发起请求时被携带并发送到服务器上。通常,它用于告知服务端两个请求是否来自同一浏览器,如保持用户的登录状态、记录用户偏好等。
工作原理:
当用户第一次访问网站时,服务器会在响应的 HTTP 头中设置 Set-Cookie字段,用于发送 Cookie 到用户的浏览器。
浏览器在接收到 Cookie 后,会将其保存在本地(通常是按照域名进行存储)。
在之后的请求中,浏览器会自动在 HTTP 请求头中携带 Cookie 字段,将之前保存的 Cookie 信息发送给服务器。
用途:
用户认证和会话管理(最重要)
跟踪用户行为
缓存用户偏好等
http是无状态、无连接的。
http是无状态的,如果我当前访问http服务器请求a.html资源,服务器给我返回。下次我再请求a.html资源,服务器还会给我返回。我请求几次服务器就返回几次,服务器不会记录之前我已经请求过a.html资源。
HTTP协议的无状态特性指服务器不保存客户端的历史请求信息,每个请求都被视为独立事务处理。
http是无连接的,这是应用层的概念。http是基于TCP的,而TCP是面向连接的。但是在应用层看来,http直接发起请求,直接响应,是无连接的。
所以就会有这样的问题,假设我今天访问某个网站看视频,但是这个网站要求我登录才能观看视频,那么我登陆会将用户名和密码作为参数提交给服务器,然后服务器认证成功后将资源给我返回。而HTTP是无状态的,那么我每次请求访问某个视频就都需要给服务器发送我的账户密码进行登录验证。那这样用户不就崩溃了么。因此就需要Cookie出场了。
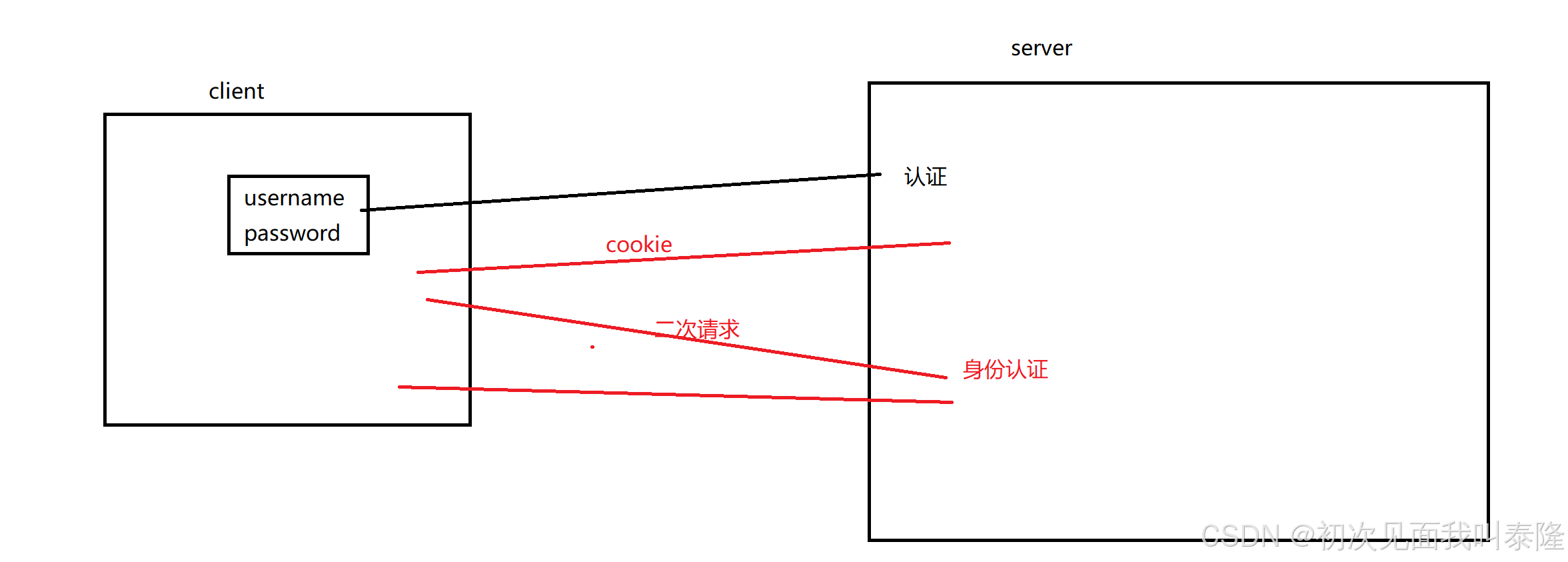
如图:用户第一次登录,将用户名和密码提交给服务器,然后服务器进行身份认证,认证成功后会返回资源并且携带cookie信息,这个cookie信息会被浏览器保存起来。那么当你第二次,第三次访问的时候,浏览器会在请求报头中自动携带cookie信息,然后服务器根据你发送请求报头中cookie信息进行身份认证,认证成功给你返回资源,所以你登陆一次之后,后面再请求资源就不需要再登录了。
浏览器保存cookie有两种方式:1、内存级。2、文件级。内存级的cookie当浏览器关闭后就失效了,文件级的cookie可以存在很长时间,哪怕浏览器关了下次也还能从文件中获取。
下面我们以bilibili网站为例进行测试:

在未登录状态下我们先进行登录:

登录之后我们会发现有很多cookie信息,所以下面我们访问网站请求资源会自动将cookie添加到请求报头中,然后服务端获取cookie信息进行认证。因此就不需要再一直登陆了。下面我们把cookie信息全部删除掉再刷新页面:

这时候就又变成未登录的状态了。
下面在我们的httpserver中响应中添加cookie信息进行测试:
当用户点击登录后,我们将用户的参数设置为cookie的value添加到响应报头中,将来反序列化后返回给客户端,然后客户端之后再次请求其他网页时都会携带cookie信息。
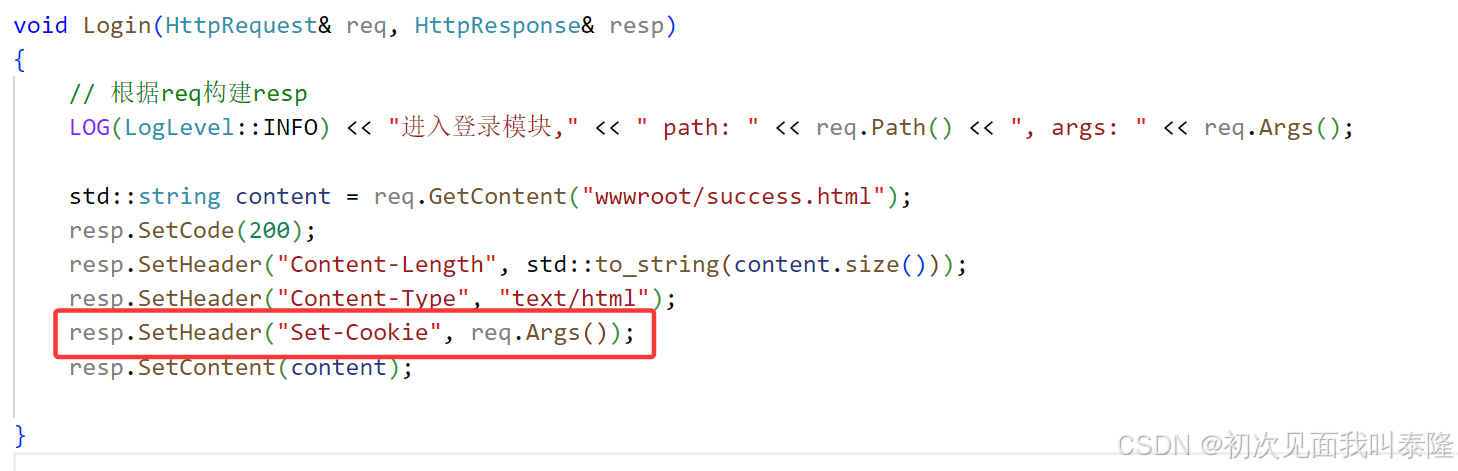
添加一行代码,然后启动服务,我们先进行登录,登录之后浏览器就会保存服务器发送过来的cookie。
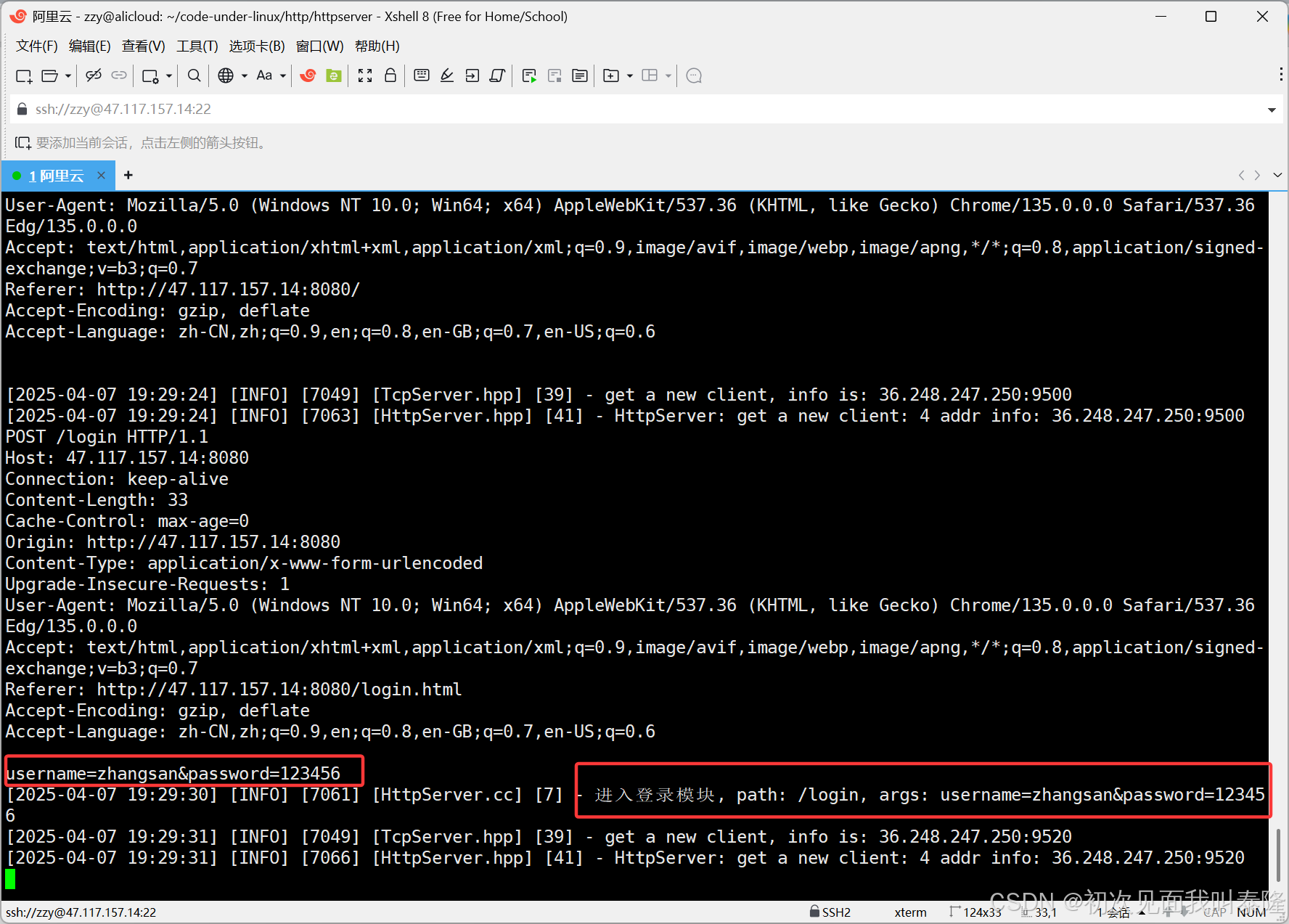
如图,我们输入用户名:zhangsan,密码:123456,点击登陆后,可以看到进入了登录模块,那么服务器就会将设置的cookie返回给客户端。
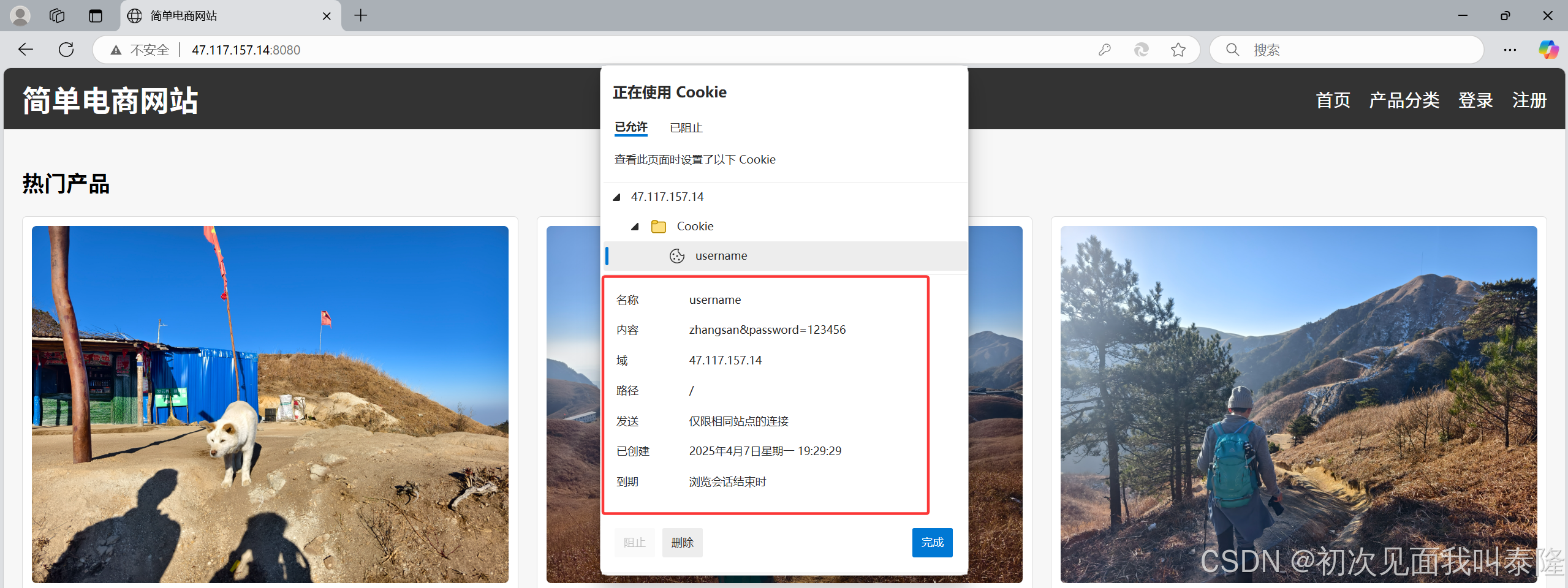
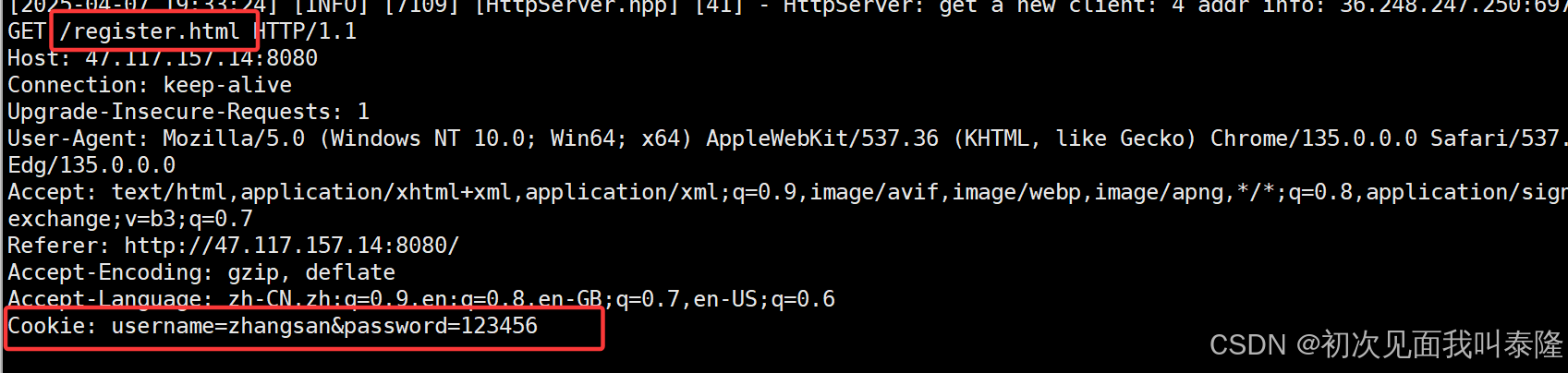
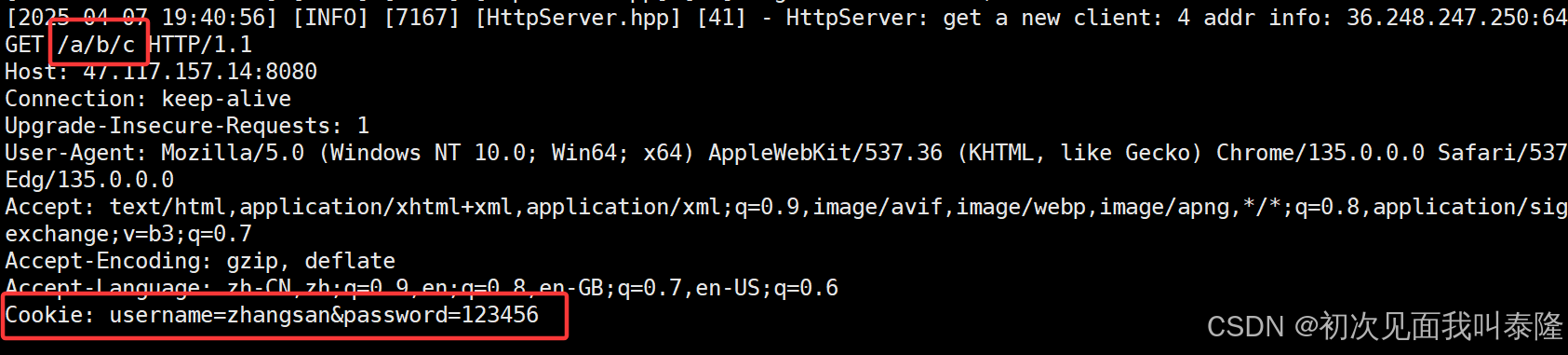
如上图,我们查到了cookie信息,并且再访问注册页面和其他任何页面,我们发现客户端发送过来的请求就携带了cookie信息。
下面给出一个完整的cookie信息示例:

expires表示的是cookie的过期时间,上面我们没有写,默认就是内存级的。下面我们给cookie添加过期时间,我们就添加十分钟。这个时间是有格式的,必须按照格式来添加。上面的时间使用的是UTC——协调世界时,也可以使用GMT——格林威治时间。
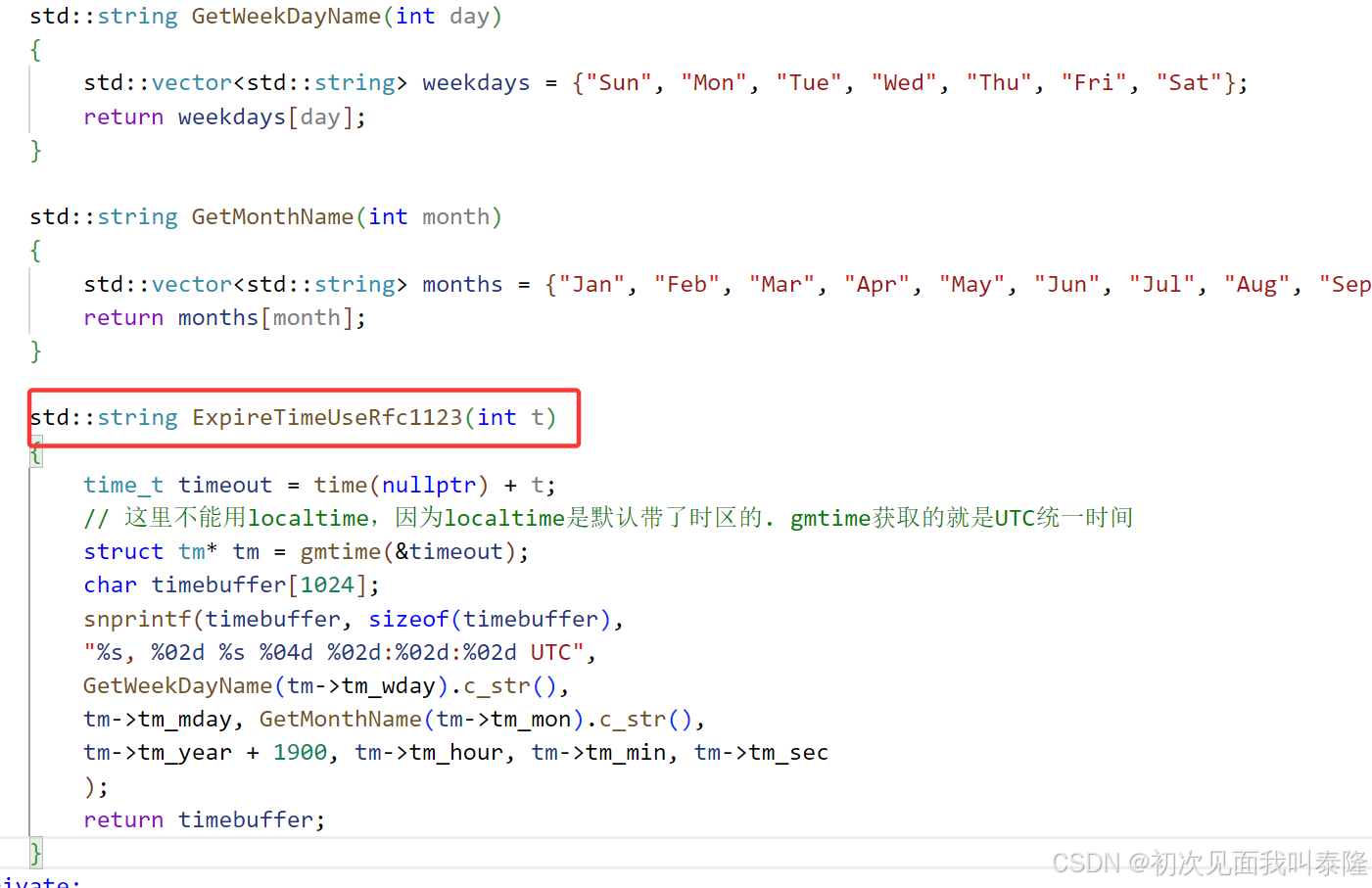
在HttpResponse中添加三个接口,前面两个接口用来获取星期几和几月份的英文名,然后ExipreTimeUseRfc1123用来格式化字符串然后返回。

然后再启动服务器进行测试:
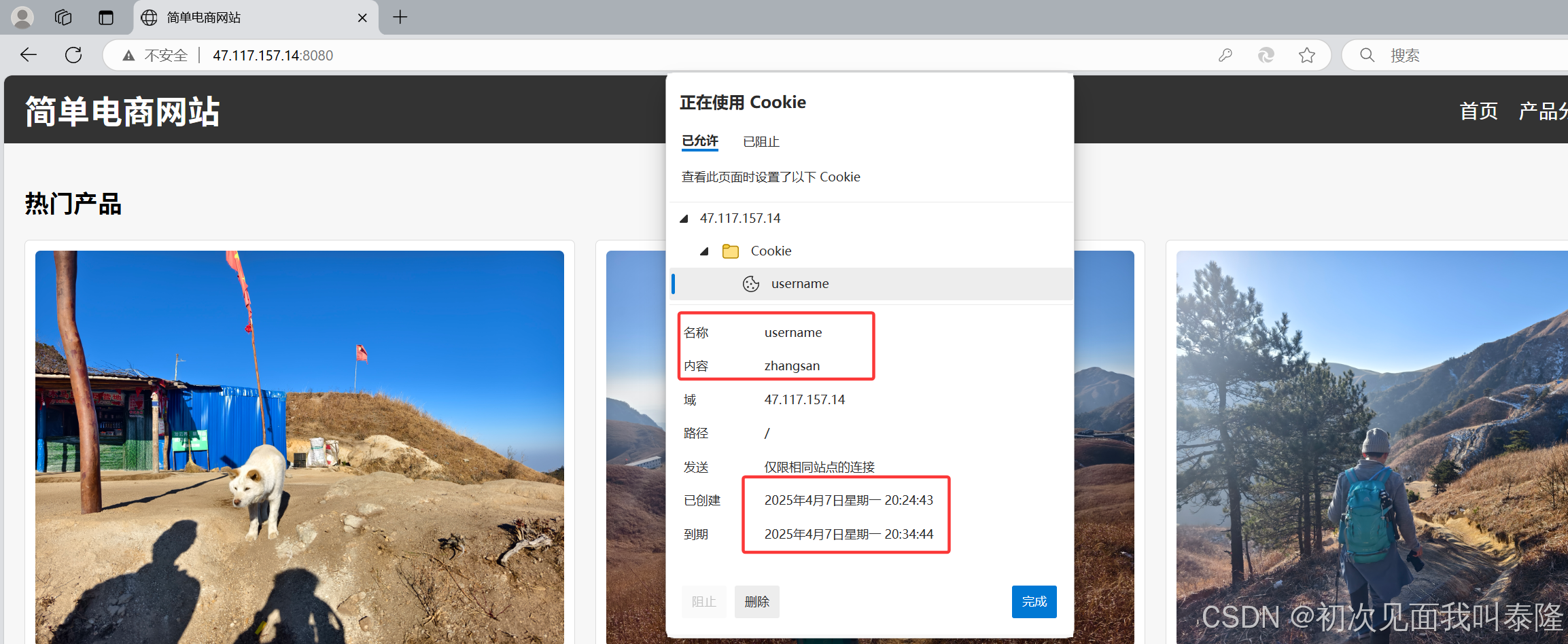
我们看到该cookie的有效期确实为10分钟。
下面介绍path,path表示向哪个路径发起请求会携带该cookie信息。默认是/路径,也就是访问该网站的所有请求都会携带cookie信息,当我们设置为/a/b时,那么只有访问/a/b的时候才会携带cookie信息,下面我们进行测试:
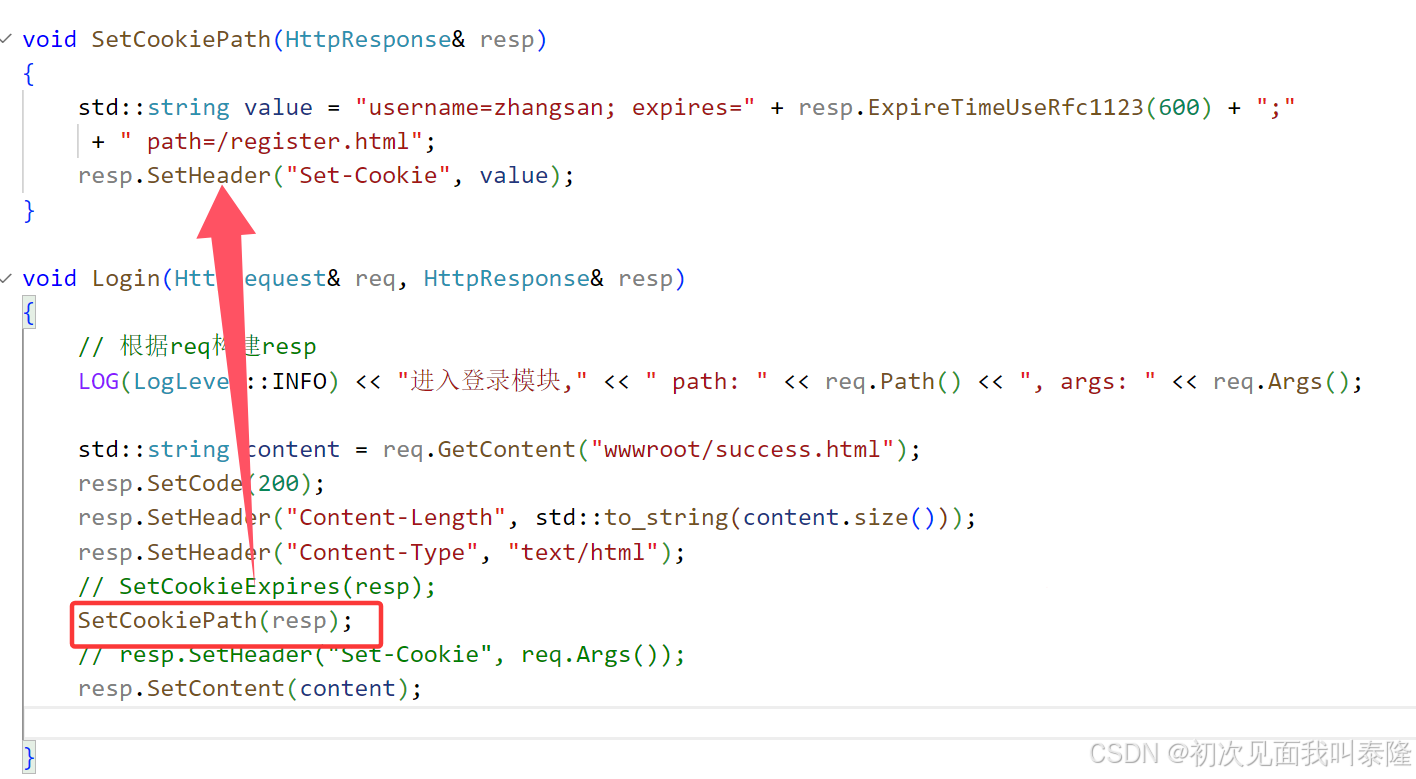
我们设置了path为/register,那么我们启动服务器,删除原来的cookie信息,然后先进行登录,服务器将cookie返回给客户端,然后浏览器就会保存cookie信息,而我们设置了path所以只有在访问/register.html的时候请求中才会携带cookie信息,访问其他网站一律不会携带。
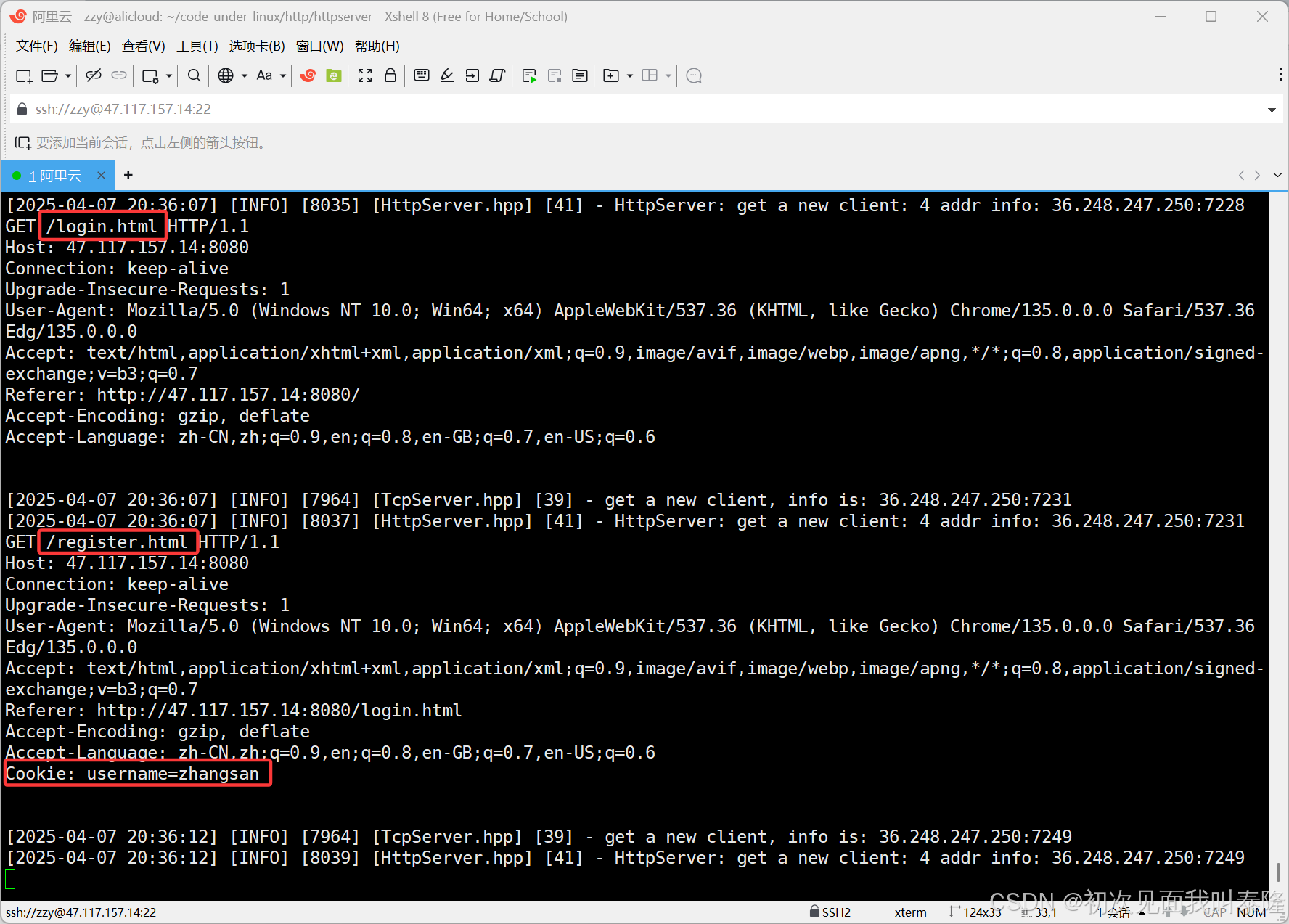
如图,我们先登录,登陆后服务器给我们返回cookie信息后,接着我们再分别访问登录页面和注册页面,发现果然只有注册页面才会携带cookie信息。
剩下字段的含义如下:

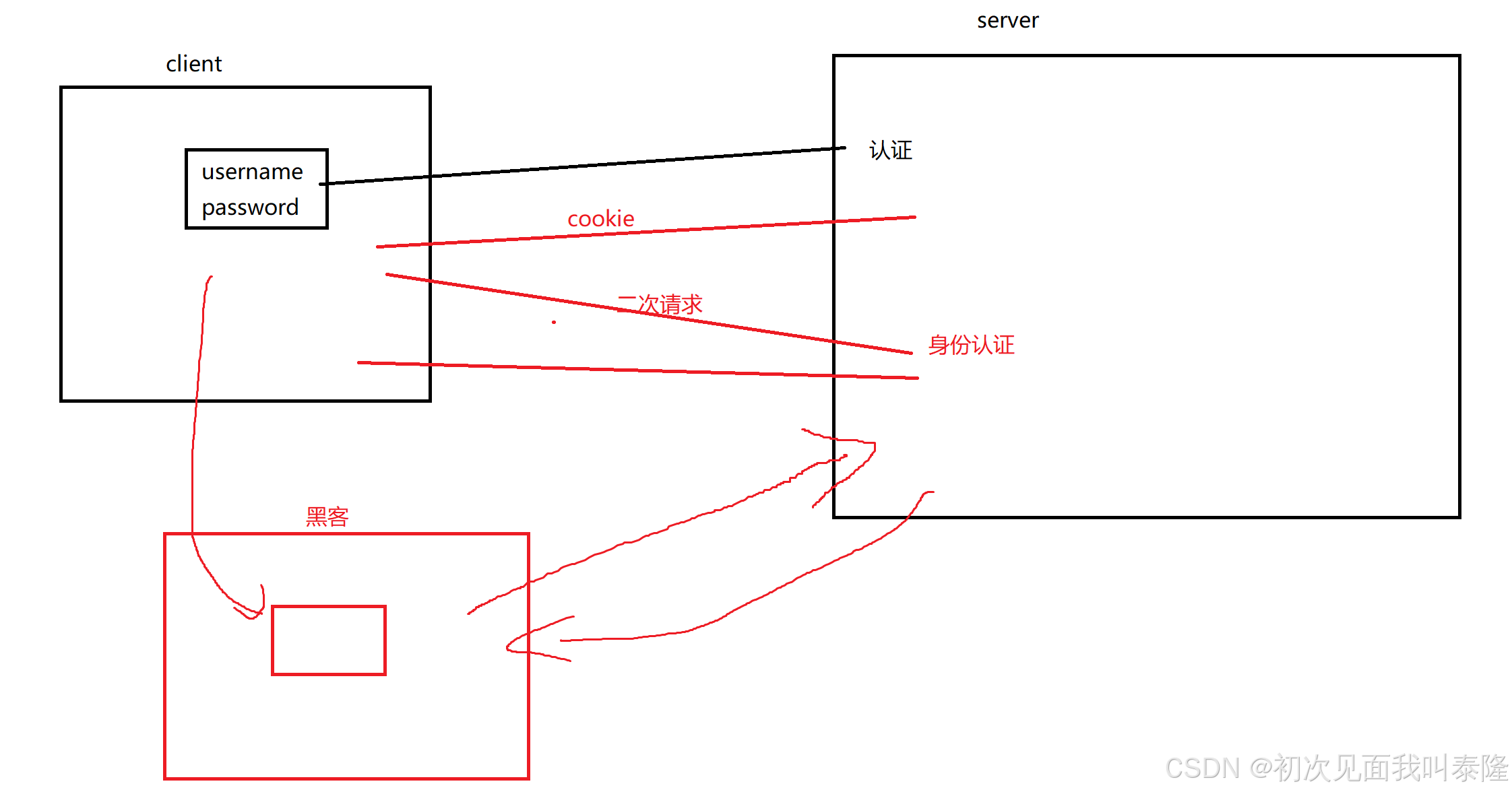
现在有个黑客盗取了你的cookie信息,比如盗取了你浏览器的文件级的cookie信息,然后将这些也放到他自己浏览器的特定目录下,然后他现在启动和你一样的浏览器,然后直接去访问服务器,那么这时候服务器就会认证成功给黑客返回请求的资源,那么你的信息就会泄漏。并且你的信息还写在cookie中,所以黑客也可以从cookie中获取你的信息,今天我们写的是用户名,但也有可能是你的密码,浏览记录等等信息。因此就需要session出场了。
3.13、Session
HTTP Session 是服务器用来跟踪用户与服务器交互期间用户状态的机制。由于HTTP协议是无状态的(每个请求都是独立的),因此服务器需要通过 Session 来记住用户的信息。
当用户首次访问网站时,服务器会为用户创建一个唯一的 Session ID,并通过Cookie 将其发送到客户端。
客户端在之后的请求中会携带这个 Session ID,服务器通过 Session ID 来识别用户,从而获取用户的会话信息。
服务器通常会将 Session 信息存储在内存、数据库或缓存中。
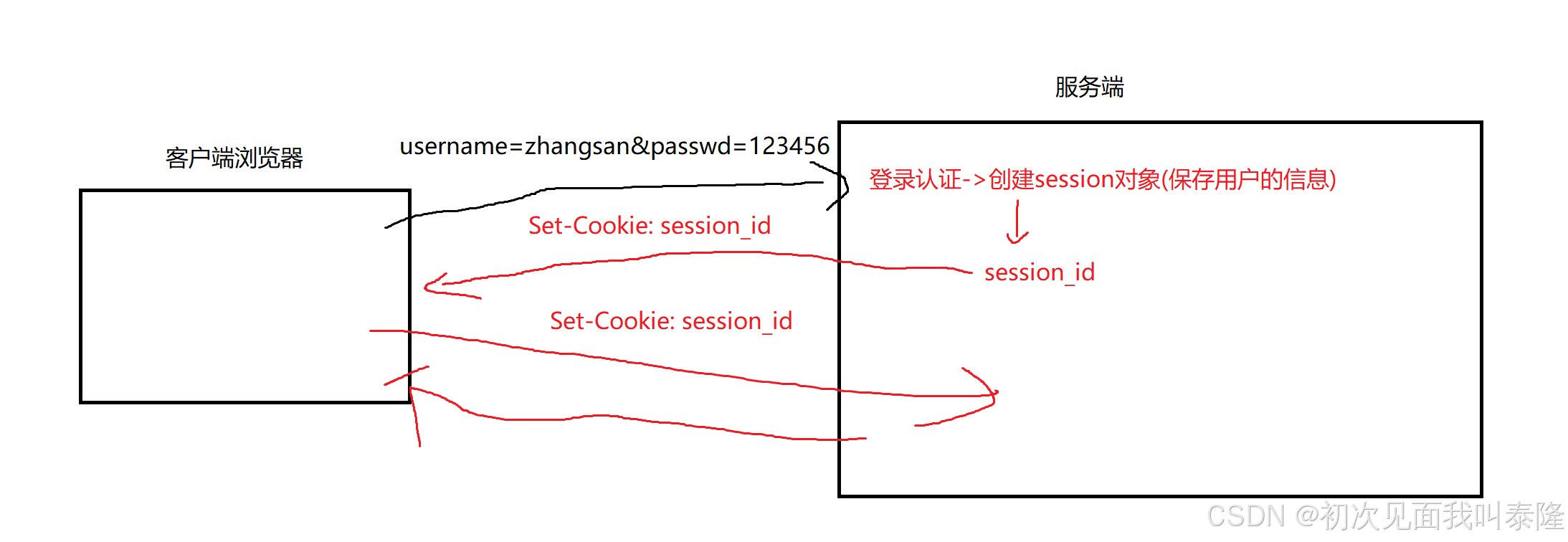
现在当我们进行登录时,将用户名和密码上传给服务器,然后服务器进行登录认证,认证成功就会给我们创建一个session对象,这个session对象里面会保存用户的各种信息,然后形成一个唯一的值session_id,接着给用户返回资源,并且在响应报头中携带一个cookie,这个cookie信息就是session_id。那么将来客户端再次发起请求的时候浏览器就会自动携带这个cookie信息,然后服务端提取出cookie中的session_id,然后进行判断确实存在这么一个session_id对应的session对象,所以认证成功,给客户端返回请求的资源。
所以实际会话保持的做法是:cookie+session。
#pragma once
#include <iostream>
#include <string>
#include <memory>
#include <unordered_map>
#include <unistd.h>
class Session
{
public:
Session(const std::string& username, const std::string& status)
:_username(username)
,_status(status)
{
_create_time = time(nullptr);
}
~Session()
{}
std::string _username;
std::string _status;
uint64_t _create_time;
uint64_t _time_out;
};
using session_ptr = std::shared_ptr<Session>;
class SessionManager
{
public:
SessionManager()
{
srand(time(nullptr)^getpid());
}
std::string AddSession(session_ptr s)
{
uint32_t randomid = rand() + time(nullptr);
std::string sessionid = std::to_string(randomid);
_sessions.insert(std::make_pair(sessionid, s));
return sessionid;
}
session_ptr GetSession(const std::string& sessionid)
{
if (_sessions.find(sessionid) == _sessions.end()) return nullptr;
return _sessions[sessionid];
}
~SessionManager()
{}
private:
std::unordered_map<std::string, session_ptr> _sessions;
};
在我们的代码中可以添加Session.hpp模块,将来如果用户登陆后就创建一个Session对象,同时生成一个sessionid返回,在响应中将sessionid返回给用户。
那么虽然采取了这种做法,黑客不是照样可以获取我的cookie信息中的session_id,然后再去请求客户端携带上这个cookie信息,这不是照样可以成功,然后可能就会获取我的私密信息了吗?没错,但是相比原来直接使用cookie,原来是将你的用户名密码等信息直接保存在cookie中的,所以黑客获取cookie就能知道你的私密信息,但是现在黑客获取的是ssession_id,所以比原来会好一些。
我们避免不了cookie信息被盗取。
1、这种方式黑客不会直接从cookie中获取用户信息。
2、服务器端可以设计各种策略来防止黑客进行恶意操作。
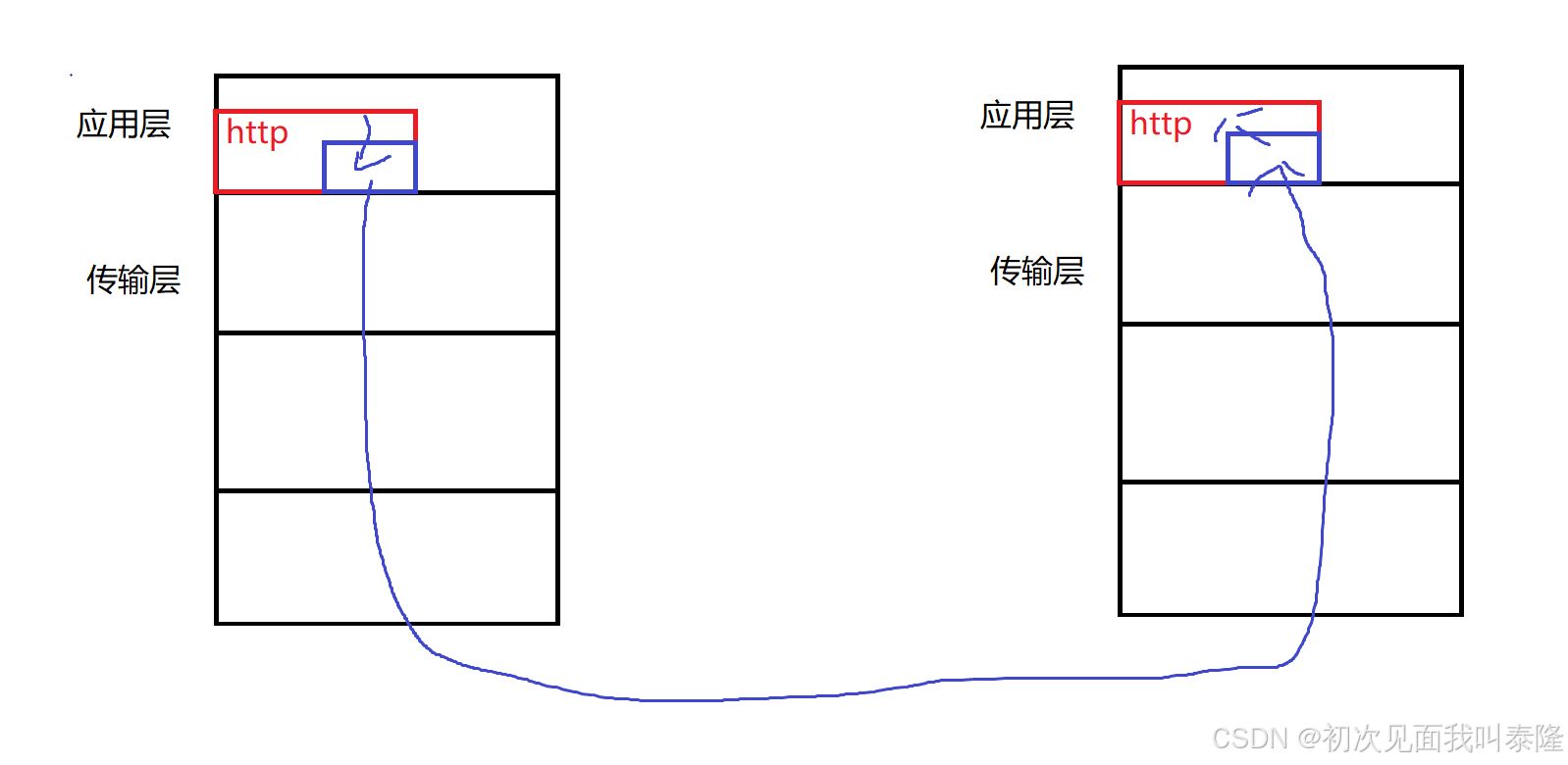
所以需要再添加一层软件层,这层是在http之下,在传输层之上的,我们成为SSL/TLS,数据经过这层加密后再向下交付,然后对方接收后需要进行解密。
超时和失效:
Session 可以设置超时时间,当超过这个时间后, Session 会自动失效。服务器也可以主动使 Session 失效,例如当用户登出时。
用途:
用户认证和会话管理
存储用户的临时数据(如购物车内容)
实现分布式系统的会话共享(通过将会话数据存储在共享数据库或缓存中)
3.14、HTTP的长连接与短链接
HTTP 中的 Connection 字段是 HTTP 报文头的一部分,它主要用于控制和管理客户端与服务器之间的连接状态。

4、Fiddler和Postman
Fiddler用于网络抓包,可以抓取我们发起的各种http请求:
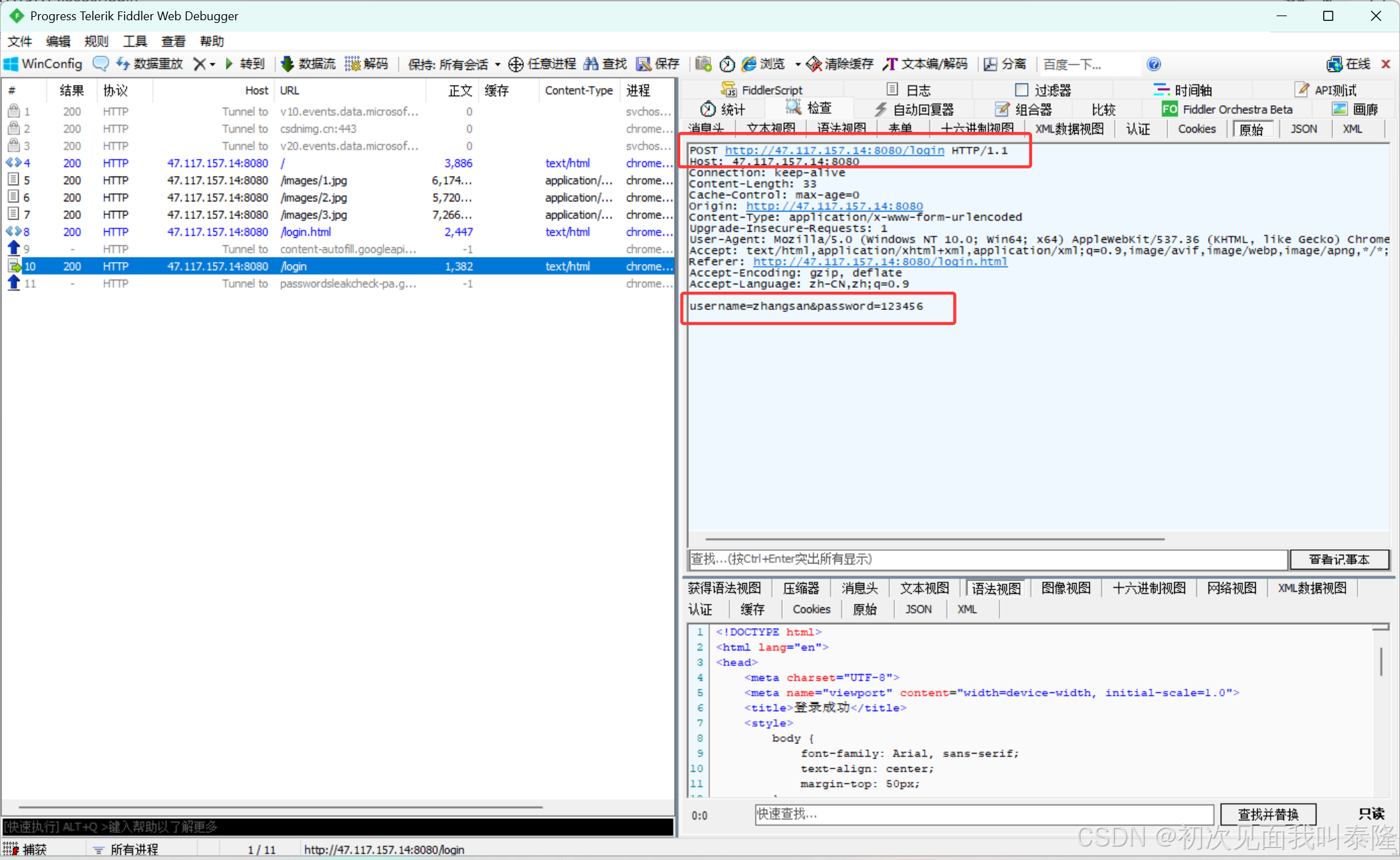
Postman可以发起http请求,可以自定义发起方法,请求参数等:
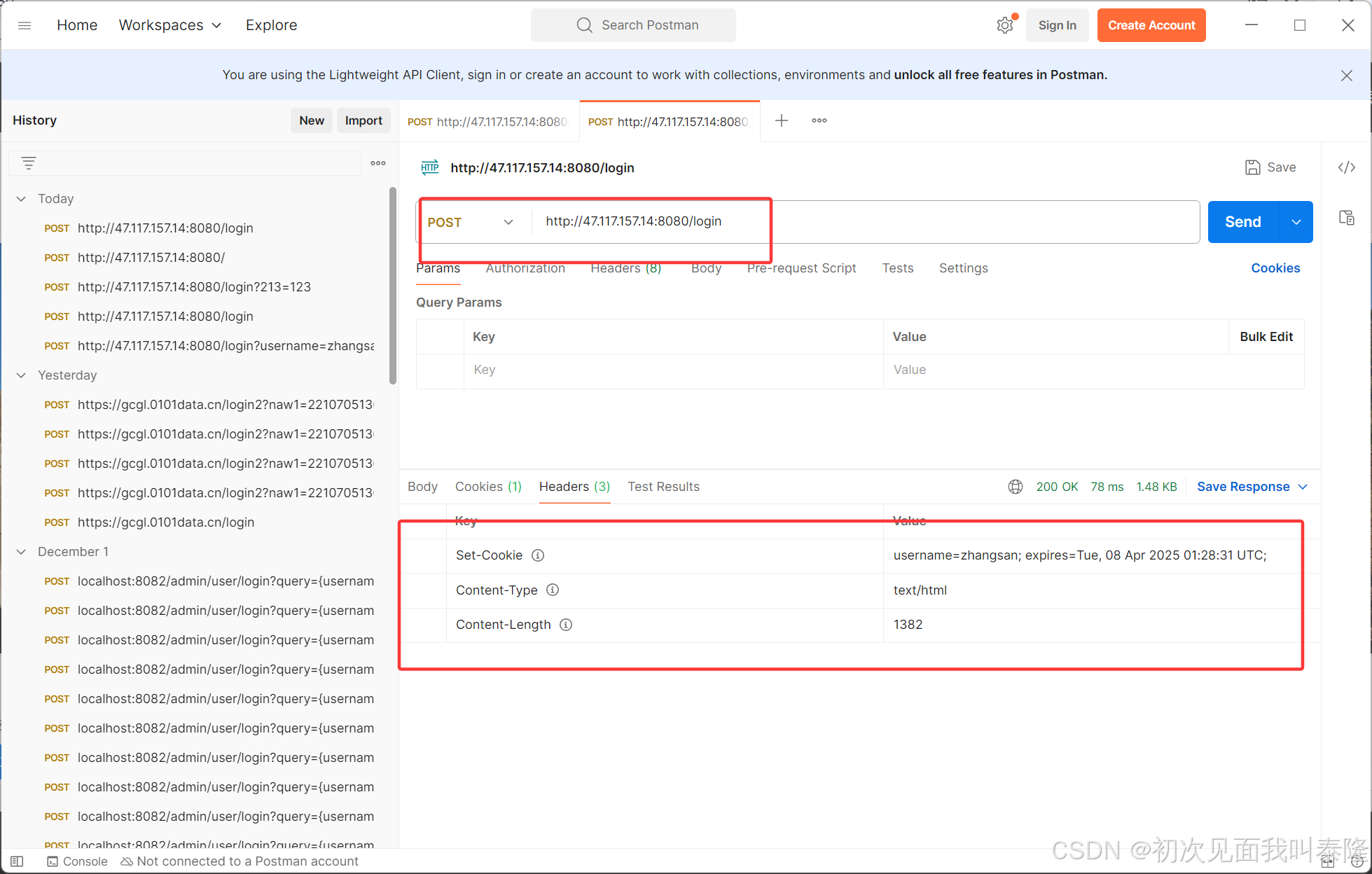

















 5231
5231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









