






每个block的参数不共享,独立学习
介绍了Transformer,下一个就是Bert,一个巨大成功的预训练模型,上图
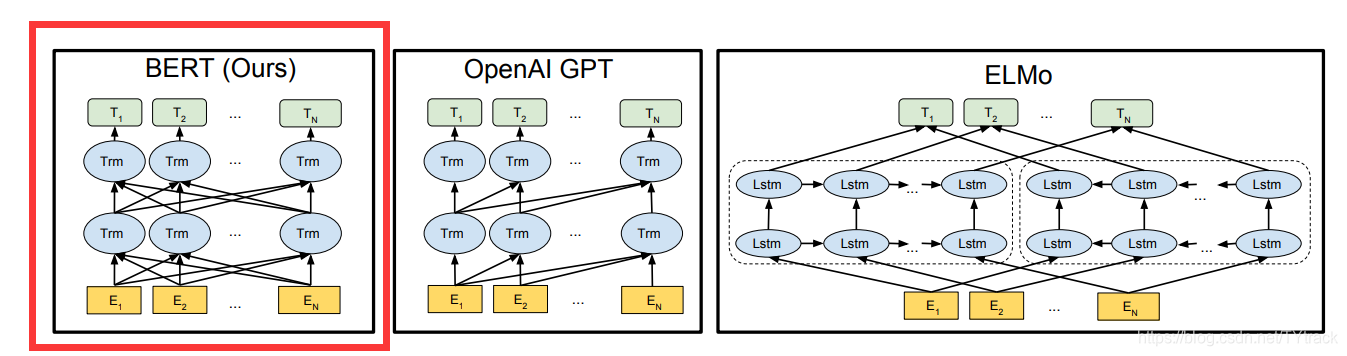
Bert全名为Bidirectional Encoder Representations from Transformers,E1...En是单个字或者词,大部分都是字为单位,Trm是一个transformer,T1...Tn是最终计算的隐藏层。因为再注意力矩阵中每个词都能学习到句子中其他词的相关程度,所以是双向。没有用到decoder
Bert有两个训练目标:
第一个任务:MaskedLM
随机15%遮盖并预测,计算Mask的词的预测词与真实值损失:其中80%是[mask],其中10%被还原成其他词,其中10%原封不动
在进行预训练目标之前,X_hidden的维度是【batch_size, seq_len, embedding_dim】,之后初始化一个映射层权重W_vocab【embedding_dim,vocab_size】,使用这个映射曾权重来实现隐藏维度到字向量的映射,最后将X_hidden与W_vocab点积【batch_size, seq_len,vocab_size】,把这个结果在最后一个维度(vocab_size)上做softmax归一化,使得待预测的每个字在词表上的概率和为1 ,就可以计算损失函数反向传播梯度了。
注意做损失时,只计算随即掩盖和替换的部分,其他部分不做损失
第二个任务:Next Sentece Prediction
[CLS]第一句话,[SEP]第二句话。[SEP]
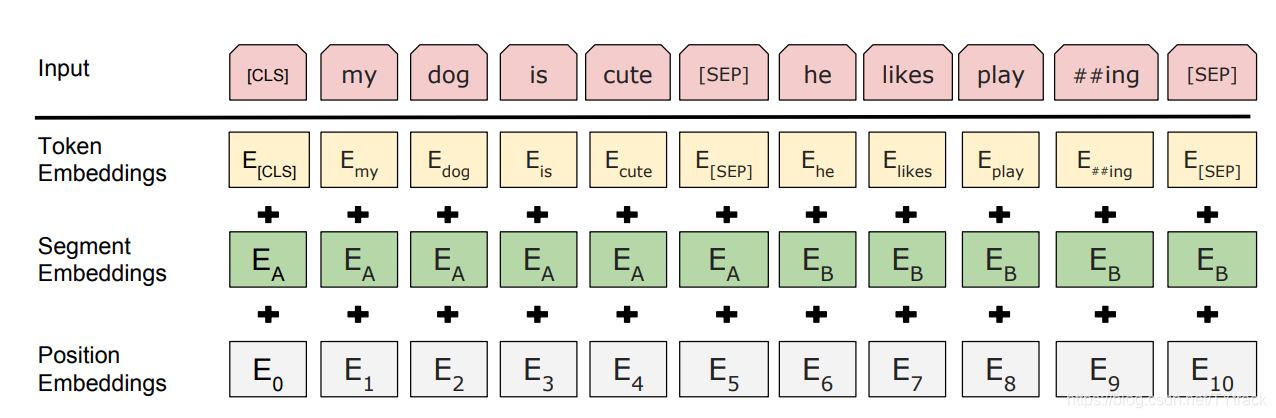
在训练中,按1:1比例中分配有属于上下文的两句话和没关系的两句话,即在训练时间上,一半是属于上下文关系的,一半不属于。一般segment embedding 只有0和1 组成,0是第一句话,1是第二句话。
在这个与训练目标中,训练目标是二分类问题,回顾transformer中每一个词的隐藏层表示都包含了其他词的信息,所以可以用[CLS]的词向量并添加一个线性层预测分类问题。
cls_vector=X_hidden[ : , 0 , :] ,其shape是【batch_size , embedding_dim】,之后再初始化一个权重,完成 embedding_dim到1的映射,实际上是一个逻辑回归的,之后再用sigmoid激活函数得到分类问题,y=sigmoid(Linear(cls_vector))
参数设置:Transformer block 个数为12,embedding_dimension=768,head_size=12


















 1903
1903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









