




 本文介绍了UNILM,一种可同时用于自然语言理解和生成任务的预训练模型。它使用共享的Transformer网络和不同类型的自注意力mask来实现单向、双向和seq-to-seq语言建模。通过这种方式,UNILM不仅能像BERT那样处理NLU任务,还能处理NLG任务,达到state-of-the-art的性能。预训练过程中,UNILM采用多种完形填空任务,通过共享参数和多任务优化增强泛化能力。
本文介绍了UNILM,一种可同时用于自然语言理解和生成任务的预训练模型。它使用共享的Transformer网络和不同类型的自注意力mask来实现单向、双向和seq-to-seq语言建模。通过这种方式,UNILM不仅能像BERT那样处理NLU任务,还能处理NLG任务,达到state-of-the-art的性能。预训练过程中,UNILM采用多种完形填空任务,通过共享参数和多任务优化增强泛化能力。
这篇paper是研究生读的第一篇,过了蛮久了,因为准备重新写博客,所以拿出来回顾一下
之前还给这篇做了PPT,paper名字是Unified Language Model Pre-training for Natural Language Understanding and Generation ,可以翻译成用作NLU和NLG的统一预训练模型,这篇论文是2019年发表的在NLP领域有些成就的一篇文章。
0、Abstract
本文介绍了一种可同时被NLU和NLG任务微调的预训练模型,使用了三种不用的语言建模任务来完成预训练:单向、双向、seq-to-seq预测,使用了一个共享的Transfomer网络和利用了特定的自注意力mask去控制预测所需的上下文信息。并顺利地和BERT在GLUE基准、SquAD2.0、CoQA上进行了对比,UNILM在5种自然语言生成任务上达到了state-of-the-art。
1、Introduction
语言模型预训练在很多NLP任务中取得了最优秀的成绩,能够从大量文本数据中通过上下文来预测当前词的方式 学习到语境化的文本表示,而且可以进行微调之后应用到下流任务中。
不同的类型的预训练语言模型会用在不同的预测任务和训练目标上,ELMO回学习到两个单向的LMs:从左到右和从右到左,GPT使用一个从左到右的Transfomer来预测一个文本序列word-by-word。相反BERT使用的是双向的Transfomer编码器来融合上文和下文信息去预测mask。尽管BERT提高了大量NLU任务的表现能力,但是其天然的双向性使其很难应用在NLG问题上。
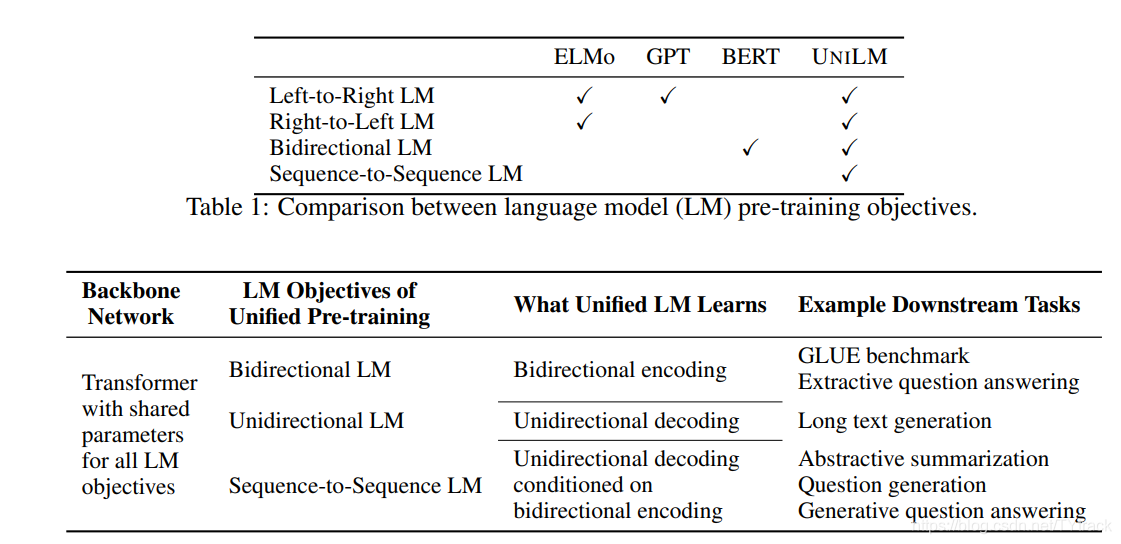
本文介绍了一种可同时被NLU和NLG任务微调的预训练模型,使用了一个多层的Transfomer网络,同时以三种非监督语言建模为目标来实现共同优化,特别的是,我们设计了一系列的完形填空任务(根据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1086
1086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









