




 本文是搭建完全分布式大数据集群的第二弹,在第一篇基础上,详细介绍了搭建Spark集群的步骤,包括安装Scala、安装Spark、配置Spark以及启动Spark,通过一系列命令操作完成集群搭建,最终成功启动并运行Spark集群。
本文是搭建完全分布式大数据集群的第二弹,在第一篇基础上,详细介绍了搭建Spark集群的步骤,包括安装Scala、安装Spark、配置Spark以及启动Spark,通过一系列命令操作完成集群搭建,最终成功启动并运行Spark集群。
写在前面的话
本文为搭建完全分布式的大数据集群第二弹,在第一篇的基础上,讲解如何搭建Spark集群。
欢迎扫码关注我的公众号,与我一同学习进步!主要致力于学习
- 使用深度学习解决计算机视觉相关问题
- Python为主的互联网应用服务
- 基于MIPS指令集的CPU微体系结构设计

安装Scala
为了确保一致性,三台服务器均将应用程序安装在/usr/local目录下。
-
使用命令
cd /usr/local直接切换到目标目录下。 -
使用命令
wget https://downloads.lightbend.com/scala/2.11.12/scala-2.11.12.tgz下载scala-2.11.12 -
使用命令
tar -zxvf scala-2.11.12.tar.gz解压scala的压缩包 -
配置环境变量
使用命令
vim /etc/profile打开配置文件,配置scala的环境变量,将以下内容添加到文件末尾,保存并退出。#scala export SCALA_HOME=/usr/local/scala-2.11.12 export PATH=$PATH:$SCALA_HOME/bin**注:**如果你的目录不是
/usr/local,一定要更改为自己的目录。 -
使用命令
source /etc/profile激活配置的环境变量 -
使用命令
scala -version查看scala的版本,出现如下图所示的结果即表示安装成功。
安装Spark
同样为了确保一致性,三台服务器均将应用程序安装在/usr/local目录下。
-
使用命令
cd /usr/local直接切换到目标目录下。 -
使用命令
wget https://archive.apache.org/dist/spark/spark-2.0.0/spark-2.0.0.tgz下载spark-2.0.0。 -
使用命令
tar -zxvf spark-2.0.0.tar.gz解压spark的压缩包。 -
配置环境变量
使用命令
vim /etc/profile打开配置文件,配置spark的环境变量,将以下内容添加到文件末尾,保存并退出。#spark export SPARK_HOME=/usr/local/spark-2.0.0 export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin**注:**如果你的目录不是
/usr/local,一定要更改为自己的目录。 -
使用命令
source /etc/profile激活配置的环境变量。 -
使用命令
spark-shell查看spark的版本,出现如下图所示的结果即表示安装成功。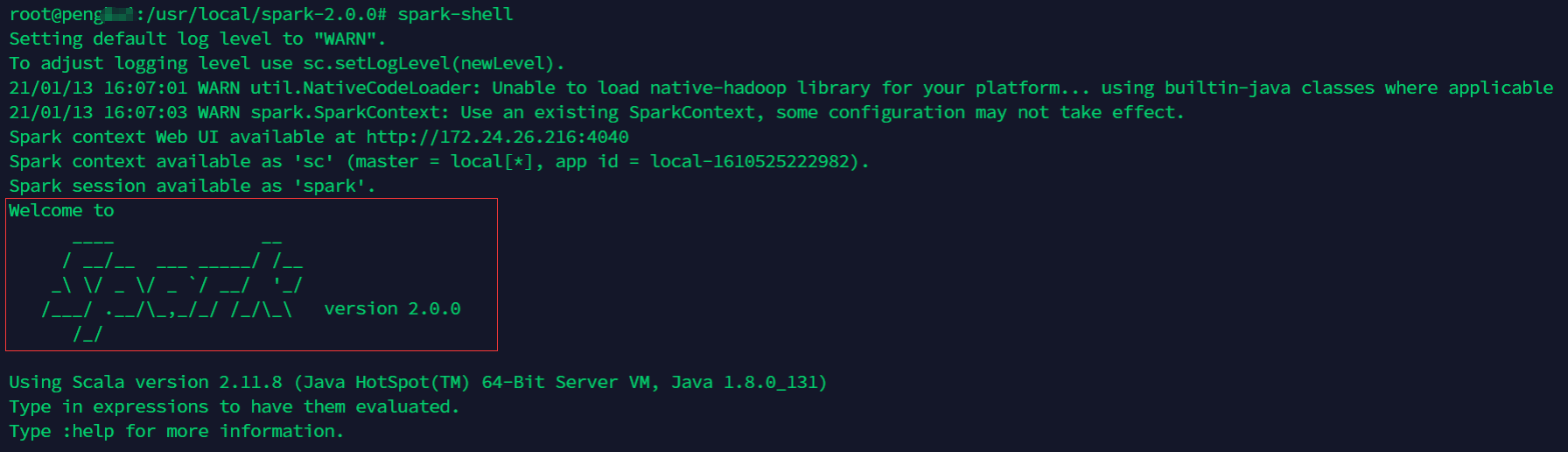
-
在终端输入
:quit退出shell,如下图所示。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KdcTUgd9-1610526713638)(https://pengkai.online/hadoop/blog_15.png)]
配置Spark
该配置项针对于主服务器,只需在主服务器上进行配置即可
-
使用命令
cd /usr/local/spark-2.0.0/conf切换到配置文件的目录下 -
使用命令
vim ./spark-env.sh打开配置文件,并进行如下的配置#!/usr/bin/env bash # 这里的hostname需要替换为主服务器的名字 export SPARK_MASTER_HOST=hostname # 这两个IP都需要替换成主服务器的内网IP export SPARK_MASTER_IP=IP export SPARK_LOCAL_IP=IP # 端口可以自己设定,设定完成后需要在防火墙中打开 export SPARK_MASTER_PORT=7077 # 工作节点的数量,两台从服务器即配置为2 export SPARK_WORKER_CORES=2 # 工作节点的内存,可根据实际的配置进行设置 export SPARK_WORKER_MEMORY=1g # Web端的端口,同样自己设定后在防火墙中打开即可 export SPARK_MASTER_WEBUI_PORT=8888 # 根据自己的安装路径,依次对各项进行配置即可 # Java的安装路径 export JAVA_HOME=/usr/lib/jdk1.8.0 # Scala的安装路径 export SCALA_HOME=/usr/local/scala-2.11.12 # Hadoop的安装路径 export HADOOP_HOME=/usr/local/hadoop-2.10.0 # Hadoop配置文件的存放路径 export HADOOP_CONF_DIR=/usr/local/hadoop-2.10.0/etc/hadoop # Spark的安装路径 export SPARK_HOME=/usr/local/spark-2.0.0 # Spark与Hadoop通信文件的存放路径 export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop-2.10.0/bin/hadoop classpath) -
配置完成后,将配置文件分别分发给两台从服务器
使用命令
scp ./spark-env.sh slave_hostname:/usr/local/spark-2.0.0/conf/spark-env.sh将该文件发送给两台从服务器# 需要进行修改的参数 slave_hostname: 从节点的名称 /usr/local/spark-2.0.0/conf/spark-env.sh: 根据自己的安装目录进行替换 -
返回主服务器,配置工作节点信息
使用命令
cd /usr/local/spark-2.0.0/conf切换到配置文件的目录下。使用命令
vim slaves打开配置文件,将从服务器的名称添加到文件末尾。该集群中,相应的添加如下所示。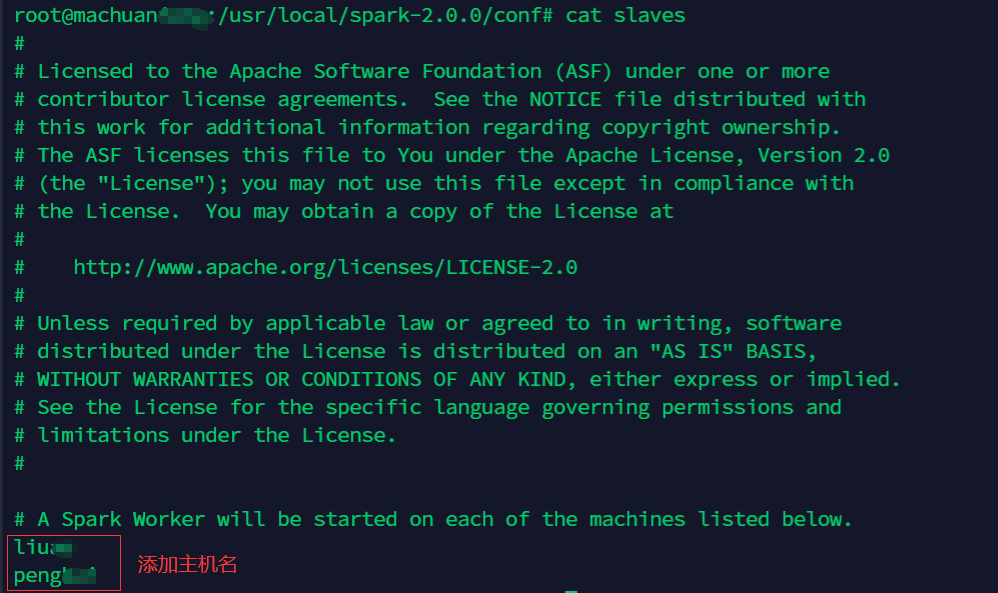
启动Spark
所有的配置项完成后,即可启动Spark使集群开始工作
-
使用命令
cd /usr/local/spark-2.0.0/sbin切换到Spark的sbin目录下,使用命令./start-spark-all.sh启动Spark集群。 -
使用命令
jps查看启动的进程,出现如下图所示的结果,即表示启动成功。-
主服务器
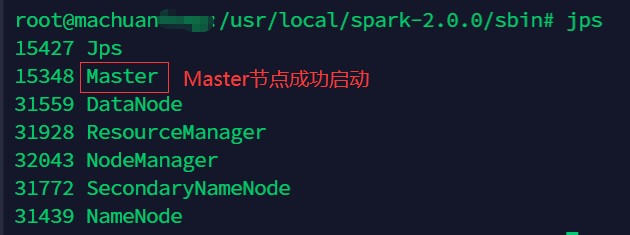
-
从服务器
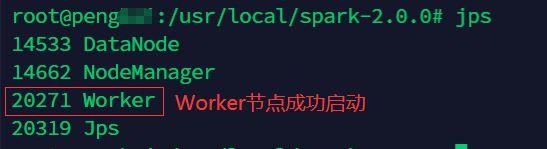
-
至此,Spark集群已经成功启动并开始运行啦!

















 1518
1518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









