





在信息检索领域,一场旷日持久的“战争”始终存在于效率与精准之间。
传统的关键词搜索速度飞快,但难以真正理解语言的细微差别。
而先进的语义搜索虽然能够深刻洞察用户的真实意图,但其巨大的计算成本,使其成为了少数科技巨头才能玩得转的昂贵功能。
现在,一篇来自谷歌DeepMind的最新研究论文,提出了一种名为BlockRank的全新AI搜索排名算法
它的出现,不仅有望打破这一僵局,研究人员甚至在结论中宣称,它能够将强大的信息发现工具,民主化地提供给更广泛的用户。

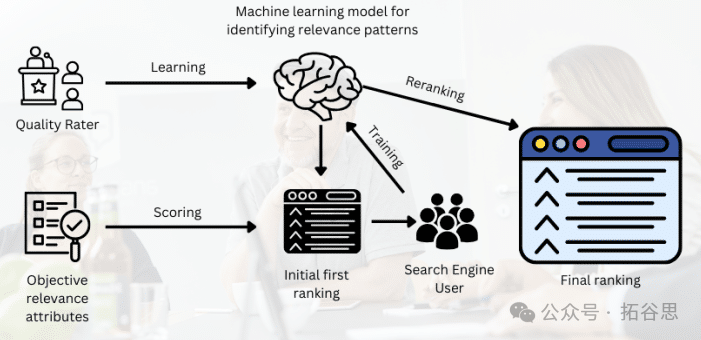
核心突破:上下文排名(ICR)
要理解BlockRank的革命性,我们必须首先理解“上下文排名”(ICR)这一革命性的概念。
传统的搜索引擎,无论是基于关键词还是语义,都是在一个“离线”的状态下,对海量的网页进行预处理和索引,然后再根据用户的查询,从这个索引中找出并排序结果。
而ICR则完全不同。它利用了大语言模型最擅长的能力来理解上下文。
ICR的工作方式,更像与AI进行实时对话。
它会向大语言模型提供一个包含了用户查询和一系列候选网页的提示词,随后其会根据大语言模型的实时对话中,对这些网页进行实时的评估和排序。
这种方法,使得排名决策不再仅仅依赖于预先计算好的相关性分数,而是能够动态地、在丰富的上下文中,理解每个网页的真正价值和细微差别。
BlockRank的诞生:源于对AI“注意力”的洞察
研究人员并非凭空创造了BlockRank。
它的诞生,源于对LLM在执行上下文检索任务时,其内部的“注意力机制”是如何运作的。
其中,有两种关键的行为模式:
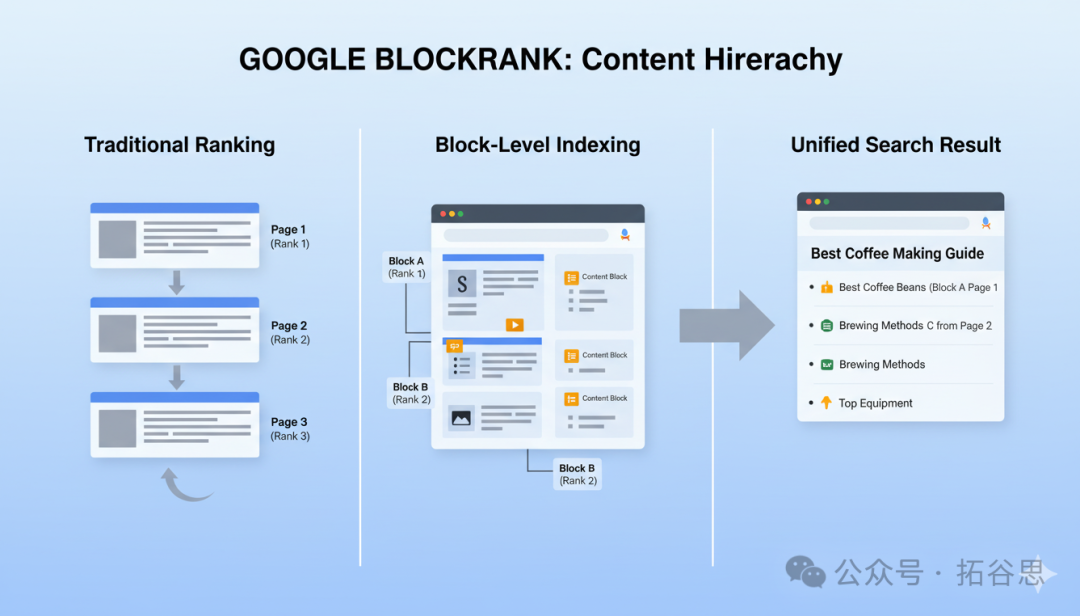
1、文档间块的稀疏性
当LLM在处理多个文档时,它并不会对所有文档都给予同等的关注。
相反,它的注意力会高度集中在少数几个(通常是一到两个)最相关的文档上。
2、查询-文档块相关性
在审视单个文档时,LLM的注意力同样不是均匀分布的。
它会精准地聚焦于文档内部那些与用户查询最直接相关的“块”或段落上。
基于这两个关键发现,研究人员意识到,他们可以设计一个更高效的系统,这个系统不再需要让LLM去处理整个冗长的文档,而只需要让它专注于那些最关键的内容块之上即可。
这就是BlockRank的核心思想。
性能验证:在三大基准测试中表现卓越
为了验证BlockRank的真实能力,研究人员在三个主流的、用于衡量搜索和排名算法性能的基准测试集上,对其进行了严格的测试。
这三个文档排名效果的测试基准分别是:
-
BEIR
-
MS MARCO
-
Natural Questions (NQ)
谷歌将BlockRank与其他强大的排名模型进行了比较,包括 FIRST、RankZephyr、RankVicuna。
BlockRank在这三个基准测试上的表现与这些系统一样好甚至更优秀。
更重要的是,它在保持高精准度的同时,显著提升了效率。

谷歌是否会采用BlockRank?
尽管BlockRank是在谷歌DeepMind内部开发的,但这并不意味着它会被直接、完整地整合进谷歌的主搜索引擎中。
谷歌的搜索引擎是一个极其庞大和复杂的系统,任何改动都需要经过漫长而谨慎的测试。
更有可能发生的是,BlockRank背后的核心理念和技术组件,可能会被逐步地、模块化地融入到谷歌现有的排名系统中。
例如,其高效的“块”分析能力,就可能被用来改进谷歌现有的各种排名和摘要系统。
BlockRank的真正价值,或许不在于它是否会成为谷歌的下一个“官方排名算法”。
而在于它为整个信息检索领域,指明了一条全新的、更高效,也更民主式的发展道路。
*本文观点源于SEJ,仅提供内容分享与参考作用
https://www.searchenginejournal.com/google-blockrank/559074/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









