




 本文介绍了HTTP中的GET与POST请求的区别,如TCP数据包数量和用途上的差异,并探讨了requests库与urllib库在发送HTTP请求时的不同,包括请求方法、请求数据、处理响应、连接方式和编码方式。此外,还讨论了断网后的请求结果以及HTTP状态码的分类和常见状态码。最后,解释了请求头的概念和如何在requests库中添加请求头。
本文介绍了HTTP中的GET与POST请求的区别,如TCP数据包数量和用途上的差异,并探讨了requests库与urllib库在发送HTTP请求时的不同,包括请求方法、请求数据、处理响应、连接方式和编码方式。此外,还讨论了断网后的请求结果以及HTTP状态码的分类和常见状态码。最后,解释了请求头的概念和如何在requests库中添加请求头。
Get与Post请求
本质: get和post本质上都是TCP链接,并无差别,只是由于HTTP的规定和浏览器/服务器的限制,导致他们在应用过程中体现出一些不同。
Get产生一个TCP数据包;Post产生两个TCP数据包。
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);对于POST,浏览器先发送header,服务器响应100(continue),然后再发送data,服务器响应200(返回数据);
对于HTTP协议的GET和POST,他们只有一点根本区别, 一个用于获取数据,一个用于修改数据。
requests库和urllib库的区别
示例:分别用requests库和urllib库向百度发送一个请求,并将其返回结果输出
urllib库:
import urllib.request
url = "https://www.baidu.com"
r = urllib.request.urlopen(url)
print("Response Headers:")
print(r.info())
print('-'*50)
print("Status Code:",r.getcode())
print("Response Body:")
print(r.read())
返回结果:
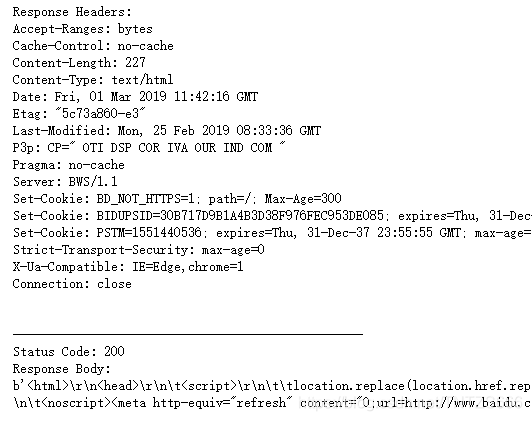
requests库:
import requests
url = "https://www.baidu.com"
r = requests.get(url)
r.encoding = 'utf-8'
print("Response Headers:")
print(r.headers)
print('-'*50)
print("Status Code:",r.status_code)
print("Response Body:")
print(r.text)
返回结果:
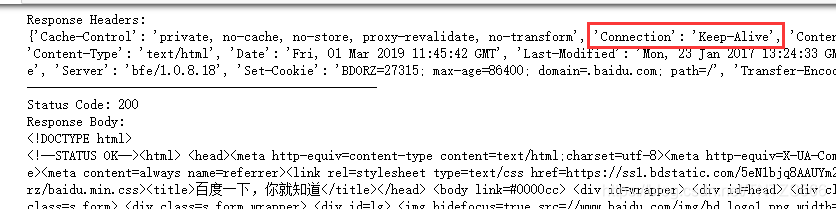
两者比较:
1)请求方法:发送get请求时,第一种使用的urllib库的urlopen方法打开一个url地址,而第二种直接使用requests库的get方法,与http请求方式是对应的,更加直接、易懂
2)请求数据:第一种按照url格式去拼接一个url字符串,显然非常麻烦,第二种按顺序将get请求的url和参数写好就可以了
3)处理响应:第一种处理消息头部、响应状态码和响应正文时分别使用info()、getcode()、read()方法,第二种使用.headers、.status_code、.text方法,方法名称与功能本身相对应,更方便理解、学习和使用。
4)连接方式:看一下返回数据的头信息的“connection”,使用urllib库时,“connection”:“close”,说明每次请求结束关掉socket通道,而使用requests库使用了urllib3,多次请求重复使用一个socket,“connection”:“keep-alive”,说明多次请求使用一个连接,消耗更少的资源。
5)编码方式:requests库的编码方式Accept-Encoding更全,在此不做举例。
由此可见,requests库更容易理解和阅读,符合Python哲学“Readability counts”,可读性很重要~更利于开发人员学习和使用
断网后发出申请的结果
requests库:
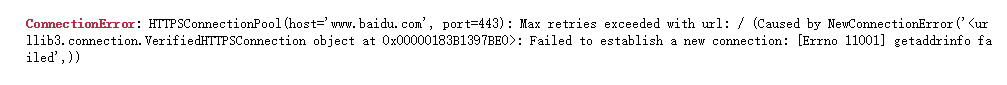
urillb库:

申请返回的状态码
分类
定义: HTTP的状态码是由三个十进制的数字组成,第一个数字表示状态码的类型,后两个字没有分别的作用,http的状态码分为5类
1** :表示的是服务器收到了请求,需要请求者继续执行操作
2** :表示的是请求成功,
3** :重定向 需要进一步的操作来完成请求
4** :客户端错误,请求包含语法错误或者是无法完成的请求
5** :服务器错误,服务器在处理请求的时候出错
常见HTTP状态码:
- 200 -请求成功
- 301 -资源被转移到其他url
- 404 -请求的资源不存在
- 500 -服务器的内部出错
状态码列表
| 状态码 | 状态码英文名称 | 中文描述 |
|---|---|---|
| 100 | Countinue | 继续,客户端应该继续他的请求 |
| 101 | Switching Protocols | 切换协议 |
| 200 | OK | 请求成功,一般用于GET与POST请求 |
| 201 | Created | 以创建。成功请求并创建了新的资源 |
| 202 | Accepted | 以接受,已接受请求,但是为处理完成 |
| 203 | Non-Authoritative Information | 非授权信息,请求成功,返回的数据为原始数据 |
| 204 | No Content | 无内容,服务器处理成功但是没有返回数据 |
| 205 | Reset Content | 重置内容,服务器处理成功,客户端应该重置文档视图 |
| 206 | Partial Content | 部分内容,服务器处理了部分的get请求 |
| 300 | Multiple Choices | 多种选择,请求的资源包括多个位置 |
| 301 | Moved Permanently | 永久的移动,请求的资源已经被永久的移动到新的url |
| 302 | Found | 临时移动,和 301相似 但是资源只是临时的移动,客户端应继续使用原本的url |
| 303 | See Other | 查看其他地址,与301类似使用GET和POST请求查看 |
| 304 | Not Modified | |
| 305 | Use Proxy | 使用代理,访问的资源必须通过代理访问 |
| 307 | Temporary Redirect | 临时重定向 和302 相似 使用的是GET请求重定向 |
| 400 | BadRequest | 客户端语法错误,服务端无法理解 |
| 401 | Unauthorized | 请求需要用户的身份认证 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden | 服务器理解客户端的请求但是,拒绝执行请求 |
| 404 | Not Found | 服务器找不到相应的资源 |
| 405 | Not Acceptable | 客户端请求中的方法被禁止 |
| 406 | Not Acceptable | 服务器无法根据客户端请求的内容特性完成请求 |
| 407 | Proxy Authentication Required | 请求要求代理的身份认证,与401类似,但请求者应当使用代理进行授权 |
| 408 | Request Time-out | 服务器等待客户端发送的请求时间过长,超时 |
| 409 | Conflict | 服务器完成客户端的PUT请求是可能返回此代码,服务器处理请求时发生了冲突 |
| 410 | Gone | 客户端请求的资源已经不存在。410不同于404,如果资源以前有现在被永久删除了可使用410代码,网站设计人员可通过301代码指定资源的新位置 |
| 411 | Length Required | 服务器无法处理客户端发送的不带Content-Length的请求信息 |
| 412 | Precondition Failed | 客户端请求信息的先决条件错误 |
| 413 | Request Entity Too Large | 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个Retry-After的响应信息 |
| 414 | Request-URI Too Large | 请求的URI过长(URI通常为网址),服务器无法处理 |
| 415 | Unsupported Media Type | 服务器无法处理请求附带的媒体格式 |
| 416 | Requested range not satisfiable | 客户端请求的范围无效 |
| 417 | Expectation Failed | 服务器无法满足Expect的请求头信息 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 502 | Bad Gateway | 充当网关或代理的服务器,从远端服务器接收到了一个无效的请求 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中 |
| 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持请求的HTTP协议的版本,无法完成处理 |
什么是请求头,如何添加请求头
定义
通俗来讲,就是能够告诉被请求的服务器需要传送什么样的格式的信息。
HTTP客户程序(例如浏览器),向服务器发送请求的时候必须指明请求类型(一般是GET或者POST)。如有必要,客户程序还可以选择发送其他的请求头。大多数请求头并不是必需的,但Content-Length除外。对于POST请求来说Content-Length必须出现。
使用requests库添加请求头
import requests
url = "http://baidu.com"
header = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*,q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive' }
r = requests.post(url, headers=header)
head = r.headers #响应头
print(head)
print('-'*80)
print(r.request.headers) #请求头
返回结果:


















 478
478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









