






 本文深入介绍了PyTorch的基础知识,从Numpy的使用开始,包括数组生成、算术运算、数组变形、批量处理和广播机制。接着,详细阐述了PyTorch与Numpy的互换、自动梯度机制、使用Numpy和PyTorch实现机器学习的步骤。此外,还探讨了PyTorch的神经网络工具箱,包括构建网络、优化器和动态修改学习率的方法。最后,提到了PyTorch的数据处理工具箱,如DataLoader和数据集的使用,以及Tensorboard的可视化应用。通过本文,读者将全面了解PyTorch的基石和核心概念。
本文深入介绍了PyTorch的基础知识,从Numpy的使用开始,包括数组生成、算术运算、数组变形、批量处理和广播机制。接着,详细阐述了PyTorch与Numpy的互换、自动梯度机制、使用Numpy和PyTorch实现机器学习的步骤。此外,还探讨了PyTorch的神经网络工具箱,包括构建网络、优化器和动态修改学习率的方法。最后,提到了PyTorch的数据处理工具箱,如DataLoader和数据集的使用,以及Tensorboard的可视化应用。通过本文,读者将全面了解PyTorch的基石和核心概念。
深度学习框架:TensorFlow、PyTorch、Keras、FastAI、CNTK等。
神经网络:卷积神经网络、循环神经网络、对抗式神经网络
目录
第一部分 PyTorch基础
1、Numpy基础


1.1 生成Numpy数组
import numpy as np
# 1、创建数组
lst1 = [3.14, 2.17, 0, 1, 2]
nd1 = np.array(lst1) # 列表转换成ndarray
print(nd1) # [3.14 2.17 0. 1. 2. ]
print(type(nd1)) # <class 'numpy.ndarray'>
lst2 = [[3.14, 2.17, 0, 1, 2], [1, 2, 3, 4, 5]]
nd2 = np.array(lst2) # 嵌套列表可以转换成多维ndarray
print(nd2)
# [[3.14 2.17 0. 1. 2. ]
# [1. 2. 3. 4. 5. ]]
# 2、随机生成数组
np.random.seed(123) # 指定一个随机种子,每次生成同一份数据
nd3 = np.random.random([3, 3]) # 生成0-1之间的随机数
print(nd3)
# [[0.69646919 0.28613933 0.22685145]
# [0.55131477 0.71946897 0.42310646]
# [0.9807642 0.68482974 0.4809319 ]]
np.random.shuffle(nd3) # 打乱生成的随机数
print(nd3)
# [[0.9807642 0.68482974 0.4809319 ]
# [0.69646919 0.28613933 0.22685145]
# [0.55131477 0.71946897 0.42310646]]
print("nd3的形状为:", nd3.shape) # nd3的形状为: (3, 3)
# 3、创建特定形状的多维数组
nd5 = np.zeros([3, 3]) # 生成全是 0 的 3x3 矩阵
# np.zeros_like(nd5) # 生成与nd5形状一样的全0矩阵
nd6 = np.ones([3, 3]) # 生成全是 1 的 3x3 矩阵
nd7 = np.eye(3) # 生成 3 阶的单位矩阵
nd8 = np.diag([1, 2, 3]) # 生成 3 阶对角矩阵
print(nd5)
# [[0. 0. 0.]
# [0. 0. 0.]
# [0. 0. 0.]]
nd9 = np.random.random([5, 5])
np.savetxt(X=nd9, fname='./test1.txt') # 保存数据到文件中
nd10 = np.loadtxt('./test1.txt')
print(nd10)
# 4、利用arange、linspace函数生成数组
# arange([start,] stop[,step,], dtype=None)
# start与stop用来指定范围,step用来设定步长。start默认为0,步长step可为小数
print(np.arange(10)) # [0 1 2 3 4 5 6 7 8 9]
print(np.arange(0, 10)) # [0 1 2 3 4 5 6 7 8 9]
print(np.arange(1, 4, 0.5)) # [1. 1.5 2. 2.5 3. 3.5]
print(np.arange(9, -1, -1)) # [9 8 7 6 5 4 3 2 1 0]1.2 获取元素

np.random.seed(2019)
nd11 = np.random.random([10]) # 生成0-1之间的随机数
print(nd11)
print(nd11[3]) # 获取指定位置的数据,获取第4个元素
print(nd11[3:6]) # 截取一段数据:包括3不包括6(从0开始)
print(nd11[1:6:2]) # 截取固定间隔数据
print(nd11[::-2]) # 倒序隔两位取数
nd12 = np.arange(25).reshape([5, 5]) # (0-24)截取一个多维数组的一个区域内数据
print(nd12)
print(nd12[1:3, 1:3]) # 2*2,不包括3
print(nd12[(nd12 > 3) & (nd12 < 10)]) # 截取一个多维数组中,数值在一个值域之内的数据
# 截取多维数组中,指定的行,如读取第2,3行
print(nd12[[1, 2]]) # 或nd12[1:3,:]
print(nd12[:, 1:3]) # 截取多维数组中,指定的列,如读取第2,3列
random.choice函数从指定的样本中随机抽取数据:
"""random.choice函数从指定的样本中随机抽取数据。"""
a = np.arange(1, 25, dtype=float)
print(a)
c1 = nr.choice(a, size=(3, 4)) # size指定输出数组形状
c2 = nr.choice(a, size=(3, 4), replace=False) # replace缺省为True,即可重复抽取。
# #下式中参数p指定每个元素对应的抽取概率,缺省为每个元素被抽取的概率相同。
c3 = nr.choice(a, size=(3, 4), p=a / np.sum(a))
print("随机可重复抽取")
print(c1)
print("随机但不重复抽取")
print(c2)
print("随机但按制度概率抽取")
print(c3)
1.3 Numpy的算术运算

A = np.array([[1, 2], [-1, 4]])
B = np.array([[2, 0], [3, 4]])
print(A * B) # 结果:[[2, 0], [-3, 16]]
print(np.multiply(A, B)) # 结果:[[2, 0], [-3, 16]]X = np.random.rand(2, 3)
def softmoid(x):
return 1 / (1 + np.exp(-x))
def relu(x):
return np.maximum(0, x)
def softmax(x):
return np.exp(x) / np.sum(np.exp(x)) # (2, 3)
print("输入参数X的形状:", X.shape) # (2, 3)
print("激活函数softmoid输出形状:", softmoid(X).shape) # (2, 3)
print("激活函数relu输出形状:", relu(X).shape) # (2, 3)
print("激活函数softmax输出形状:", softmax(X).shape) # (2, 3)
"""矩阵乘法"""
X1 = np.array([[1, 2], [3, 4]])
X2 = np.array([[5, 6, 7], [8, 9, 10]])
X3 = np.dot(X1, X2)
print(X3)1.4 数组变形
更改数组的形状

"""1、reshape:改变向量的维度(不修改向量本身),所指定的行数或列数一定要能被整除"""
arr = np.arange(10) # [0 1 2 3 4 5 6 7 8 9]
print(arr) # 将向量 arr 维度变换为2行5列
print(arr.reshape(2, 5))
# 指定维度时可以只指定行数或列数, 其他用 -1 代替
print(arr.reshape(5, -1)) # 5行
print(arr.reshape(-1, 5)) # 5列
"""2、resize:改变向量的维度(修改向量本身)"""
# 将向量 arr 维度变换为2行5列
arr.resize(2, 5)
print(arr)
"""3、T:向量转置"""
arr = np.arange(12).reshape(3, 4) # 向量 arr 为3行4列
print(arr)
print(arr.T) # 将向量 arr 进行转置为4行3列
"""4、ravel:向量展平"""
arr = np.arange(6).reshape(2, -1) # 输出结果: [[0 1 2] [3 4 5]]
print(arr)
print(arr.ravel()) # 按照行优先,展平 [0 1 2 3 4 5]
print(arr.ravel('F')) # 按照列优先,展平 [0 3 1 4 2 5]
"""
5、flatten:把矩阵转换为向量
[[6. 7. 1. 2.]
[9. 5. 7. 2.]
[6. 4. 7. 2.]]
结果:
[6. 7. 1. 2. 9. 5. 7. 2. 6. 4. 7. 2.]
"""
a = np.floor(10 * np.random.random((3, 4)))
print(a)
print(a.flatten())
"""
6、squeeze:降维,把矩阵中含1的维度去掉。
[[0]
[1]
[2]]
结果:
[0 1 2]
[[[[0]
[1]]]
[[[2]
[3]]]
[[[4]
[5]]]]
结果:
[[0 1]
[2 3]
[4 5]]
"""
arr = np.arange(3).reshape(3, 1)
print(arr)
print(arr.shape) # (3,1)
print(arr.squeeze())
print(arr.squeeze().shape) # (3,)
arr1 = np.arange(6).reshape(3, 1, 2, 1)
print(arr1)
print(arr1.shape) # (3, 1, 2, 1)
print(arr1.squeeze().shape) # (3, 2)
print(arr1.squeeze())
"""
7、transpose:对高维矩阵进行轴对换,,比如把图片中表 示颜色顺序的RGB改为GBR
[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]
(2, 3, 4)
轴对换后:
[[[ 0 12]
[ 1 13]
[ 2 14]
[ 3 15]]
[[ 4 16]
[ 5 17]
[ 6 18]
[ 7 19]]
[[ 8 20]
[ 9 21]
[10 22]
[11 23]]]
(3, 4, 2)
"""
arr2 = np.arange(24).reshape(2, 3, 4)
print(arr2)
print(arr2.shape) # (2, 3, 4)
print(arr2.transpose(1, 2, 0))
print(arr2.transpose(1, 2, 0).shape) # (3, 4, 2)合并数组

"""1、append"""
# 一维数组
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
c = np.append(a, b)
print(c) # [1 2 3 4 5 6]
# 多维数组
a = np.arange(4).reshape(2, 2)
b = np.arange(4).reshape(2, 2)
c = np.append(a, b, axis=0) # 按行合并
print('按行合并后的结果:\n', c)
print('合并后数据维度:', c.shape)
d = np.append(a, b, axis=1) # 按列合并
print('按列合并后的结果\n', d)
print('合并后数据维度:', d.shape)
"""2、concatenate:沿指定轴连接数组或矩阵"""
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6]])
c = np.concatenate((a, b), axis=0)
print(c)
d = np.concatenate((a, b.T), axis=1)
print(d)
"""3、stack:沿指定轴堆叠数组或矩阵"""
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6], [7, 8]])
print(np.stack((a, b), axis=0))
1.5 批量处理
# 生成10000个形状为2X3的矩阵
data_train = np.random.randn(10000, 2, 3) # 标准正态的随机数
# 这是一个3维矩阵,第1个维度为样本数,后两个是数据形状
print(data_train.shape) # (10000,2,3)
np.random.shuffle(data_train) # 打乱这10000条数据
batch_size = 100 # 定义批量大小
# 进行批处理
for i in range(0, len(data_train), batch_size):
x_batch_sum = np.sum(data_train[i:i + batch_size])
print("第{}批次,该批次的数据之和:{}".format(i, x_batch_sum))
1.6 通用函数


math与numpy函数的性能比较
"""math与numpy函数的性能比较"""
x = [i * 0.001 for i in np.arange(1000000)]
start = time.clock()
for i, t in enumerate(x):
x[i] = math.sin(t)
print("math.sin:", time.clock() - start)
x = [i * 0.001 for i in np.arange(1000000)]
x = np.array(x)
start = time.clock()
np.sin(x)
print("numpy.sin:", time.clock() - start)![]()
结论:numpy.sin比math.sin快近10倍
循环与向量运算比较
x1 = np.random.rand(1000000)
x2 = np.random.rand(1000000)
# 使用循环计算向量点积
tic = time.process_time()
dot = 0
for i in range(len(x1)):
dot += x1[i] * x2[i]
toc = time.process_time()
print("dot = " + str(dot) + "\n for loop----- Computation time = " + str(1000 * (toc - tic)) + "ms")
# 使用numpy函数求点积
tic = time.process_time()
dot = 0
dot = np.dot(x1, x2)
toc = time.process_time()
print("dot = " + str(dot) + "\n verctor version---- Computation time = " + str(1000 * (toc - tic)) + "ms")
1.7 广播机制
四条规则:
- 让所有输入数组都向其中shape最长的数组看齐,不足的部分则通过 在前面加1补齐,如: a:2×3×2 ;b:3×2 ;则b向a看齐,在b的前面加1,变为:1×3×2。
- 输出数组的shape是输入数组shape的各个轴上的最大值;
- 如果输入数组的某个轴和输出数组的对应轴的长度相同或者某个轴 的长度为1时,这个数组能被用来计算,否则出错;
- 当输入数组的某个轴的长度为1时,沿着此轴运算时都用(或复制) 此轴上的第一组值。

A = np.arange(0, 40, 10).reshape(4, 1) # 0 10 20 30 (4*1)
B = np.arange(0, 3) # [0 1 2] (3,)
print("A矩阵的形状:{},B矩阵的形状:{}".format(A.shape, B.shape))
C = A + B
print("C矩阵的形状:{}".format(C.shape))
print(C)2、PyTorch基础
GPU版本PyTorch:Python、PyTorch、GPU的驱动(英伟达的NVIDIA)、CUDA、cuDNN计算 框架
后台启动jupyter notebook:nohup jupyter notebook >/dev/null 2>&1 &(localhost:8888)
2.4 Numpy与Tensor
x = torch.tensor([1, 2])
y = torch.tensor([3, 4])
z = x.add(y) # x不变 z:tensor([4, 6]) x:tensor([1, 2])
x.add_(y) # x改变
torch.Tensor([1, 2, 3, 4, 5, 6]) # 根据list数据生成Tensor
torch.Tensor(2, 3) # 根据指定形状生成Tensor
t = torch.Tensor([[1, 2, 3], [4, 5, 6]]) # 根据给定的Tensor的形状生成Tensor
# 查看Tensor的形状
print(t.size()) # shape与size()等价方式:t.shape
torch.Tensor(t.size()) # 根据已有形状创建Tensor
"""torch.Tensor与torch.tensor的区别"""
t1 = torch.Tensor(1) # 默认dtype(FloatTensor),返回一个大小为1的张量
t2 = torch.tensor(1) # 从数据中推断数据类型, 返回一个固定值1
print("t1的值{},t1的数据类型{}".format(t1, t1.type()))
print("t2的值{},t2的数据类型{}".format(t2, t2.type()))
"""自动生成Tensor"""
print(torch.eye(2, 2)) # 生成一个单位矩阵
print(torch.zeros(2, 3)) # 自动生成全是0的矩阵
print(torch.linspace(1, 10, 4)) # 根据规则生成数据
print(torch.rand(2, 3)) # 生成满足均匀分布随机数
print(torch.randn(2, 3)) # 生成满足标准分布随机数
print(torch.zeros_like(torch.rand(2, 3))) # 返回所给数据形状相同,值全为0的张量
"""修改Tensor形状"""
x = torch.randn(2, 3) # 生成一个形状为2x3的矩阵
print(x.size()) # 查看矩阵的形状, 结果为torch.Size([2, 3])
print(x.dim()) # 查看x的维度, 结果为2
x.view(3, 2) # 把x变为3x2的矩阵
y = x.view(-1) # 把x展平为1维向量
print(y.shape) # torch.Size([6])
z = torch.unsqueeze(y, 0) # 添加一个维度
print(z.size()) # 查看z的形状, 结果为torch.Size([1, 6])
print(z.numel()) # 计算Z的元素个数, 结果为6
"""索引操作"""
torch.manual_seed(100) # 设置一个随机种子
x = torch.randn(2, 3) # 生成一个形状为2x3的矩阵
print(x)
print(x[0, :]) # 根据索引获取第1行,所有数据
print(x[:, -1]) # 获取最后一列数据
# 生成是否大于0的Byter张量
mask = x > 0
print(torch.masked_select(x, mask)) # 获取大于0的值(使用二元值进行选择)
print(torch.nonzero(mask)) # 获取非0下标,即行,列索引
# 获取指定索引对应的值,输出根据以下规则得到
# out[i][j] = input[index[i][j]][j] # if dim == 0
# out[i][j] = input[i][index[i][j]] if dim == 1
index = torch.LongTensor([[0, 1, 1]])
# 在指定维度上选择数据,输出的形状与index(index的类型必须是LongTensor类型的)一致
print(torch.gather(x, 0, index))
index = torch.LongTensor([[0, 1, 1], [1, 1, 1]])
a = torch.gather(x, 1, index)
print(a)
# 把a的值返回到一个2x3的0矩阵中
z = torch.zeros(2, 3)
print(z.scatter_(1, index, a)) # 为gather的反操作,根据指定索引补充数据"""广播机制"""
A = np.arange(0, 40, 10).reshape(4, 1)
B = np.arange(0, 3)
# 把ndarray转换为Tensor
A1 = torch.from_numpy(A) # 形状为4x1
B1 = torch.from_numpy(B) # 形状为3, [0 1 2]
C = A1 + B1 # Tensor自动实现广播
print(C)
# 我们可以根据广播机制,手工进行配置
# 根据规则1,B1需要向A1看齐,把B变为(1,3)
B2 = B1.unsqueeze(0) # B2的形状为1x3 [[0, 1, 2]]
# 使用expand函数重复数组,分别的4x3的矩阵
A2 = A1.expand(4, 3) # 原为4x1
B3 = B2.expand(4, 3) # 原为 [[0, 1, 2]]
# 然后进行相加,C1与C结果一致
C1 = A2 + B3
print(C1)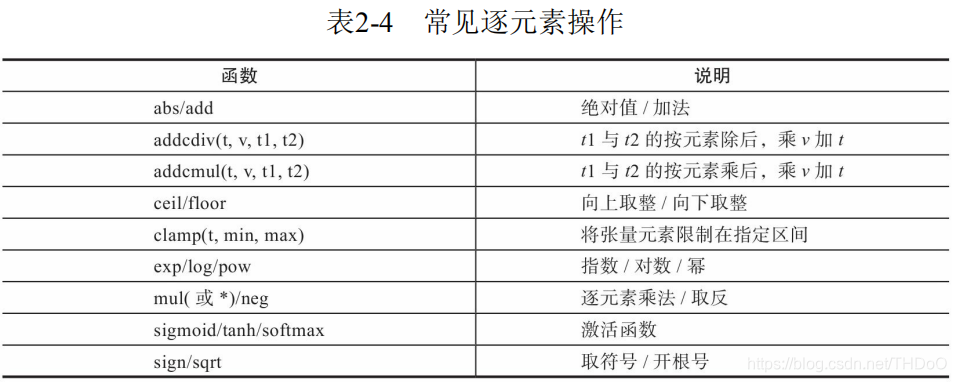
"""逐元素操作"""
t = torch.randn(1, 3) # tensor([[ 1.2224, 0.1619, -0.0745]])
t1 = torch.randn(3, 1)
t2 = torch.randn(1, 3)
print(t+0.1*(t1/t2))
print(torch.addcdiv(t, 0.1, t1, t2)) # t1与t2的按元素除后,乘0.1加 t
print(torch.sigmoid(t)) # 计算sigmoid
print(torch.clamp(t, 0, 1)) # 将t限制在[0,1]之间
# 这些操作均会创建新的Tensor,如果需要就地操作,可以使用这些方法的下划线版本,例如abs_
print(t.add_(2)) # t+2进行就地运算

"""归并操作"""
# 生成一个含6个数的向量 tensor([ 0., 2., 4., 6., 8., 10.])
a = torch.linspace(0, 10, 6)
# 使用view方法,把a变为2x3矩阵
# tensor([[ 0., 2., 4.],
# [ 6., 8., 10.]])
a = a.view((2, 3))
# dim=0, 沿y轴方向累加 tensor([ 6., 10., 14.])
b = a.sum(dim=0) # b的形状为[3]
# 沿y轴方向累加,即dim=0,并保留含1的维度 tensor([[ 6., 10., 14.]])
b = a.sum(dim=0, keepdim=True) # b的形状为[1,3]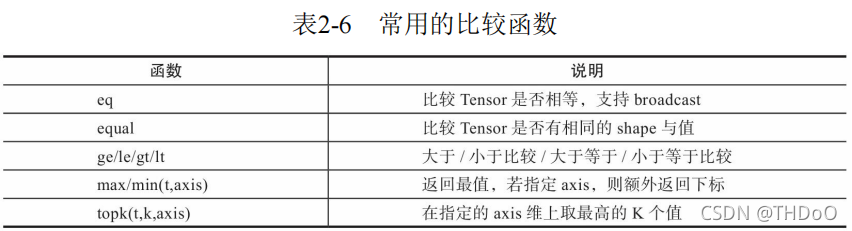
"""比较操作"""
import torch
# linspace()从start 到end,均匀切分成steps份
x = torch.linspace(0, 10, 6).view(2, 3) # tensor([[ 0., 2., 4.], [ 6., 8., 10.]])
print(torch.max(x)) # 求所有元素的最大值, tensor(10.)
# 求y轴方向的最大值
print(torch.max(x, dim=0)) # 结果为[6,8,10], indices=tensor([1, 1, 1])
# 求最大的2个元素
# 结果为values=tensor([[ 6., 8., 10.]]), 对应索引为indices=tensor([[1, 1, 1]])
print(torch.topk(x, 1, dim=0))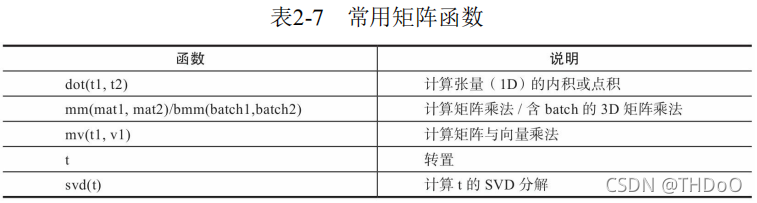
"""矩阵操作"""
a = torch.tensor([2, 3])
b = torch.tensor([3, 4])
print(torch.dot(a, b)) # 计算张量内积或点积 运行结果: tensor(18)
x = torch.randint(10, (2, 3)) # 0-9随机
y = torch.randint(6, (3, 4))
print(torch.mm(x, y)) # 计算矩阵乘法, 对2D的矩阵进行点积
x = torch.randint(10, (2, 2, 3))
y = torch.randint(6, (2, 3, 4))
print(torch.bmm(x, y)) # 含batch的3D进行点积运算
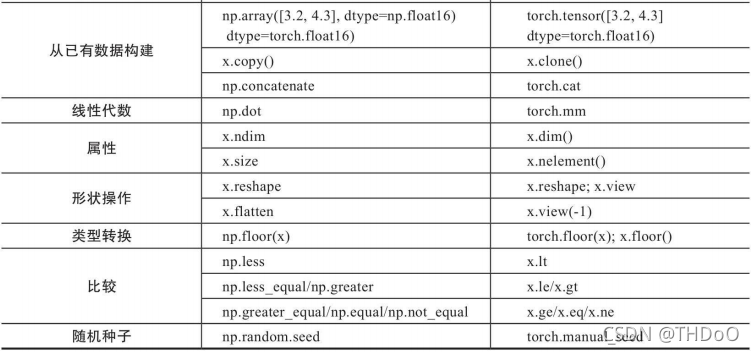
2.5 Tensor 与Autograd
1、计算图:是一种有向无环图(DAG),用图形方式来表示算子与变量之间的关 系。圆形表示变量,矩阵表示算子。z=wx+b,可写成两个表示式:y=wx,则z=y+b。y、z是计算得到的变量,非叶子节点,z为根节点。mul 和add是算子(或操作或函数)。由这些变量及算子,就构成一个完整的计 算过程(或前向传播过程)。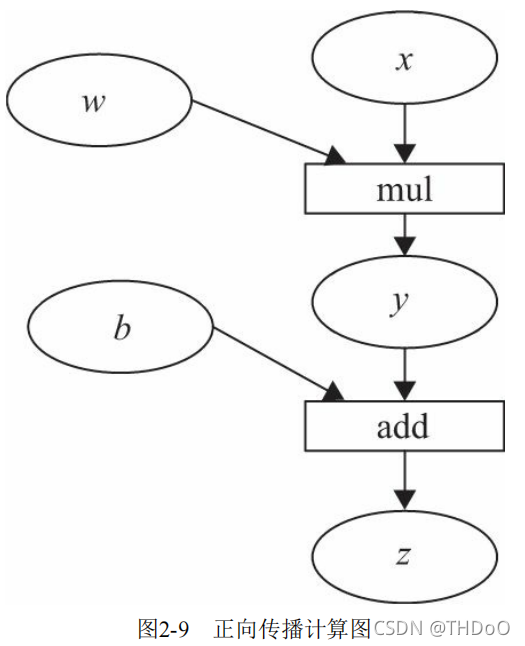
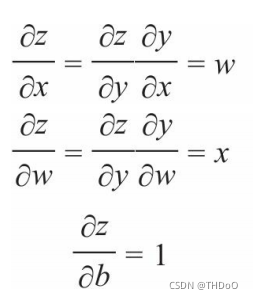
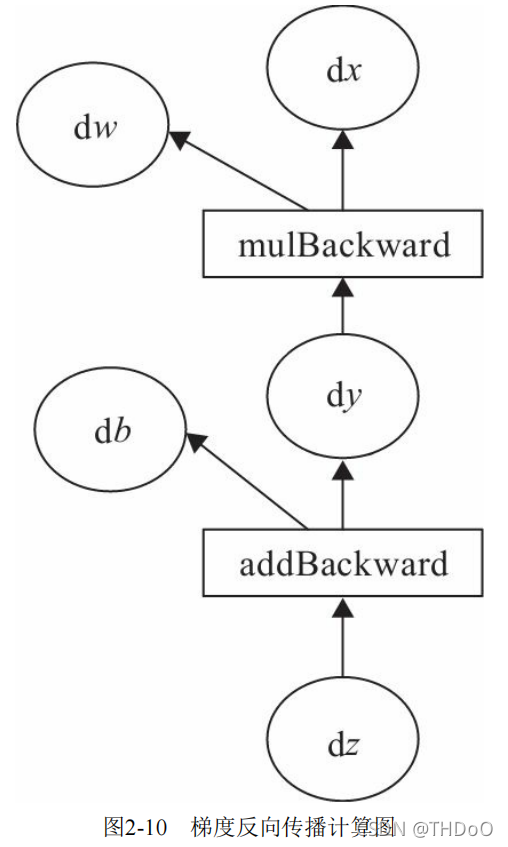
"""标量反向传播"""
"""(1)定义叶子节点及算子节点"""
# 定义输入张量x
x = torch.Tensor([2]) # tensor([2.])
# 初始化权重参数W,偏移量b、并设置require_grad属性为True,为自动求导
w = torch.randn(1, requires_grad=True)
b = torch.randn(1, requires_grad=True)
# 实现前向传播 z=wx+b; 两个表示式:y=wx,则z=y+b。
y = torch.mul(w, x) # 等价于 w*x
z = torch.add(y, b) # 等价于 y+b
# 查看x,w,b页子节点的requite_grad属性
# 运行结果:x,w,b的require_grad属性分别为:False,True,True
print("x,w,b的require_grad属性分别为:{},{},{}"
.format(x.requires_grad, w.requires_grad, b.requires_grad))
"""(2)查看叶子节点、非叶子节点的其他属性"""
# 查看非叶子节点的requres_grad属性
print("y,z的requires_grad属性分别为:{},{}".format(y.requires_grad, z.requires_grad))
# 因与w,b有依赖关系,故y,z的requires_grad属性也是:True,True
# 查看各节点是否为叶子节点
print("x,w,b,y,z的是否为叶子节点:{},{},{},{},{}".format(x.is_leaf, w.is_leaf, b.is_leaf, y.is_leaf, z.is_leaf))
# x,w,b,y,z的是否为叶子节点:True,True,True,False,False
# 查看叶子节点的grad_fn属性
print("x,w,b的grad_fn属性:{},{},{}".format(x.grad_fn, w.grad_fn, b.grad_fn))
# 因x,w,b为用户创建的,为通过其他张量计算得到,故x,w,b的grad_fn属性:None,None,None
# 查看非叶子节点的grad_fn属性
print("y,z的是否为叶子节点:{},{}".format(y.grad_fn, z.grad_fn))
# y,z的是否为叶子节点:
# <MulBackward0 object at 0x0000019EEDDAB390>,<AddBackward0 object at 0x0000019EEDDAB438>
"""(3)自动求导,实现梯度方向传播,即梯度的反向传播"""
# 基于z张量进行梯度反向传播,执行backward之后计算图会自动清空,
z.backward() # None
# 如果需要多次使用backward,需要修改参数retain_graph为True,此时梯度是累加的
# z.backward(retain_graph=True)
# 查看叶子节点的梯度,x是叶子节点但它无须求导,故其梯度为None
print("参数w,b,x的梯度分别为:{},{},{}".format(w.grad, b.grad, x.grad))
# 参数w,b的梯度分别为:tensor([2.]),tensor([1.]),None
# 非叶子节点的梯度,执行backward之后,会自动清空
print("非叶子节点y,z的梯度分别为:{},{}".format(y.grad, z.grad))
# 非叶子节点y,z的梯度分别为:None,None
PyTorch规定:不让张量(Tensor)对张量求导,只允许标量对张量求导。
"""非标量反向传播"""
"""(1)定义叶子节点及计算节点"""
# 定义叶子节点张量x,形状为1x2
x = torch.tensor([[2, 3]], dtype=torch.float, requires_grad=True)
J = torch.zeros(2, 2) # 初始化Jacobian矩阵 tensor([[0., 0.], [0., 0.]])
y = torch.zeros(1, 2) # 初始化目标张量,形状为1x2 tensor([[0., 0.]])
# 定义y与x之间的映射关系:y1=x1**2(平方)+3*x2,y2=x2**2+2*x1
y[0, 0] = x[0, 0] ** 2 + 3 * x[0, 1]
y[0, 1] = x[0, 1] ** 2 + 2 * x[0, 0]"""(2)手工计算y对x的梯度"""
![]()
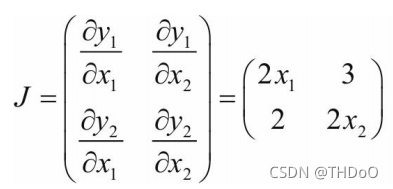
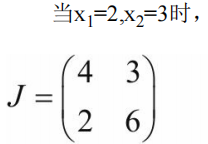
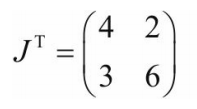 (TRUE)
(TRUE)
"""(3)调用backward来获取y对x的梯度"""
y.backward(torch.Tensor([[1, 1]]))
print(x.grad) # 结果为tensor([[6., 9.]])
#结果与我们手工运算的不符,显然这个结果是【错误】的 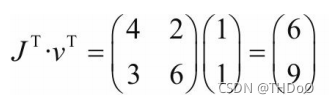 (FALSE)
(FALSE)
错在v的取值,通过这种方式得到的并不是y对x的梯度。
分成两步计算。首先让v=(1,0)得到y1对x的梯度,然后使v= (0,1),得到y2对x的梯度。这里因需要重复使用backward(),需要使参数 retain_graph=True.
# 生成y1对x的梯度
y.backward(torch.Tensor([[1, 0]]), retain_graph=True)
J[0] = x.grad
x.grad = torch.zeros_like(x.grad) # 梯度是累加的,故需要对x的梯度清零
# 生成y2对x的梯度
y.backward(torch.Tensor([[0, 1]]))
J[1] = x.grad
print(J) # 显示jacobian矩阵的值 tensor([[4., 3.], [2., 6.]]) 【正确】2.6 使用Numpy实现机器学习
1、首先,给出一个数组x,然后基于表达式,加上一些噪音数据 到达另一组数据y。
2、然后,构建一个机器学习模型,学习表达式 的两个参数w、b。 利用数组x,y的数据为训练数据。
3、最后,采用梯度梯度下降法,通过多次迭代,学习到w、b的值。
"""(1)导入需要的库"""
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
"""(2)生成输入数据x及目标数据y"""
np.random.seed(100) # 设置随机数种子,生成同一个份数据
x = np.linspace(-1, 1, 100).reshape(100, 1)
y = 3 * np.power(x, 2) + 2 + 0.2 * np.random.rand(x.size).reshape(100, 1)
"""(3)查看x、y数据分布情况"""
plt.scatter(x, y) # 画图
plt.show()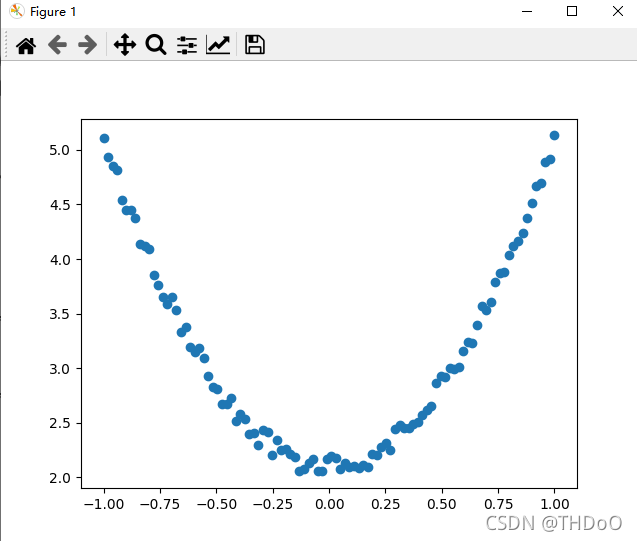
"""(4)初始化权重参数"""
# 随机初始化参数
w1 = np.random.rand(1, 1)
b1 = np.random.rand(1, 1)定义损失函数,假设批量大小为100: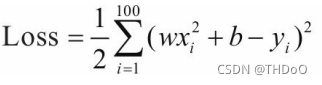
对损失函数求导: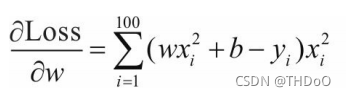
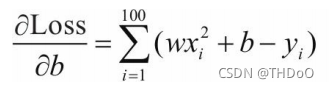
利用梯度下降法学习参数,学习率为lr: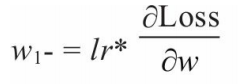
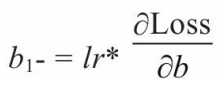
"""(5)训练模型"""
lr = 0.001 # 学习率
for i in range(800):
# 前向传播
y_pred = np.power(x, 2) * w1 + b1
# 定义损失函数
loss = 0.5 * (y_pred - y) ** 2
loss = loss.sum() # 计算梯度
grad_w = np.sum((y_pred - y) * np.power(x, 2))
grad_b = np.sum((y_pred - y))
# 使用梯度下降法,是loss最小
w1 -= lr * grad_w
b1 -= lr * grad_b
"""(6)可视化结果"""
plt.plot(x, y_pred, 'r-', label='predict')
plt.scatter(x, y, color='blue', marker='o', label='true') # true data
plt.xlim(-1, 1)
plt.ylim(2, 6)
plt.legend()
plt.show()
print(w1, b1) # [[2.98927619]] [[2.09818307]] 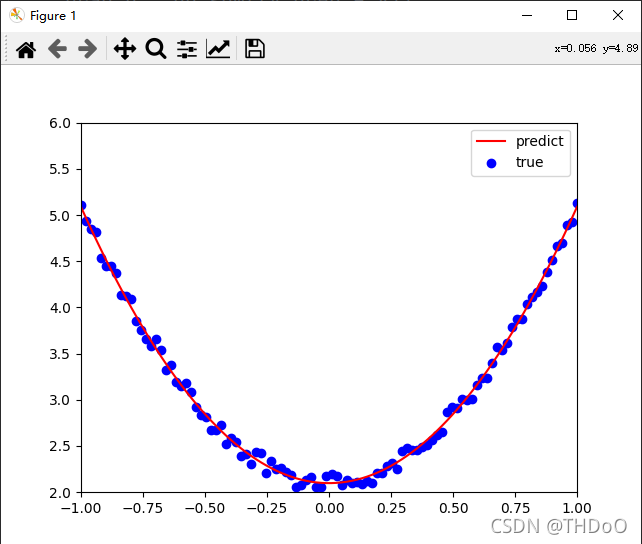
2.7 使用Tensor及Antograd实现机器学习
允许副本存在
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
"""(1)导入需要的库"""
import torch as t
from matplotlib import pyplot as plt
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
"""(2)生成训练数据,并可视化数据分布情况"""
t.manual_seed(100)
dtype = t.float
# 生成x坐标数据,x为tenor,需要把x的形状转换为100x1
x = t.unsqueeze(t.linspace(-1, 1, 100), dim=1)
# 生成y坐标数据,y为tenor,形状为100x1,另加上一些噪声
y = 3 * x.pow(2) + 2 + 0.2 * t.rand(x.size())
# 画图,把tensor数据转换为numpy数据
plt.scatter(x.numpy(), y.numpy())
plt.show() 
"""(3)初始化权重参数"""
# 随机初始化参数,参数w、b为需要学习的,故需requires_grad=True
w = t.randn(1, 1, dtype=dtype, requires_grad=True)
b = t.zeros(1, 1, dtype=dtype, requires_grad=True)
"""(4)训练模型"""
lr = 0.001 # 学习率
for ii in range(800):
# 前向传播,并定义损失函数loss
y_pred = x.pow(2).mm(w) + b
loss = 0.5 * (y_pred - y) ** 2
loss = loss.sum()
# 自动计算梯度,梯度存放在grad属性中
loss.backward()
# 手动更新参数,需要用torch.no_grad(),使上下文环境中切断自动求导的计算
with t.no_grad():
w -= lr * w.grad
b -= lr * b.grad
# 梯度清零
w.grad.zero_()
b.grad.zero_()
"""(5)可视化训练结果"""
plt.plot(x.numpy(), y_pred.detach().numpy(), 'r-', label='predict') # predict
plt.scatter(x.numpy(), y.numpy(), color='blue', marker='o', label='true') # true data
plt.xlim(-1, 1)
plt.ylim(2, 6)
plt.legend()
plt.show()
print(w, b)
# tensor([[2.9645]], requires_grad=True) tensor([[2.1146]], requires_grad=True)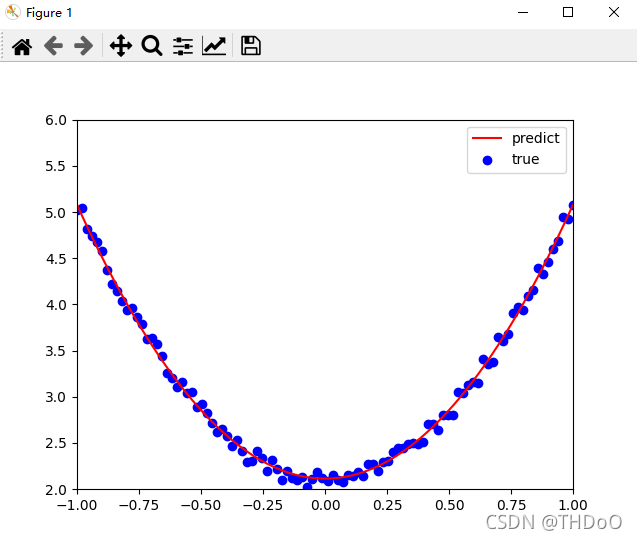
2.8 使用TensorFlow架构
import tensorflow as tf
import numpy as np
from matplotlib import pyplot as plt
"""(1)导入库及生成训练数据"""
np.random.seed(100)
x = np.linspace(-1, 1, 100).reshape(100, 1)
y = 3 * np.power(x, 2) + 2 + 0.2 * np.random.rand(x.size).reshape(100, 1)
"""(2)初始化参数"""
# 创建两个占位符,分别用来存放输入数据x和目标值y
# 运行计算图时,导入数据.
x1 = tf.placeholder(tf.float32, shape=(None, 1))
y1 = tf.placeholder(tf.float32, shape=(None, 1))
# 创建权重变量w和b,并用随机值初始化.
# TensorFlow 的变量在整个计算图保存其值.
w = tf.Variable(tf.random_uniform([1], 0, 1.0))
b = tf.Variable(tf.zeros([1]))
"""(3)实现前向传播及损失函数"""
y_pred = np.power(x, 2) * w + b # 前向传播,计算预测值.
loss = tf.reduce_mean(tf.square(y - y_pred)) # 计算损失值
# 计算有关参数w、b关于损失函数的梯度.
grad_w, grad_b = tf.gradients(loss, [w, b])
# 用梯度下降法更新参数. 执行计算图时给 new_w1 和new_w2 赋值
# 对TensorFlow 来说,更新参数是计算图的一部分内容,而PyTorch,这部分属于计算图之外.
learning_rate = 0.01
new_w = w.assign(w - learning_rate * grad_w)
new_b = b.assign(b - learning_rate * grad_b)
"""(4)训练模型"""
# 已构建计算图,接下来创建TensorFlow session,准备执行计算图.
with tf.Session() as sess:
# 执行之前需要初始化变量w、b
sess.run(tf.global_variables_initializer())
for step in range(2000):
# 循环执行计算图. 每次需要把x1、y1赋给x和y.
# 每次执行计算图时,需要计算关于new_w和new_b的损失值, 返回numpy多维数组
loss_value, v_w, v_b = sess.run([loss, new_w, new_b],
feed_dict={x1: x, y1: y})
if step % 200 == 0: # 每200次打印一次训练结果
print("损失值、权重、偏移量分别为{:.4f},{},{}".format(loss_value, v_w, v_b))
"""(5)可视化结果"""
plt.figure()
plt.scatter(x,y)
plt.plot(x, v_b + v_w*x**2)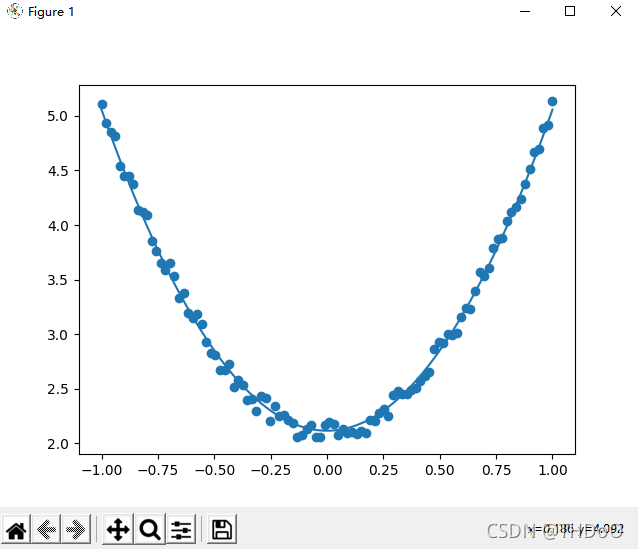
运行结果:
损失值、权重、偏移量分别为10.1084,[0.18666345],[0.0612011]
损失值、权重、偏移量分别为0.1622,[1.6832255],[2.549754]
损失值、权重、偏移量分别为0.0851,[2.0572715],[2.4431512]
损失值、权重、偏移量分别为0.0457,[2.3191078],[2.3464773]
损失值、权重、偏移量分别为0.0253,[2.5074914],[2.2766845]
损失值、权重、偏移量分别为0.0147,[2.6430826],[2.226448]
损失值、权重、偏移量分别为0.0092,[2.7406776],[2.1902893]
损失值、权重、偏移量分别为0.0064,[2.8109221],[2.1642632]
损失值、权重、偏移量分别为0.0049,[2.8614826],[2.1455307]
损失值、权重、偏移量分别为0.0042,[2.8978734],[2.1320477]
TensorFlow使用静态图,其特点是先构造图形(如果不显式说明, TensorFlow会自动构建一个缺省图形),然后启动Session,执行相关程序。 这个时候程序才开始运行,前面都是铺垫,所以也没有运行结果。
而 PyTorch的动态图,动态的最关键的一点就是它是交互式的,而且执行每个 命令马上就可看到结果,这对训练、发现问题、纠正问题非常方便,且其构 图是一个叠加(动态)过程,期间我们可以随时添加内容,这些特征对于训练和调试过程是非常有帮助的。
3、PyTorch神经网络工具箱
3.1 神经网络核心组件
(1)层:神经网络的基本结构,将输入张量转换为输出张量。
(2)模型:层构成的网络。
(3)损失函数:参数学习的目标函数,通过最小化损失函数来学习各种参数。
(4)优化器:如何使损失函数最小,这就涉及优化器。
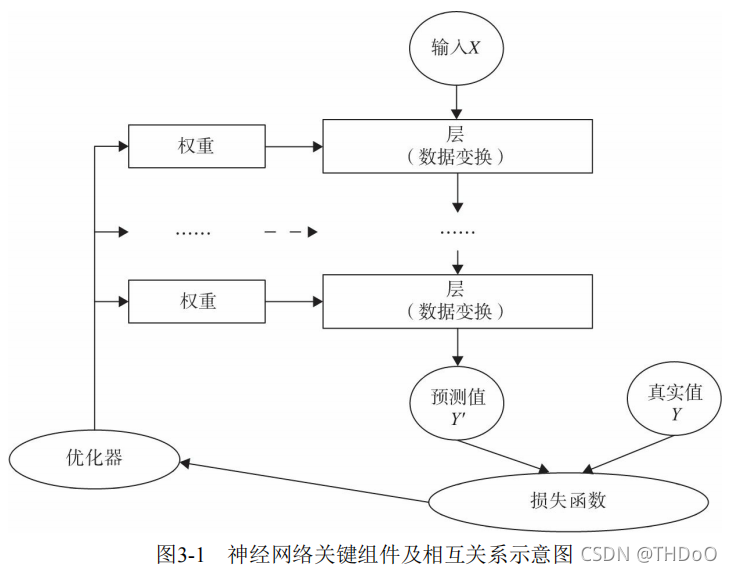
多个层链接在一起构成一个模型或网络,输入数据通过这个模型转换为 预测值,然后损失函数把预测值与真实值进行比较,得到损失值(损失值可 以是距离、概率值等),该损失值用于衡量预测值与目标结果的匹配或相似 程度,优化器利用损失值更新权重参数,从而使损失值越来越小。这是一个 循环过程,当损失值达到一个阀值或循环次数到达指定次数,循环结束。
3.2 实现神经网络实例
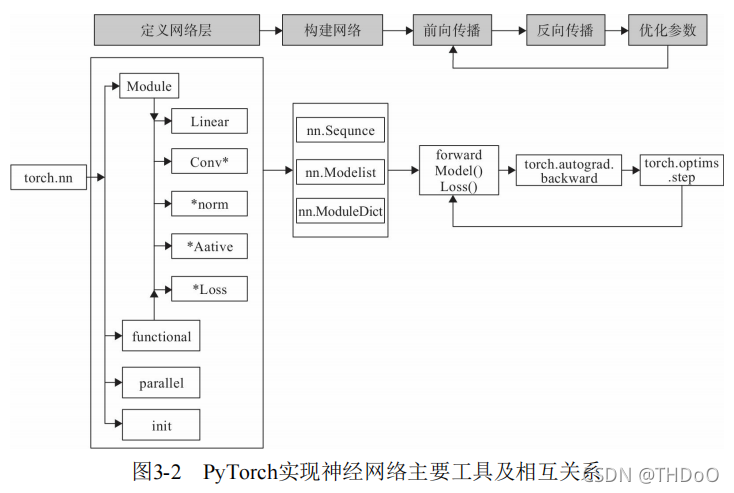
卷积层、全连接层、Dropout层等因含有可学习参数,一般使用nn.Module;
激活函数、池化层不含可学习参数, 可以使用nn.functional中对应的函数。
主要步骤:
(1)利用PyTorch内置函数mnist下载数据。
(2)利用torchvision对数据进行预处理,调用torch.utils建立一个数据迭代器。
(3)可视化源数据。
(4)利用nn工具箱构建神经网络模型。
(5)实例化模型,并定义损失函数及优化器。
(6)训练模型。
(7)可视化结果。
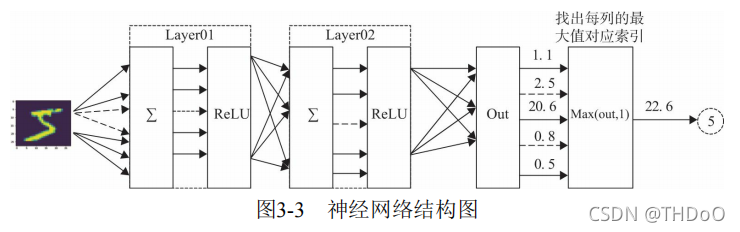
使用两个隐含层,每层激活函数为ReLU,最后使用torch.max(out,1)找 出张量out最大值对应索引作为预测值。
一、准备数据
import numpy as np
import torch # 导入 PyTorch 内置的 mnist 数据
from torchvision.datasets import mnist # 导入预处理模块
import torchvision.transforms as transforms
from torch.utils.data import DataLoader # 导入nn及优化器
import torch.nn.functional as F
import torch.optim as optim
from torch import nn
import matplotlib.pyplot as plt
"""2.定义一些超参数"""
train_batch_size = 64
test_batch_size = 128
learning_rate = 0.01
num_epoches = 20
lr = 0.01
momentum = 0.5
"""3.下载数据并对数据进行预处理"""
# 定义预处理函数,这些预处理依次放在Compose函数中。 transforms.Compose可以把一些转换函数组合在一起;
# Normalize([0.5],[0.5])对张量进行归一化,这里两个0.5分别表示对张 量进行归一化的全局平均值和方差。
# 因图像是灰色的只有一个通道,如果有多个通道,需要有多个数字,如3个通道,应该是Normalize([m1,m2,m3], [n1,n2,n3]);
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize([0.5], [0.5])])
# 下载数据,并对数据进行预处理
# download参数控制是否需要下载,如果./data目录下已有MNIST,可选择False;
train_dataset = mnist.MNIST('./data', train=True, transform=transform, download=True)
test_dataset = mnist.MNIST('./data', train=False, transform=transform)
# dataloader是一个可迭代对象,可以使用迭代器一样使用。用DataLoader得到生成器,这可节省内存;
train_loader = DataLoader(train_dataset, batch_size=train_batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=test_batch_size, shuffle=False)二、可视化源数据
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
fig = plt.figure()
for i in range(6):
plt.subplot(2, 3, i + 1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Ground Truth: {}".format(example_targets[i]))
plt.xticks([])
plt.yticks([])
plt.show()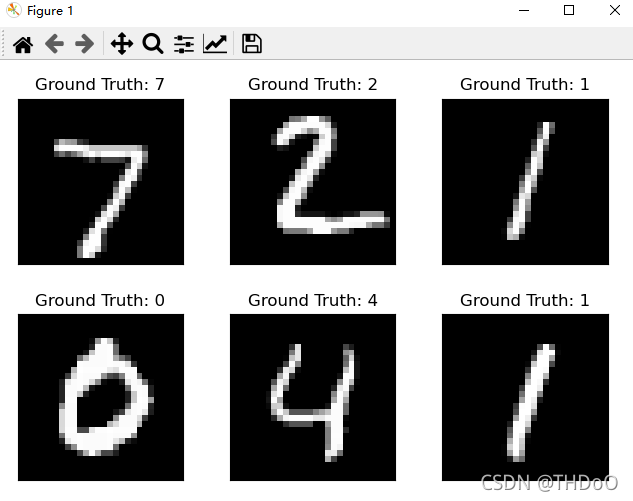
三、构建模型
"""1)构建网络"""
class Net(nn.Module):
""" 使用sequential构建网络,Sequential()函数的功能是将网络的层组合到一起 """
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super(Net, self).__init__()
self.layer1 = nn.Sequential(nn.Linear(in_dim, n_hidden_1), nn.BatchNorm1d(n_hidden_1))
self.layer2 = nn.Sequential(nn.Linear(n_hidden_1, n_hidden_2), nn.BatchNorm1d(n_hidden_2))
self.layer3 = nn.Sequential(nn.Linear(n_hidden_2, out_dim))
def forward(self, x):
x = F.relu(self.layer1(x))
x = F.relu(self.layer2(x))
x = self.layer3(x)
return x
"""2)实例化网络"""
# 检测是否有可用的GPU,有则使用,否则使用CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 实例化网络
model = Net(28 * 28, 300, 100, 10)
model.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=momentum)四、训练模型
"""1.训练模型"""
# 开始训练
losses = []
acces = []
eval_losses = []
eval_acces = []
for epoch in range(num_epoches):
train_loss = 0
train_acc = 0
model.train()
# 动态修改参数学习率
if epoch % 5 == 0:
optimizer.param_groups[0]['lr'] *= 0.1
for img, label in train_loader:
img = img.to(device)
label = label.to(device)
img = img.view(img.size(0), -1)
# 前向传播
out = model(img)
loss = criterion(out, label)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录误差
train_loss += loss.item()
# 计算分类的准确率
_, pred = out.max(1)
num_correct = (pred == label).sum().item()
acc = num_correct / img.shape[0]
train_acc += acc
losses.append(train_loss / len(train_loader))
acces.append(train_acc / len(train_loader))
# 在测试集上检验效果
eval_loss = 0
eval_acc = 0
# 将模型改为预测模式
model.eval()
for img, label in test_loader:
img = img.to(device)
label = label.to(device)
img = img.view(img.size(0), -1)
out = model(img)
loss = criterion(out, label)
# 记录误差
eval_loss += loss.item()
# 记录准确率
_, pred = out.max(1)
num_correct = (pred == label).sum().item()
acc = num_correct / img.shape[0]
eval_acc += acc
eval_losses.append(eval_loss / len(test_loader))
eval_acces.append(eval_acc / len(test_loader))
print('epoch: {}, Train Loss: {:.4f}, Train Acc: {:.4f}, Test Loss: {:.4f}, Test Acc: {:.4f}'
.format(epoch, train_loss / len(train_loader), train_acc / len(train_loader),
eval_loss / len(test_loader), eval_acc / len(test_loader)))
"""2.可视化训练及测试损失值"""
plt.title('trainloss')
plt.plot(np.arange(len(losses)), losses)
plt.legend(['Train Loss'], loc='upper right')运行结果:
epoch: 0, Train Loss: 1.0034, Train Acc: 0.7948, Test Loss: 0.5563, Test Acc: 0.8968
epoch: 1, Train Loss: 0.4838, Train Acc: 0.9003, Test Loss: 0.3600, Test Acc: 0.9222
epoch: 2, Train Loss: 0.3542, Train Acc: 0.9172, Test Loss: 0.2787, Test Acc: 0.9353
epoch: 3, Train Loss: 0.2892, Train Acc: 0.9310, Test Loss: 0.2312, Test Acc: 0.9449
epoch: 4, Train Loss: 0.2473, Train Acc: 0.9393, Test Loss: 0.2038, Test Acc: 0.9502
epoch: 5, Train Loss: 0.2254, Train Acc: 0.9444, Test Loss: 0.2010, Test Acc: 0.9509
epoch: 6, Train Loss: 0.2241, Train Acc: 0.9448, Test Loss: 0.1972, Test Acc: 0.9518
epoch: 7, Train Loss: 0.2204, Train Acc: 0.9461, Test Loss: 0.1955, Test Acc: 0.9524
epoch: 8, Train Loss: 0.2195, Train Acc: 0.9455, Test Loss: 0.1941, Test Acc: 0.9521
epoch: 9, Train Loss: 0.2161, Train Acc: 0.9472, Test Loss: 0.1890, Test Acc: 0.9543
epoch: 10, Train Loss: 0.2131, Train Acc: 0.9481, Test Loss: 0.1929, Test Acc: 0.9515
epoch: 11, Train Loss: 0.2136, Train Acc: 0.9479, Test Loss: 0.1902, Test Acc: 0.9537
epoch: 12, Train Loss: 0.2136, Train Acc: 0.9468, Test Loss: 0.1918, Test Acc: 0.9531
epoch: 13, Train Loss: 0.2132, Train Acc: 0.9472, Test Loss: 0.1913, Test Acc: 0.9532
epoch: 14, Train Loss: 0.2123, Train Acc: 0.9482, Test Loss: 0.1882, Test Acc: 0.9545
epoch: 15, Train Loss: 0.2122, Train Acc: 0.9481, Test Loss: 0.1897, Test Acc: 0.9540
epoch: 16, Train Loss: 0.2132, Train Acc: 0.9475, Test Loss: 0.1918, Test Acc: 0.9527
epoch: 17, Train Loss: 0.2110, Train Acc: 0.9488, Test Loss: 0.1891, Test Acc: 0.9537
epoch: 18, Train Loss: 0.2114, Train Acc: 0.9484, Test Loss: 0.1895, Test Acc: 0.9528
epoch: 19, Train Loss: 0.2123, Train Acc: 0.9483, Test Loss: 0.1905, Test Acc: 0.9537
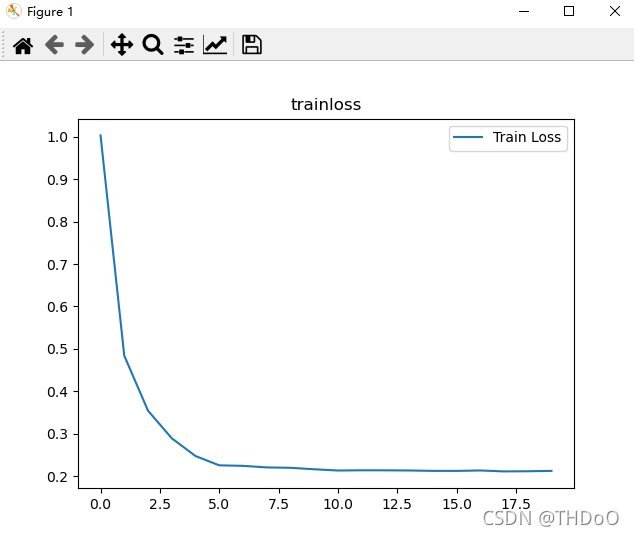
神经网络的结构比较简单,只用了两层,也没有使用Dropout层, 迭代20次,还是有提升空 间。如果采用cnn、Dropout等层,还可以提升模型性能。
3.3 如何构建神经网络
一、构建网络层
"""采用字典方式构建网络"""
class Net(torch.nn.Module):
def __init__(self):
super(Net4, self).__init__()
self.conv = torch.nn.Sequential(
OrderedDict(
[
("conv1", torch.nn.Conv2d(3, 32, 3, 1, 1)), # 对每层定义一个名称
("relu1", torch.nn.ReLU()),
("pool", torch.nn.MaxPool2d(2))
]
)
)
self.dense = torch.nn.Sequential(
OrderedDict(
[
("dense1", torch.nn.Linear(32 * 3 * 3, 128)),
("relu2", torch.nn.ReLU()),
("dense2", torch.nn.Linear(128, 10))
]
)
)二、前向传播
forward函数的任务需要把输入层、网络 层、输出层链接起来,实现信息的前向传导。
三、反向传播
梯度的反向传播:利用复合函数的链式法则,直接让损失函数(loss)调用backward()即可。
四、训练模型
训练模型时需要注意使模型处于训练模式,即调用model.train()。调用 model.train()会把所有的module设置为训练模式。如果是测试或验证阶段, 需要使模型处于验证阶段,即调用model.eval(),调用model.eval()会把所有 的training属性设置为False。
缺省情况下梯度是累加的,需要手工把梯度初始化或清零,调用 optimizer.zero_grad()即可。训练过程中,正向传播生成网络的输出,计算输 出和实际值之间的损失值。调用loss.backward()自动生成梯度,然后使用 optimizer.step()执行优化器,把梯度传播回每个网络。
如果希望用GPU训练,需要把模型、训练数据、测试数据发送到GPU 上,即调用.to(device)。如果需要使用多GPU进行处理,可使模型或相关数 据引用nn.DataParallel。
3.4 神经网络工具箱nn
1. nn.Module
nn.Module是nn的一个核心数据结构,它可以是神经网络的某个层 (Layer),也可以是包含多层的神经网络。在实际使用中,最常见的做法 是继承nn.Module,生成自己的网络/层。如:(class Net(torch.nn.Module))。nn中已实现了绝大多数层, 包括全连接层、损失层、激活层、卷积层、循环层等,这些层都是 nn.Module的子类,能够自动检测到自己的Parameter,并将其作为学习参 数,且针对GPU运行进行了cuDNN优化。
如nn.Linear、nn.Conv2d、nn.CrossEntropyLoss等。
2. nn.functional
nn.functional中的函数,其名称一般为nn.funtional.xxx,
如 nn.funtional.linear、nn.funtional.conv2d、nn.funtional.cross_entropy等。
3. 主要区别
(1)nn.Xxx继承于nn.Module,nn.Xxx需要先实例化并传入参数,然后以 函数调用的方式调用实例化的对象并传入输入数据。它能够很好地与 nn.Sequential结合使用,而nn.functional.xxx无法与nn.Sequential结合使用。
(2)nn.Xxx不需要自己定义和管理weight、bias参数;而nn.functional.xxx 需要自己定义weight、bias参数,每次调用的时候都需要手动传入weight、 bias等参数,不利于代码复用。
(3)Dropout操作在训练和测试阶段是有区别的,使用nn.Xxx方式定义Dropout,在调用model.eval()之后,自动实现状态的转换,而使用 nn.functional.xxx却无此功能。
两种功能都是相同的,但PyTorch官方推荐:具有学习参数 的(例如,conv2d,linear,batch_norm)采用nn.Xxx方式。没有学习参数的(例 如,maxpool、loss func、activation func)等根据个人选择使用 nn.functional.xxx或者nn.Xxx方式。
3.5 优化器
对3.2进行细化讲解,使用优化器的一般步骤:
"""(1)建立优化器实例"""
# 实例化SGD优化器,动量参数momentum(该值一般在(0,1)之间),是SGD的改进版,
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=momentum)
# 以下步骤在训练模型的for循环中
"""(2)向前传播"""
# 把输入数据传入神经网络Net实例化对象model中,自动执行forward函数,得到out输出值,
# 然后用out与标记label计算损失值loss。
out = model(img)
loss = criterion(out, label)
"""(3)清空梯度"""
# 缺省情况梯度是累加的,在梯度反向传播前,先需把梯度清零
optimizer.zero_grad()
"""(4)反向传播"""
# 基于损失值,把梯度进行反向传播。
loss.backward()
"""(5)更新参数"""
# 基于当前梯度(存储在参数的.grad属性中)更新参数。
optimizer.step()3.6 动态修改学习率参数
修改参数的方式可以通过修改参数optimizer.params_groups或新建optimizer。新建optimizer比较简单,optimizer十分轻量级,所以开销很小。 但是新的优化器会初始化动量等状态信息,这对于使用动量的优化器 (momentum参数的sgd)可能会造成收敛中的震荡。
3.7 优化器比较
import torch
import torch.utils.data as Data
import torch.nn.functional as F
import matplotlib.pyplot as plt
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
# 超参数
LR = 0.01
BATCH_SIZE = 32
EPOCH = 12
"""(2)生成数据"""
# 生成训练数据
# torch.unsqueeze() 的作用是将一维变二维,torch只能处理二维的数据
x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
# 0.1 * torch.normal(x.size())增加噪点
y = x.pow(2) + 0.1 * torch.normal(torch.zeros(*x.size()))
torch_dataset = Data.TensorDataset(x, y)
# 得到一个代批量的生成器
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True)
"""(3)构建神经网络"""
class Net(torch.nn.Module):
# 初始化
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1, 20)
self.predict = torch.nn.Linear(20, 1)
# 前向传递
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
"""(4)使用多种优化器"""
net_SGD = Net()
net_Momentum = Net()
net_RMSProp = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_RMSProp, net_Adam]
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.9)
opt_RMSProp = torch.optim.RMSprop(net_RMSProp.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSProp, opt_Adam]
"""(5)训练模型"""
loss_func = torch.nn.MSELoss()
loss_his = [[], [], [], []] # 记录损失
for epoch in range(EPOCH):
for step, (batch_x, batch_y) in enumerate(loader):
for net, opt, l_his in zip(nets, optimizers, loss_his):
output = net(batch_x) # get output for every net
loss = loss_func(output, batch_y) # compute loss for every net
opt.zero_grad() # clear gradients for next train
loss.backward() # backpropagation, compute gradients
opt.step() # apply gradients
l_his.append(loss.data.numpy()) # loss recoder
labels = ['SGD', 'Momentum', 'RMSprop', 'Adam']
"""(6)可视化结果"""
for i, l_his in enumerate(loss_his):
plt.plot(l_his, label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0, 0.2))
plt.show()
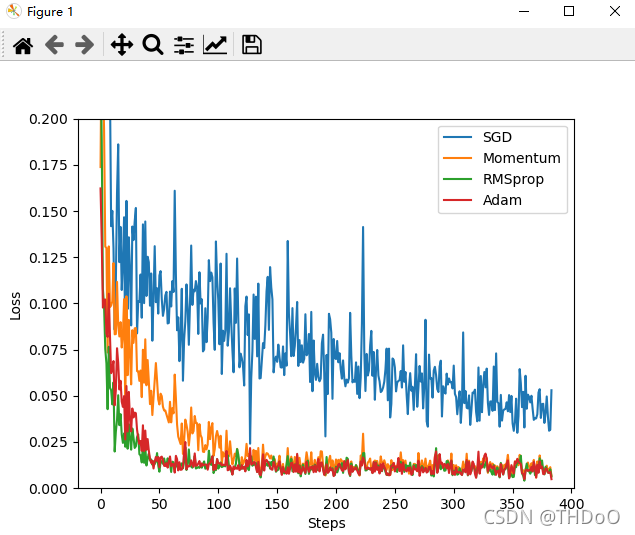
4、PyTorch数据处理工具箱
4.1 数据处理工具箱概述
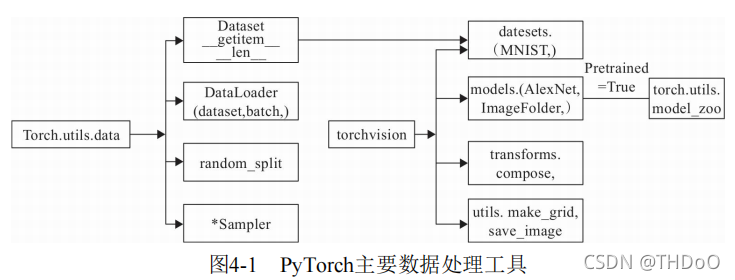
torch.utils.data工具包:
(1)Dataset:是一个抽象类,其他数据集需要继承这个类,并且覆写其 中的两个方法(_getitem__、__len__)。
(2)DataLoader:定义一个新的迭代器,实现批量(batch)读取,打乱数据(shuffle)并提供并行加速等功能。
(3)random_split:把数据集随机拆分为给定长度的非重叠的新数据集。
(4)*sampler:多种采样函数。
(1 ) datasets:提供常用的数据集加载,设计上都是继承自 torch.utils.data.Dataset ,主要包括 MMIST 、 CIFAR10/100 、ImageNet和COCO等。
(2 ) models:提供深度学习中各种经典的网络结构以及训练好的模型(p retrained=True ),包括 AlexNet 、 VGG 系列、 ResNet系列、Inception系列等。
(3 ) transforms :常用的数据预处理操作,主要包括对 Tensor及PIL Image对象的操作。
(4 ) utils :含两个函数,一个是 make_grid,它能将多张图片拼接在一个 网格中;另一个是 save_img ,它能将Tensor保存成图片。
4.2 utils.data简介
Dataset:只负责数据的抽取,调用一次__getitem__只返回一个样本。
import torch
from torch.utils import data
import numpy as np
class TestDataset(data.Dataset): # 继承Dataset
"""2)定义获取数据集的类:该类继承基类Dataset,自定义一个数据集及对应标签。"""
def __init__(self):
self.Data = np.asarray([[1, 2], [3, 4], [2, 1], [3, 4], [4, 5]]) # 一些由2维向量表示的数据集
self.Label = np.asarray([0, 1, 0, 1, 2]) # 这是数据集对应的标签
def __getitem__(self, index):
# 把numpy转换为Tensor
txt = torch.from_numpy(self.Data[index])
label = torch.tensor(self.Label[index])
return txt, label
def __len__(self):
return len(self.Data)
"""3)获取数据集中数据"""
Test = TestDataset()
# 相当于调用__getitem__(2)
print(Test[2]) # (tensor([2, 1], dtype=torch.int32), tensor(0, dtype=torch.int32))
print(Test.__len__()) # 5
DataLoader:批量读取
格式:
data.DataLoader(
dataset, # 加载的数据集。
batch_size=1, # 批大小。
shuffle=False, # 是否将数据打乱。
sampler=None, # 样本抽样。
batch_sampler=None,
num_workers=0, # 使用多进程加载的进程数,0代表不使用多进程。
collate_fn=<function default_collate at 0x7f108ee01620>, # 如何将多个样本数据拼接成一个batch,一般使用默认的拼接方式即可。
pin_memory=False, # 是否将数据保存在pin memory区,pin memory中的数据转到GPU会快一些。
drop_last=False, # dataset中的数据个数可能不是batch_size的整数倍,drop_last为True会将多出来不足一个batch的数据丢弃。
timeout=0,
worker_init_fn=None,
)
if __name__ == '__main__':
test_loader = data.DataLoader(Test, batch_size=2, shuffle=False, num_workers=2)
for i, traindata in enumerate(test_loader):
print('i:', i)
Data, Label = traindata
print('data:', Data)
print('Label:', Label)运行结果:
i: 0
data: tensor([[1, 2],
[3, 4]], dtype=torch.int32)
Label: tensor([0, 1], dtype=torch.int32)
i: 1
data: tensor([[2, 1],
[3, 4]], dtype=torch.int32)
Label: tensor([0, 1], dtype=torch.int32)
i: 2
data: tensor([[4, 5]], dtype=torch.int32)
Label: tensor([2], dtype=torch.int32)
4.3 torchvision简介
(1)PIL Image对象:
Scale/Resize:调整尺寸,长宽比保持不变。
CenterCrop、RandomCrop、RandomSizedCrop:裁剪图片,CenterCrop 和RandomCrop在crop时是固定size,RandomResizedCrop则是random size的 crop。
Pad:填充。
ToTensor:把一个取值范围是[0,255]的PIL.Image转换成Tensor。形状为(H,W,C)的Numpy.ndarray转换成形状为[C,H,W],取值范围是[0,1.0]的 torch.FloatTensor。
RandomHorizontalFlip:图像随机水平翻转,翻转概率为0.5。
RandomVerticalFlip:图像随机垂直翻转。
ColorJitter:修改亮度、对比度和饱和度
(2)Tensor对象:
Normalize:标准化,即,减均值,除以标准差。
ToPILImage:将Tensor转为PIL Image。
"""对数据集进行多个操作,通过Compose将这些操作拼接起来"""
transforms.Compose([
# 将给定的 PIL.Image 进行中心切割,得到给定的 size,
# size 可以是 tuple,(target_height, target_width)。
# size 也可以是一个 Integer,在这种情况下,切出来的图片形状是正方形。
transforms.CenterCrop(10),
# 切割中心点的位置随机选取
transforms.RandomCrop(20, padding=0),
# 把一个取值范围是 [0, 255] 的 PIL.Image 或者 shape 为 (H, W, C) 的 numpy.ndarray,
# 转换为形状为 (C, H, W),取值范围是 [0, 1] 的 torch.FloatTensor
transforms.ToTensor(),
# 规范化到[-1,1]
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
])2、ImageFolder

from torch.utils import data
from torchvision import transforms, utils
from torchvision import datasets
import torch
import matplotlib.pyplot as plt
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
"""利用torchvision.datasets.ImageFolder来直接构造dataset"""
my_trans = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor()
])
train_data = datasets.ImageFolder('../data', transform=my_trans)
train_loader = data.DataLoader(train_data, batch_size=8, shuffle=True, )
for i_batch, img in enumerate(train_loader):
if i_batch == 0:
print(img[1])
fig = plt.figure()
grid = utils.make_grid(img[0])
plt.imshow(grid.numpy().transpose((1, 2, 0)))
plt.show()
utils.save_image(grid, 'test01.png')
break

from PIL import Image
Image.open('test01.png') # 查看图片4.4 可视化工具Tensorboard
import numpy as np
from tensorboardX import SummaryWriter
writer = SummaryWriter()
for epoch in range(100):
writer. add_scalar('scalar/test', np. random.rand(), epoch)
writer. add_scalars('scalar/scalars_test', {'xsinx': epoch * np.sin(epoch), 'xcosx' : epoch * np.cos(epoch)}, epoch)
writer.close()命令行操作:
1.cd到runs上一级目录——cd part4;
2.tensorboard --logdir runs。(当SummaryWriter(log_dir='scalar')的log_dir的参数值 存在时,tensorboard --logdir runs 改为 tensorboard --logdir 参数值)
可视化神经网络
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from tensorboardX import SummaryWriter
class Net(nn.Module):
"""(2)构建神经网络"""
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
self.bn = nn.BatchNorm2d(20)
def forward(self, x):
x = F.max_pool2d(self.conv1(x), 2)
x = F.relu(x) + F.relu(-x)
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = self.bn(x)
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
x = F.softmax(x, dim=1)
return x
"""(3)把模型保存为graph"""
# 定义输入
input = torch.rand(32, 1, 28, 28)
# 实例化神经网络
model = Net()
# 将model保存为graph
with SummaryWriter(log_dir='logs', comment='Net') as w:
w.add_graph(model, (input,))tensorboard --logdir=logs
可视化损失值
import torch
import torch.nn as nn
from tensorboardX import SummaryWriter
import numpy as np
input_size = 1
output_size = 1
num_epoches = 60
learning_rate = 0.001
dtype = torch.FloatTensor
writer = SummaryWriter(log_dir='logs', comment='Linear')
np.random.seed(100)
x_train = np.linspace(-1, 1, 100).reshape(100, 1)
y_train = 3 * np.power(x_train, 2) + 2 + 0.2 * np.random.rand(x_train.size).reshape(100, 1)
model = nn.Linear(input_size, output_size)
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
for epoch in range(num_epoches):
inputs = torch.from_numpy(x_train).type(dtype)
targets = torch.from_numpy(y_train).type(dtype)
output = model(inputs)
loss = criterion(output, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 保存loss的数据与epoch数值
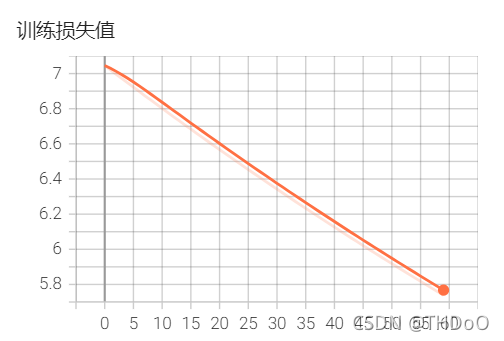
writer.add_scalar('训练损失值', loss, epoch)
可视化特征图
import torch
import torchvision
import torchvision.transforms as transforms
from tensorboardX import SummaryWriter
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision.utils as vutils
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# cifair10数据集
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=False, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
class CNNNet(nn.Module):
def __init__(self):
super(CNNNet, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=5, stride=1)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(in_channels=16, out_channels=36, kernel_size=3, stride=1)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(1296, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
# print(x.shape)
x = x.view(-1, 36 * 6 * 6)
x = F.relu(self.fc2(F.relu(self.fc1(x))))
return x
if __name__ == '__main__':
net = CNNNet()
net = net.to(device)
LR = 0.001
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9)
# 初始化数据
for m in net.modules():
if isinstance(m, nn.Conv2d):
nn.init.normal_(m.weight)
nn.init.xavier_normal_(m.weight)
nn.init.kaiming_normal_(m.weight) # 卷积层参数初始化
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight) # 全连接层参数初始化
# 训练模型
for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# 获取训练数据
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
# 权重参数梯度清零
optimizer.zero_grad()
# 正向及反向传播
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 显示损失值
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
writer = SummaryWriter(log_dir='logs', comment='feature map')
for i, data in enumerate(trainloader, 0):
# 获取训练数据
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
x = inputs[0].unsqueeze(0)
break
img_grid = vutils.make_grid(x, normalize=True, scale_each=True, nrow=2)
net.eval()
for name, layer in net._modules.items():
# 为fc层预处理x
x = x.view(x.size(0), -1) if "fc" in name else x
print(x.size())
x = layer(x)
print(f'{name}')
# 查看卷积层的特征图
if 'layer' in name or 'conv' in name:
x1 = x.transpose(0, 1) # C,B, H, W ---> B,C, H, W
# normalize进行归一化处理
img_grid = vutils.make_grid(x1, normalize=True, scale_each=True, nrow=4)
writer.add_image(f'{name}_feature_maps', img_grid, global_step=0)
[1, 2000] loss: 3.510
[1, 4000] loss: 2.303
[1, 6000] loss: 2.303
[1, 8000] loss: 2.303
[1, 10000] loss: 2.303
[1, 12000] loss: 2.303
[2, 2000] loss: 2.303
[2, 4000] loss: 2.303
[2, 6000] loss: 2.303
[2, 8000] loss: 2.303
[2, 10000] loss: 2.303
[2, 12000] loss: 2.303
Finished Training
torch.Size([1, 3, 32, 32])
conv1
torch.Size([1, 16, 28, 28])
pool1
torch.Size([1, 16, 14, 14])
conv2
torch.Size([1, 36, 12, 12])
pool2
torch.Size([1, 1296])
fc1
torch.Size([1, 128])
fc2




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









