



selenium爬取淘宝商品基础数据以及商品详情
网页分析
确定要爬取的数据
要爬取的数据如下:
商品基础数据中包括了价格,商品标题,店铺名称,店铺地址

商品详情中的所有数据
商品人气值

商品月销量

商品评价量

分析网页构成
这部分比较基础,就不再赘述,这里主要说一下因为淘宝商品搜索结果中包含淘宝的店铺和天猫的店铺

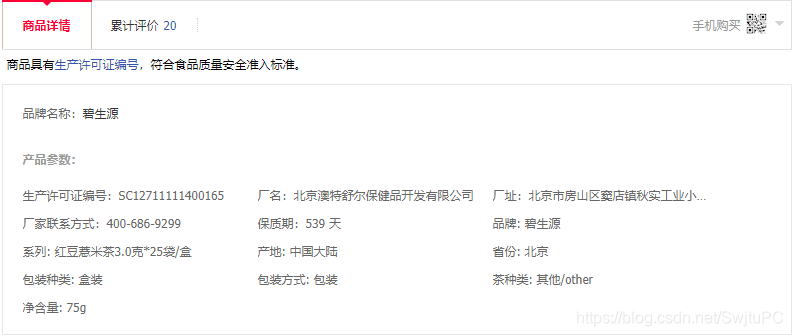
淘宝店铺中的商品详情为:

天猫的店铺详情如下:
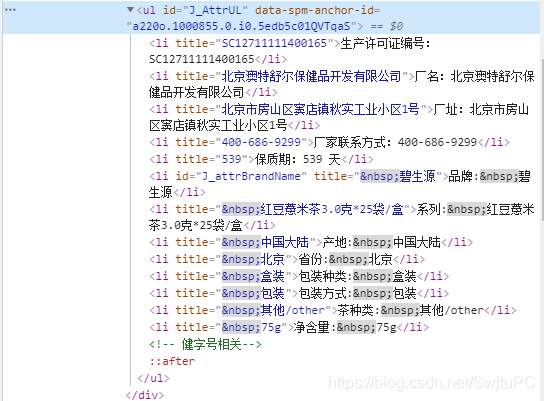
因此定位淘宝商品详情的XPTH为:if WebDriverWait(self.browser, 3, 0.2).until( lambda x: x.find_element_by_xpath('//*[@id="attributes"]/ul')):
定位天猫商品详情的XPTH为:if WebDriverWait(self.browser, 3, 0.2).until( lambda x: x.find_element_by_xpath('//*[@id="J_AttrList"]')):good_info = self.browser.find_element_by_xpath('//*[@id="J_AttrList"]').text
在爬取商品详情时加入判断当前商品是为天猫还是淘宝(如果不这样做使用try来进行的话程序跑的会很慢)
currentPageUrl = self.browser.current_url#获得当前页面url判断是天猫还是淘宝
tianmao="detail.tmall.com"
taobao="item.taobao.com"
爬取流程
登入
因为使用淘宝账号登入(淘宝登入界面)时需要使用验证码,所以这里采用曲线救国的方法:采用微博登入选项
首先你需要自己将微博账号与淘宝账号绑定(不会的自行百度)
登入代码块如下:
def login(self):
# 打开网页
self.browser.get(self.url)
self.browser.maximize_window()
# 自适应等待,点击密码登录选项
# self.browser.implicitly_wait(30) #智能等待,直到网页加载完毕,最长等待时间为30s
#self.browser.find_element_by_xpath('//*[@class="forget-pwd J_Quick2Static"]').click()
# 自适应等待,点击微博登录宣传
self.browser.implicitly_wait(30)
self.browser.find_element_by_xpath('//*[@class="weibo-login"]').click()
# 自适应等待,输入微博账号
self.browser.implicitly_wait(30)
self.browser.find_element_by_name('username').send_keys(weibo_username)
# 自适应等待,输入微博密码
self.browser.implicitly_wait(30)
self.browser.find_element_by_name('password').send_keys(weibo_password)
# 自适应等待,点击确认登录按钮
self.browser.implicitly_wait(30)
self.browser.find_element_by_xpath('//*[@class="btn_tip"]/a/span').click()
# 直到获取到淘宝会员昵称才能确定是登录成功
taobao_name = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.site-nav-bd > ul.site-nav-bd-l > li#J_SiteNavLogin > div.site-nav-menu-hd > div.site-nav-user > a.site-nav-login-info-nick ')))
# 输出淘宝昵称
print(taobao_name.text)
这里的weibo_username与weibo_password填自己的微博账号和密码
至此完成了淘宝登入,接下来进行数据的爬取
爬取基础数据以及商品详情
爬取基础数据
while flag_stop:
goods_numer=goods_numer+1
time.sleep(2)#尊重淘宝休息一下
goods = self.browser.find_elements_by_xpath('//div[contains(@class,"J_MouserOnverReq")]')
#规定爬取商品数量
for good in goods:
if i==400:
flag_stop=0#跳出
break
i=i+1
flag_pingzhong = 0
#...
#商品各属性
price = good.find_element_by_xpath('.//div[2]/div[1]/div/strong').text
title = good.find_element_by_xpath('.//div[2]/div[2]/a').text
shop_name = good.find_element_by_xpath('.//div[2]/div[3]/div[1]/a/span[2]').text
origin = good.find_element_by_xpath('.//div[2]/div[3]/div[2]').text
print("i=",i)
print(price, title, shop_name, origin)
good.click()#点击商品跳转到商品详情
爬取商品详情
self.browser.switch_to.window(self.browser.window_handles[-1])#切换到商品详情界面
currentPageUrl = self.browser.current_url#获得当前页面url判断是天猫还是淘宝
tianmao="detail.tmall.com"
taobao="item.taobao.com"
if tianmao in currentPageUrl:
print("天猫")
time.sleep(0.2)
js = "window.scrollTo(0,1000)"#下滑页面
self.browser.execute_script(js)
################################################获得商品详情
try:
if WebDriverWait(self.browser, 3, 0.2).until(
lambda x: x.find_element_by_xpath('//*[@id="J_AttrList"]')):
good_info = self.browser.find_element_by_xpath('//*[@id="J_AttrList"]').text
#################################判断原产地是否包含省份
if kw_judge not in good_info:
print("不符合规则")
i = i - 1
self.browser.close()#关闭当前窗口
self.browser.switch_to.window(main_driver)#切换至主界面
continue # 忽略这次
print(good_info)
###############################################获得商品月销
try:
# if self.browser.find_element_by_xpath('//span[@class="tm-count"]'):
# Monthlysales = self.browser.find_element_by_xpath('//span[@class="tm-count"]')
if WebDriverWait(self.browser, 3, 0.2).until(
lambda x: x.find_element_by_xpath('//span[@class="tm-count"]')):
Monthlysales = self.browser.find_element_by_xpath('//span[@class="tm-count"]')
Monthlysales_number = Monthlysales.text
print("月销量" + Monthlysales_number)
except:
print("无月销")
######################################################获得商品评价
try:
if WebDriverWait(self.browser, 3, 0.2).until( lambda x: x.find_element_by_xpath('//*[@id="J_ItemRates"]/div/span[2]')):
evaluate = self.browser.find_element_by_xpath(' //*[@id="J_ItemRates"]/div/span[2]')
evaluate_number = evaluate.text
print("评价量" + evaluate_number)
except Exception as e:
print("无评价")
print('get button failed: ', e)
print("trydiv")
#######################################################获得商品人气
try:
if WebDriverWait(self.browser, 3, 0.2).until( lambda x: x.find_element_by_xpath('// *[ @ id = "J_CollectCount"]')):
hotofgood = self.browser.find_element_by_xpath('// *[ @ id = "J_CollectCount"]').text
hotofgood_number=re.findall(r"\d+\.?\d*",hotofgood)[0]
print("商品人气"+hotofgood_number)
except Exception as e:
print('get button failed: ', e)
sleep(3)#睡眠3s,保证电脑性能能够加载出页面,我之前调成1s会导致页面加载不出来信息获取失败
self.browser.close()
self.browser.switch_to.window(main_driver)
睡眠3s,保证电脑性能能够加载出页面,我之前调成1s会导致页面加载不出来信息获取失败
对自己电脑有自信的可以调的更低
因为我做的项目中是爬取茶叶,因为淘宝的搜索结果中包含推荐,比如我搜索四川的茶叶,搜索结果中也会推其他地方的茶叶,所以加入了在商品详情中判断省份。若你做的是其他项目具体情况具体分析
下一页跳转:
next_page = WebDriverWait(self.browser, 3, 0.2).until(
lambda x: x.find_element_by_xpath('//span[contains(text(),"下一页")]/..'))
这里说一下几个比较关键的函数(若你对其他函数有疑问搜索selenium的用法):
1
find_element_by_xpath('.//div[2]/div[1]/div/strong').text
这个是获得XPTH为.//div[2]/div[1]/div/strong属性下的文本信息
XPTH可以通过右键控制台中你想要获得的地方之后选Copy->Copy Xpath
2
browser.switch_to.window(self.browser.window_handles[-1])
切换到新打开的窗口(新打开的窗口默认值为-1)
3
self.browser.close()#关闭当前窗口
self.browser.switch_to.window(main_driver)#切换至主界面
4
main_driver为主界面的url
WebDriverWait(self.browser, 3, 0.2).until(
lambda x: x.find_element_by_xpath('//*[@id="J_AttrList"]')):
这个为寻找Xpth为//*[@id="J_AttrList"]的标签,限时为3s,每0.2s进行一次搜索
5
hotofgood_number=re.findall(r"\d+\.?\d*",hotofgood)[0]
正则表达式,寻找hotofgood中所有数字以数组的形式返回,这里取第一个数字即[0]
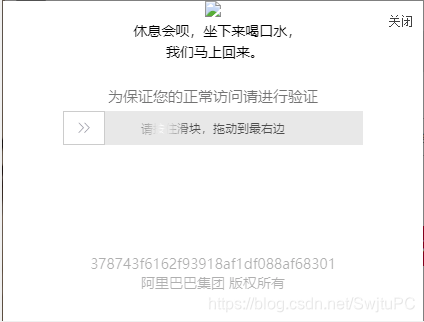
淘宝滑动验证码
在爬取中,因为淘宝会识别到是否使用selenium便会给你发滑动验证码,这个时候由于验证码的出现鼠标便无法点击主页面(比如你要爬取商品的具体评论,要首先点击商品评论的按钮,这时就要解决这个验证码的问题)。由于我没有爬取需要二次点击的需求便没有处理这个,因为在验证码加载出来时,页面内容已经加载完毕了。
保存EXCEL中
这里采用Xlwt具体函数搜索Xlwt用法
首先创建EXCEL表后将EXCEL表的表头填入:
book = xlwt.Workbook(encoding='utf-8')
sheet = book.add_sheet('Sheet1')
proj = ['商品名', '单价/元', '店铺名称', '店铺位置', '商品月销', '商品评论数','商品人气', '商品详情']
for i in range(0, len(proj)):
sheet.write(0, i, proj[i]) # 按行插入行标题
book.save('Goodsinformation.xls')
-
创建工作表对象,并设置编码格式为utf-8
-
添加一个sheet表,参数为sheet的表名
-
sheet.write()是写入内容的方法
参数一:表示行数
参数二:表示列数
参数三:表示要写入的内容
-
保存Excel表,注意表名后面要加.xls后缀
在程序中进行数据插入时,由于以循环的方式插入若用上面的方法进行数据插入会导致只保存最后插入的数据。所以这里要用打开EXCEL表的形式进行数据插入
book = xlrd.open_workbook('E:\Teadatapretreatment\Goodsinformation.xls')
book2=copy(book)
sheet = book2.get_sheet(0)
写入操作与上面相同
sheet.write(i, j, text)
最后是保存操作,这个原理是创建一个副表进行最新数据的更新后删除旧表使用副表作为新表。
os.remove('Goodsinformation.xls')
book2_pingzhong.save('Goodsinformation.xls')
完整代码
因为后续团队需求在其中加入了判断是否为品种茶
代码还不够简洁,但是基础功能都完成了
# -*- coding: utf-8 -*-
import os
import random
import re
import time
import urllib.parse
from logging import exception
import xlrd
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
# option=webdriver.ChromeOptions()
# option.add_argument("headless")
# driver = webdriver.Chrome(options=option)
from selenium.webdriver import ActionChains
from selenium.webdriver.support.wait import WebDriverWait
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from pyquery import PyQuery as pq
from time import sleep
import random
import pyautogui
from splinter.exceptions import ElementDoesNotExist
from selenium.common import exceptions as ex
import xlwt
from xlutils.copy import copy
def dispose_slider():
time.sleep(0.2)
pyautogui.moveTo(x=1080, y=503, duration=0.25)
pyautogui.dragTo(x=1080, y=560, duration=0.5)
time.sleep(0.2)
pyautogui.moveTo(x=660, y=677, duration=0.25)
pyautogui.dragTo(x=1300, y=677, duration=0.8)
# 休息0.25秒,表示对淘宝的尊敬
time.sleep(0.25)
#定义一个taobao类
class taobao_infos:
# 滑块验证处理
#对象初始化
def __init__(self):
url = 'https://login.taobao.com/member/login.jhtml'
self.url = url
options = webdriver.ChromeOptions()
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2}) # 不加载图片,加快访问速度
options.add_experimental_option('excludeSwitches', ['enable-automation']) # 此步骤很重要,设置为开发者模式,防止被各大网站识别出来使用了Selenium
self.browser = webdriver.Chrome(executable_path=chromedriver_path, options=options)
self.wait = WebDriverWait(self.browser, 10) #超时时长为10s
#登录淘宝
def login(self):
# 打开网页
self.browser.get(self.url)
self.browser.maximize_window()
# 自适应等待,点击密码登录选项
# self.browser.implicitly_wait(30) #智能等待,直到网页加载完毕,最长等待时间为30s
#self.browser.find_element_by_xpath('//*[@class="forget-pwd J_Quick2Static"]').click()
# 自适应等待,点击微博登录宣传
self.browser.implicitly_wait(30)
self.browser.find_element_by_xpath('//*[@class="weibo-login"]').click()
# 自适应等待,输入微博账号
self.browser.implicitly_wait(30)
self.browser.find_element_by_name('username').send_keys(weibo_username)
# 自适应等待,输入微博密码
self.browser.implicitly_wait(30)
self.browser.find_element_by_name('password').send_keys(weibo_password)
# 自适应等待,点击确认登录按钮
self.browser.implicitly_wait(30)
self.browser.find_element_by_xpath('//*[@class="btn_tip"]/a/span').click()
# 直到获取到淘宝会员昵称才能确定是登录成功
taobao_name = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.site-nav-bd > ul.site-nav-bd-l > li#J_SiteNavLogin > div.site-nav-menu-hd > div.site-nav-user > a.site-nav-login-info-nick ')))
# 输出淘宝昵称
print(taobao_name.text)
def crawl_good_buy_data(self):
kw = "四川 茶叶"
kw_judge="四川"
kw_pingzhong1="竹叶青"
kw_pingzhong2 = "蒙顶山茶"
kw_pingzhong3 = "峨眉毛峰"
kw_pingzhong4 = "苦丁茶"
kw_pingzhong5 = "川红工夫"
kw_pingzhong6 = "巴山雀舌"
url = "https://s.taobao.com/search?q={kw}".format(kw=urllib.parse.quote(kw))
self.browser.get(url)
js = "window.scrollTo(0,document.body.scrollHeight)"
self.browser.execute_script(js)
main_driver = self.browser.current_window_handle
flag_stop=1
#while True:
goods_numer = -1 # 商品数目
i = 0
j=0
#flag_stop用来跳出循环
while flag_stop:
goods_numer=goods_numer+1
time.sleep(2)
goods = self.browser.find_elements_by_xpath('//div[contains(@class,"J_MouserOnverReq")]')
#规定爬取商品数量
for good in goods:
if i==400:
flag_stop=0#跳出
break
i=i+1
flag_pingzhong = 0
###################################普通茶
book = xlrd.open_workbook('E:\Teadatapretreatment\Goodsinformation.xls')
book2=copy(book)
sheet = book2.get_sheet(0)
##################################品种茶
book_pingzhong = xlrd.open_workbook('E:\Teadatapretreatment\品种茶.xls')
book2_pingzhong = copy(book_pingzhong)
sheet_pingzhong = book2_pingzhong.get_sheet(0)
##########################################二次保证返回到了主界面
# self.browser.switch_to.window(main_driver)
#商品各属性
price = good.find_element_by_xpath('.//div[2]/div[1]/div/strong').text
title = good.find_element_by_xpath('.//div[2]/div[2]/a').text
shop_name = good.find_element_by_xpath('.//div[2]/div[3]/div[1]/a/span[2]').text
origin = good.find_element_by_xpath('.//div[2]/div[3]/div[2]').text
print("i=",i)
print(price, title, shop_name, origin)
sheet.write(i, 0, title)
sheet.write(i, 1, price)
sheet.write(i, 2, shop_name)
sheet.write(i, 3, origin)
good.click()#点击商品跳转到商品详情
self.browser.switch_to.window(self.browser.window_handles[-1])#切换到商品详情界面
currentPageUrl = self.browser.current_url#获得当前页面url判断是天猫还是淘宝
tianmao="detail.tmall.com"
taobao="item.taobao.com"
if tianmao in currentPageUrl:
print("天猫")
time.sleep(0.2)
js = "window.scrollTo(0,1000)"
self.browser.execute_script(js)
################################################获得商品详情
try:
# if self.browser.find_element_by_xpath('//div[@class="attributes-list"]').text:
# good_info = self.browser.find_element_by_xpath('//div[@class="attributes-list"]').text
if WebDriverWait(self.browser, 3, 0.2).until(
lambda x: x.find_element_by_xpath('//*[@id="J_AttrList"]')):
good_info = self.browser.find_element_by_xpath('//*[@id="J_AttrList"]').text
#################################判断原产地是否包含省份
if kw_judge not in good_info:
print("不符合规则")
i = i - 1
self.browser.close()
self.browser.switch_to.window(main_driver)
continue # 忽略这次
print(good_info)
sheet.write(i, 7, good_info)
###################################判断是否为品种茶
if kw_pingzhong1 in good_info or kw_pingzhong2 in good_info or kw_pingzhong3 in good_info or kw_pingzhong4 in good_info or kw_pingzhong5 in good_info or kw_pingzhong6 in good_info:
flag_pingzhong=1
j=j+1
print("为品种茶")
else:
print("非品种茶")
except Exception as e:
print("无商品详情")
sheet.write(i, 7, "none")
print('get button failed: ', e)
###############################################获得商品月销
try:
# if self.browser.find_element_by_xpath('//span[@class="tm-count"]'):
# Monthlysales = self.browser.find_element_by_xpath('//span[@class="tm-count"]')
if WebDriverWait(self.browser, 3, 0.2).until(
lambda x: x.find_element_by_xpath('//span[@class="tm-count"]')):
Monthlysales = self.browser.find_element_by_xpath('//span[@class="tm-count"]')
Monthlysales_number = Monthlysales.text
print("月销量" + Monthlysales_number)
sheet.write(i, 4, Monthlysales_number)
except:
print("无月销")
sheet.write(i, 4, "0")
######################################################获得商品评价
try:
if WebDriverWait(self.browser, 3, 0.2).until( lambda x: x.find_element_by_xpath('//*[@id="J_ItemRates"]/div/span[2]')):
evaluate = self.browser.find_element_by_xpath(' //*[@id="J_ItemRates"]/div/span[2]')
evaluate_number = evaluate.text
print("评价量" + evaluate_number)
sheet.write(i, 5, evaluate_number)
except Exception as e:
print("无评价")
sheet.write(i, 5, "0")
print('get button failed: ', e)
print("trydiv")
#######################################################获得商品人气
try:
if WebDriverWait(self.browser, 3, 0.2).until( lambda x: x.find_element_by_xpath('// *[ @ id = "J_CollectCount"]')):
hotofgood = self.browser.find_element_by_xpath('// *[ @ id = "J_CollectCount"]').text
hotofgood_number=re.findall(r"\d+\.?\d*",hotofgood)[0]
print("商品人气"+hotofgood_number)
sheet.write(i, 6, hotofgood_number)
except Exception as e:
sheet.write(i, 6, "0")
print('get button failed: ', e)
os.remove('Goodsinformation.xls')
book2.save('Goodsinformation.xls')
sleep(3)
self.browser.close()
self.browser.switch_to.window(main_driver)
if taobao in currentPageUrl:
print("淘宝")
time.sleep(0.2)
js = "window.scrollTo(0,1000)"
self.browser.execute_script(js)
################################################获得商品详情
try:
# if self.browser.find_element_by_xpath('//div[@class="attributes-list"]').text:
# good_info = self.browser.find_element_by_xpath('//div[@class="attributes-list"]').text
if WebDriverWait(self.browser, 3, 0.2).until(
lambda x: x.find_element_by_xpath('//*[@id="attributes"]/ul')):
good_info = self.browser.find_element_by_xpath('//*[@id="attributes"]/ul').text
if kw_judge not in good_info:
print("不符合规则")
i = i - 1
self.browser.close()
self.browser.switch_to.window(main_driver)
continue # 忽略这次
if kw_pingzhong1 in good_info or kw_pingzhong2 in good_info or kw_pingzhong3 in good_info or kw_pingzhong4 in good_info or kw_pingzhong5 in good_info or kw_pingzhong6 in good_info:
flag_pingzhong=1
j=j+1
print("为品种茶")
else:
print("非品种茶")
print(good_info)
sheet.write(i, 7, good_info)
except Exception as e:
print("无商品详情")
sheet.write(i, 7, "none")
print('get button failed: ', e)
######################################################获得商品月销
try:
# if self.browser.find_element_by_xpath('//span[@class="tm-count"]'):
# Monthlysales = self.browser.find_element_by_xpath('//span[@class="tm-count"]')
if WebDriverWait(self.browser, 3, 0.2).until(
lambda x: x.find_element_by_xpath('//*[@id="J_SellCounter"]')):
Monthlysales = self.browser.find_element_by_xpath('//*[@id="J_SellCounter"]')
Monthlysales_number = Monthlysales.text
print("月销量" + Monthlysales_number)
sheet.write(i, 4, Monthlysales_number)
except:
print("无月销")
sheet.write(i, 4, "0")
######################################################获得商品评价
try:
if WebDriverWait(self.browser, 3, 0.2).until(
lambda x: x.find_element_by_xpath('// *[ @ id = "J_RateCounter"]')):
evaluate = self.browser.find_element_by_xpath(' // *[ @ id = "J_RateCounter"]')
evaluate_number = evaluate.text
print("评价量" + evaluate_number)
sheet.write(i, 5, evaluate_number)
except Exception as e:
print("无评价")
sheet.write(i, 5, "0")
print('get button failed: ', e)
print("trydiv")
#######################################################获得商品人气
try:
if WebDriverWait(self.browser, 3, 0.2).until( lambda x: x.find_element_by_xpath('//*[@id="J_Social"]/ul/li/a/em')):
hotofgood = self.browser.find_element_by_xpath('//*[@id="J_Social"]/ul/li/a/em').text
hotofgood_number=re.findall(r"\d+\.?\d*",hotofgood)[0]
print("商品人气"+hotofgood_number)
sheet.write(i, 6, hotofgood_number)
except Exception as e:
sheet.write(i, 6, "0")
print('get button failed: ', e)
os.remove('Goodsinformation.xls')
book2.save('Goodsinformation.xls')
sleep(3)
self.browser.close()
self.browser.switch_to.window(main_driver)
if flag_pingzhong == 1:
sheet_pingzhong.write(j, 0, title)
sheet_pingzhong.write(j, 1, price)
sheet_pingzhong.write(j, 2, shop_name)
sheet_pingzhong.write(j, 3, origin)
sheet_pingzhong.write(j, 4, Monthlysales_number)
sheet_pingzhong.write(j, 5, evaluate_number)
sheet_pingzhong.write(j, 6, hotofgood_number)
sheet_pingzhong.write(j, 7, good_info)
os.remove('品种茶.xls')
book2_pingzhong.save('品种茶.xls')
try:
next_page = WebDriverWait(self.browser, 3, 0.2).until(
lambda x: x.find_element_by_xpath('//span[contains(text(),"下一页")]/..'))
except Exception as e:
print(e)
else:
next_page.click()
self.browser.quit()
if __name__ == "__main__":
# 使用之前请先查看当前目录下的使用说明文件README.MD
# 使用之前请先查看当前目录下的使用说明文件README.MD
# 使用之前请先查看当前目录下的使用说明文件README.MD
chromedriver_path = "" #改成你的chromedriver的完整路径地址
weibo_username = "" #改成你的微博账号
weibo_password = "" #改成你的微博密码
a = taobao_infos()
a.login() #登录
################创建excel表
book = xlwt.Workbook(encoding='utf-8')
sheet = book.add_sheet('Sheet1')
proj = ['商品名', '单价/元', '店铺名称', '店铺位置', '商品月销', '商品评论数','商品人气', '商品详情']
for i in range(0, len(proj)):
sheet.write(0, i, proj[i]) # 按行插入行标题
book.save('Goodsinformation.xls')
book_pingzhong = xlwt.Workbook(encoding='utf-8')
sheet_pingzhong = book_pingzhong.add_sheet('Sheet1')
for i in range(0, len(proj)):
sheet_pingzhong.write(0, i, proj[i]) # 按行插入行标题
book_pingzhong.save('品种茶.xls')
a.crawl_good_buy_data() #爬取淘宝
参考
爬取淘宝商品信息
利用Selenium爬取淘宝商品
python+selenium通过添加cookie获取淘宝网的登录态
使用selenium爬取淘宝页面中的商品信息
淘宝天猫评论爬取,简单的办法完成滑动验证
selenium跳过webdriver检测并爬取淘宝我已购买的宝贝数据
评淘宝小米10爬行“蜘蛛+皮托圭”,Splinterpyautogui,爬取,评论
python(15)提取字符串中的数字
如何在Python中创建Excel表格

















 1608
1608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









