




 博客介绍了网页爬取相关内容。以Chrome浏览器为例,说明了获取User - Agent请求头的步骤,即进入网站查看network,点击name下文件,在requests headers中找到User - Agent并复制到headers里。还提到可转换成json的网页较好爬,以及后续有写入文件操作。
博客介绍了网页爬取相关内容。以Chrome浏览器为例,说明了获取User - Agent请求头的步骤,即进入网站查看network,点击name下文件,在requests headers中找到User - Agent并复制到headers里。还提到可转换成json的网页较好爬,以及后续有写入文件操作。
import requests
url = 'https://www.youkuaiyun.com/?spm=1001.2014.3001.4476'
headers = {'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36'}
def get():
try:
g = requests.get(url)
g.encoding = 'utf-8'
data = g.text
with open("csdn.txt","a") as file:
file.write(data)
print("Done!")
file.close()
except:
print("Oh,Little error!")
get()
先附上代码,这个User-Agent可以在Chrome或火狐浏览器上查看。我已Chrome为例,首先,来到你想爬取的网站,右键选择查看。选择network。
进去后你会看到一些进度条,如果没有,刷新一下。
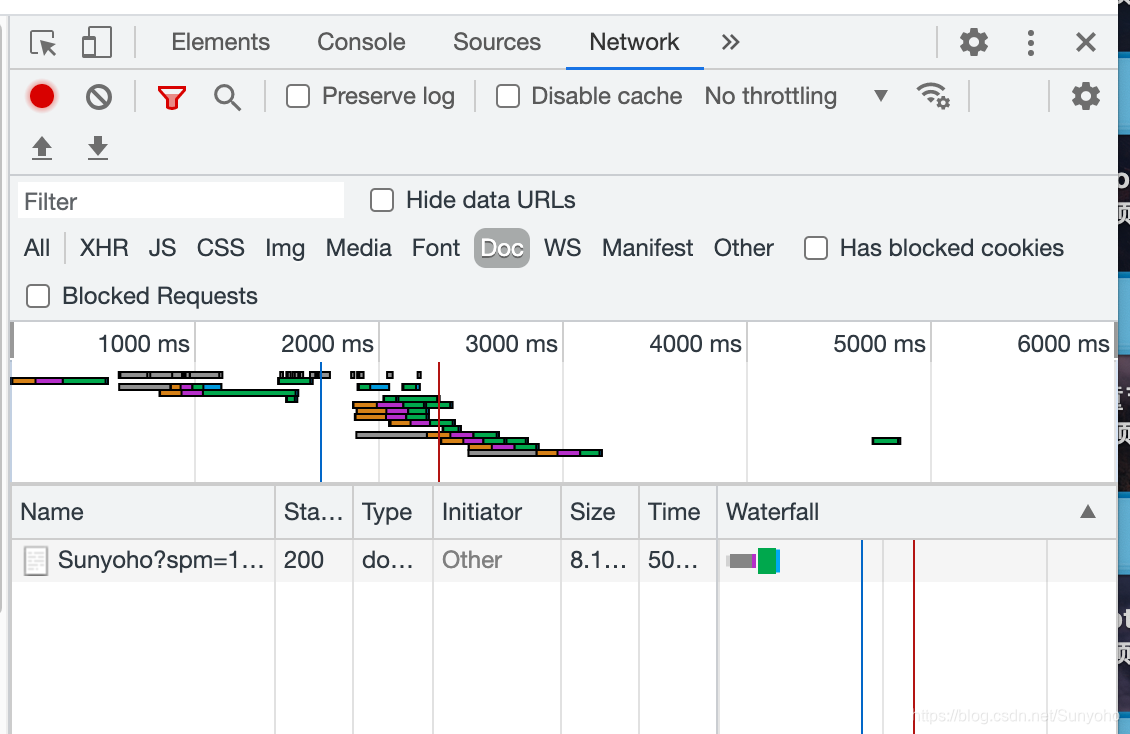
然后点一下name下的文件,我的文件是Sunyoho?spm开头的,注意,点一下就好,不要双击。
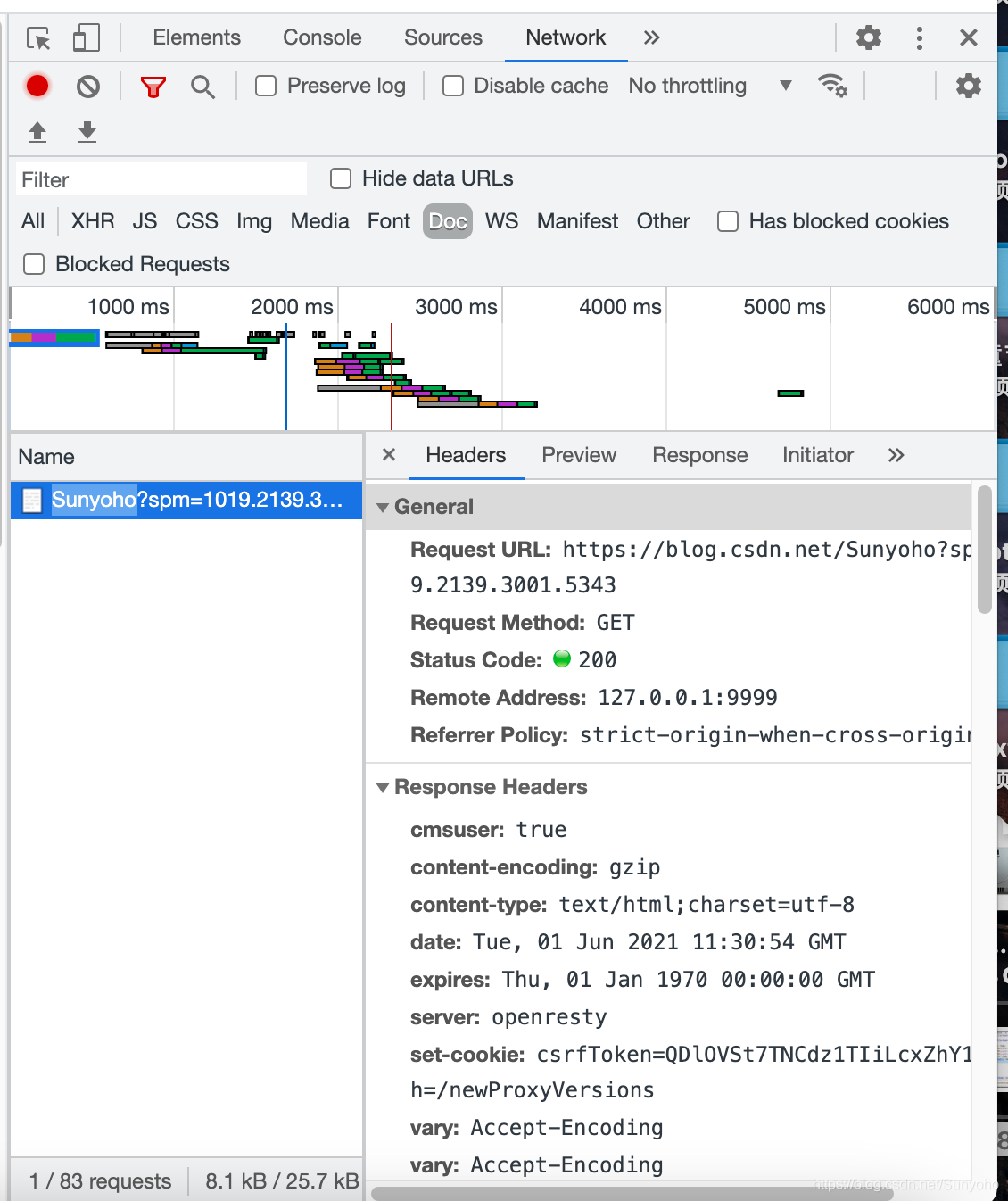
进去后会出现很多选项,往下滑,滑到requests headers,就是这个请求头,如果要获取到网站信息,有些网站是不让你爬的,所以要把这个爬取请求伪装成是你的浏览器访问网站。
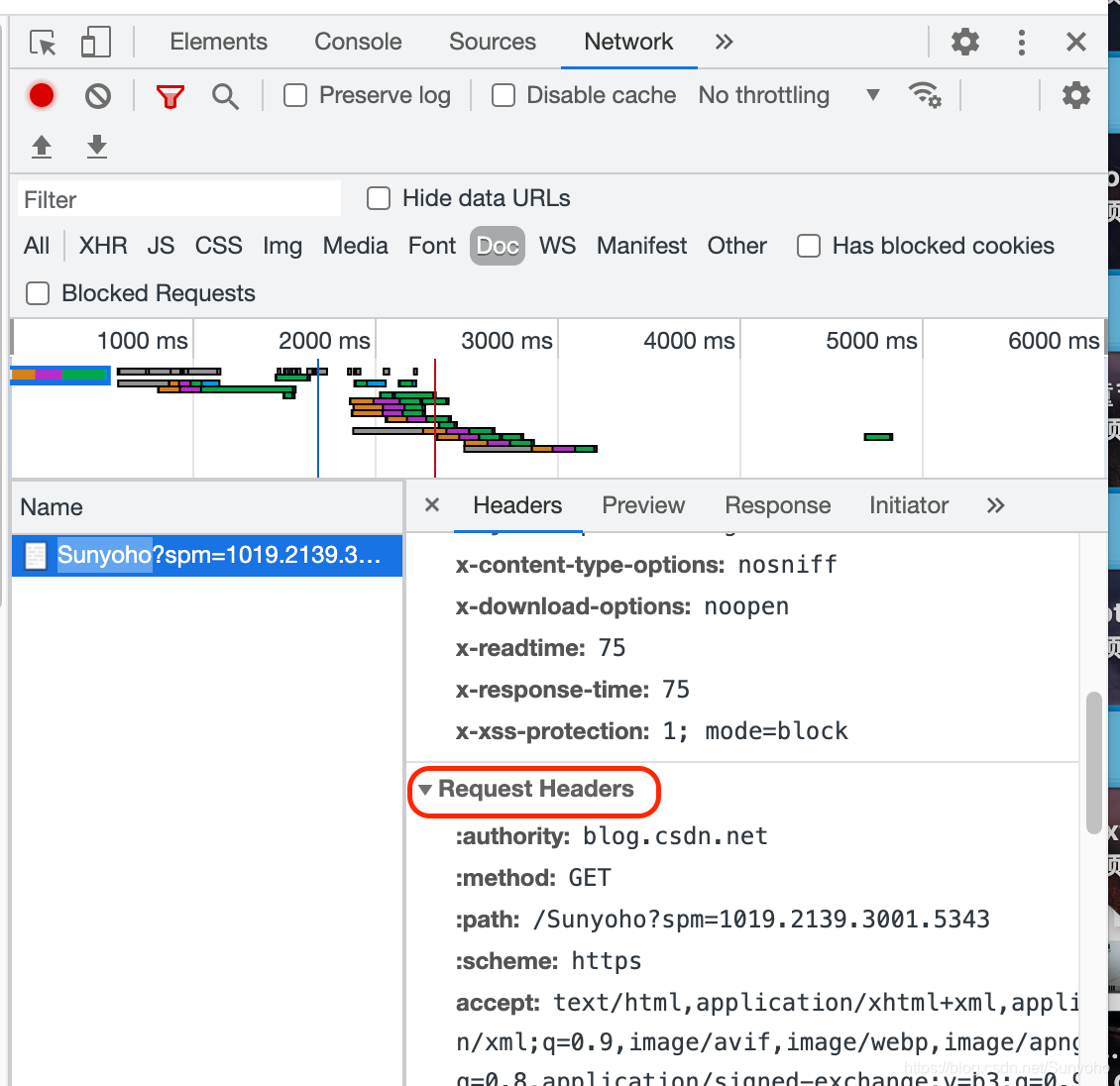
然后往下翻,找到这个,User-Agent。Mozilla开头的,OK!直接把你的请求头复制下来,选中,然后Mac用command+c拷贝,win用ctrl+c,复制到headers里去。
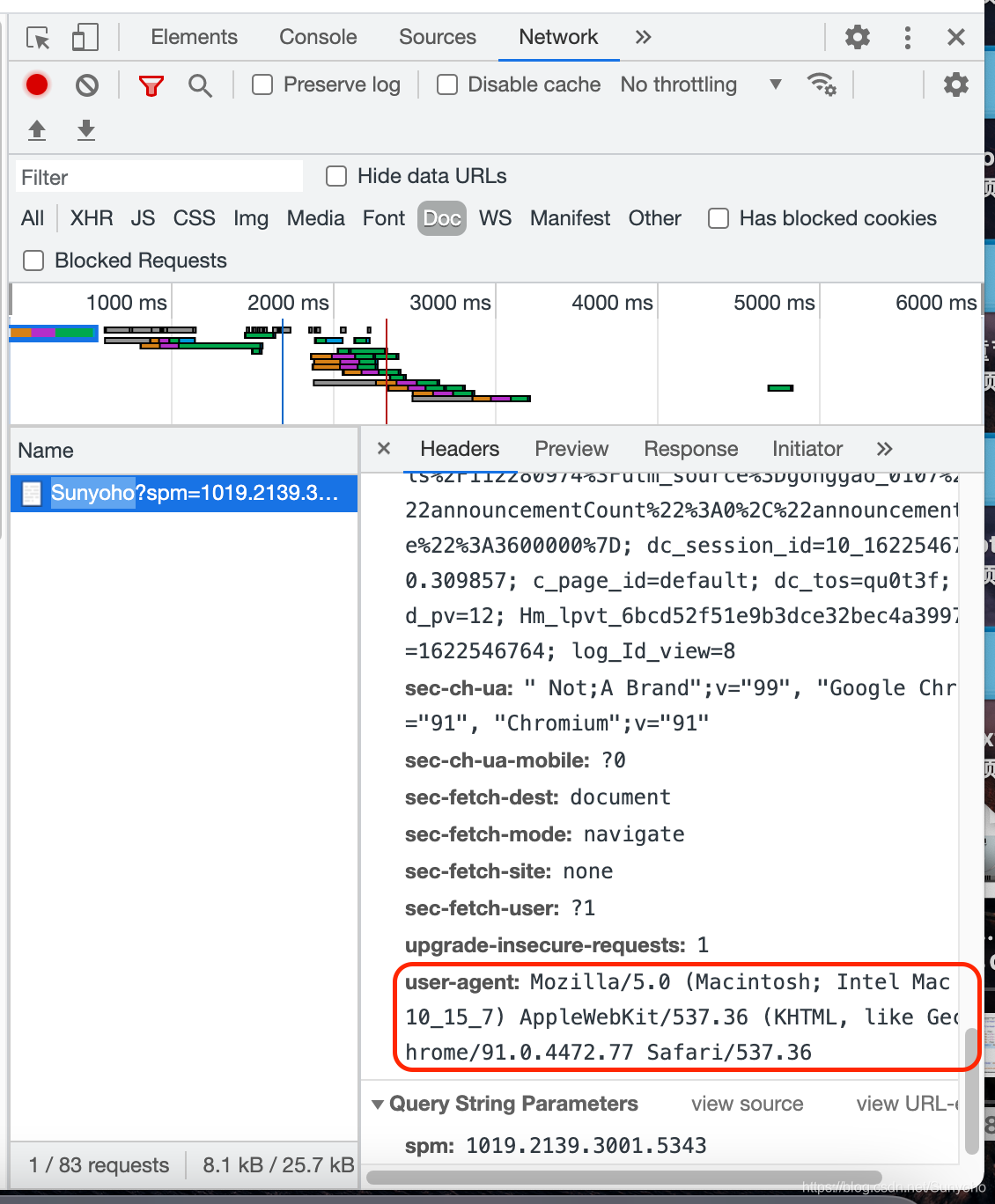
像这种可以转换成json的网页比较好爬,下面就是写入文件的一些操作,不用多说。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









