



 提出一种结合双向LSTM与CNN的模型,实现对客户反馈文本的有效自动分类。该模型能捕捉句子的上下文信息,并从中提取关键特征,从而准确地将反馈分为评论、请求等多个类别。
提出一种结合双向LSTM与CNN的模型,实现对客户反馈文本的有效自动分类。该模型能捕捉句子的上下文信息,并从中提取关键特征,从而准确地将反馈分为评论、请求等多个类别。
**
摘要
通过分析顾客户反馈的信息有助于改善顾客服务,许多在线客户反馈采用在线评论的形式,但是大量的此类数据使得手动分类变得不切实际,因此需要自动分类以允许分析系统识别客户表达的含义或意图。IJCNLP 2017共享任务4的目的是将客户反馈分为六个标签。 我们提出了一个系统,它使用单词嵌入来表达语料库中句子的特征,使用神经网络作为分类器来完成共享任务。 然后使用集合方法来获得最终预测结果。针对本文提出的方法在12项提交的结果中微平均F1排名第一,准确率第二。
1介绍
软件公司每天连续不断地收到大量的网上顾客反馈信息,包括产品评价,漏洞报告,新功能需求,反应投诉,容量问题等等。对此有效分类客户反馈可以为改进的客户服务提供基础,但是大量数据使得手动分类变得不切实际,因此需要自动分类以准确识别客户的意义或意图。
句子分类对于自然语言处理而言是一个基础性的任务(Collobert 等,2011),此共享任务的目标是将跨语言客户反馈分为六类(评论,请求,漏洞错误,投诉,无意义和未确定)。每个句子将被分配至少一个标签。它可以被视为多标签分类问题。近年来,深度神经网络模型,如卷积神经网络(CNN)(Cun等,1990),循环神经网络(RNN)(Goller和Kuchler,1996),长期短期记忆(LSTM)(Hochreiter和Schmidhuber,1997)及其组合(Wang et al。,2016)在许多NLP任务中取得了显着成果,包括句子分类(Kim,2014; Kalchbrenner等,2014),情感分析(Ir-soy和Cardie, 2014; Liu et al。,2015),讽刺检测(Ghosh和Veale,2016; Amir等,2016)。神经网络模型可以自动推断特征,并可以用作感知分类器。单词嵌入(Mikolov等,2013a; 2013b; Pennington等,214; Yu等,2017)可以提供单词矢量表示,捕获单词的语义和句法信息。单词向量用于构建感知矩阵,然后将信息注入到感知分类器中。 LSTM可以在一个方向上提供传感序列信息。前向和后向网络分别捕获过去和未来的信息。因此,我们为模型使用了双向LSTM。本文提出了一个系统,将英国客户反馈分为六个标签(评论,请求,漏洞错误,投诉,无意义和未开发)。该系统使用句子的词向量作为输入,神经网络作为分类器,神经网络使用句子矩阵作为输入来将句子分类为六个标签。 对于多标签分类,我们为每个标签构建二元分类器。 拟议的句子分类模型由两部分组成:双向LSTM和CNN。 双向LSTM用于通过顺序建模捕获句子的上下文。 序列特征用作CNN层的输入,然后用于提取最重要的特征以形成句子表示。 顶部的逻辑回归层用于输出句子标签。
文章剩余的部分作如下安排:第2章节描述句子分类的模型,第3章节简要的介绍在文章中用到的集成方法,章节4报告实验结果并分析。章节5则是给出结论以及对于未来工作的方向。
2句子分类模型
该模型旨在根据句子文本将句子分为六个标签。 图1显示了用于句子分类的双向LSTM-CNN模型的框架。 在输入层中,基于单词向量将句子变换为句子矩阵。 使用Glove(Pennington等,2014)工具包从大型语料库训练词汇单词的单词向量。 句子矩阵被馈送到前向LSTM网络和后向LSTM网络。 然后在所有时间步长上对表示序列进行平均,然后连接以产生最终序列表示。 序列是CNN层的输入。 CNN提取序列特征信息,然后是逻辑回归层,其目标是给定句子的类标签。
对于给定的语料库,我们将词向量存储在一个可以用来查找的矩阵MMM∈\in∈Rd∗∣V∣R^{d*|V|}Rd∗∣V∣中,|V|是指所给文本词汇量的大小,d是指词向量的维度,对于句子S={s1,s2,s3,....sn},nS=\{s_1,s_2,s_3,....s_n\},nS={s1,s2,s3,....sn},n是句子的长度,设|V|为词汇量,而d是词向量的维度,那么句子的矩阵表示则是X={x1,x2,x3,....xn}X=\{x_1,x_2,x_3,....x_n\}X={x1,x2,x3,....xn},xix_ixi则是单词sis_isi根据查找矩阵M中的词向量。
2.1循环神经网络
为了捕获输入序列之间的关系,我们可以使用RNN层将单词向量转换为句子特征表示。由于梯度消失和梯度爆炸的问题(Pascanu 等人,2012),引入Lstm(rnn的一种)用于序列建模(Tang等人,2015;Tai等,2015),Lstm是由三个门组成:输入门i,遗忘门f和输出门o,门机制协作工作去学习长期依赖,在每个时刻步骤t,Lstm计算过程如下:
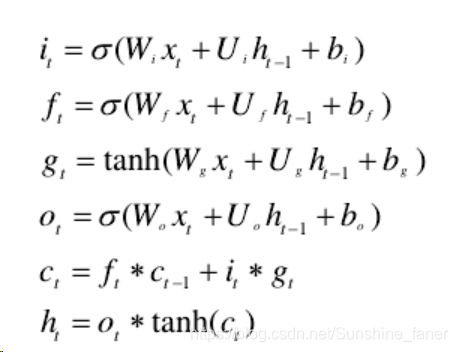
xix_ixi是底层的输入,ht−1h_{t-1}ht−1是时间步骤t−1t-1t−1的隐藏状态,it,ft,oti_t,f_t,o_tit,ft,ota分别为输入门,遗忘门,输出门。w∈Rw∗dw\in R^{w*d}w∈Rw∗d和U∈Rw∗dU \in R^{w*d}U∈Rw∗d是输入xtx_txt和隐藏状态ht−1h_{t-1}ht−1对于不同门时的权重矩阵,bbb是偏置,这儿*是表示按位相乘,σ(⋅)\sigma(\cdot)σ(⋅)和tanh(⋅)tanh(\cdot)tanh(⋅)是元素的激活函数。d可以是词向量的维度,也可以是下层隐藏状态的大小。前向网络和反向网络可以分别捕获过去和将来的信息。对于句子分类,将过去和将来的信息结合起来进行词序建模是有益的。因此,在序列建模中,我们使用双向LSTM获取上下文信息。
2.2卷积神经网络
卷积是用来提取n元特征,我们使用卷积核F∈Rw∗dF\in R^{w*d}F∈Rw∗d来获得特征映射Y∈Rn−w+1Y\in R^{n-w+1}Y∈Rn−w+1,第j个元素yiy_iyi 是由:yi=f(W⋅xj:j+w−1+b)y_i=f(W \cdot x_{j:j+w-1}+b)yi=f(W⋅xj:j+w−1+b)得来。fff是Relu激活函数,WWW是卷积核的权重,bbb是偏置,www是卷积核长,ddd的词向量维度,卷积层使用多组卷积核并行获得特征映射。因此可以利用不同长度的卷积核提取不同的特征信息。
将特征映射输入最大池层,获得最显著的信息,形成特征向量。特征向量有助于确定输出结果。
3集成方法
在统计学中,集成方法使用多种学习算法来获得更好的预测性能(Maclin和Opitz,1999年;Rokach,2010年)。本文采用基于神经网络的方法,在不同的训练时间内产生多个结果,以获得更好的预测性能。对于多标签分类,我们对集成法中的投票规则进行了修改。预测输出可以分两步计算:对于每个标签,如果积极结果占总预测结果的一半以上,我们将句子分配给标签I。在那之后,如果句子没有被注释,我们将它指定给j加上最大成分的预测。
4,实验和评估
数据集,针对分析客户反馈这一任务准备了几个带注释和未注释的英语客户反馈句子,共有3065个培训文本,500个开发文本和500个测试文本。培训和开发文本标有六个标签(评论,请求,错误,投诉,无意义和未确定)。我们通过将测试集的结果提交给IJCNLP 2017任务4客户反馈分析来评估提出的双向LSTM-CNN模型。表1中所示的六个标签的分布表明数据不平衡。大多数数据被分配了五个类别标签中的一个,并且只有少数被注释为未确定。通过词嵌入工具提供许多预先训练的英语单词向量。我们使用训练的840B标记的预训练单词向量来自common crawls,其维度由Glove(Pennington等人,2014)提供300,因为词汇量很大。如果单词不在预训练的词汇表中,则使用均匀分布样本随机初始化单词向量.
设Y是句子标签的向量表示。 标签ls = {l1,l2,l3,l4,l5,l6},句子有多个标签{l1,l2}。 对于每个标签,我们使用二元分类器。 因此,我们可以将标签表示为:Y =(1,1,0,0,0,0),通过二元交叉熵计算损失函数。
实验设置。包含开发集和训练集的数据集随机抽取,然后重新划分为5倍交叉验证。基于开发数据的性能选择神经网络的超参数。我们通过平均5倍交叉验证中的开发集的10个评估结果来获得最终的超参数。每个epoch时间为10,以尽量减少损失函数。为了避免过度拟合,我们使用早期停止机制和随机dropout(速率为0.25或0.5)(Srivastava等,2014)。 nadam(Dozat,2016)更新规则用于自动调整学习速率。顶层中的激活函数是一个sigmoid函数,它将每个标签在0到1的范围内缩放。如果连续结果iy大于0.5,则向上舍入为1,否则设置为0。将六个标签的预测结果Y =(0,0,0,0,0)分配给具有Y的最大值iy的标签i。
我们首先在CNN,LSTM及其组合上进行实验,包括LSTM-CNN,CNN-LSTM,bi-LSTM和bi-LSTM-CNN。 CNN1和CNN2具有不同的超参数,在CNN1中具有256个特征映射,3个卷积核窗口,以及在CNN2中具有128个特征映射的3和5个卷积核窗口。我们比较基于NN的方法生成的结果,并在微平均F1中的开发集数据上选择最佳的五个结果,以产生整体结果。
评估指标。ijcnlp 2017年任务4发布了所有参与者的评估结果,这些结果基于准确性和微观平均F1测量。对于二元分类,有四个基本结果:正积极(tp)、正消极(tn)、负积极(fp)和负消极(fn)。准确度和F1分数(Powers,2011)是用于评估二元分类问题性能的评估指标B(tp、tn、fp、fn)。准确度是真实结果(tp和tn)在总测试集中的比例。微平均F1对其在所有标签中的总计数进行了二元评估。结果。共有12个小组参加了任务4。表2显示了综合方法的结果,其中最好的五个结果产生的双向LSTM-CNN模型。我们通过对所有标签的微观平均f1进行排序获得最佳结果。微平均f1的综合结果排名第一,准确度排名第二。表3显示了神经网络模型十次运行的交流精度和微观平均F1的最佳实验结果,以及集成方法的RIVE运行。结果表明,该集成方法具有较好的性能,表明该集成方法在所有神经网络方法的基础上都有一定的改进。在所有基于神经网络的方法中,双LSTM CNN的集成结果达到了最佳性能。双LSTM在没有合奏的情况下获得了更好的性能。
5.结论
本研究提出一个神经网络模型,将基于文本的顾客反馈分为六个层次。我们使用系综方法,以微平均f1排序得到五个结果中的最佳结果。在所有基于神经网络的方法中,使用集成方法可以进一步提高性能。双向LSTM产生句子序列特征,卷积层从序列表示中提取显著信息,将句子分类为多个标签。实验结果表明,该双向LSTM-CNN具有最佳的性能。未来的工作将集中在探索多种语言的客户反馈,并考虑标签之间的高阶相关性,以提高微观和宏观平均F1的分类性能。

















 1753
1753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









