




 南京大学的研究团队提出BEVFormer,利用Transformer的注意力机制生成准确的BEV特征,解决深度信息不准确导致的3D检测性能问题。通过BEVquery、空间cross-attention和时序自注意力设计,有效融合多相机视图和历史BEV特征。
南京大学的研究团队提出BEVFormer,利用Transformer的注意力机制生成准确的BEV特征,解决深度信息不准确导致的3D检测性能问题。通过BEVquery、空间cross-attention和时序自注意力设计,有效融合多相机视图和历史BEV特征。
作者单位
南京大学,上海人工智能实验室
目的
动机:
- BEV的感知方式在多项任务中有较好的表现,但是在 3D 检测任务中,并没有明显的由于其它方法。原因是当前流行的生成 BEV 的方案对深度值 或 深度分布的准确性比较很敏感。不准确的 BEV特征会损害性能。本文想设计一种不依赖深度信息的 BEV 生成方式。 Transformer 可以利用注意力机制可以动态的聚合特征,可以满足本文的需求。
- BEV 是连接时间和空间的理想桥梁。时间信息在推断物体的运动状态和识别被遮挡的物体方面有重要作用。但如果只是简单的叠加时序的 BEV特征,结果可能并不理想。本文借了 RNN 的方法,可以循环的利用 BEV 特征。
因此本文提出了以 BEVFormer, 可以有效地聚合 多视图相机的时空特征 和 历史 BEV 特征。
方法
网络结构
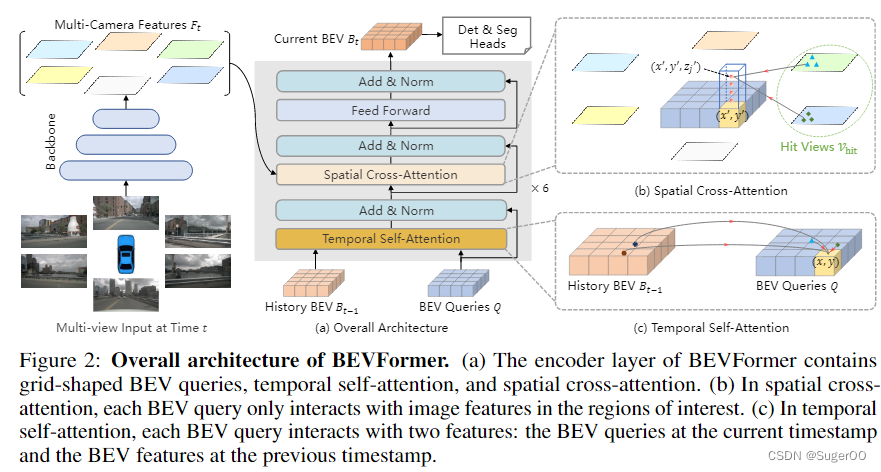
BEVFormer 架构
6个 encoder 层,基本都遵循 Transformer 的结构,除了3个自定义的设计:BEV query,空间 cross-attention, 空间自注意力。
BEV query 是网格状可学习的参数,旨在通过注意力机制 从多相机视图查询 BEV空间中的特征。
在 推理阶段,先生成多相机的图像特征。然后用 BEV queries 通过时序自注意力 从历史帧的特征上查询空间信息。然后使用 BEV queries 结合 cross-attention 从多相机特征 查询空间信息。在 FFN 之后,encoder 会输出 refined 的BEV 特征,作为下一层 encoder 的输入。经过 6 个堆叠的 encoder ,会生成一个 当前帧的 BEV feature,用于一些特定任务的 head。
BEV queries, 一个 shape 为 HxWxC 的可学习 向量,更具体的,query 上每一个位置都和 真实世界的位置一一对应。按照常规的做法,会加入 可学习的位置 embedding 到 BEV queries 中,输入到 BEVFormer。
空间 cross-attention
如果直接对多相机的特征做自注意力,多头注意力的成本很高。于是本文提出了 空间 cross-attention,其中每个 BEV queris 至于多相机视图中感兴趣交互。最初 deformable attention 视为 2D 感知设计的,所以 3D场景需要做一些调整。
首先将 BEV平面上的每个 queries lift 到 柱状(pillar-like )queries, 从中采样 N个 3D 参考点。然后将这些参考点 投影到 2D 视图。这些参考点只会落在一些视图上。然后从命中的视图参考点 附近采样一些特征。然后讲这些采样的特征 家全球和,作为 空间 cross-attention 的输出。
时序自注意力
首先将 T-1 帧的特征 和 T 帧的特征 在空间上对齐,然后做 deformable 注意力。
![![[attachments/Pasted image 20230813210210.png]]](https://i-blog.csdnimg.cn/blog_migrate/9418f8c8603ef844d67a2600e6152aac.png)
这里的 Q_p 表示 在 p=(x,y) 位置的 BEV query
相关资料
https://www.bilibili.com/video/BV1PF411c78z/?vd_source=00106fd989dcb83a8a603de5e4375920
https://www.bilibili.com/video/BV1A34y1W7Lu/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









