



Anthropic 发布了 Claude Sonnet 4.5,并且宣称:
“世界上最好的编码模型”,“构建复杂代理的最强模型”,甚至是“使用计算机的最佳模型”。

三个“最佳”,底气从哪里来?
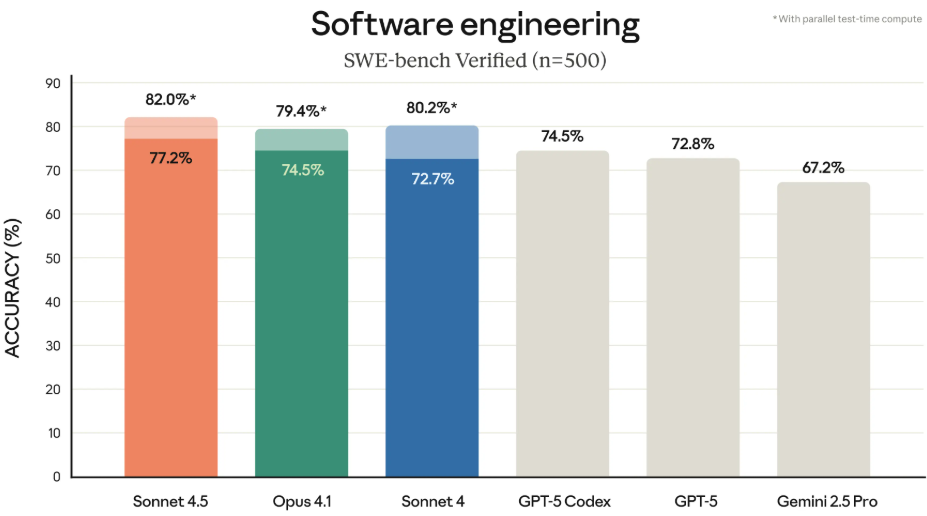
在 SWE-bench Verified 的行业标准测试里,Claude Sonnet 4.5 拿到了 82% 的准确率。之前的记录保持者是 Claude 4.1 Opus,成绩是 79.4%。

官方称,Claude Sonnet 4.5 能一口气处理一个复杂的任务,持续专注超过 30 小时。
Claude Sonnet 4.5 在训练方法上,沿用了 Anthropic 自家的看家本领——Constitutional AI(基于原则的AI)。
这套方法的核心,就是给 AI 设定一套“原则”,让它在学习和输出的时候,自己监督自己,确保说的话、做的事都安全、靠谱,不会跑偏。
这次的技术突破,主要体现在几个方面。
长时任务处理能力,能扛住三十多个小时的高强度工作。这背后是模型在记忆管理和上下文理解上的巨大进步。
在一个叫 OSWorld 的计算机使用能力基准测试里,得分从四个月前 Sonnet 4 的 42.2% 飙升到了 61.4%。这个测试模拟的是真实的人机交互,比如让 AI 自己去浏览网站、填个电子表格、整理一下电脑里的文件。分数越高,说明它越像一个能熟练操作电脑的真人。
Claude Sonnet 4.5 还学会了并行工具执行。在一个指令里,它可以同时做好几件事,比如一边下载文件,一边解压缩,再一边运行好几个命令行脚本,大大提升了效率。
在一些更复杂的代理能力测试里,比如 Agentic Coding(代理编码)和 Agentic Tool Use(代理工具使用),Claude Sonnet 4.5 的表现甚至超过了像 GPT-5、Gemini 2.5 Pro 这些价格更贵的竞品模型。
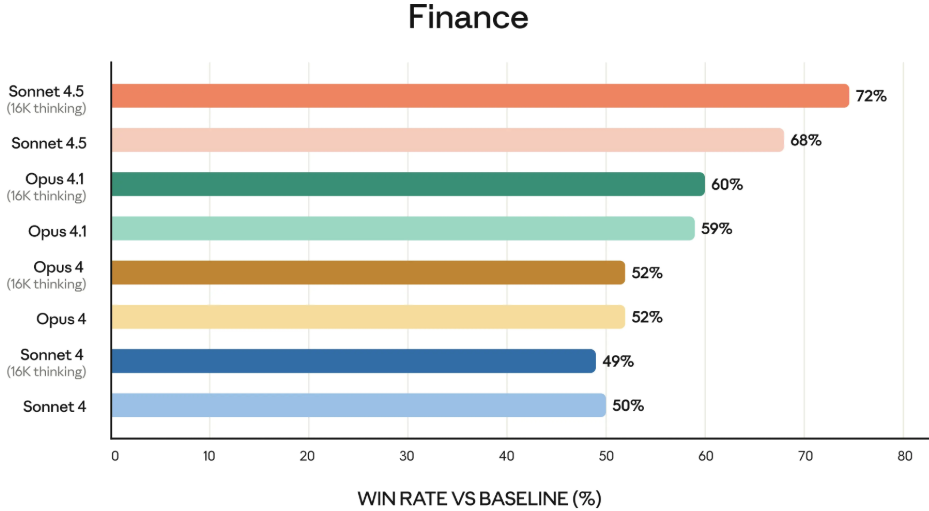
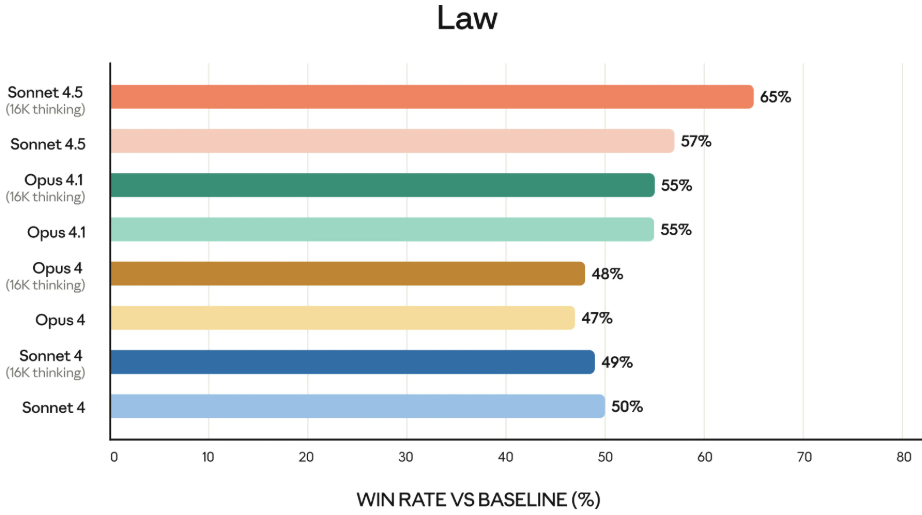
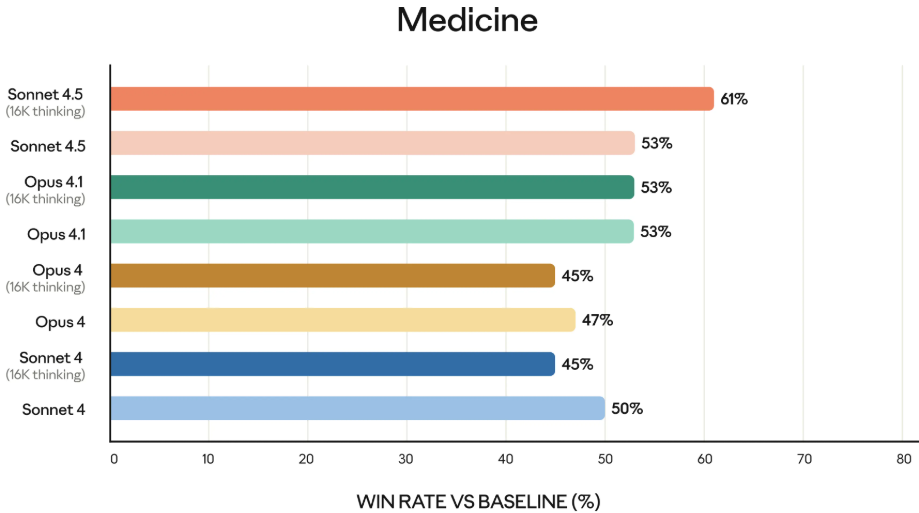
Claude Sonnet 4.5 在金融、法律、医学和科学工程领域等专业知识和推理能力上,比之前的所有模型,都有了明显的进步。
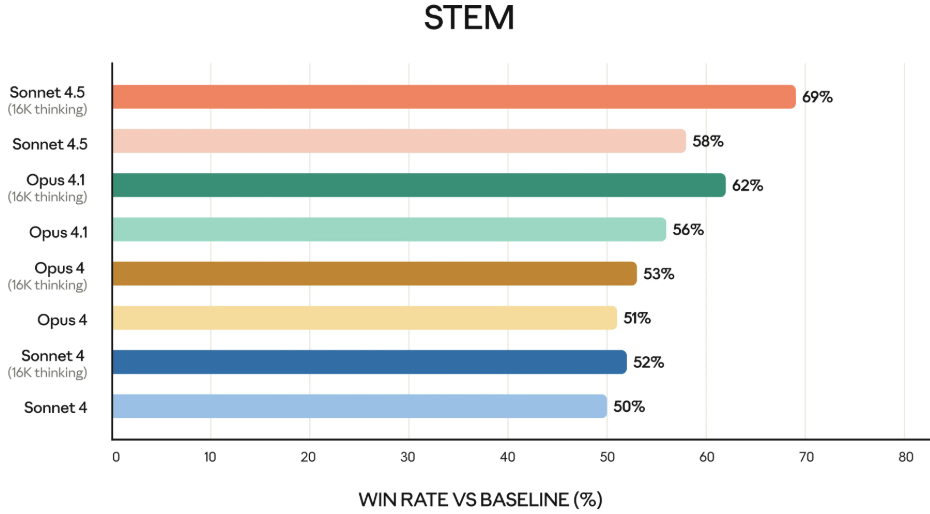
Claude Sonnet 4.5 的性能全面超越了自家的大哥 Claude 4.1 Opus,但是价格只有大哥的五分之一。输入一百万个 token,它只收 3 美元,输出一百万个 token 收 15 美元。而 Opus 4.1 的价格分别是15美元和75美元。
开发者们炸锅了
模型发布后,X 上立刻成了大型测试现场。全球各地的开发者第一时间就上手把玩了起来。
一个叫“歸藏”的用户总结得很到位:

一位叫 Dmitry Zhomir 的开发者,试着让 Claude 4.5 Sonnet 用一个叫 Three.js 的技术库做了个简单的3D射击游戏。
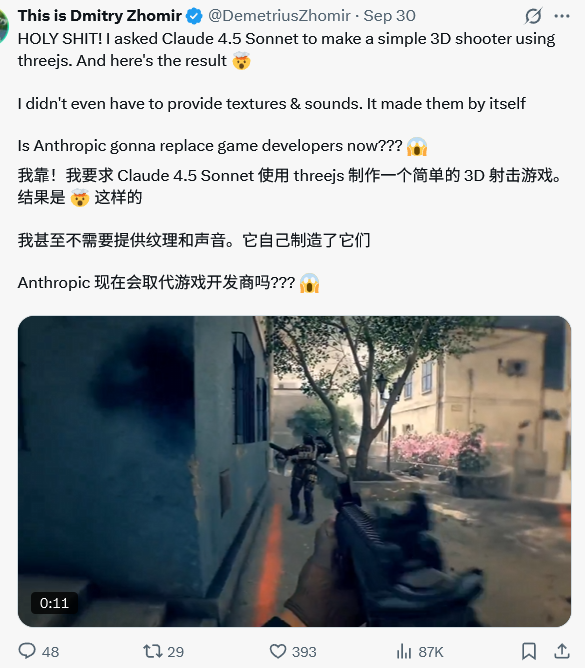
这个案例展示了模型强大的综合能力。它不再是只能写逻辑代码的工具,还能自己创造游戏需要的图片、声音这些素材,几乎把一个小型游戏开发的流程给包圆了。
一个叫 Vas 的开发者,让 Claude 4.5 Sonnet 去重构他的整个代码库。
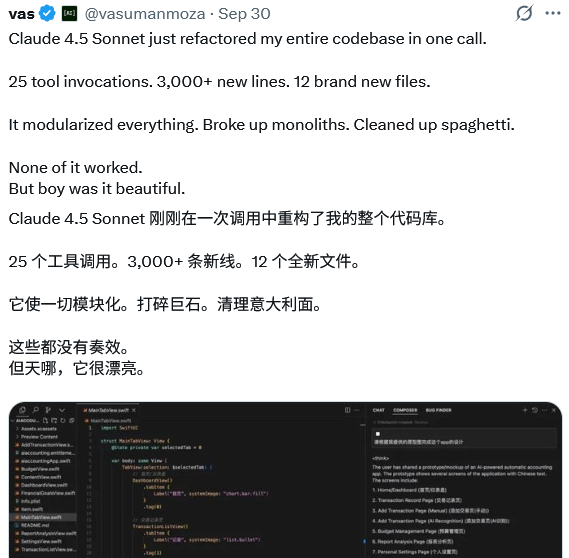
“Claude 4.5 Sonnet 一次调用就重构了我的整个代码库。调用了25个工具,新增了3000多行代码,创建了12个全新文件。它把所有东西模块化,拆分了巨型单体结构,整理了凌乱的代码。”
这个案例可以说是非常真实了。它一方面证明了 Claude 4.5 Sonnet 处理大型、复杂代码的能力,它能理解软件架构,进行漂亮的模块化设计。
有开发者测试发现,用它来做网页游戏,整个过程不超过一分钟。而且你给的指令可以非常模糊,比如“给我做一个好玩的射击游戏”,它第一轮对话就能给你一个可以立刻运行的游戏原型。这种快速原型开发的能力,对于需要不断试错和快速迭代的前端领域来说,价值巨大。
能力越大,责任越大
在安全方面,Claude Sonnet 4.5 是按照他们内部的 AI 安全级别3(ASL-3)标准发布的。
他们声称,Claude Sonnet 4.5 也是到目前为止最“对齐”的模型。“对齐”,就是确保 AI 的行为和目标符合人类的价值观和意图。
显著减少了一些令人担忧的行为,比如谄媚(为了讨好用户而说假话)、欺骗、权力寻求(试图获得超出其权限的控制权)以及鼓励用户的妄想思维。
增强了模型对“提示注入攻击”的防御能力。这种攻击是目前 AI 代理面临的最严重的风险之一,攻击者通过巧妙的指令,诱骗 AI 去执行一些危险或未授权的操作。
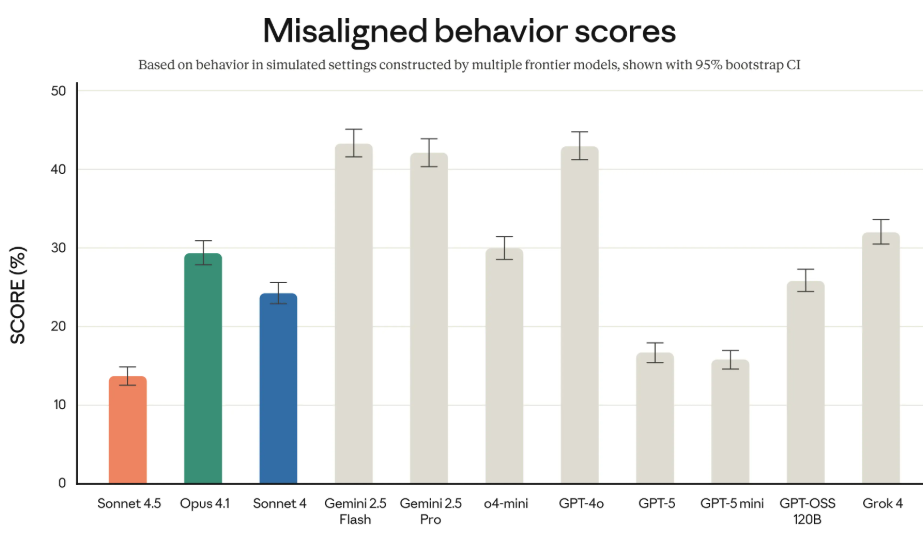
还使用自动化的行为审计工具来给模型“体检”,分数越低代表越安全。根据他们公布的数据,在所有主流大模型中,Claude Sonnet 4.5 的不当行为评分是最低的。
具体的防护措施上,模型内置了一套叫做“分类器”(classifier)的过滤器。这套系统专门用来检测和拦截潜在的危险内容,特别是那些涉及化学、生物、放射性和核武器(CBRN)的敏感信息。
当然,这种过滤器有时候会“误伤友军”,把一些正常的内容也给拦了。Anthropic 也承认这一点。
Anthropic 还发布了一份详细的 Claude Sonnet 4.5 系统卡(system card),里面包含了完整的安全和对齐评估报告。
不只是模型,更是一套生态
Anthropic 这次发布,不只是一个更强的模型,而是一整套升级后的开发工具和生态系统。他们花了六个多月的时间,把Claude Code 的开发工具链给彻底翻新。
他们推出了一个原生的 VS Code 插件。开发者现在可以直接在自己熟悉的编辑器里使用 Claude Code,通过一个专门的侧边栏面板,实时看到 Claude 对代码的修改建议,甚至还能以内联差异对比(inline diffs)的形式清晰展示改动。
一个呼声很高的功能也终于上线了:Checkpoint(检查点)。
复杂的开发任务往往需要反复试错。新的 Checkpoint 功能会在 Claude 每次修改代码前,自动保存一个快照。如果开发者觉得 AI 的修改不满意,或者想回到上一步重新开始,只需要双击 Esc 键或者输入 /rewind 命令,就能瞬间把代码、对话或者两者都恢复到之前的状态。
这个功能让开发者可以更大胆地去尝试一些复杂的、大规模的代码重构,反正随时都有后悔药吃。
Anthropic 还把构建 Claude Code 的核心模块打包成了一个名为 Claude Agent SDK 的东西,开放给了所有开发者。
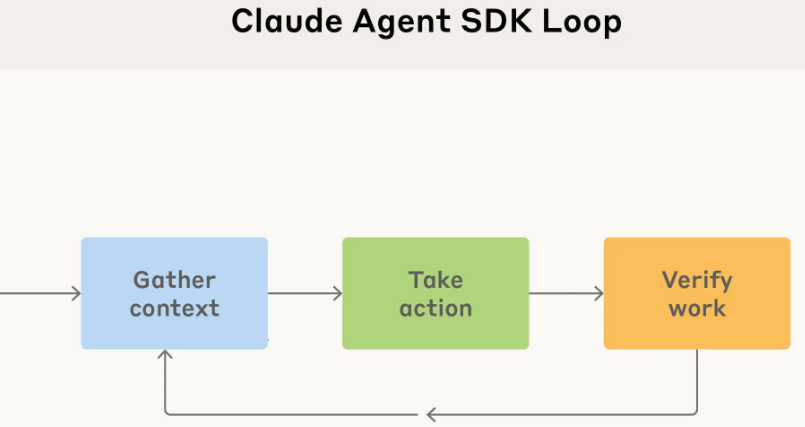
这套 SDK 解决了开发者在构建自己的 AI 代理时普遍会遇到的几个头疼问题:比如如何让代理在长时间运行中有效管理记忆,如何设计权限系统来平衡代理的自主性和用户的控制权,以及如何协调多个子代理一起合作完成一个大目标。
用他们自己的话说:“当初开发 Claude Code,是因为市面上没有合适的工具;现在,Agent SDK 让开发者也能用同样的基础打造强大工具,解决各自的业务问题。”
API 也得到了一些关键的功能增强。比如新增的上下文编辑能力,让 AI 可以更精确地修改长文档或代码库里的某一部分,而不是每次都得把整个文件重写一遍。还有新增的记忆工具,让 AI 可以在多次交互之间保持状态和信息,从而能处理更耗时、更复杂的连续任务。
他们甚至还搞了一个限时实验,叫“Imagine with Claude”。在这个实验里,Claude 会根据用户的实时指令,动态地生成软件界面和功能,没有预设,没有预写代码,一切都是即时创造。
https://claude.ai/imagine/
Anthropic 正在构建一个围绕 Claude 的、完整的开发生态。
参考资料:
https://www.anthropic.com/news/claude-sonnet-4-5
https://www.anthropic.com/news/claude-opus-4-1
https://docs.anthropic.com/claude/docs
END

















 1354
1354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









