



谷歌DeepMind研究团队发现,它们最新的视频模型Veo 3已经学会了“无师自通”,给它一张图、一句话,它就能处理一堆以前压根没学过的视觉任务。
这篇在9月25日发布的论文,标题很直接,《视频模型是零样本学习者和推理者》(Video models are zero-shot learners and reasoners)。研究人员发现,视频模型正在成为计算机视觉领域的那个“通才”,就像大型语言模型(LLMs)统一了自然语言处理(NLP)领域一样。
过去,自然语言处理领域也是一堆“专才”的天下,一个模型干翻译,一个模型搞问答,另一个负责写摘要,井水不犯河水。后来大型语言模型出来了,一个模型就能应付编程、数学、写作、翻译、研究等各种任务。
怎么做到的?方法简单粗暴,就是在海量数据上训练一个超大的生成模型。这样一来,模型就具备了强大的通用语言理解能力,不用再为每个任务单独“开小灶”了。通过给几个例子(少样本学习)或者直接下指令(零样本学习),模型就能解决新问题。
现在的计算机视觉领域,看起来就像几年前的自然语言处理。我们有专门用来做图像分割的“Segment Anything”,也有专门做物体检测的YOLO系列。这些模型在自己的领域里很能打,但通用性差点意思。你没法指望一个做物体检测的模型,动动嘴皮子就去给你解个迷宫。
但让自然语言处理领域发生质变的基本要素,视频模型也同样具备。
那就是在网络规模的数据上进行大规模训练。这次研究的主角是Veo 3,为了看看它到底进步了多少,研究人员还拉上了它的前辈Veo 2做对比。Veo 2和Veo 3的发布时间只隔了半年左右,但性能的提升却相当惊人。
游戏规则正在悄然改变
研究人员探索Veo 3能力的方法极其简单:提示它。
就是给模型一张初始图片作为视频的第一帧,再加上一句文本指令,然后让模型生成一个8秒长、720p分辨率、24帧率的视频。
它完全复刻了自然语言处理领域从复杂的模型微调到简单的提示词驱动的转变。核心观点就是,在自然语言处理领域,提示词取代了任务特定的训练;一个类似的范式转变,正在计算机视觉领域发生,而视频模型就是那个催化剂。
需要说明的是,根据官方文档,这个API系统里有一个基于大型语言模型的提示词重写器。也就是说,在某些任务里,解决方案可能来自语言模型,而不是视频模型本身。研究者把整个系统(重写器+视频生成器)看作一个黑箱。
但为了验证视频模型自身的推理能力,他们特地找了一些关键任务,比如机器人导航、解迷宫、视觉对称性等,用独立的语言模型(Gemini 2.5 Pro)试了一下,发现语言模型只看图是搞不定这些事的。这反过来证明了视频模型在其中扮演的关键角色。
研究人员把Veo 3展现出的能力分成了四个层级,一层比一层高级,后一层建立在前一层的基础上。
第一层是感知,也就是看懂图像里的信息。
提示词:在金刚鹦鹉所栖息的树枝顶端添加一个亮蓝色的圆点。金刚鹦鹉的眼睛变成鲜红色。其他所有东西都变为漆黑一片。摄像机视角保持静止,不进行缩放或平移。

第二层是建模,在看懂的基础上,理解物体和物理规律,建立一个对世界的认知模型。
提示词:手松开了物体。摄像机静止,无摇镜,无变焦,无推拉。(并没有告知松开手后会怎样?)

第三层是操纵,能够有目的地改变它所感知和建模的世界。
提示词:运用常识,让连接在机械臂上的两只机械手像人类那样打开罐子。

第四层是推理,能在一系列操纵步骤中,跨越时间和空间进行规划和解决问题。
提示词:在不越过任何黑色边界的情况下,角落里的那只灰色老鼠熟练地在迷宫中四处游走,直到找到那块黄色的奶酪。

可以看到,视频模型已经展现出了强大的通用能力。
先说感知。传统的计算机视觉任务,比如边缘检测、物体分割、关键点定位,都需要专门的模型来干。Veo 3不需要任何针对性训练,就能处理这些经典任务。它还能做超分辨率、图像去模糊、去噪和低光增强。
这些能力甚至延伸到更复杂的任务上,比如在一堆东西里找出你要找的(联合搜索),或者看懂那些模棱两可的图片。除了去噪本身就是扩散模型的老本行,其他这些活,视频模型可都没正经学过。
在感知的基础上,Veo 3开始对世界进行建模。它似乎理解一些朴素的物理规律。比如它能模拟刚体和软体的动态效果,知道木头是易燃的,理解空气阻力对下落物体的影响,也明白浮力是怎么回事。它还能模拟光的折射和反射,以及颜料的混合。
除了物理世界,Veo 3还能理解一些抽象关系。它能分清玩具和笔记本电脑的区别。它能识别模式,生成相似的变体,还能把一个整体拆分成部分。最关键的是,它有记忆,在视频播放过程中,即使镜头移动了,它也记得世界之前的状态。
有了感知和建模的能力,操纵世界就顺理成章了。Veo 3成了一个零样本图像编辑器。移除背景、转换艺术风格、给黑白照片上色、修复图片里的瑕疵、扩展图片边界(外绘),都不在话下。它甚至能修改图片里的文字,或者根据你画的简笔画来编辑图像。
它对三维世界的理解,让它能把零散的部件组合成一个场景,能从不同角度展示物体和角色,能把一个东西平滑地变成另一个东西,还能通过改变视角、光照和外观,把一张自拍变成专业的写真照。
这种能力让它能够想象复杂的互动。比如模拟灵巧的物体操作,解释一个工具是干什么用的,演示如何画一个形状,或者怎么卷一个墨西哥卷饼。总而言之,视频模型正在有目的地操纵和模拟一个数字化的视觉世界。
最后是推理,这是所有能力的集大成者。语言模型通过“思维链”一步步解决复杂问题,视频模型则通过“帧链”(也就是视频生成本身)来解决需要跨越时空进行逐步推理的视觉问题。
研究人员在很多任务中看到了这种推理能力的萌芽。
比如生成有效的图遍历路径、在树状结构上进行视觉上的广度优先搜索、完成视觉序列、连接相同颜色的点、把形状塞进对应的孔里、给数字排序。
它还能使用工具来完成任务,解决简单的数独和视觉谜题。最让人惊讶的是,它能解迷宫,还能从几个例子里推断出规则。虽然不总是完美,但它能在零样本的情况下尝试解决这些问题,本身就预示着未来更高级的视觉推理和规划能力的可能性。
定量评估如何?
定性分析看着很热闹,但模型的真实水平还得靠数据说话。研究团队选了七个任务,从感知、操纵、推理三个层面进行了定量评估。
Veo 3相比Veo 2有巨大提升,性能通常能赶上甚至超过Nano Banana。
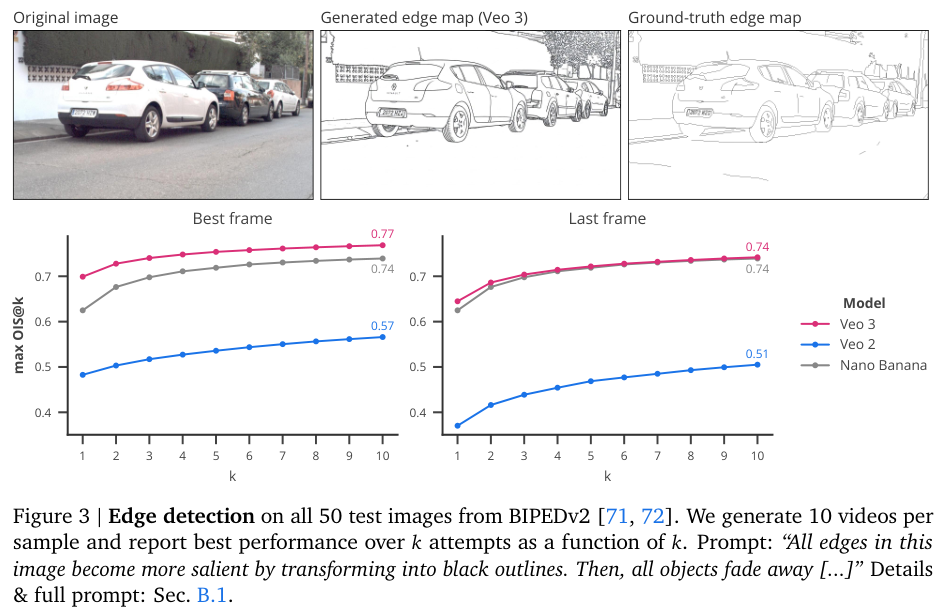
在边缘检测任务上,Veo 3的pass@10(尝试10次中的最佳表现)达到了0.77,虽然不如专门训练的模型(0.90),但考虑到它是零样本完成的,这个成绩相当亮眼。有趣的是,很多时候Veo 3画出的边缘比标准答案还精细,比如它会把树叶和轮胎的轮廓都勾出来,这在数据集里可能被认为是错误,但实际上更符合真实世界。
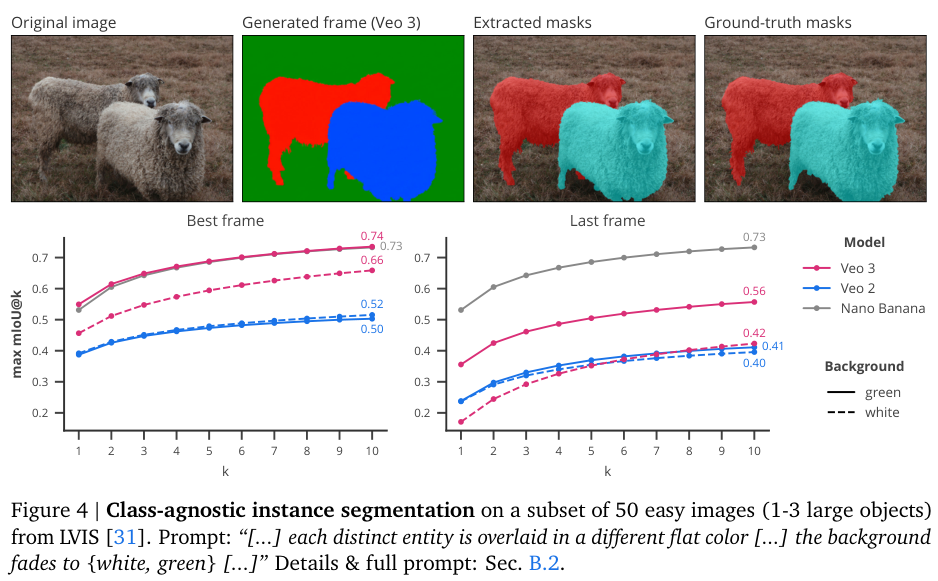
在实例分割任务上,研究人员让模型把图里所有物体都分割出来,但不告诉它具体是什么物体。结果显示,Veo 3的最佳帧pass@10达到了0.74的mIoU(平均交并比),和Nano Banana的0.73不相上下。这里还发现一个好玩的细节,提示词很重要。如果让模型把背景变成绿色,分割效果就比变成白色要好,可能是因为电影里的绿幕特效让模型对绿色背景更敏感。
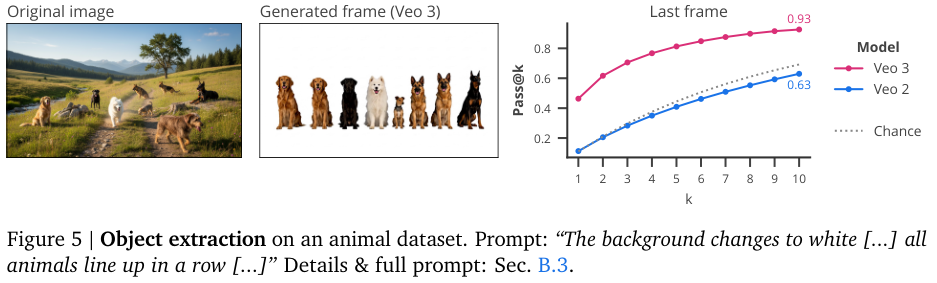
在物体提取任务中,他们让Veo把图里的所有动物都提取出来,排成一排。Veo 2的表现跟瞎猜差不多,但Veo 3的pass@10成功率高达92.6%。
在图像编辑任务上,Veo 3表现出色,尤其是在编辑时保留细节和纹理方面。不过它有个强烈的偏好,就是总想让场景动起来,这会引入一些意想不到的变化,比如镜头移动。如果能更好地控制这些“副作用”,视频模型可能会成为非常强大的、具备三维感知能力的图像和视频编辑器。

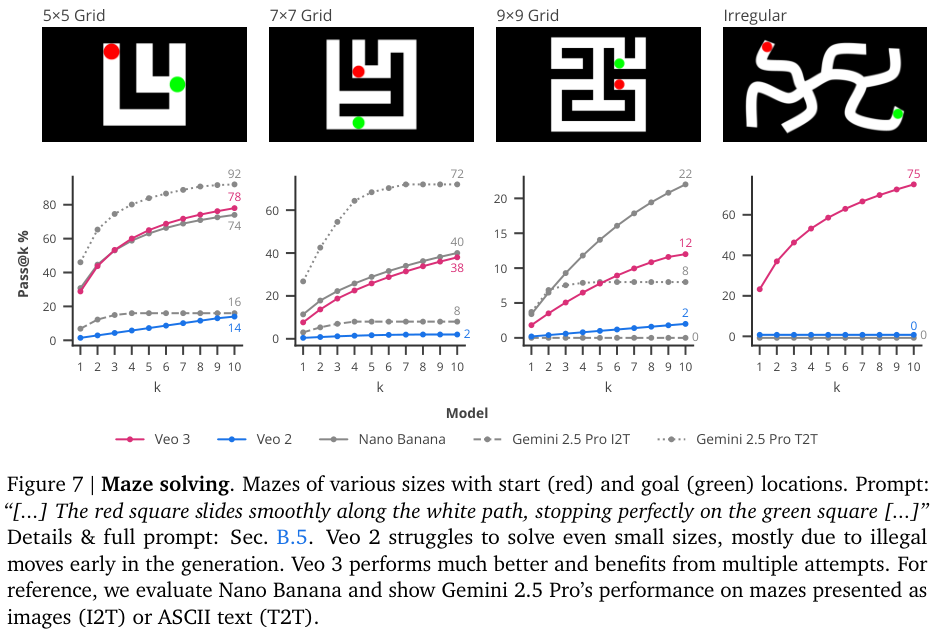
推理能力的测试是重头戏。在解迷宫任务中,Veo 3展现了真正的零样本推理能力,比经常“穿墙”的Veo 2强太多了。比如在5×5的迷宫里,Veo 3的pass@10成功率是78%,而Veo 2只有14%。虽然在规则的方形迷宫里,Nano Banana表现更好,但一到不规则迷宫,它就完全歇菜了。这恰恰凸显了视频模型在视觉媒介中逐步解决视觉问题的优势。
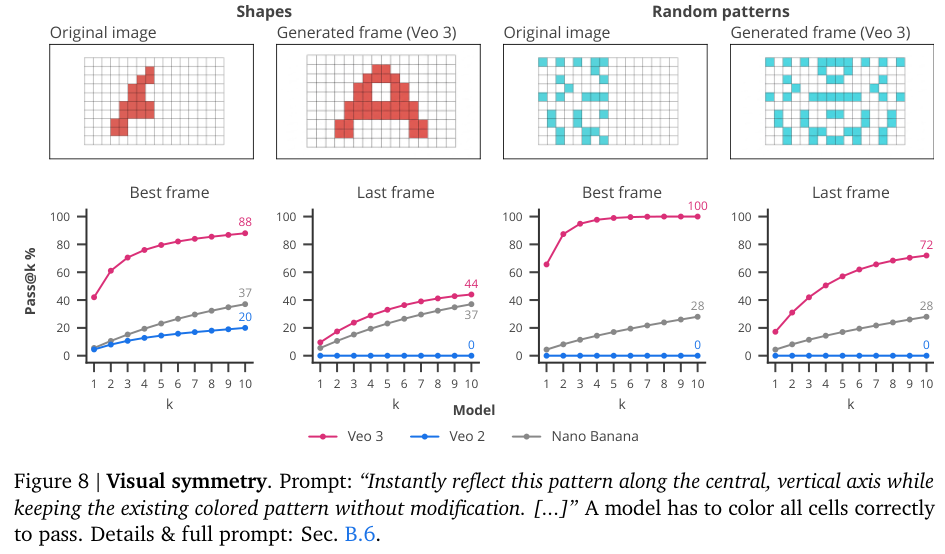
在视觉对称任务中,模型需要根据一半的图案补全另一半。Veo 3的表现远超Veo 2和Nano Banana。这个任务也证明了提示词工程的重要性,最好和最差的提示词,能让成功率相差40到64个百分点。
最后一个是视觉类比任务,考验模型理解关系和转换的能力,比如“A对于B,就像C对于?”。Veo 3能正确处理颜色和大小变化的类比,但在反射和旋转类比上表现不佳,甚至低于随机水平,说明它在这些方面存在系统性的错误理解。
视觉领域的GPT-3时刻到了吗?
这项研究的核心结论是,机器视觉正处在一个范式转变的边缘,而大规模视频模型的新兴能力是推动这一转变的关键。Veo 3能在零样本的情况下,解决从感知到初步推理的各种任务。
这里报告的性能,其实只是模型能力的下限。因为一个任务可以用无数种方式来呈现和提示。同样的迷宫,可以是黑白网格,也可以是游戏场景。
这说明,提示工程对于视觉任务和对于语言任务一样重要。我们必须区分一个模型在某个特定任务上的表现,和它解决这类任务的根本能力。所以,即使是研究中报告的失败案例,比如教模型叠衣服、规划搬沙发路线等,也可能只是没找到正确的“打开方式”。
生成视频的成本目前很高,但这不是问题。成本下降是有规律可循的。
有研究机构估计,大型语言模型达到同等性能水平的推理成本,每年会下降9倍到900倍。想当年GPT-3刚出来时,大家也觉得它太大太贵,难以部署。但快速下降的成本和通用模型的巨大优势,最终让它取代了大部分专用的语言模型。
如果历史会重演,那么同样的故事也将在视觉领域上演。
这是一个激动人心的时刻。
我们亲眼见证了自然语言处理领域从专用模型到通用模型的转变,现在,同样的剧本似乎要在计算机视觉领域上演了,主角就是这些日益强大的视频模型。
Sora 2的出现,就是最好的证明。
参考资料:
https://arxiv.org/abs/2509.20328
https://blog.google/technology/ai/generative-media-models-io-2025/
https://cloud.google.com/blog/products/ai-machine-learning/veo-3-fast-available-for-everyone-on-vertex-ai
https://cloud.google.com/vertex-ai/generative-ai/docs/video/turn-the-prompt-rewriter-off#prompt-rewriter
https://video-zero-shot.github.io/
https://aistudio.google.com/models/veo-3
END

















 322
322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









