



大语言模型能写代码、做题、进行文学创作等等,十八般武艺样样精通,可这些模型给人的感觉是只会“背答案”,怎样才能真正激活它们深层次的推理能力呢?
由此诞生了强化学习与可验证奖励(Reinforcement Learning with Verifiable Rewards,简称RLVR)。各种RLVR算法层出不穷,但都面临着一个致命的弱点——模型太容易“早熟”了,也就是过早收敛,并且训练过程中还会出现一种叫“熵崩溃”的现象,也就是模型的思想僵化了,失去了探索新世界的动力。

一篇来题为《CDE:Curiosity-Driven Exploration for Efficient Reinforcement Learning in Large Language Models》的论文,应运而生。它由腾讯AI实验室与北卡罗来纳大学教堂山分校等顶级机构的研究人员联合发布,提出了一个颠覆性的解决方案——好奇心驱动探索(Curiosity-Driven Exploration,简称CDE)框架。这个框架不再从外部强行给模型灌输什么,而是反其道而行之,利用模型自己内在的好奇心信号,引导它去探索未知的世界。
AI训练老大难:原地踏步还是走火入魔?
在强化学习圈子里,有个“千古难题”,叫做“探索-利用困境”(Exploration-Exploitation Dilemma)。这是个啥意思呢?打个比方,你下馆子吃饭,发现一家川菜馆特别好吃,那你接下来是该继续吃这家,保证每顿都满意(利用),还是应该去试试旁边那家没吃过的新疆菜,冒着可能不好吃的风险,去寻找“更好吃”的可能性(探索)?这个两难的选择,就是这个困境的核心。
这个困境在训练大型语言模型的时候,被放大了无数倍。现在的RLVR方法,普遍都有点“功利”,它们太倾向于“利用”那些已经知道能拿高分的策略了。这就导致模型很快就满足于现状,不再去探索那些虽然有风险、但可能藏着更优解的“无人区”,也就是我们前面说的“过早收敛”。在训练过程中,这种现象有一个更专业的名词,叫“熵崩溃”(Entropy Collapse)。其实就是说模型的策略熵(可以理解为思想的混乱或多样性程度)急剧下降,整个模型变得死气沉沉,只会走老路,丧失了创造力和探索欲。
熵崩溃这玩意儿,可以说是RLVR的“癌症”,它直接暴露了现有训练方法的根本缺陷:重利用,轻探索。模型不是在学习,更像是在“应试”,只想着怎么在已知的路径上刷高分,而不是真正去理解和探索问题的本质。当然,强化学习的文献里,解决探索问题的策略汗牛充栋,但这些老办法一旦用到大型语言模型身上,就显得水土不服,各种拉胯。
比如,一些简单粗暴的启发式方法,像什么熵奖励(Entropy Bonuses)和ε-贪婪策略(ε-greedy Policies),它们要么是往环境里注入一些随机性,要么是鼓励模型的策略变得更随机。这些方法在理论上早就被证明不是最优的,在面对像深度强化学习和大型语言模型推理这种复杂如迷宫的环境时,效果更是备受争议。
那有没有更高级的玩法呢?有,那就是基于计数的探索方法。这种方法的思路很直观:哪个 状态-动作对(state–action pairs)被访问的次数少,就给它更高的探索奖励,激励模型去“雨露均沾”。像多臂赌博机(Multi-Armed Bandit)里的UCB(Upper Confidence Bound)算法,还有线性赌博机(Linear Bandits)和马尔可夫决策过程(MDPs)里的LinUCB和LSVI-UCB算法,都是这个流派的杰出代表,在很多场景下都取得了近乎完美的探索效果。但是,这些方法想在大型语言模型上施展拳脚,却面临两大拦路虎:
第一,计算复杂度太高了。这些算法动不动就要进行矩阵求逆这种“史诗级”的计算,对于大型语言模型那动辄亿万维度的高维嵌入来说,计算成本高到能让英伟达的股价再翻一倍,根本不现实。
第二,太依赖表示能力了。它们的效果好坏,严重依赖于你能不能把状态-动作对(在LLM里就是推理路径)表示得足够好。可大型语言模型的推理过程,尤其是那种带有长思维链(Chain-of-Thought,简称CoT)的推理,其路径复杂多变,想用一个固定的嵌入向量就把它完美地表示出来,简直是天方夜谭。
研究团队也试过。他们最初就想把基于计数的探索方法直接搬到RLVR里用。为了绕开矩阵求逆那个计算黑洞,他们很机智地用了SimHash技术,把思维链响应的嵌入向量映射成离散的哈希码,然后用哈希码被访问的频率来当成一个“伪计数”。
想法很丰满,现实很骨感。这个方法在实践中被证明问题很大:复杂的思维链推理轨迹,根本没法用一个固定的嵌入向量来有意义地表征。结果就是,大部分的响应都挤在相同或相近的哈希格子里,导致计数分布高度集中,所谓的“基于计数的探索”也就成了一句空话,对RLVR的帮助微乎其微。
杀手锏:给模型装上“好奇心”雷达
既然老路走不通,那就得开辟新天地。面对传统探索方法的种种局限,研究团队的脑洞开始转向一个更直观、也更符合生物直觉的方向——利用模型自身内在的好奇心,来作为探索的指南针。这个想法的灵感,来源于人类婴儿的认知发展。你想想,小孩子学习新东西,可不是靠什么外部经验总结和计数驱动的,而是被一种探索新奇事物的内在好奇心所驱使。他们会去摸、去舔、去尝试一切未知的东西,这种源于本能的好奇心,才是最高效的学习引擎。

CDE框架的核心思想,就是要把这种“好奇心”机制,复刻到大型语言模型身上。它巧妙地从模型的两个关键组件——行动者(Actor)和评论者(Critic)——身上,分别提取好奇心信号。
咱们先来看看行动者(Actor)的好奇心。Actor就是负责生成文本的那个部分。研究团队用它生成响应的“困惑度”(Perplexity,PPL)来作为好奇心的度量。困惑度这个指标,就是衡量语言模型对一句话有多“吃惊”。困惑度越高,就表示模型对它自己生成的这句话越感到“意外”,越可能处在模型学习分布中一个它很少涉足的“知识盲区”。这不就是好奇心最好的体现吗?
Actor好奇心奖励的数学表达式长这样:
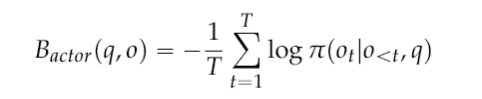
这里的q是输入的提示,o是生成的响应,T是响应的长度,π就是Actor的策略。这个B_actor的值越高,就代表模型越“惊讶”,也就意味着这是一个更强的、值得去探索的内在奖励信号。
Critic在强化学习里扮演的是“价值评估师”的角色,它的任务是判断当前的响应有多好。研究团队认为,Critic的判断本身,也蕴含着好奇心的信号。他们通过其后验价值分布的方差来衡量这种好奇心。这个听起来有点绕,咱们还是打个比方。假设你请了一群美食评论家(多头Critic)来评价一道菜(一个响应)。如果这道菜是他们经常吃的家常菜(数据密集的区域),那他们的打分可能都差不多,方差就很小。但如果这道菜是一道他们谁也没见过的分子料理(稀疏采样的区域),那他们的打分可能就五花八门,分歧很大,方差自然就很高。这种高方差,就代表了高度的不确定性,也正是需要探索的地方。
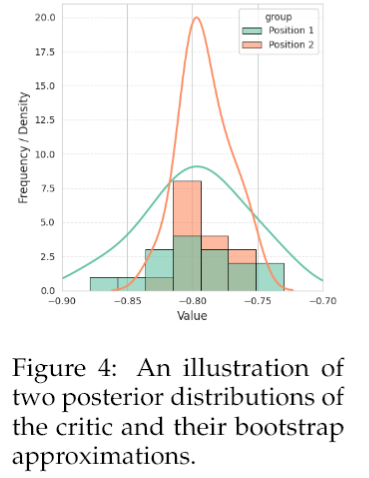
为了在实际操作中近似这个后验分布,研究团队采用了统计学里一个非常经典的方法——Bootstrap,并通过一个多头Critic的结构来实现。简单说,就是训练好几个Critic头,每个头只看一部分重新采样的数据。这样一来,每个头就有了自己的“偏见”,它们共同构成了对后验分布的一个经验近似。然后,用这K个头之间打分的标准差,作为一个原则性的好奇心信号,引导模型的策略朝着那些价值函数不确定、探索不足、评委们“吵得最凶”的高分歧区域前进。
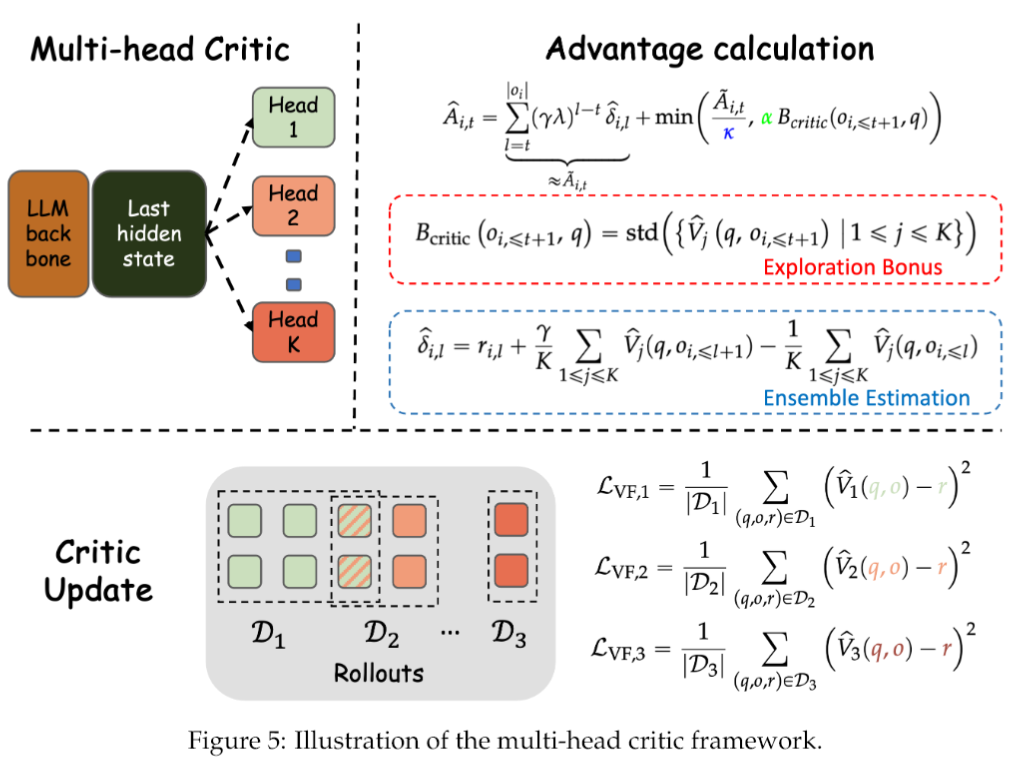
研究团队还通过两个关键的定理,把CDE和强化学习里那些经典的探索原则给联系了起来,让这个框架从一个“好点子”升华为了一个“有理论依据的科学方法”。
CDE实战效果有多猛?
研究团队在多个堪称“地狱难度”的数学推理基准测试上,对CDE框架进行了全面的“大考”,包括MATH、AMC23、AIME24和AIME25。这些可都是检验大型语言模型推理能力含金量的“试金石”。
实验的设置上,研究团队使用了一个名为DAPO-17K的数据集进行训练。考虑到计算资源,他们是在一个简化设置下进行的实验。所有的实验都是在Verl框架内,使用Qwen3-4B-Base这个模型来实现的。
不同模型在验证集上的零样本准确率。研究团队报告了Pass@1(一次就答对的概率)和Pass@16(生成16个答案里至少有一个答对的概率)两个指标。
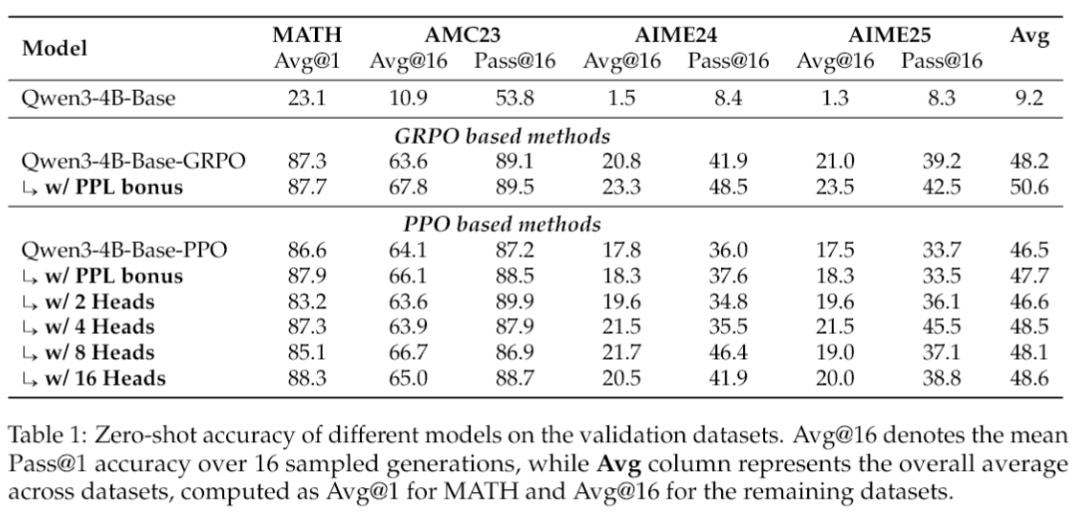
从这张成绩单里,我们看到:
PPL奖励(也就是Actor的好奇心)对GRPO(Group Relative Policy Optimization)方法的加成效果是肉眼可见的。在所有数据集上,平均提升了大约2.4个百分点,而且表现非常稳定。特别是在AIME24这个数据集上,Pass@16的成绩直接比基线GRPO方法暴涨了将近8个点,这提升幅度,相当恐怖。
多头PPO(Proximal Policy Optimization)(也就是Critic的好奇心)的表现,也是全面碾压普通的PPO。使用4个头和16个头的版本,在所有基准上平均获得了大约2个点的提升。尤其是在AIME数据集上,很多情况下的Pass@16成绩都飙升了将近10个点。
关于头的数量,也不是越多越好。实验发现,多头PPO的性能通常随着头数K的增加而提高,但有个阈值。K=2的时候,提升还不太明显;可一旦K增加到4或以上,性能提升就开始趋于平稳了。这说明,适度数量的头就已经能捕捉到大部分模型需要的那种“认知不确定性”了,再多就有点边际效益递减的意思。
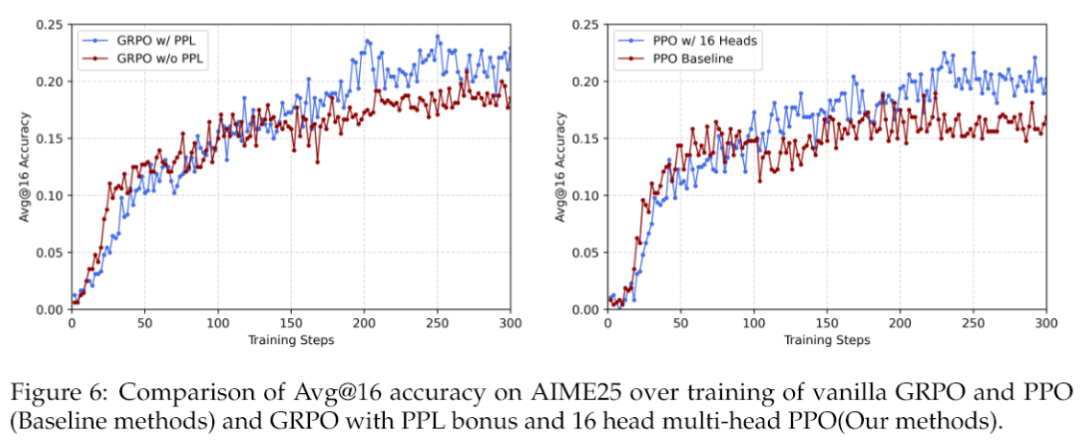
上面这张图揭示了一个更有趣的现象。你会发现,带PPL奖励的GRPO和多头PPO这些“好奇心”版本,在训练初期,提升测试准确率的速度反而比基线方法要慢。但是,别急,让子弹飞一会儿。随着训练的进行,它们开始奋起直追,并最终反超了基线。这个过程,完美诠释了什么叫“厚积薄发”。这种模式,鼓励模型先“放慢脚步,开阔眼界”,等到对整个问题空间有了更全面的认识之后,这些好奇心信号会自我校准,引导模型平稳地转向目标利用,最终自然能达到更高的性能天花板。
研究团队还对PPL奖励进行了更深入的“解剖”,发现了一些非常有意思的细节。比如,那个控制PPL奖励权重的系数ω_t,它的衰减方式大有讲究。他们比较了四种衰减方案:不衰减、线性衰减、余弦衰减和阶梯式衰减。
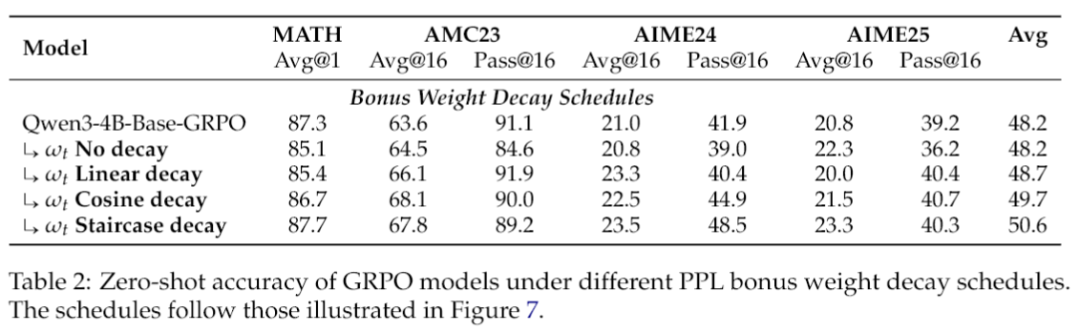
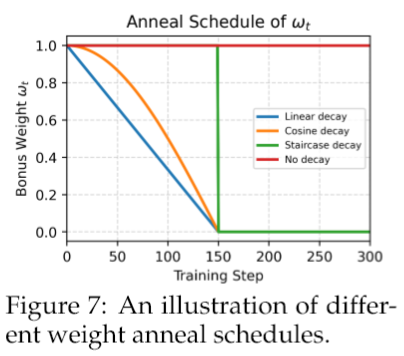
结果说明了两点:衰减是必须的。所有带衰减的方案都比不衰减的基线要好,这说明从探索到利用的平滑过渡至关重要。早期的强力探索是王道。“阶梯式”衰减方案被证明是效果最好的。它的策略是,在训练早期,保持一个很高的探索奖励,让模型尽情地“浪”,扩大认知边界;然后,在某个时间点,突然把这个奖励拿掉,让模型安下心来,稳定地收敛。相比之下,线性和余弦这种“温柔”的衰减方式,过早地削弱了探索信号,反而限制了模型的最终潜力。
从策略熵的动态变化也能印证这一点。基线GRPO的熵会急剧下降,这就是“熵崩溃”。而加上了PPL奖励后,熵的下降明显被缓解了,说明模型保持了更长时间的探索活力。在不同的衰减方案里,不衰减的PPL奖励让熵一直剧烈波动,模型始终无法稳定下来;而阶梯式衰减则产生了一条更平稳、更健康的熵轨迹。
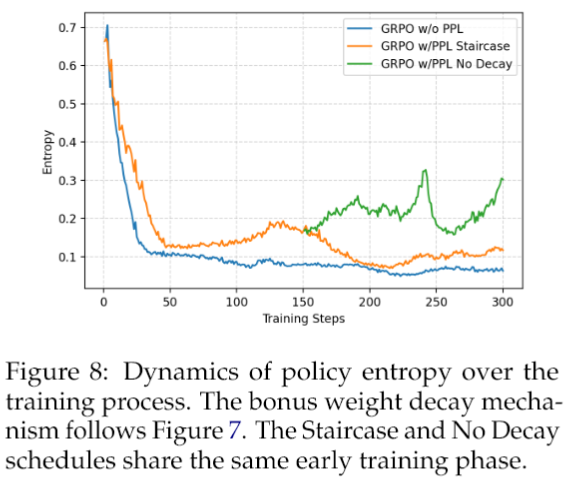
最让人惊喜的发现,是CDE框架有效解决了RLVR中一个隐藏很深的“校准崩溃”(Calibration Collapse)问题。
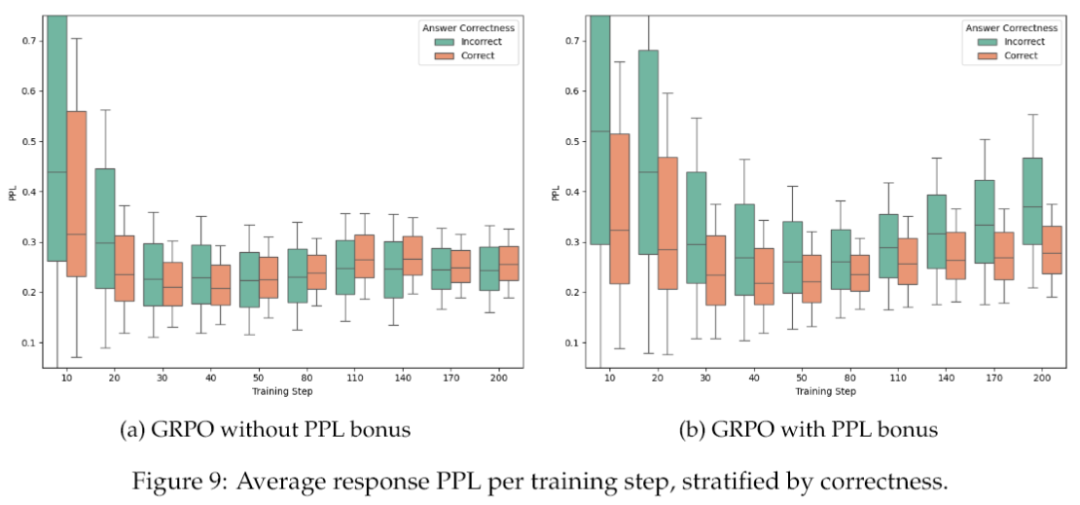
看上面这张图。左边(a)是普通的GRPO训练,你会发现在训练早期,正确答案的PPL(困惑度)比错误答案的要低(说明模型对正确答案更自信),这很正常。但随着训练的进行,这个差距竟然越来越小,最后甚至消失了——模型的自信程度,和答案的正确性脱钩了!这就是“校准崩溃”,模型变成了一个对自己错误答案也同样自信的“睁眼瞎”。而右边(b)是加了PPL奖励的GRPO,这种正确与错误答案PPL之间的分离度,在整个训练过程中都维持得非常好。
CDE打开的潘多拉魔盒
CDE框架的成功,绝不仅仅是在几个数学测试中刷高了分数那么简单。它更深远的影响在于,为大型语言模型的训练范式,乃至我们对AI学习方式的理解,都带来了全新的启示。
它直面并解决了“校准崩溃”这个棘手的问题。一个理想的AI,应该是“忠实”的——在它答对的时候,它应该表现出自信;在它答错的时候,它应该表现出谨慎。更好的校准能力,不仅能增强模型的可解释性,让使用者更信任它的输出,还能支持更多高级的推理时策略。
CDE利用模型自身的好奇心信号,四两拨千斤,既避免了巨大的计算开销,又达到了较好的效果。
研究团队指出,这个框架的原理是通用的,可以被应用到众多需要复杂推理和探索的领域。比如,在多模态推理中,CDE可以帮助模型在视觉、文本等不同模态的信息之间进行更有效的探索和关联。
未来的AI,或许不再需要我们手把手地去教,而是可以在“好奇心”的驱动下,像人类一样,主动地去探索和学习这个世界。
参考资料:
https://arxiv.org/abs/2509.09675
https://arxiv.org/abs/2501.12948
https://arxiv.org/abs/2402.03300
https://arxiv.org/abs/2505.22617
https://maa.org/math-competitions/aime
END

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









