





 本文提出一种基于词嵌入和用户信誉的论坛问答匹配算法,利用CBoW模型生成词向量,结合问题标题和描述的相似度计算,及用户信誉评估,提升重复问题识别效率。
本文提出一种基于词嵌入和用户信誉的论坛问答匹配算法,利用CBoW模型生成词向量,结合问题标题和描述的相似度计算,及用户信誉评估,提升重复问题识别效率。
摘要
- 社区问题的难点在于:重复性问题
- 解决上述问题要采用Query retrieval(QR),QR的难点在于:同义词汇
- 本文算法:1)采用continuous bag-of-words(CBoW)模型对词(word)进行 Distributed Representations(分布式表达,词嵌入);2)对given query和存档的query计算tile域和description域的相似度;3)将用户信誉(user reputation)也用于排序模型
- 测试数据集为 Asus's Republic of Gamers (ROG) 论坛
引言
QR的难点在于同于词汇,处理同义词的方法有四种:
- Language model information retrieval (LMIR):思想为计算给定问题和候选问题间词序列的概率
- language model with category smoothing (LMC):将问题类别表示为向量空间的一个维度(上述两种方法的缺点为:忽略了词与词之间的相似度)
- translation-based language modeling (TBLM):使用QA对来学习语义相关的单词以改进传统的IR模型,缺点是学习一个翻译表太耗时
- distributed-representation-based language modeling (DRLM) :使用数据的分布式表示来替换TBLM中的词到词间的翻译概率,其使用word2vector计算概率
本文算法
本文算法包含三部分:1)词嵌入学习:给定论坛数据集,问题被视为基本单位, 问题中的每个单词都会转换为一个单词向量。
2)得分生成:学习到单词向量后,就可以通过计算查询问题和候选问题之间的相似性来进行问题检索。
3)使用信誉信息:通过引入每个存档问题参与者的信誉值来加强排序函数。
1.Word2vec
word2vec的理解可以参看博客[NLP] 秒懂词向量Word2vec的本质,研究表明CBoW模型在文本分类方面表现更好,特别适用于包含极少数不常见单词的文档,而且该模型的训练速度快于 skip-gram模型,因此本文采用CBoW进行词向量学习。
2.问题标题和描述的排序函数
利用word2vec学习到词向量后,每个问题q的向量表达式如下:
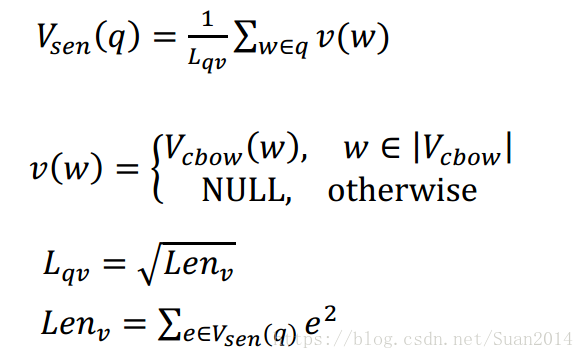
其中w为q中的每个词,e是向量中每个维度的值。查询问题q和候选答案Q间的相似度得分为:
![]()
论坛问题包含两部分:title和description,不同于之前的研究,本文分别计算这两部分的相似度得分:
![]()
α和β都是超参数,α+β=1
3.使用论坛中的用户信誉
查询问题q和候选问题Q间的相似度得分表达为:
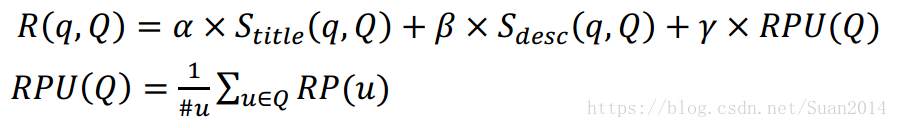
![]() 为超参数,
为超参数,![]() ,RPU(Q)是参与Q讨论的用户信誉值总和,为避免来自同一论坛用户的过多信誉值,只添加一次每个参与者的信誉值,为确保新帖的公平性,求信誉值的均值。
,RPU(Q)是参与Q讨论的用户信誉值总和,为避免来自同一论坛用户的过多信誉值,只添加一次每个参与者的信誉值,为确保新帖的公平性,求信誉值的均值。
实验
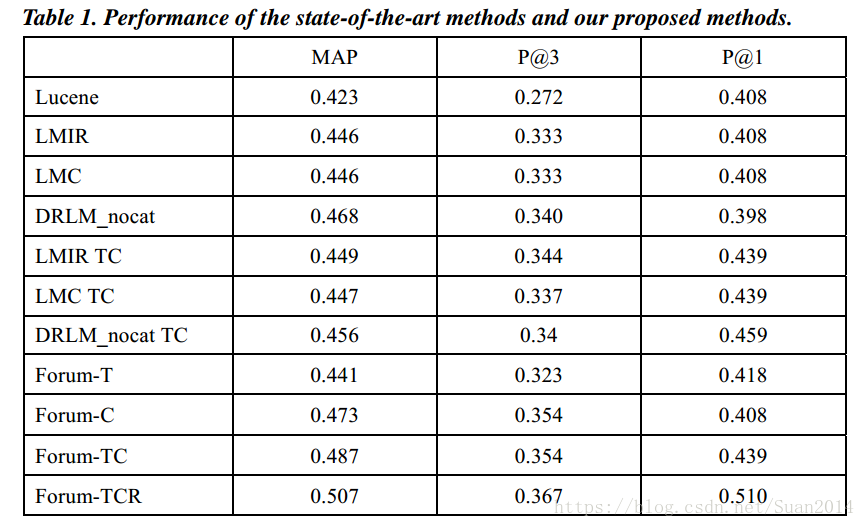
Forum为本文算法,-T考虑问题title的相似度,-C考虑问题description的相似度,-R考虑用户信誉值的相似度,上表可以看出本文算法优于其他算法。
下表为超参数的最优值:
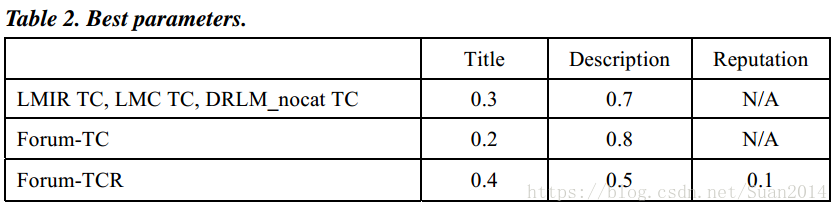
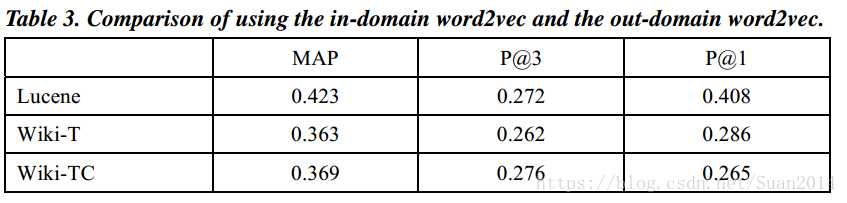
Wiki表示采用Wiki训练数据,Table3表明Wiki表现最差,这表明对于word2vec的训练,域内数据比域外培训数据更有效。


















 1800
1800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











