




 本文详细解析了WordCount案例的实现过程,包括输入、拆分、映射、洗牌、归约等步骤,并通过SQL示例说明了map、reduce的功能。
本文详细解析了WordCount案例的实现过程,包括输入、拆分、映射、洗牌、归约等步骤,并通过SQL示例说明了map、reduce的功能。
文章预览:
1.wordcount案例的过程分析
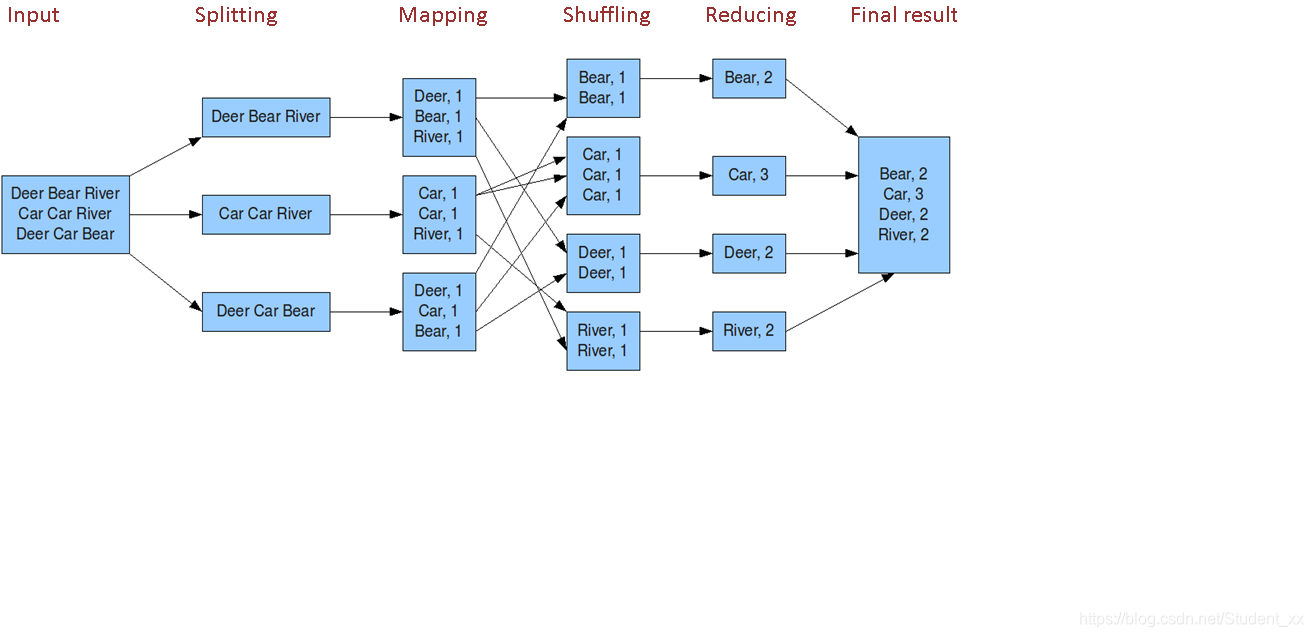
如上图,假设此文件大小为300MB,我们要对这个文件中的单词出现的频次进行统计,这个过程称之为wordcount,下面描述一下这个wordcount的过程:
1.Input
Input阶段是对这个文件原封不动的读取进来。
2.Splitting
Splitting阶段是对这个文件进行拆分,正常的block块默认大小是128M,而这个文件是300M,300/128=2…4,那么这个文件如上图会被拆分成3个块,对应的三个块大小是:128M、128M、44M。
3.Mapping
Mapping阶段是对上一步分好的块每个块都跑一个task任务,这个任务的目的就是将数据转换成(key,value)的格式。key为出现的单词,value是1。
4.Shuffling
Shuffling阶段是通过网络IO,将相同的key拉到一起。
5.Reducing
Redcing阶段主要是对每个相同的key进行求和,生成的数据格式还是(key,value)的格式,key为单词,value是这个单词出现的次数。
6.Final Result
最后一个阶段是将上部的结果汇总写到一个文件中。
2.map、shuffle、reduce过程解析
1.map
map就是映射,指的是一组数据按照规则映射为一组,即按照一定的规则进行映射,比如:a b c 映射为:(a,1) (b,1) (a,1)
用SQL来表示此过程:如果表数据如下的话:
| name |
|---|
| a |
| b |
| a |
| c |
那么:map过程就像此SQL表示的逻辑:
select name+‘x’ from t;结果如下:
| name |
|---|
| ax |
| bx |
| ax |
| cx |
2.reduce
reduce就是规约、汇总。即像SQL中的group by做汇总。 接上步映射结果(a,1) (b,1) (a,1),此步reduce的结果为:(a,2) (b,1)。
用SQL来表示此过程,如果表数据如下的话:
| name |
|---|
| a |
| b |
| a |
| c |
那么reduce过程就像此SQL的逻辑:
select name,count(name) from
(
select id,name+‘x’ from t
)group by name;
| name | count(name) |
|---|---|
| ax | 2 |
| bx | 1 |
| cx | 1 |
3.shuffle
洗牌,就是根据key进行网络传输拉到一起,按规则计算:
例如:想要统计name=a出现的次数,则就需要将两台机器中name=a的key通过网络传输拉到一起,很消耗网络IO
ruozedata001机器 :
name=a #假设100万条
name=b #假设10万条
ruozedata002机器 :
name=a #假设1万条
name=c #假设10万条
能不做shuffle就不要做shuffle

















 585
585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









