




 本文介绍了一种使用Python抓取特定网站图片的方法,通过解析网页结构定位图片链接,并实现自动下载。文章还提供了如何处理页面翻页及使用代理IP避免被封禁的建议。
本文介绍了一种使用Python抓取特定网站图片的方法,通过解析网页结构定位图片链接,并实现自动下载。文章还提供了如何处理页面翻页及使用代理IP避免被封禁的建议。
学习笔记:这个案例主要用于抓取妹子图片
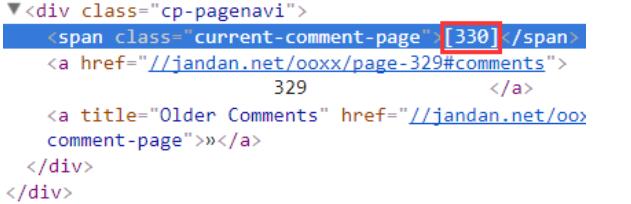
当我们切换图片时,会发现地址栏里面只有页码数在发生变化,其他的都没有改变

我们通过审查元素可以看到,最新的页码其实是保存在一个span标签里面的,我们可以通过它的class属性去获取最新的页面
我们先来抓取前十页的图片
import urllib.request # 访问网页必须用到这个
import os
def url_open(url):
req = urllib.request.Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36')
response = urllib.request.urlopen(req)
html = response.read()
return html
def get_page(url):
"""
:param url:
:return: 页码数【字符串类型】
"""
html = url_open(url).decode('utf-8')
# 加上偏移量
a = html.find('current-comment-page')+23
b = html.find(']', a)
return html[a:b]
def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = []
a = html.find('img src=')
while a != -1:
b = html.find('.gif', a, a+140)
if b != -1:
if html[a+9] != 'h':
img_addrs.append('http:' + html[a+9:b+4])
else:
img_addrs.append(html[a+9:b+4])
else:
b = a + 9
a = html.find('img src=', b)
return img_addrs
def save_imgs(folder, img_addrs):
for each in img_addrs:
# 通过/切分字符串,获取图片名称
filename = each.split('/')[-1]
# 写入文件夹
with open(filename, 'wb') as f:
img = url_open(each)
f.write(img)
def download_mm(folder='OOXX', pages=10):
"""
:param folder: 文件夹名称
:param pages: 下载页数
:return:
"""
os.mkdir(folder) # 创建一个文件夹
os.chdir(folder) # 改变目录,后面保存的图片就会直接保存进去
url = 'http://jandan.net/ooxx/'
# 获取最新页数
page_num = int(get_page(url))
# 遍历前十页
for i in range(pages):
page_num -= i
page_url = url+'page-'+str(page_num)+'#comments'
img_addrs = find_imgs(page_url)
save_imgs(folder, img_addrs)
if __name__ == '__main__':
download_mm()执行这段代码,我们就能从自己创建的文件夹里面找到我们抓取到的图片,除此之外为了避免ip的频繁访问而导致的一些问题,我们还可以通过上节的内容,使用代理ip来进行处理。

















 3254
3254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









