




 本文介绍了一种Scrapy爬虫管道的封装方法,包括如何通过连接池操作数据库,实现异步插入数据。该方法简化了数据处理流程,提高了爬虫效率。
本文介绍了一种Scrapy爬虫管道的封装方法,包括如何通过连接池操作数据库,实现异步插入数据。该方法简化了数据处理流程,提高了爬虫效率。
正常scrapy爬虫管道数据处理1

这种方式
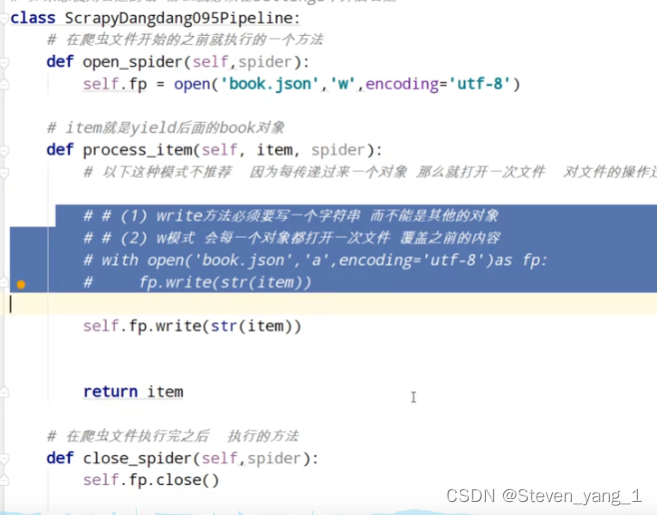
封装管道
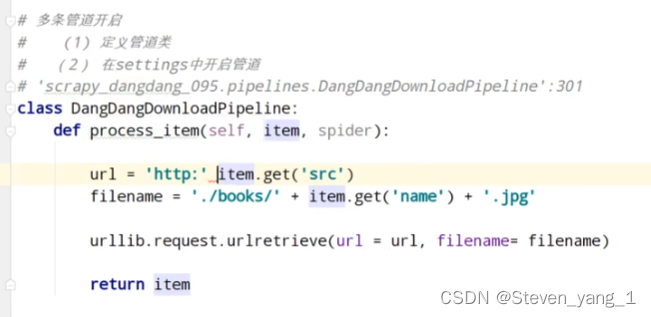
![]()
多页相同的html抓取,允许只需要填写域名即可,返回原爬虫即可抓取

多层页面抓取

直接运行测试反扒
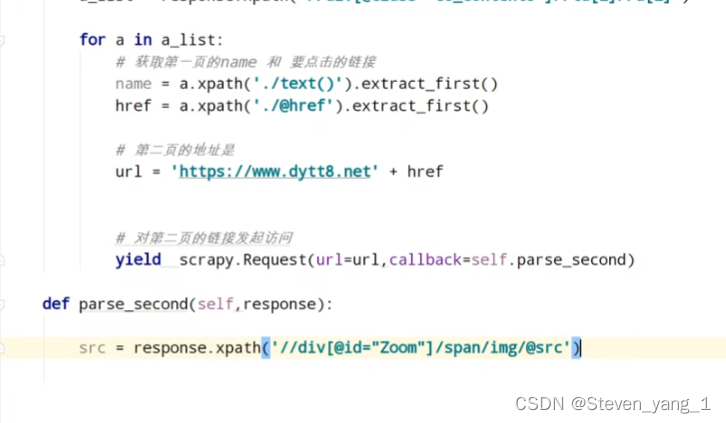 第二页的数据 SPAN标签识别不了,meta传递
第二页的数据 SPAN标签识别不了,meta传递
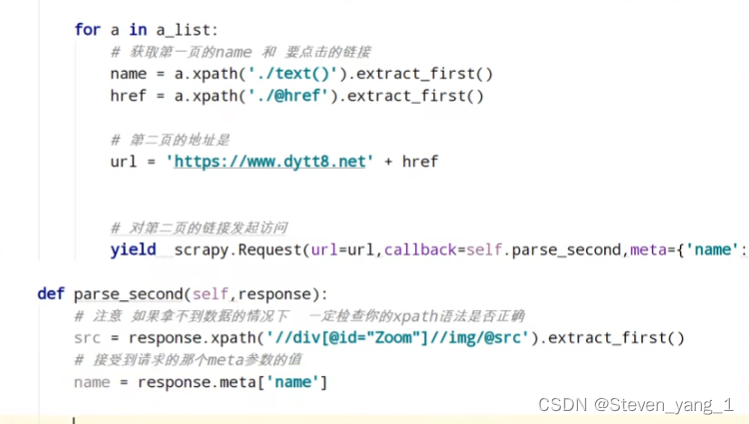
item传递
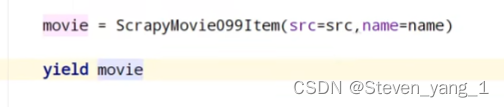
管道开始
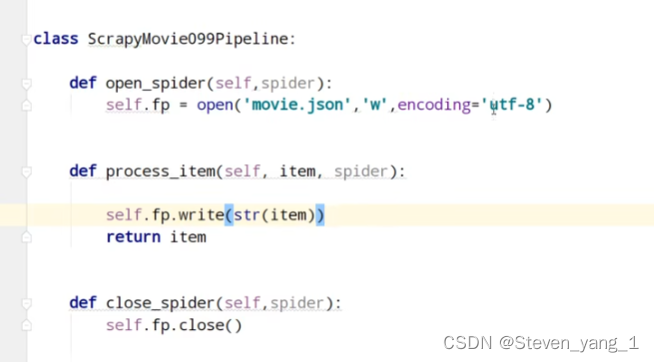 。
。
异步爬虫管道封装2
class RankxsPipeline(object):
# 初始化函数
def __init__(self, db_pool):
self.db_pool = db_pool
# 从settings配置文件中读取参数
@classmethod
def from_settings(cls, settings):
# 用一个db_params接收连接数据库的参数
db_params = dict(
host=settings['MYSQL_HOST'],
user=settings['MYSQL_USER'],
password=settings['MYSQL_PASSWORD'],
port=settings['MYSQL_PORT'],
database=settings['MYSQL_DBNAME'],
charset=settings['MYSQL_CHARSET'],
use_unicode=True,
# 设置游标类型
cursorclass=cursors.DictCursor
)
# 创建连接池
db_pool = adbapi.ConnectionPool('pymysql', **db_params)
# 返回一个pipeline对象
return cls(db_pool)
# 处理item函数
def process_item(self, item, spider):
# 把要执行的sql放入连接池
self.db_pool.runInteraction(self.insert_into, item)
# # 如果sql执行发送错误,自动回调addErrBack()函数
# 返回Item
return item
# 处理sql函数
def insert_into(self, cursor, item):
# 创建sql语句
sql = "insert into xiaoshuo(bookname,content,pic,typename) values(%s,%s,%s,%s)"
# 执行sql语句
cursor.execute(sql,(item['bookname'], item['content'], item['pic'], item['typename']))

















 1162
1162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









