




 本文汇总了Oracle数据库常见的错误及其解决方法,包括ORA-12505(监听器拒绝连接)、ORA-28001(密码过期)、ORA-00904(无效标识符)、ORU-10027(缓冲区溢出)、ORA-00060(死锁)和ORA-12519(无适当的服务处理器)。对于每个错误,详细解释了报错原因并提供了相应的解决策略,如检查和修改SID、更新密码策略、优化程序设计以及调整数据库连接数等。
本文汇总了Oracle数据库常见的错误及其解决方法,包括ORA-12505(监听器拒绝连接)、ORA-28001(密码过期)、ORA-00904(无效标识符)、ORU-10027(缓冲区溢出)、ORA-00060(死锁)和ORA-12519(无适当的服务处理器)。对于每个错误,详细解释了报错原因并提供了相应的解决策略,如检查和修改SID、更新密码策略、优化程序设计以及调整数据库连接数等。
Oracle报错及解决[持续更新]
1. ORA-12505
完整报错:
Listener refused the connection with the following error: ORA-12505,
TNS:listener does not currently know of SID given in connect descriptor
报错原因:
连接数据库时, 服务名/SID填写错误!
解决方法:
查询自己的真实SID, 修改连接时的SID定义, 重新连接即可 !
2. ORA-28001
完整报错:
[99999][28001] ORA-28001: the password has expired.
报错原因:
密码长时间未修改, 超过密码更新过期策略设置的过期时间
解决方法:
方法一: 使用sysdba 修改密码
方法二: 将密码过期策略中的过期时间设置为永不过期
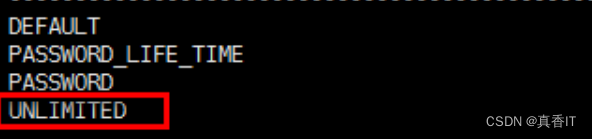
- 查看当前的过期时长 :180天
select * from dba_profiles where profile='DEFAULT' and resource_name='PASSWORD_LIFE_TIME';

- 修改过期策略
alter profile default limit password_life_time unlimited;
- 再次查看过期时长, 现在为永不失效
select * from dba_profiles where profile='DEFAULT' and resource_name='PASSWORD_LIFE_TIME';
4. 重新为用户设置密码, 如scott用户
alter user scott identified by tiger
3. ORA-00904
ORA-00904: invalid identifier标识符无效
一般是字段不存在, 或者是字段名写错了 !
4. ORU-10027
ORU-10027: buffer overflow, limit of 1000000 bytes
存储过程中打印输出的字符串过多, 导致内存缓存被占满!
5. ORA-00060
【死锁】ORA-00060: deadlock detected while waiting for resource
死锁存在的两个必要条件,一个是多任务工作的并发,另一个是共享资源的独占性需求。只要一个系统(广义系统)中存在这两个前提,我们就认为可能出现死锁的情况。
死锁描述的是一种状态。当两个或两个以上的任务单元在执行过程中,因为请求资源出现等待,因资源永远不能获得而相互等待的状态。如果没有外力的作用,死锁状态是会一直持续下去。死锁是伴随着多任务、并行操作产生的,在单任务情况下,一个任务单元可以使用并且独占所有资源,不存在资源等待的情况,所以也没有死锁的情况。在进入多任务系统环境下,多个任务之间存在资源共享和独占的需求,才可能出现死锁。
死锁最简单的例子:任务A,B,资源1,2。任务A独占了资源1,任务B独占了资源2。此时,任务A要资源2,向任务B提出请求并等待。任务B要求资源1,并且也等待。AB两者均不释放所占有的资源,就造成了死锁。
Oracle的锁机制是建立在行锁一级,在插入、更新行一级信息的时候,会加入独占锁内容。死锁是数据库经常发生的问题,数据库一般不会无缘无故产生死锁,死锁通常都是由于我们应用程序的设计本身造成的。
解决办法:
-- 方式1: 查询等待任务和提交
select * from dba_waiters;
commit;
-- 方式2: 查询死锁的会话进程,杀死死锁会话
select sid, serial#, username, command, lockwait, osuser from v$session where lockwait is not null;
-- 从查询结果中, 获取sid, 和 serial , 进行拼接, 在下面删除, 如果sid 为, 586, serial 为 19649, 拼接成 '586,19649'
alter system kill session '586,19649' ;
6. ORA-12519
ORA-12519: TNS:no appropriate service handler found
当前数据库连接数已满,没有可以提供的数据库连接服务。
--当前的连接数
select count(*) from v$process
--数据库允许的最大连接数
select value from v$parameter where name = 'processes'
解决方案:
- 1.修改数据库连接数,增加数据库允许连接服务的个数【不推荐】
- 2.修改程序,降低连接数的使用,如增大切片时的分片数据量的大小。【推荐】
持续更新中…!
欢迎大家留言一起讨论学习!


















 4385
4385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











