 深入理解Linux进程机制
深入理解Linux进程机制





1.进程引入
你手机里的「微信」、电脑上的「浏览器」,本质上是程序—— 就像一本 “菜谱”:写着要放什么料、按什么步骤做,但它只是 “静态的纸”,放在那里不会自己动。
而进程,是 “照着菜谱做饭的过程”: 比如你打开微信聊天,从点击微信图标(开始),到打字发消息(执行),再到关掉微信(结束)
—— 这整个 “正在运行微信” 的过程,就是一个进程。
简单说: 程序 = 菜谱(静态,存着不动);
进程 = 照着菜谱做饭(动态,有开始、有过程、有结束)。
再举个例子:你同时打开两个微信窗口(一个工作号、一个生活号),这就是 “一个程序(微信)对应两个进程(两个正在运行的微信)”
—— 就像一本菜谱,两个人同时照着做,两个做饭过程互不干扰。
进程的 3 个关键特点:用 “做饭” 类比
1. 有 “生命周期”:从 “准备” 到 “收拾”
准备阶段(新建):你拿出食材、洗好锅 —— 对应 OS(操作系统,比如 Windows、Linux)给程序分配内存、准备资源,刚启动还没开始 “干活”;
等着用灶台(就绪):食材切好了,就等灶台空出来 —— 对应进程已经准备好所有东西,就等 CPU(电脑的 “灶台”)来 “用它”;
正在炒菜(运行):你占着灶台炒青菜 —— 对应 CPU 正在执行这个进程的指令(比如微信正在处理你发的消息);
等着水开(阻塞):菜炒到一半,要等锅里的水烧开才能下一步 —— 对应进程暂时 “卡住”,比如浏览器加载网页时,要等网络响应,就算 CPU 空着也没法继续;
收拾洗碗(终止):饭做好、碗洗干净 —— 对应进程结束(比如关掉微信),OS 回收它用的内存、资源,这个 “做饭过程” 彻底消失。
2. 能 “同时干多件事”:不是 “等一个做完再做”
你家只有一个灶台(像电脑的单核 CPU),但可以 “一边煮水,一边切菜”—— 不是等水烧开再切菜,而是煮水时切菜,水快开了再回头看。
进程也是这样:比如你同时用浏览器看视频、用微信发消息,电脑不会 “等浏览器看完视频,再让微信干活”—— 而是 CPU 在两个进程间 “快速切换”(比如先给浏览器 0.01 秒处理视频画面,再给微信 0.01 秒处理消息),因为切换太快,你感觉不到 “卡顿”,以为它们在 “同时跑”—— 这就是进程的 “并发性”。
3. 各干各的,不抢东西(独立性)
你和家人同时做饭:你炒青菜用一个锅,家人煮汤用另一个锅,不会抢同一个锅铲(除非故意分享)。
进程也一样:每个进程都有自己的 “专属资源”—— 比如微信用的内存、浏览器用的缓存,互相不会随便 “抢”。
除非你主动操作(比如用微信把文件发给浏览器打开),否则两个进程就像 “各做各的饭”,互不干扰。
操作系统(OS):进程的 “管家”
家里做饭需要有人协调:谁先用灶台、谁等着、食材不够了找谁要 ——OS 就是进程的 “管家”,负责管 3 件事:
1.给每个进程发 “身份证”(PCB):记录这个进程是 “微信” 还是 “浏览器”、做到哪一步了、需要什么资源(比如要多少内存),就算进程暂时 “等水开”(阻塞),管家也不会忘了它的状态;
2.安排 “灶台”(CPU):比如先让 “浏览器” 用 CPU 加载网页,再让 “微信” 用 CPU 处理消息,避免 “抢灶台”;
3.收 “收尾工作”:进程结束后(比如关掉微信),管家会把它用的内存、缓存 “收拾干净”,避免浪费。
2.进程介绍
基本概念
描述进程-PCB
task_struct-PCB的一种
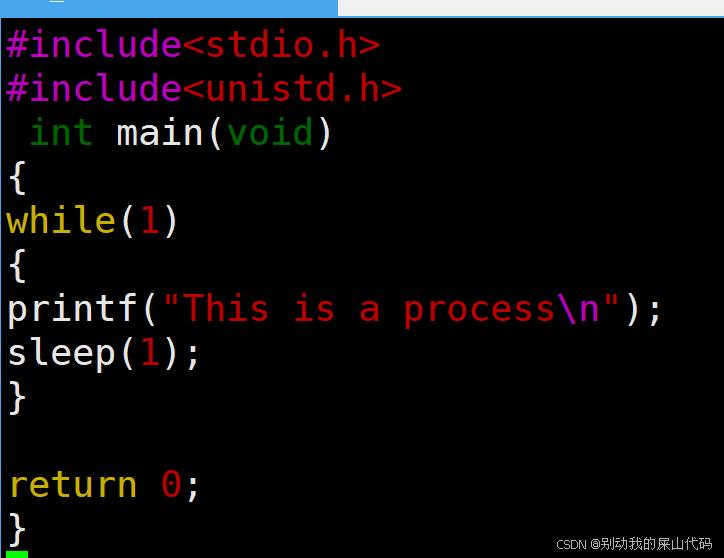
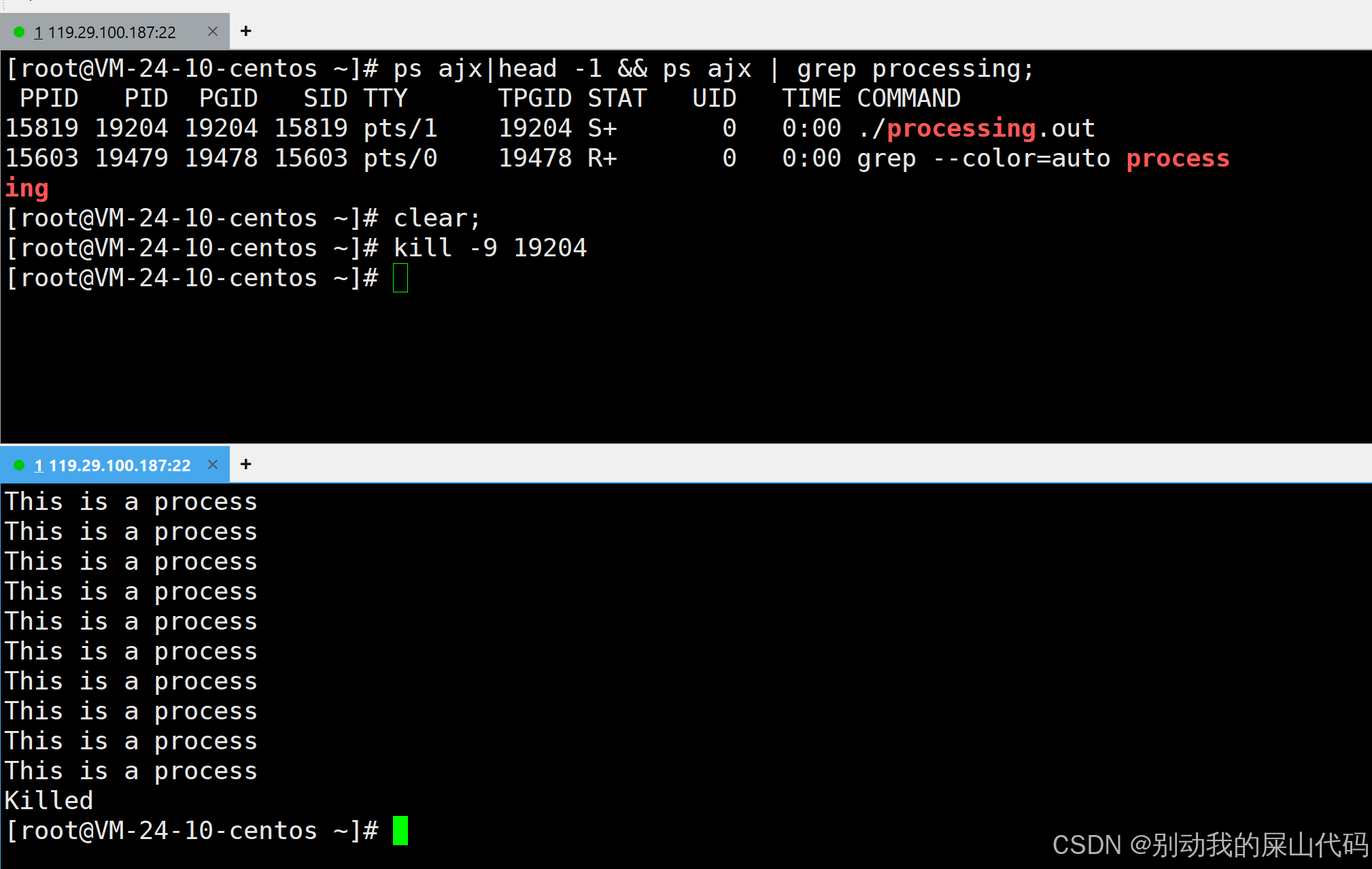
我们先让一个死循环的c程序跑起来
我们发现当我们程序跑起来的时候我们可以看到和processing有关的进程有两个
一个进程是正常执行processing.out文件
一个进程是grep

当是当我们ctrl c强制把这个c程序停下来 再查看和processing有关的进程
这个时候和processing有关的进程只有grep了
而且这个进程是一个新的进程
和之前那个grep的进程不一样
因为上次那个进程grep的PID和这次进程的PID不一样
同一个文件 每次执行都是一个新的进程
PID就是上面介绍的标示符

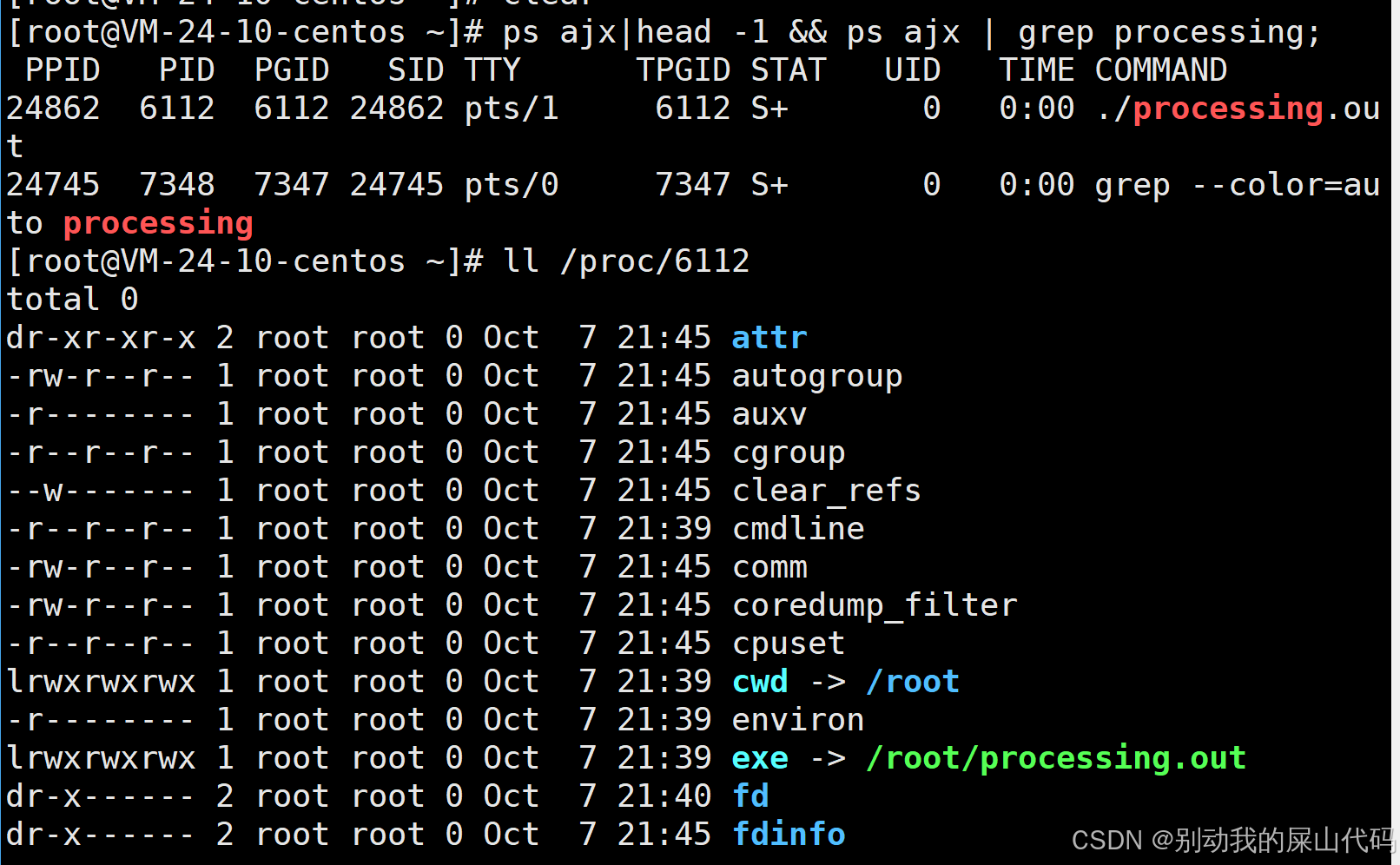
我们可以根据PID来查找我们的进程
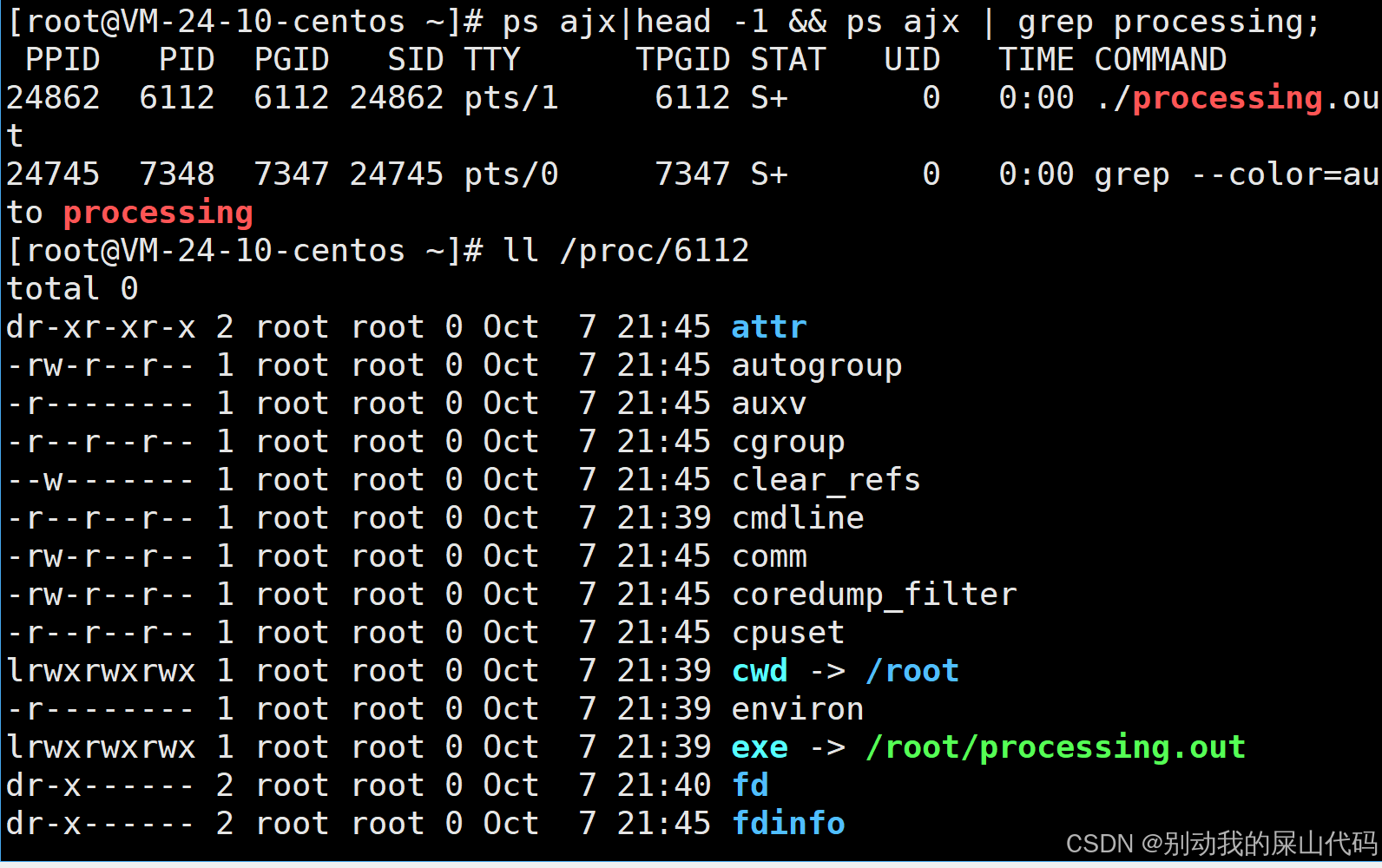
我们可以看到exe指向的 就是我们执行文件所在的位置
cwd 全称是current work director 就是告诉你我们是在哪个路径下执行的processing.out这个文件的

3.杀死进程
当我们运行了一个死循环的代码
我们除了可以ctrl c 强制退出这个进程
还可以通过通过杀死进程来实现退出
kill -9 进程的PID
4.getpid和getppid
需要包含头文件
#include <sys/types.h>
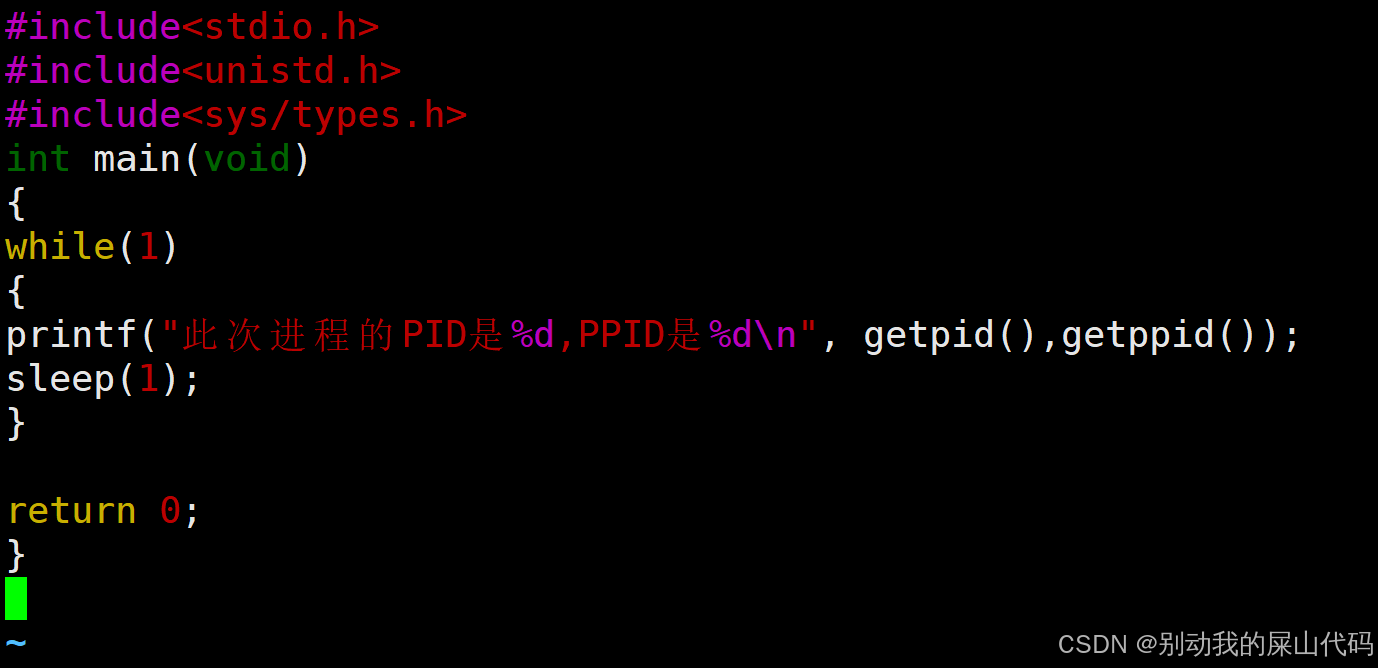
getpid可以查看我们当前程序进程的PID
getppid可以查看我们当前程序进程的PPID 也就是父进程的PID
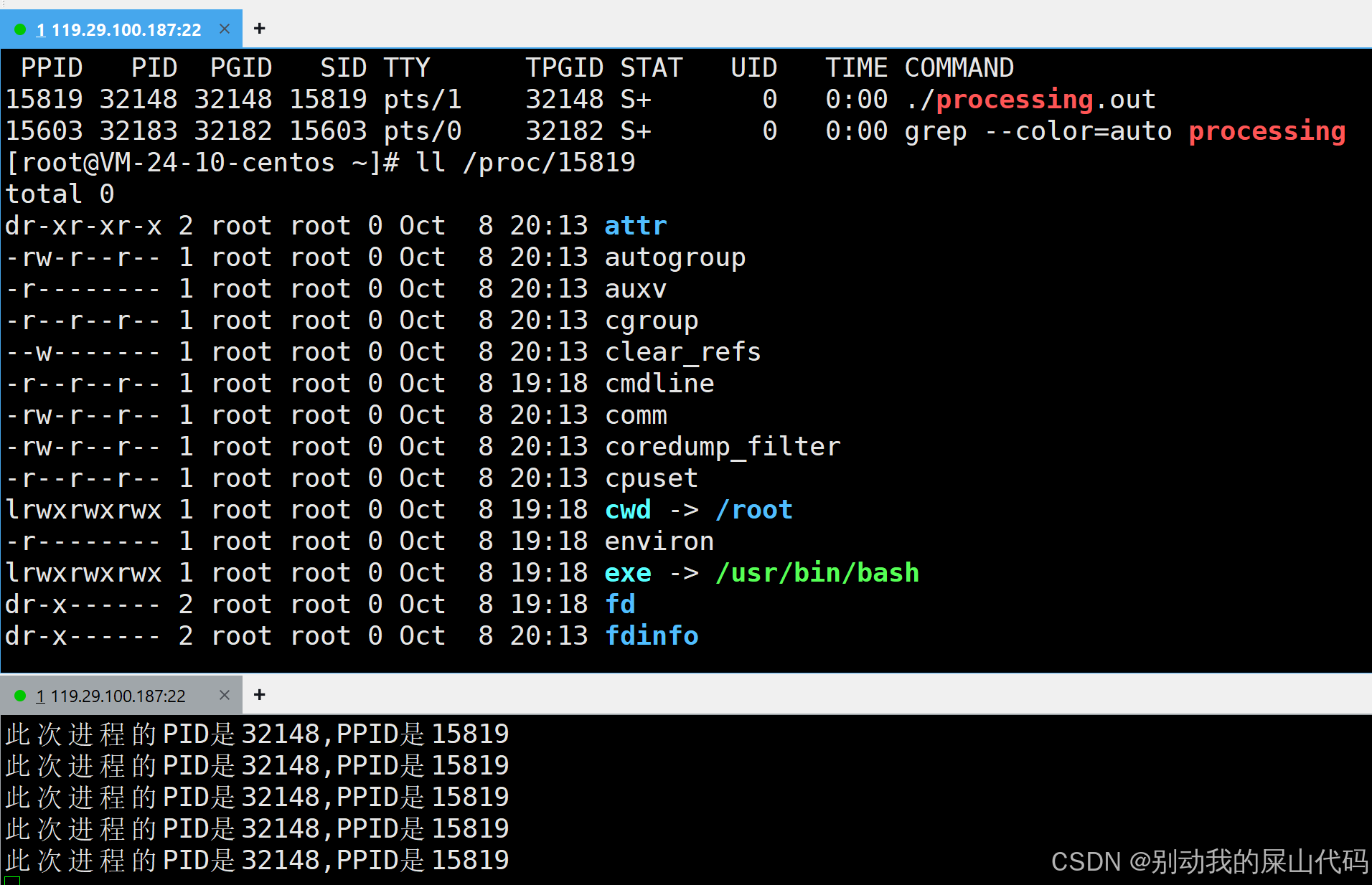
同时我们还发现我们运行的这个程序的父进程是bash
我们每次登录shell 都会创建一个bash进程
5.fork
fork 是系统调用,核心作用是创建新进程(子进程)
对于子进程返回0 对于父进程返回子进程的PID
我们先来看一串代码
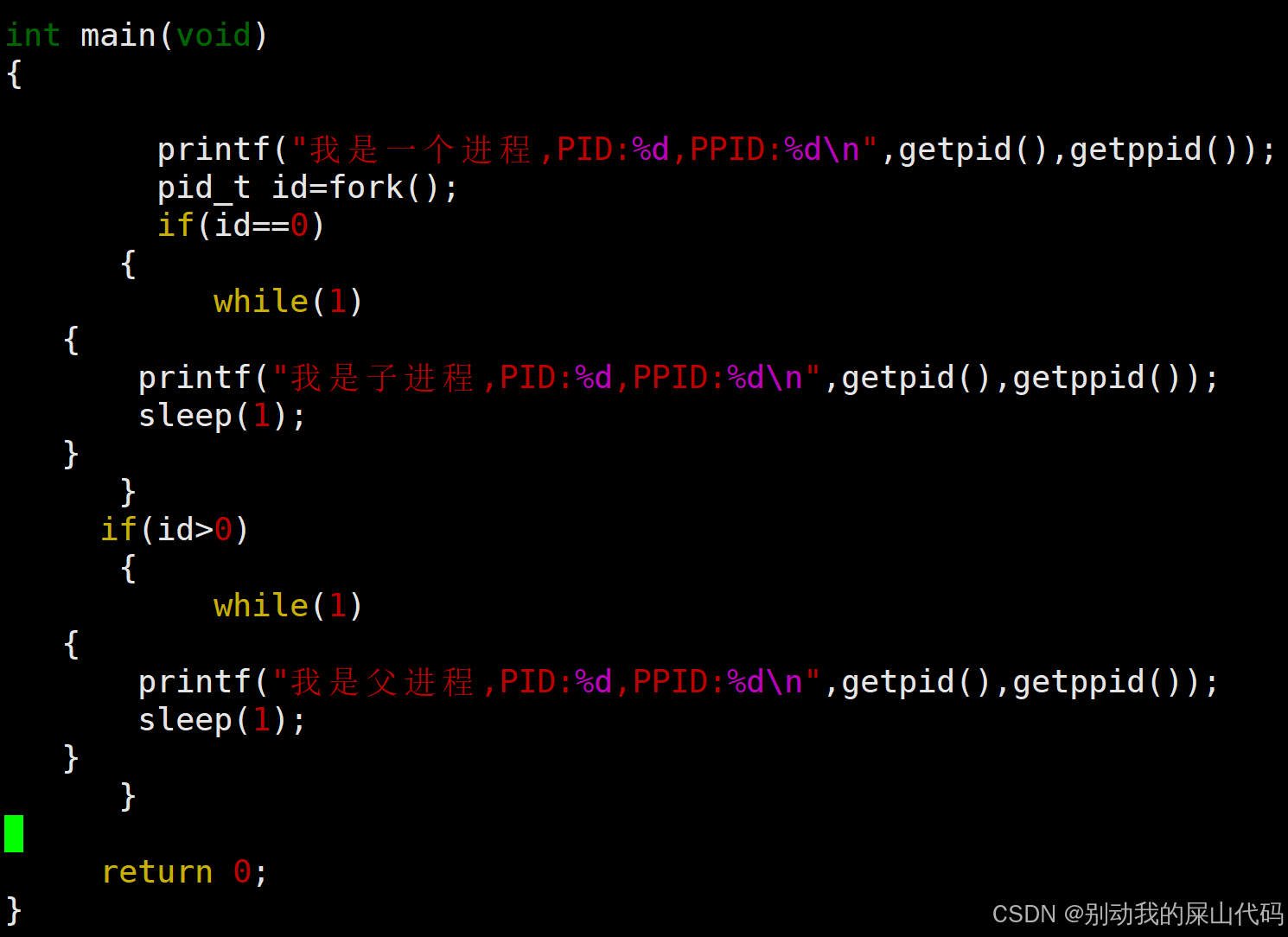
运行这个代码我们发现一件很神奇的事情、
就是我们id==0和id>0同时满足了!!! 为什么???
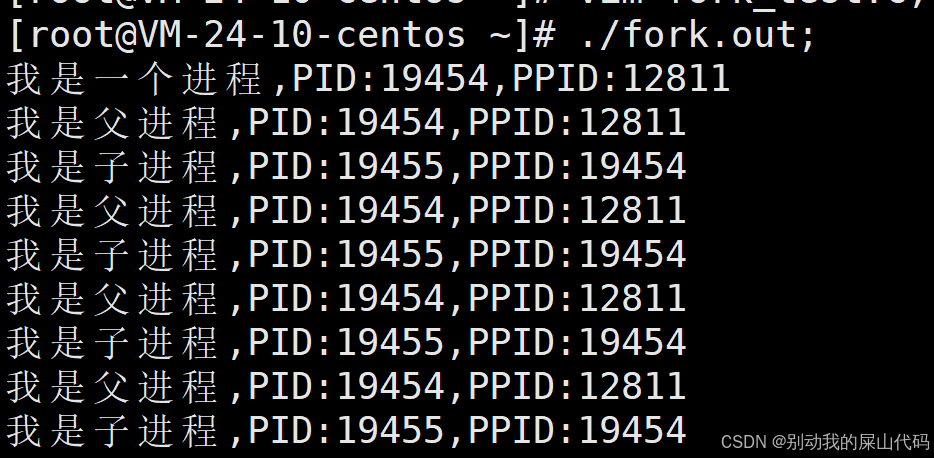
我们有三个问题???
1.为什么对于父进程返回子进程的PID 对于父进程返子进程的PID???
2.fork函数是怎么做到两个返回值的???
3.为什么返回值id为什么可以是两个值呢???
第一个问题的回答很简单
一个子进程只有一个父进程 很好找到
但是一个父进程可以有多个子进程
如果不给父进程返回子进程的PID 父进程怎么找到这个创建的子进程呢???
第二个问题
我们要先思考 就是父进程有它的代码和数据
那么新建的子进程呢???
我们先要了解一件事 就是进程是独立的
一个进程的运行不会影响另一个进程
新的子进程和父进程共享代码
因为进程运行中 是对代码的运行 无法对代码进行修改
不会影响进程的独立性
所以说父进程和子进程完全可以共享一份代码不会出问题
所以子进程就没必要再生成一份代码
可以类比理解成浅拷贝
新的进程如果要使用数据要单独拷贝一份
如果父子进程共享数据 那么父进程更改数据会影响子进程
这就破坏了独立性
但是并不是每个子进程都会使用数据
如果每个子进程都拷贝一个数据 太浪费了内存了
所以当子进程需要数据的时候 才会把父进程的数据拷贝一份
可以类比理解成深拷贝
当fork函数return的时候 我们的数据子进程已经创建好了
id本质上是接收fork的返回值
本质上是对子进程和父进程的数据进行写入
所以这个时候子进程要把父进程的数据拷贝一份做修改
所以本质上id接收fork的返回值接收了两份
一份来自父进程 一份来自子进程
第三个问题在地址空间的时候会得到解决

















 24万+
24万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









