



 COIG-PC是智源研究院发布的首个大规模、可商用的中文指令数据集,旨在提升大语言模型在中文处理上的能力。该数据集整合了众多开源数据,支持多任务指令,且注重数据质量与合规性。星尘数据深度参与了该项目,并提供了COSMO大模型数据金字塔解决方案,以提升模型性能。此数据集解决了中文数据获取、标注、质量和模型迭代的挑战,为中文NLP领域带来新机遇。
COIG-PC是智源研究院发布的首个大规模、可商用的中文指令数据集,旨在提升大语言模型在中文处理上的能力。该数据集整合了众多开源数据,支持多任务指令,且注重数据质量与合规性。星尘数据深度参与了该项目,并提供了COSMO大模型数据金字塔解决方案,以提升模型性能。此数据集解决了中文数据获取、标注、质量和模型迭代的挑战,为中文NLP领域带来新机遇。
各位AI研究者及开发者,
“千模大军”们,
是否一直在寻找高质量的中文语料库?
星尘君告诉您一个好消息!
📢📢📢
6月9日,
在第五届智源大会上,
智源研究院院长黄铁军
公布国内首个大规模、可商用的
中文指令数据COIG最新进展!
COIG第2期Prompt Collection:
最大规模、持续更新的
中文多任务指令数据集来了!


COIG第2期Prompt Collection
整合海量开源数据,
当前已发布来自348个源数据集的
949个指令任务文件,
未来将持续更新。
目前,COIG-PC第一版已开源,
星尘数据深度参与了本项目的搭建!

与其他中文指令数据集相比,COIG-PC覆盖了绝大多数的传统自然语言处理场景,支持商用许可,且支持根据需要自行采样,还有对不同指令的细粒度类型与领域说明。
项目团队正积极工作,预计将整合超过1800个开源数据集,并通过人工改写,精心整理近4亿条指令数据,并提供完善的数据筛选、版本控制工具,方便研究使用。
开源地址:
https://huggingface.co/datasets/BAAI/COIG-PC
一、中文数据为何难?
1、获取数据难
数据是大模型训练的基础,但获取大模型训练所需的预训练、SFT、 RLHF 、CoT、多轮对话等数据集是一项挑战。尤其对于某些特定的领域和主题,相关数据可能非常稀缺,获取成本极高,训练的模型效果不能保证。此外,数据的获取还涉及到许多法律和伦理问题,如用户隐私保护和数据所有权等。
2、标注数据难
大模型数据标注不同于过往的AI数据标注,数据需求量大,原始数据来源广、子任务多。不仅需要更加专业的标注团队来进行任务类型的设计、规范;还需要本科以上的、具备专业语言理解能力和写作能力的标注人员对数据进行标注、编写;更需要专业的NLP专家对中文语境的难例、特例进行细节和质量的把控,能够有效反馈模型训练。
3、质量保证难
数据的质量直接影响到模型的性能,但确保大模型数据的质量是一项挑战。大模型数据需要保证3H原则,即Helpful、Honest、Harmless。不仅需要确保数据多样性、有用性和无害性,还需要避免主观性和幻觉,脱离政治敏感、种族歧视等敏感内容。
4、模型迭代难
大模型风口期短,数据要求快、准、实时更新。想要提高大模型训练的效果,需要数据侧动态反馈,不断磨合,由专业NLP团队和数据策略专家与算法互动,进行数据的更新和迭代。
二、什么是COIG-PC?
COIG-PC数据集是智源研究院联合北京大学、香港科技大学、滑铁卢大学、谢菲尔德大学、北京邮电大学、M-A-P Community,星尘数据等精心策划和全面收集的中文任务和数据集,旨在提供丰富的资源,以提高大语言模型文本生成、信息提取、情感分析、机器翻译等能力,促进中文大语言模型的微调和优化。
COIG-PC采用类似FLAN Collection的Instruction数据收集流程:通过对来源于互联网的传统NLP数据集进行改写,高质量地建模NLP常规指令,并进行精心开发与优化。研究者和开发人员可在遵守各原始数据集使用规则前提下,基于学习、研究、商业等目的使用。
三、四大优势,直面大模型时代中文数据难题
数据体系的搭建是模型训练的基础,数据集的质量直接影响模型的性能。当前,大模型中文语料稀缺,COIG-PC将成为中文NLP领域的宝贵资源:
1、解决复杂中文问题:作为一种拥有海量汉字和多样语法结构的语言,中文因其错综复杂的特性和丰富多样的字符及语法结构而闻名,这种复杂性让模型训练显得极其困难。COIG-PC数据集作为专为中文量身打造的资源,将有效提高模型应对复杂中文的能力。
2、全面的数据整合:COIG-PC搜集了上千个原始中文NLP开源数据集,集成了市场上几乎所有可用的中文数据集,构造了中文社区最大的开源指令微调数据集,希望缓解LLM时代中文社区的数据难题。
3、数据去重和规范化:COIG-PC非常注重数据的质量,经过严格的人工处理以消除重复数据,确保数据集没有冗余。此外,联合来自二十多个机构近百位工程师进行数据规范化,保证数据结构良好。这种方式不仅使模型训练更高效,也可以保证模型训练的结果更加准确。
4、微调和优化:COIG-PC对数据集进行了指令优化,这一结构可以帮助模型更好地理解和执行任务,可进一步提高模型在未知任务和领域的表现。
通过全面聚合、精心筛选、去重和数据标准化,COIG-PC将有效促进中文大语言模型的发展,为中文NLP领域带来新的可能性和机遇。
四、星尘COSMO大模型数据金字塔解决方案
数据体系的搭建和数据集的质量决定了模型的上限。 数据能够赋予AI理解世界的能力,让AI拥有人类般的思维和逻辑,可以塑造其价值观,使其明辨善恶,同时保证其输出内容健康、无害,最终通往AGI。达到以上效果,一个完整的、结构化的、多元化的、包罗万象的数据体系尤为重要。
除了参与COIG第2期的搭建,今年6月,星尘数据还发布了COSMO大模型数据金字塔解决方案,以四层金字塔式数据结构,为您搭建起一站式数据解决方案,全方位提升模型性能。

1、让数据解锁AI2.0的无限可能
-
0层 :公共数据
作为大模型预训练的基础,提供大量经过清洗和加工的公共数据集,打造大模型的知识体系和世界观。
-
1层:通用能力数据
为大模型微调提供高质量的数据,包括SFT、RLHF数据集以及涵盖语文、数学、化学、多轮对话等领域的难例数据,弥补公共数据的不足。
-
2层:专有能力数据
针对特定领域和应用场景,我们提供了丰富的专有能力数据集。如:思维链、插件调用能力、社会主义价值观对齐、行业专业词汇等,这些专有能力数据集将帮助模型实现更精准的定位和更高效的性能表现。
-
3层:企业私有化部署数据
面向各行各业的企业和单位,提供可进行私有化部署的私域数据集搭建服务,以满足定制化需求和内部知识库的构建。
2、星尘独家优势
-
卓越的行业经验
庞大的标注人力网络:我们汇集了大量优秀的本科生,确保为您提供高质量的数据标注服务。
经验丰富的项目经理:我们的项目经理具备丰富的行业经验,能够为您提供专业的项目管理和协调服务。
顶尖客户与前沿项目经验:我们与多家国内外知名企业合作,积累了前沿项目经验和行业know-how,能够为您提供最佳实践和解决方案。
-
强大的专家团队
NLP专家:我们的团队拥有多位自然语言处理领域的顶级专家,为您的AI项目提供专业的技术支持和指导。
数据策略专家:我们的数据策略专家具备丰富的行业知识和经验,能为您提供定制化的数据策略和解决方案。
-
高效的自动化产品工具
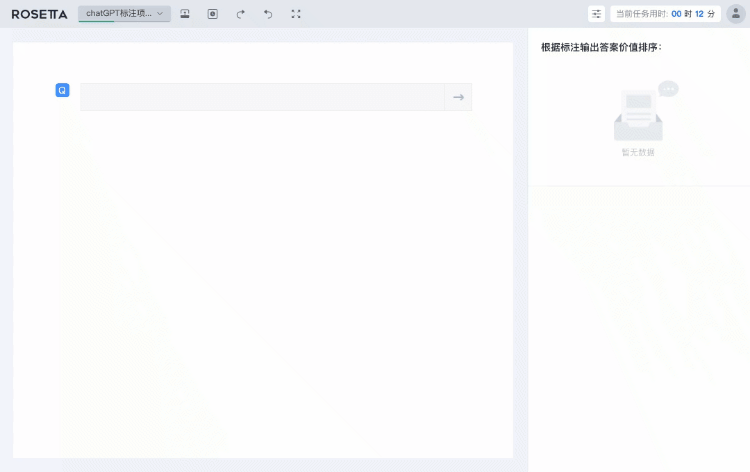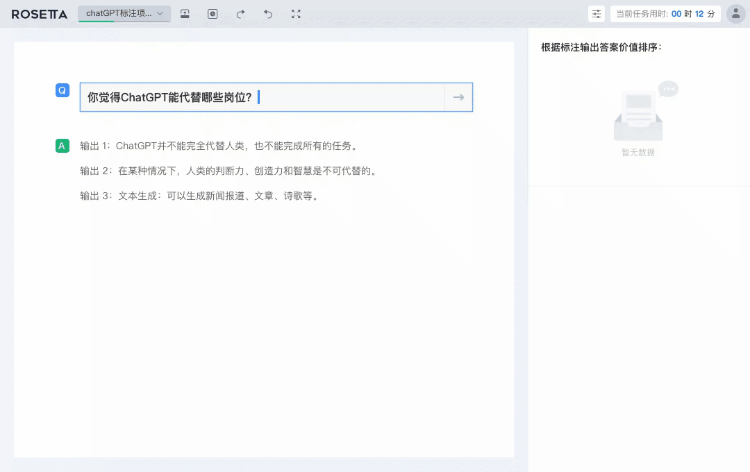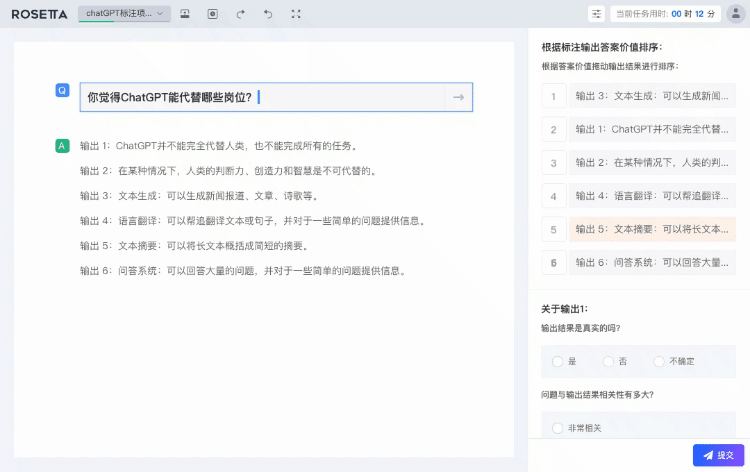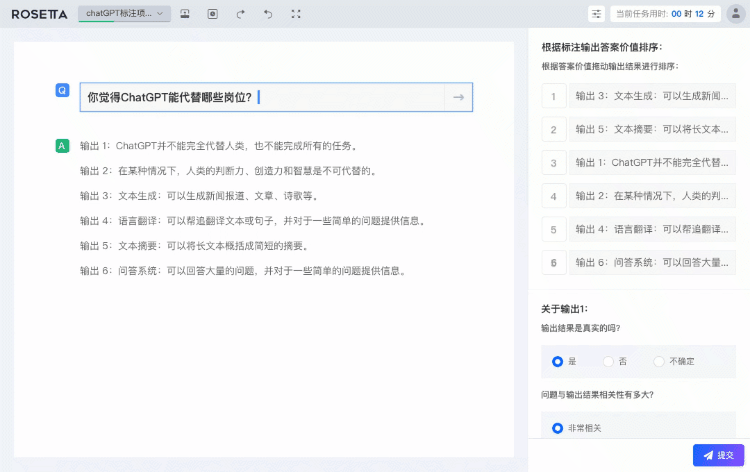
图:星尘数据Rosetta平台交互式数据标注服务(HFS)
数据处理流程编排:通过对数据处理流程的组织和安排,实现自定义配置工作流程,针对不同业务需求轻松获取各类数据。
算法辅助标注:结合预标注算法、辅助算法及质检算法,大幅提升数据标注和质检的效率与质量,确保用户能迅速获得高质量的数据集。
自动化任务调度:借助规则引擎与调度引擎,根据数据标注进度和质量进行动态任务调度,保证数据标注和质检工作始终保持在最高效水平。
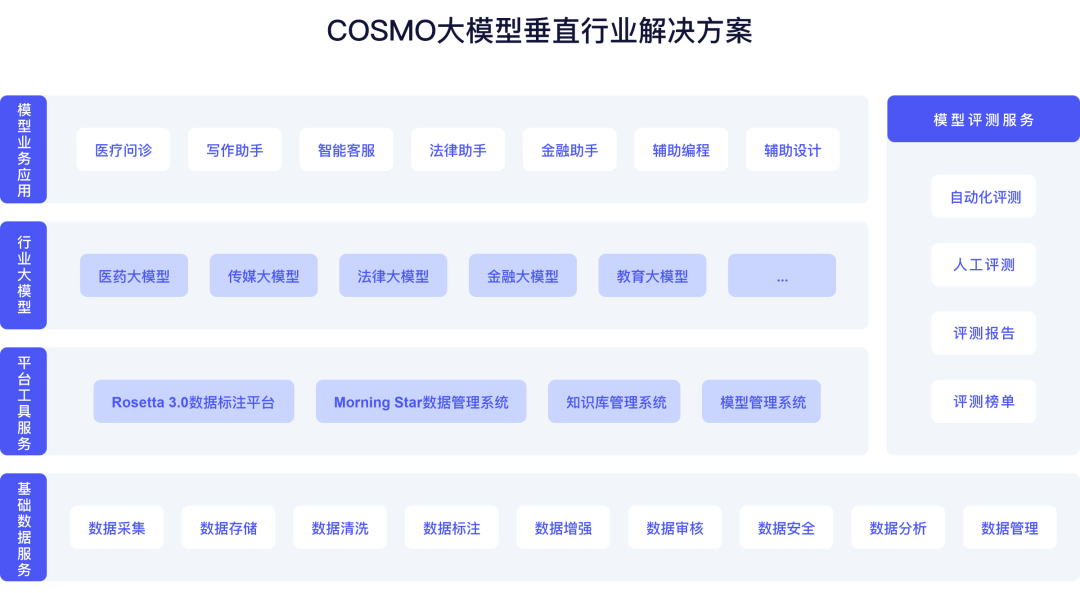
我们致力于基于领先的技术能力,为更多行业提供定制化的大模型解决方案,如医疗、法律、媒体、金融、教育、游戏等,期待与您共同创造行业智能化的未来。
星尘数据关注全球最前沿的趋势,拥有宏大的视野和业内最领先的经验,以期为您提供最优质的服务,为您打造最坚实的数据底座,助您解锁更高效的大模型训练!同时,星尘数据正在联合开源社区NLP专家共同打造中文大语言模型指令跟随Benchmark数据集,助力大模型发展,请大家拭目以待!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











