





作者:
-
张婧婧 腾旭微信数据科学家
-
熊吉祥 腾讯微信 OLAP 研发工程师、StarRocks Contributor
本文整理自微信工程师在 StarRocks 年度峰会上的分享,介绍了因果推断在业务中的应用,详细阐述了基于 StarRocks 构建因果推断分析工具的技术方案,通过高效算子的支持,大幅提升了计算效率。例如,t 检验在 6亿行数据上的执行时间仅需 1 秒。StarRocks 还实现了实时数据整合,支持多种数据源(如 Iceberg 和 Hive)的无缝访问,进一步增强了平台的灵活性与应用价值。
因果推断介绍
什么是因果推断?
因果推断的核心概念是,从数据中推断一个变量对另一个变量的影响程度。简单来说,它帮助我们了解因果关系的存在和影响力。例如,如果我们上线了一个新的算法模型,能否提升 DAU(日活跃用户)?又或者一个新的产品UI能否增加点击率?这些问题本质上是在问:我们当前所采取的措施是否有效?做得是否正确?因果推断正是用来回答这些问题的,它帮助我们做出科学的决策。
那么,为什么需要使用因果推断呢?难道产品经理或者算法专家不清楚我们当前的做法是否合适吗?实际上,这种不确定性是存在的。根据一项统计数据,全球一些领先互联网公司的“上线成功改动率”远低于预期。具体来说,这些公司在进行大量的 A/B 实验后,最终能带来有效成果的策略比例通常只有10%左右。像必应、Google Ads、Netflix 等公司都呈现出类似的情况[1]。这意味着,实际上即便是行业内的专家,也无法完全确定某一策略是否能够产生预期效果,原因在于他们并非对产品和用户有足够深入的理解。
接下来,有人可能会问,既然如此,为什么不直接通过一些数字进行策略效果评估?例如,进行环比或同比分析,看看某一策略上线后,今天和昨天、或者上个周六和这个周六的数据对比,是否能够反映出该策略的实际效果?然而,这种方式显然存在问题。因为数据本身存在波动、周期性,且受到外界因素的影响,单纯的对比并不足以准确归因于该策略本身的影响。
此外,我们也可以使用时序模型来预测 DAU 的变化。如果没有引入新的模型,我们可以通过旧有的推荐系统模型来预测 DAU 的变化。然而,在实际应用中,即便是预测 DAU 的误差小于1%,也已经算是一个相对精准的模型了。但随着增长的逐渐放缓,单个策略的效果通常难以超过1%,这意味着模型的误差往往比实际增长还要大,因此很难依赖现有的模型来精确评估单一策略的效果。这时,因果推断就显得尤为重要。
在互联网行业,因果推断的最常见应用之一就是 A/B 测试。
什么是 AB test ?
具体来说,A/B 测试的过程是:从所有用户中随机抽取两组同质的用户群体,其中一组用户使用原有的策略(A 组),另一组用户使用新策略(B 组)。接着,通过对比这两组用户在关键指标上的差异,例如点击率、停留时长等,来评估新策略的效果。通过这种方式,我们能够明确将指标差异归因于策略的变化。

一个经典的例子来自于谷歌的 Gmail 广告优化[2]。最初,谷歌在确定广告中蓝色小链接的颜色时,采用的是传统的方法,即由首席设计师或营销总监拍板决定选用哪种颜色。然而,随着 A/B 测试的引入,谷歌改变了这一做法。他们决定测试 40 种不同的蓝色,来找出哪个蓝色能获得最高的点击率。在实验中,每个颜色方案会被展示给 1% 的用户,经过对比测试,他们最终发现,一种带有轻微紫色调的蓝色,比带有绿色调的蓝色点击率更高。如此细微的调整,竟然为谷歌带来了每年增加2亿美元的广告收入。
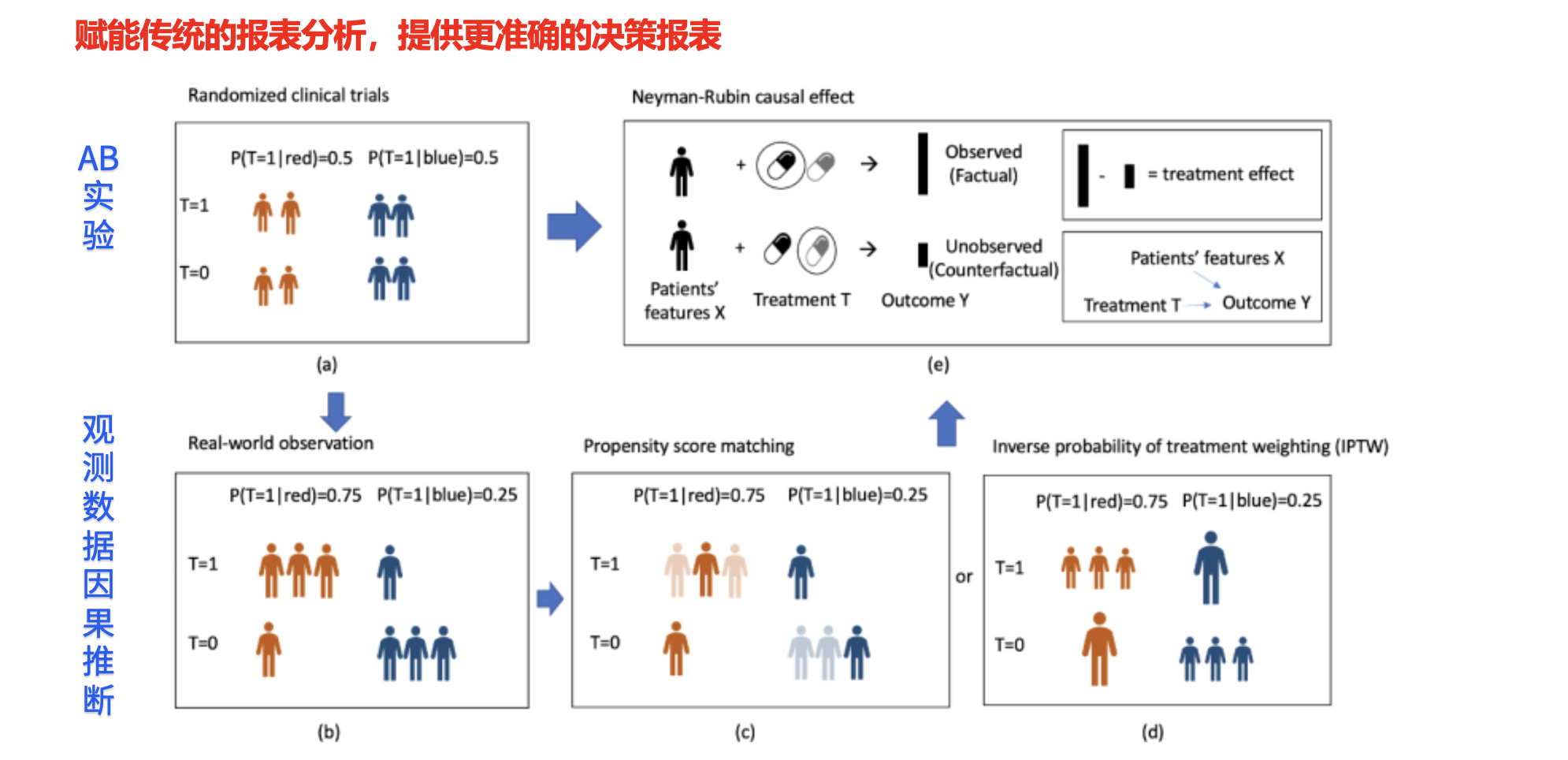
总结来说,因果推断相较于传统的报表分析,能够提供更为准确的决策支持。之前提到的 A/B 测试,就是因果推断中最经典的应用之一。因为 A/B 测试能够通过将用户分为两个完全同质的群体,从而有效地评估策略的影响力。然而,在某些情况下,我们无法进行实验,这时只能依赖离线推断和观测性因果推断的方法,尽量通过数据纠偏,得到尽可能准确的结果。
具体的案例分享,将会在下文进行详细讲解。接下来,讨论一下因果推断与 StarRocks 的结合。为什么我们需要借助 StarRocks 来进行因果推断呢?关键在于我们目前缺乏一种实时且分布式的计算能力。
在互联网应用场景下,数据量通常非常庞大。例如,微信的日活跃用户数就达到了上亿级别。在这种数据量巨大的情况下,现有的因果推断工具大多数是基于单机计算的,通常依赖 Python 等工具进行样本抽样计算。虽然单机模式在某些小规模数据的分析中可以工作,但面对如此庞大的数据量时,单机处理就会面临很大的问题。首先,它会大大降低因果推断的效果,具体体现在两个方面:
-
互联网场景下,面临大数据量的因果推断,目前的单机采样损失效果。
-
Power(统计检验显著性)在因果推断中,“Power” 代表的是进行统计检验时,策略有效果的时候能够检验出显著差异的能力。如果检验的 Power 较低,我们就可能无法确认策略的效果是否真实有效。举个例子,如果某一指标的差异为 0.1%,而我们用 1 万样本进行检验,检验的能力只有 0.04,这意味着只有 4% 的概率能发现显著差异。而如果我们使用 1 亿样本进行检验,可以百分之百检验出来。这就显示出样本量对检验结果的影响,单机处理时样本量小、计算能力有限,可能无法准确地发现显著差异。
-
MSE(模型预估精度)单机计算会影响因果推断模型的预估精度,尤其是在因果推断与机器学习模型相结合时。以因果树模型为例,我们用它来估算每个用户对策略的敏感度。如果我们使用 1 万样本进行训练,估算得到的策略敏感度的误差大约是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 771
771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









