




StarRocks Lakehouse 快速入门旨在帮助大家快速了解湖仓相关技术,内容涵盖关键特性介绍、独特的优势、使用场景和如何与 StarRocks 快速构建一套解决方案。最后大家也可以通过用户真实的使用场景来了解 StarRocks Lakehouse 的最佳实践!
本文主要分享 StarRocks Hive Catalog 最佳实践。场景基于订单管理的具体应用展开。
Apache Hive 介绍
Apache Hive 是一个分布式、容错的数据仓库系统,能够实现大规模的分析。Hive Metastore (HMS) 提供了一个元数据存储库,可以轻松分析这些元数据以做出基于数据的决策,因此它是许多数据湖架构中的关键组件。Hive 构建于 Apache Hadoop 之上,并通过 HDFS 支持在 S3、ADLS、GS 等存储上的数据管理。Hive 允许用户使用 SQL 读取、写入和管理 PB 级的数据。
Hive 架构与关键特性
架构设计

关键特性
-
Hive-Server 2 (HS2) :支持多客户端并发和身份验证,优化了对 JDBC 和 ODBC 客户端的支持。
-
Hive Metastore Server (HMS) :用于存储 Hive 表及分区元数据,支持 Spark 和 Presto 等多种开源软件,是数据湖的重要组成部分。
-
Hive ACID :为 ORC 表提供完整的 ACID 支持,并为其他格式提供仅插入操作的支持。
-
Hive Iceberg :通过 Hive StorageHandler 原生支持 Apache Iceberg 表,适合云原生的高性能场景。
-
安全性与可观测性 :支持 Kerberos 认证,集成 Apache Ranger 和 Apache Atlas。
-
Hive LLAP :实现低延迟、交互式 SQL 查询,优化数据缓存,加速查询。
-
查询优化 :基于 Apache Calcite 的成本优化器(CBO)提升查询效率。
Apache Hive 的优势
-
数据仓库 功能 :支持数据库、表、分区等基本功能,方便数据管理与查询。
-
多执行引擎 :支持MapReduce、Tez、Spark等引擎,用户可根据需求优化查询性能。
-
扩展性 :支持自定义函数(UDF),可与其他Hadoop生态工具集成,提高处理灵活性。
-
适合批处理 :特别适合大规模数据分析、报表生成和ETL任务。
-
易于集成 :可与Flume、Sqoop、Oozie等工具集成,增强大数据处理能力。
Apache Hive 的使用场景
-
数据仓库 :将Hadoop中的数据转换为SQL查询形式,提供数据仓库功能,便于用户查询和管理数据。
-
数据分析 :通过HiveQL进行数据查询、聚合和过滤,适合大规模数据分析场景。
-
数据挖掘 :与机器学习工具集成,进行数据挖掘与模式分析。
-
ETL操作 :适用于大规模日志分析与历史数据处理,优化系统性能,理解用户行为。
-
离线 处理 :适合离线的大数据处理场景,批处理引擎支持大规模查询任务。
-
工具集成 :与Apache Spark、Mahout等工具无缝集成,提升查询性能和数据建模能力。
StarRocks Hive Catalog
Hive 作为经典的MapReduce 底层引擎,常用于批处理和离线分析,在实时分析领域则由于查询性能相对较低,资源使用率较高则存在短板。
而 StarRocks 是一个 MPP 数据库,能够快速处理大规模数据集的复杂查询,支持实时分析,提供快速的查询响应,适合需要即时数据反馈的场景。
StarRocks 不仅能高效的分析本地存储的数据,也可以作为计算引擎直接分析数据湖中的数据。用户可以通过 StarRocks 提供的 External Catalog,轻松查询存储在 Apache Hive、Apache Iceberg、Apache Hudi、Delta Lake 等数据湖上的数据,无需进行数据迁移。支持的存储系统包括 HDFS、S3、OSS,支持的文件格式包括 Parquet、ORC、CSV。
通过 StarRocks Hive Catalog,实现了 StarRocks 与 Hive 的无缝集成,结合了两者的优势。在数据湖分析场景中,StarRocks 主要负责数据的计算分析,而数据湖则主要负责数据的存储、组织和维护。使用数据湖的优势在于可以使用开放的存储格式和灵活多变的 schema 定义方式,可以让 BI/AI/Adhoc/ 报表等业务有统一的 single source of truth。而 StarRocks 作为数据湖的计算引擎,可以充分发挥向量化引擎和 CBO 的优势,大大提升了数据湖分析的性能。
数据模型
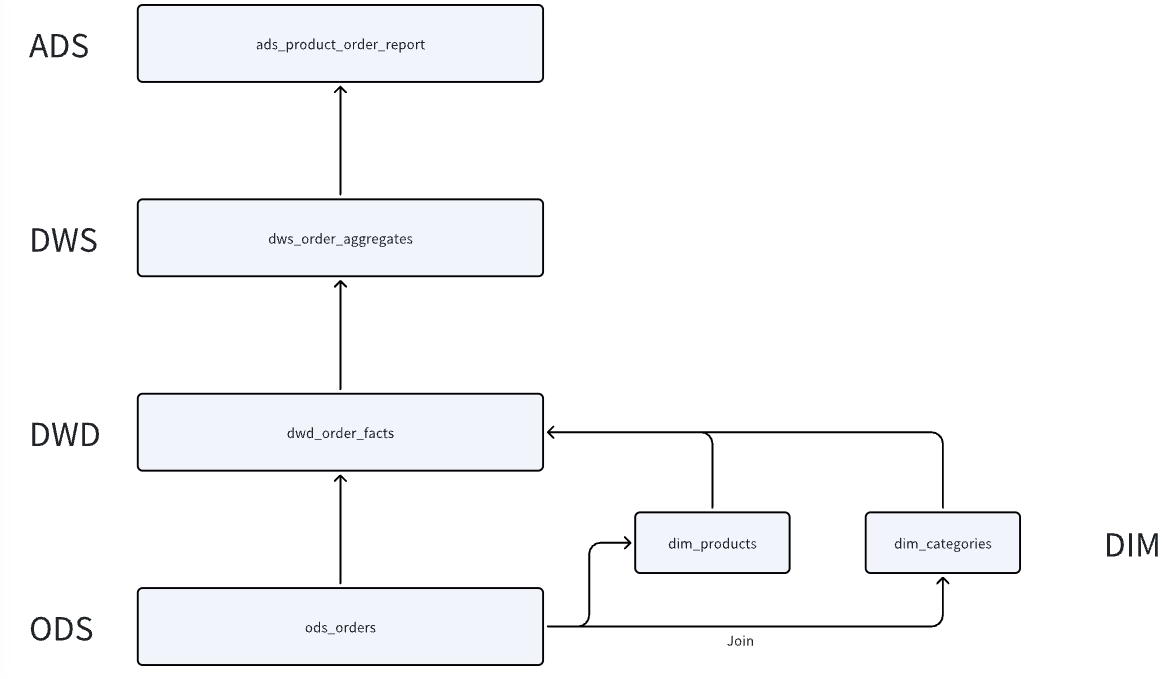
技术架构演进
StarRocks Hive Catalog可以按照如下的方式演进:
直接查 Hive 表的数据 --> 使用 Data Cache 加速查询 Hive 表的数据 --> 使用 Data Cache 和 异步物化视图 加速查询 Hive 表的数据
-
StarRocks Hive Catalog直接查结果集
-
所有ETL都是在Hive中完成,StarRocks利用Hive Catalog查询DWD、DWS和ADS的结果集
-
利用StarRocks Hive Catalog + datacache现查
-
只有ODS和DWD是在Hive中完成,后续DWS和ADS都是利用StarRocks的Hive Catalog现查(现计算)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1041
1041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









