




 随着人工智能的蓬勃发展,数据存储需求和挑战日益增加。星实的StarGFS并行文件系统提供高性能、高数据读写能力、小文件高效检索技术,以及面向高性能计算的智能缓存和字节粒度锁。StarGFS通过多元数据服务器集群、SSD动态缓存、小文件容器存储、增强型权限管理和StarRAID技术,确保数据安全和高并发访问,满足深度学习的存储需求。
随着人工智能的蓬勃发展,数据存储需求和挑战日益增加。星实的StarGFS并行文件系统提供高性能、高数据读写能力、小文件高效检索技术,以及面向高性能计算的智能缓存和字节粒度锁。StarGFS通过多元数据服务器集群、SSD动态缓存、小文件容器存储、增强型权限管理和StarRAID技术,确保数据安全和高并发访问,满足深度学习的存储需求。
一、人工智能蓬勃发展
1956年,几个计算机科学家相聚在达特茅斯会议,提出了“人工智能”的概念,梦想着用当时刚刚出现的计算机来构造复杂的、拥有与人类智慧同样本质特性的机器。其后,人工智能就一直萦绕于人们的脑海之中,并在科研实验室中慢慢孵化。之后的几十年,人工智能一直在两极反转,或被称作人类文明耀眼未来的预言,或被当成技术疯子的狂想扔到垃圾堆里。直到2012年之前,这两种声音还在同时存在。
2012年以后,得益于数据量的上涨、运算力的提升和机器学习新算法(深度学习)的出现,人工智能开始大爆发。人工智能广泛的采用深度学习来实现,目前大部分的深度学习算法研究都基于GPU架构的超算平台。GPU+人工智能算法在很多领域都取得了很好的应用效果,如信号处理、物理模拟、几何计算、数据挖掘和图像处理等领域。HPC和AI正走的越来越近。
二、数据存储的需求和挑战
机器学习是实现人工智能(AI)的一种方法,而深度学习又是实现机器学习的一种方法。

由于高性能计算技术的发展,使得相比神经网络计算量更大的深度学习,能够在可以接受的时间内完成可以使用的深度学习模型。
深度学习常用的学习工具有:Caffee、MxNet、TensorFlow、Torch等,这些软件在训练算法时,同时兼具计算密集型和I/O密集型两个特点,深度学习算法对于速度和规模的需求是相互促进的。为了达到更好的分类和识别效果,我们需要更多高质量的特征。这导致了深层神经网络模型往往具有大量的模型参数,非常复杂的特征抽取层,以及非常深的层次结构。大量的模型参数反过来对数据规模又提出了更高的要求以避免出现过拟合的问题(过拟合问题是指模型参数对训练数据拟合度非常高,但在测试数据上则没有很好效果)。
数据是深度学习的基础,也是实现人工智能的最底层土壤。深度学习对于存储和读取对存储也提出了非常高的挑战:
三、星实StarGFS提供强力解决方案
3.1 StarGFS并行文件系统
星实推出的StarGFS并行文件系统是一个性能为中心,围绕简单易用、易安装以及易管理而设计的领先并行文件系统。具有高性能、高可靠、出众的小文件性能等诸多特点,能很好的适应。
StarGFS是以性能为中心,采用了集群架构设置,系统支持无上限的扩展,理论上能扩展到EB级别。单一集群承载上万台服务器。整个系统能提供上百GB/s的吞吐带宽。
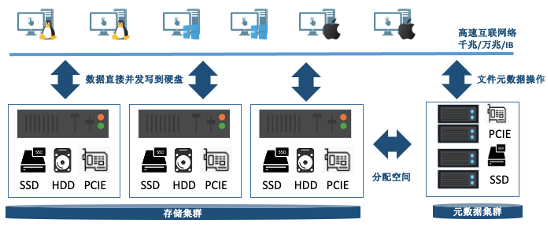
StarGFS架构图
3.2 高数据读写性能
可选的前端客户端切片技术满足高并发需求
StarGFS采用了和传统存储系统不一样的文件数据切片式存储,智能化的文件切片存储能够更好的让数据落盘更加顺序化,减少硬盘磁头抖动提升读写性能;并且由于所有硬盘同时运转对外提供存储服务,实现系统性能最大化。
StarGFS对于普通的SATA硬盘可以发挥接近150MB/s的读写性能,充分发挥硬件自身的效率来实现超高的并发数据读写能力,提高业务运转效率。
针对海量小文件高吞吐率、高效检索技术
深度学习场景具有很多图片和文件参与模型的训练,这些大量的图片和文档大小都比较小,一般都在10M以下并且数量巨大,大的模型甚至有上百万个文件。
StarGFS现有的多元数据服务器集群技术的基础上,结合高性能计算应用文件创建、访问以及目录结构特点,研制了多元数据服务器集群技术。在一套存储系统中可以根据用户生产系统中实际产生文件数量的规模对元数据服务器集群进行动态配置,整个存储系统中所有的元数据服务器同时参与文件的检索和定位工作,消除存储系统中元数据通道的瓶颈,同时还可以根据后续应用特点的变化和需求的增强,做到在线扩展元数据服务器,并且达到即插即用的效果。
同时StarGFS充分利用SSD的高IOPS特点,设计了SSD动态缓存技术,提升文件系统在海量小文件场景的IOPS/OPS。
u 创新小文件容器Container存储技术
目前,存储市场上大部分的存储系统在海量小文件的应用模式下,都存在吞吐率低,检索慢的问题,这个问题的本质原因是整个存储系统处理元数据的效率所导致的。海量的小文件导致了元数据数量也狠庞大,常见的文件系统无法快速的处理庞大的元数据。StarGFS创新采用了小文件容器Container聚合存储技术,将多个文件进行聚合存储。这样将多次的元数据操作整合成了一次,大大减少了元数据的操作量。十几倍的提升了小文件的读取效率。
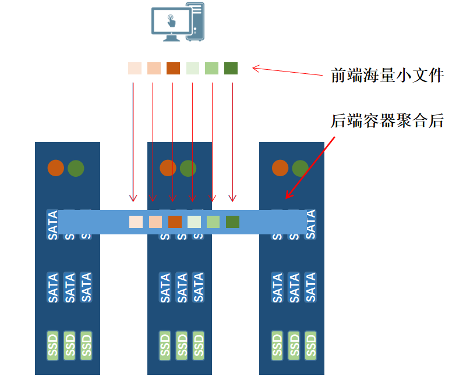
小文件容器Container存储技术
面向高性能计算的字节粒度锁
深度学习的常用软件中,普遍采用了MPI,OpenMPI等技术来进行并发的计算来加速整个模式的训练。这对并行文件系统要求具有支持字节锁的能力。
普通的本地文件系统只提供文件粒度的锁,文件粒度的锁在文件这一级别上限制了并发,导致很多只是修改文件不同部分的进程或者线程也不能同时修改。而在很多高性能计算应用场景中,文件粒度锁限制了高并发,因为很多场景只是修改文件的一个部分,修改文件不同部分之间的进程或者线程理论上是可以同时进行的,但是文件粒度锁无法有效解决。
为了可以在文件内部可以进行并发读写,StarGFS并行文件系统系统提供了字节粒度锁。这样加锁的粒度能够达到字节,修改同一个文件不同部分就可以并行执行,从而提高了同一个文件的IO性能。
面向高性能计算的智能数据缓存技术
高效的数据缓存技术能够帮助存储系统发挥更好的性能,提高计算任务的效率。StarGFS采用多级智能数据缓存技术来实现高效缓存。
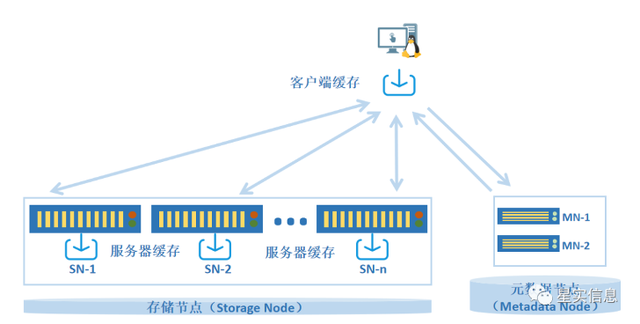
StarGFS多级缓存机制
首先,通过应用服务器上自主研发客户端内核模块,分析应用访问数据的特点,采用特定的缓存算法在应用服务器上有效缓存应用的访问数据;
其次,将所有存储服务器的内存集合起来形成一个大的缓存池,通过存储服务器上独特的缓存算法缓存不同应用访问的数据;
最后,将所有元数据服务器的内存集合起来形成一个高效的元数据缓存池,通过复杂的元数据淘汰算法来缓存元数据信息。通过这样多级数据的缓存技术,会使得整个存储系统的性能能够得到大幅提高。
3.3 面向多用户环境的增强型权限管理技术
很多深度学习的计算平台是一个多用户共享平台,每天都有很多用户在计算平台上面运行不同的任务,整个存储系统也需要保证各个用户之间的任务相互独立、数据安全高可用。因此,传统的基于操作系统用户权限的管理技术无法完全满足计算平台的需求。在新研制的存储系统中拟提供增强型权限管理技术,除了兼容原有基于操作系统用户的权限管理之外,还增加了自身所特有的增强型权限管理技术,通过存储系统的后端管理平台直接为某个目录指定哪些用户、或者哪些应用服务器能够访问,哪些目录禁止用户删除、修改等。
3.4 StarRAID技术保障数据安全
创新的StarRAID技术对数据进行冗余保护,通过N+M纠删码按需动态设置数据保护等级。存储系统具备自动故障检测与恢复机制,自动快速恢复重建,恢复速度是传统Raid的10倍以上(1TB数据重构时间小于30分钟),能保证系统在数据安全性、高并发读写、高空间利用率三者皆得。。
系统支持磁盘热插拔,只要容量足够就不需即时更换故障盘,不影响业务连续性。
3.5 丰富的存储高级功能
u 灵活的双机/多机/集群方案
领先的对称双活方案:不需要引入任何第三方软硬件,直接通过两台同系列存储系统实现两台存储的双活工作。当其中一台存储发生故障时,可由另一台存储实时接管业务,实现RPO、RTO为零。StarGFS支持单节点、双节点、分布式集群架构灵活弹性部署,提高投资的灵活性。
u 秒级数据快照克隆技术
StarGFS的快照功能可为文件或者卷创建多达无限数量的基于增量的历史时间点拷贝。当发生数据“软”故障,比如软件程序导致的数据损坏、病毒破坏、意外删除等,可以通过对合适的时间点标记进行“回滚”来快速恢复数据。该功能特别适用于关键性业务的连续数据保护。
u 异构数据迁移
支持不同存储系统之间数据快速高效、安全的复制和迁移,实现点对点、多点对多点之间的相互数据复制,发生意外灾难时能够对数据进行快速恢复,确保用户的业务持续性。具备差异、增量等备份机制,支持多目标源相互复制和推送。
u 支持全面的权限管理
StarGFS支持权限控制列表ACL等相关功能,并且还支持更多可灵活配置的文件访问权限控制选项,能够根据应用场景需求动态灵活的授权给相关的用户或者工作站相关的文件创建、删除、重命名、修改等相关的权限,从而能够满足更多场景的文件数据安全存储和访问的需求。
举报/反馈


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









