




 这篇博客介绍了两篇关于动力学时间序列分析的工作,包括基于时间延迟和方向交互的检测方法CME,以及利用随机分布嵌入实现短期高维数据预测的RDE框架。CME方法通过峰值识别时间延迟,而RDE方法通过低维弱预测器组合进行未来状态预测。尽管研究展示了在二元系统中的应用,但对长时间预测和网络结构的探讨不足。
这篇博客介绍了两篇关于动力学时间序列分析的工作,包括基于时间延迟和方向交互的检测方法CME,以及利用随机分布嵌入实现短期高维数据预测的RDE框架。CME方法通过峰值识别时间延迟,而RDE方法通过低维弱预测器组合进行未来状态预测。尽管研究展示了在二元系统中的应用,但对长时间预测和网络结构的探讨不足。
前几天去厦门开会(DDAP10),全英文演讲加之大家口音都略重,说实话听演讲主要靠看ppt,摘出一篇听懂的写篇博客纪念一下吧。
11.2 Session-A 13:30-18:00 WICC G201
| Time | Speaker | No. | Title |
|---|---|---|---|
| 14:30-15:00 | Wei Lin | ST-07 | Dynamical time series analytics: From networks construction to dynamics prediction |
主要讲了他的两个工作,一个是重构的工作,一个是预测的工作,分别发表在PRE和PNAS上。
第一篇工作
Detection of time delays and directional interactions based on time series from complex dynamical systems

ABSTRACT
Data-based and model-free accurate identification of intrinsic(固有) time delays and directional interactions.
METHOD
Given a time series x(t)x(t)x(t), one forms a manifold(流形) MX∈RnM_X\in R^nMX∈Rn based on delay coordinate embedding: X(t)=[x(t),x(t−δt),...,x(t−(n−1)δt)]X(t) = [x(t),x(t − \delta t), . . . ,x(t − (n − 1)\delta t)]X(t)=[x(t),x(t−δt),...,x(t−(n−1)δt)], where nnn is the embedding dimension and δt\delta tδt is a proper time lag.
CME method:
Say we are given time series x(t)x(t)x(t) and y(t)y(t)y(t) as well as a set of possible time delays: Γ={τ1,τ2,…,τm}\Gamma = \{\tau_1,\tau_2, … ,\tau_m\}Γ={τ1,τ2,…,τm}. For each candidate time delay τi\tau_iτi, we let z(t)=x(t−τi)z(t) = x(t − \tau_i)z(t)=x(t−τi) and form the manifolds MYM_YMY and MZM_ZMZ with nyn_yny and nzn_znz being the respective embedding dimensions. For each point Y(t^)∈MYY(\hat{t}) \in M_YY(t^)∈MY , we find KKK nearest neighbors Y(tj)(j=1,2,…,K)Y(t_j)(j = 1,2, …,K)Y(tj)(j=1,2,…,K), which are mapped to the mutual neighbors Z(tj)∈MZ(j=1,2,…,K)Z(t_j) \in M_Z(j = 1,2, …,K)Z(tj)∈MZ(j=1,2,…,K) by the cross map. We then estimate Z(t)Z(t)Z(t) by averaging these mutual neighbors through Z^(t^)∣MY=(1/K)∑j=1KZ(tj)\hat{Z}(\hat{t})|M_Y=(1/K)\sum^K_{j=1}Z(t_j)Z^(t^)∣MY=(1/K)∑j=1KZ(tj). Finally, we define the CME score as
s(τ)=(nZ)−1trace(ΣZ^−1cov(Z^,Z)ΣZ−1)s(\tau)=(n_Z)^{-1}trace(\Sigma_{\hat{Z}}^{-1}cov(\hat{Z},Z)\Sigma_Z^{-1})s(τ)=(nZ)−1trace(ΣZ^−1cov(Z^,Z)ΣZ−1)
It is straightforward to show 0≤s≤10\leq s\leq 10≤s≤1. The larger the value of sss, the stronger the driving force from x(t−τ)x(t−\tau)x(t−τ) to y(t)y(t)y(t). In a plot of s(τ)s(\tau)s(τ), if there is a peak at τk∈Γ\tau_k\in \Gammaτk∈Γ, the time delay from XXX to YYY can be identified as τk\tau_kτk.
可以理解为如果xxx是以延迟τk\tau_kτk作用于yyy,那么当yyy的情况(YYY)类似时,τk\tau_kτk之前的xxx(也就是zzz)的情况(ZZZ)也应该类似(协方差大,相关性强),形式上和pearson相关系数一样。
RESULTS
To validate our CME method, we begin with a discrete-time logistic model of two non-identical species:
Xt+1=Xt(γx−γxXt−K1Yt−τ1)X_{t+1}=X_t(\gamma_x-\gamma_xX_t-K_1Y_{t-\tau_1})Xt+1=Xt(γx−γxXt−K1Yt−τ1)
Yt+1=Yt(γy−γyYt−K2Xt−τ2)Y_{t+1}=Y_t(\gamma_y-\gamma_yY_t-K_2X_{t-\tau_2})Yt+1=Yt(γy−γyYt−K2Xt−τ2)
where γx=3.78,γy=3.77\gamma_x=3.78, \gamma_y = 3.77γx=3.78,γy=3.77, K1K_1K1 and K2K_2K2 are the coupling parameters, and τ1\tau_1τ1 and τ2\tau_2τ2 are the intrinsic time delays that we aim to determine from time series.
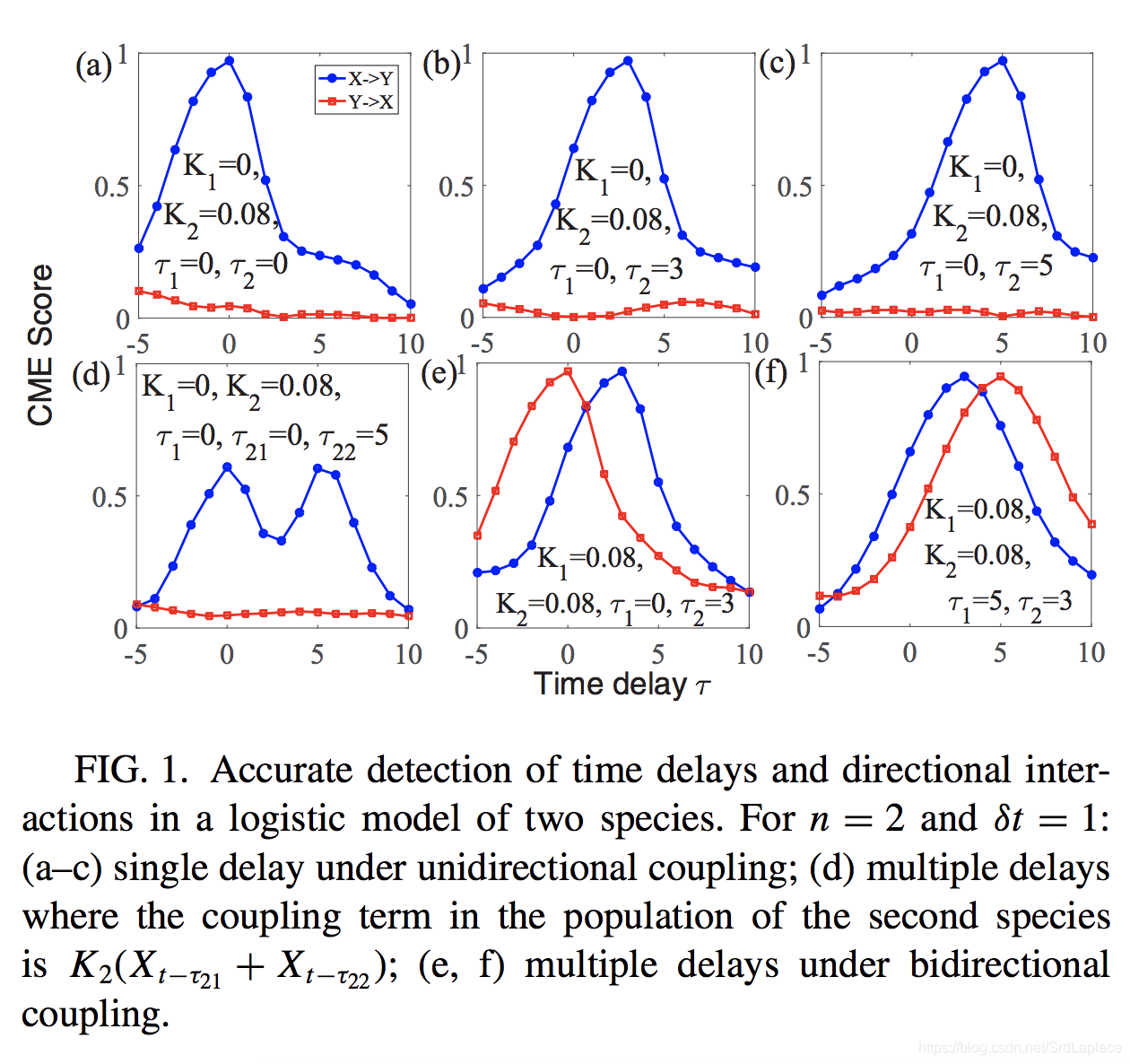
后面也举了几个微分方程的例子。
疑问:他所举例都是两个节点的连接,并没有把方法运用到网络中。
第二篇工作
Randomly distributed embedding making short-term high-dimensional data predictable

Abstract
In this work, we propose a model-free framework, named randomly distributed embedding (RDE), to achieve accurate future state prediction based on short-term high-dimensional data.
From the observed data of high-dimensional variables, the RDE framework randomly generates a sufficient number of low-dimensional “nondelay embeddings” and maps each of them to a “delay embedding,” which is constructed from the data of a to be predicted target variable.
Any of these mappings can perform as a low-dimensional weak predictor for future state prediction, and all of such mappings generate a distribution of predicted future states.
用机器学习embedding的思想,把随机选取若干个变量当作特征,预测指定节点的值,然后进行embedding。
RDE Framework
For each index tuple l=(li,l2,...,lL)l = (l_i, l_2, ..., l_L)l=(li,l2,...,lL), a component of such a mapping, denoted by ϕl\phi_lϕl , can be obtained as a predictor for the target variable xk(t)x_k (t)xk(t) in the form of
xk(t+τ)=ϕl(xl1(t),xl2(t),...,xlL(t))x_k(t+\tau)=\phi_l(x_{l_1}(t),x_{l_2}(t),...,x_{l_L}(t))xk(t+τ)=ϕl(xl1(t),xl2(t),...,xlL(t))
Notice that LLL is much lower than the dimension nnn of the entire system. Then, typical approximation frameworks with usual fitting algorithms could be used to implement this predictor. In this paper, we apply the Gaussian Process Regression method to fit each ϕl\phi_lϕl .
Specifically, better prediction can be estimated by
x^k(t+τ)=E[x^kl(t+τ)]\hat{x}_k(t+\tau)=E[\hat{x}^l_k(t+\tau)]x^k(t+τ)=E[x^kl(t+τ)]
where E[⋅]E[\cdot]E[⋅] represents an estimation based on the available probability information of the random variablex^kl\hat{x}^l_kx^kl. A straightforward scheme to obtain this estimation is to use the expectation of the distribution as the final prediction value [i.e., x^k(t+τ)=∫xp(x)dx\hat{x}_k(t+\tau)=\int{xp(x)dx}x^k(t+τ)=∫xp(x)dx , where p(x)p(x)p(x) denotes the probability density function of the random variable x^kl\hat{x}^l_kx^kl].
In light of the feature bagging strategy in machine learning, each random embedding is treated as a feature, and thus, the final prediction value is estimated by the aggregated average of the selected features: that is,
xk(t+τ)=∑iwix^kl(t+τ)x_k(t+\tau)=\sum_iw_i\hat{x}^l_k(t+\tau)xk(t+τ)=i∑wix^kl(t+τ)
where each wiw_iwi is a weight related to the in-sample fitting error of ϕi\phi_iϕi and the equation represents the best fitting errors for the final prediction.
Methods
Given time series data sampled from nnn variables of a system with length mmm (i.e., x(t)∈Rn,t=t1,t2,...,tmx(t)\in R_n , t = t_1, t_2, . . . , t_mx(t)∈Rn,t=t1,t2,...,tm, where ti=tI−1+τti = t_{I−1} + \tauti=tI−1+τ), one can estimate the box-counting dimension ddd of the system’s dynamics and choose embedding dimension L>2dL>2dL>2d. Assume that the target variable to be predicted is represented as xkx_kxk. The RDE algorithm is listed as follows:
- Randomly pick s tuples from (1,2,…,n)(1, 2, …, n)(1,2,…,n) with replacement, and each tuple contains LLL numbers.
- For the lllth tuple (l1,l2,…,lL)(l_1, l_2, …, l_L)(l1,l2,…,lL), fit a predictor ϕi\phi_iϕi so as to minimize ∑I=1m−1∣∣xk(ti+τ)−ϕl(xl1(ti),xl2(ti),…,xlL(ti)∣∣\sum_{I=1}^{m-1}||x_k(t_i+\tau) − \phi_l(x_{l_1}(t_i), x_{l_2}(t_i ), …, x_{l_L}(ti)||∑I=1m−1∣∣xk(ti+τ)−ϕl(xl1(ti),xl2(ti),…,xlL(ti)∣∣. Standard fitting algorithms could be adopted. In this paper, Gaussian Process Regression is used.
- Use each predictor ϕl\phi_lϕl , and make one-step prediction x^kl(t∗+τ)=ϕl(xl1(t∗),xl2(t∗),…,xlL(t∗)\hat{x}^l_k(t^*+\tau)=\phi_l(x_{l_1}(t^*),x_{l_2}(t^*), …, x_{l_L}(t^*)x^kl(t∗+τ)=ϕl(xl1(t∗),xl2(t∗),…,xlL(t∗) for a specific future time t∗+τt^*+\taut∗+τ.
- Multiple predicted values form a set {x^kl(t∗+τ)}\{\hat{x}^l_k(t^* + \tau)\}{x^kl(t∗+τ)}. Exclude the outliers from the set, and use the Kernel Density Estimation method to approximate the probability density function p(x)p(x)p(x) of its distribution.
- 将预测值的分布的平均当作是预测值. Otherwise, calculate the in-sample prediction error δl\delta_lδl for the fitted ϕl\phi_lϕl using the leave-one-out method. Based on the rank of the in-sample error, rrr best tuples are picked out, and the final prediction is given by the aggregated average in the form of xk(t+τ)=∑irwix^kl(t+τ)x_k(t+\tau)=\sum_i^rw_i\hat{x}^l_k(t+\tau)xk(t+τ)=∑irwix^kl(t+τ), where the weight wi=exp(−δi/δ1)∑jexp(−δj/δ1)w_i=\frac{exp(−\delta_i/\delta_1)}{\sum_j exp(−\delta_j/\delta_1)}wi=∑jexp(−δj/δ1)exp(−δi/δ1) .
Result
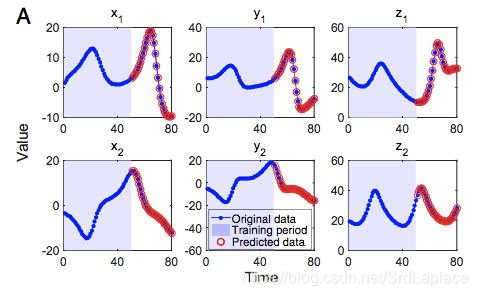
As particularly shown in Fig. 1, with the n-dimensional time series data xi(t),i=1,2,...,nx_i(t), i = 1, 2, . . . , nxi(t),i=1,2,...,n, two kinds of 3D (threedimensional) attractors can be reconstructed.
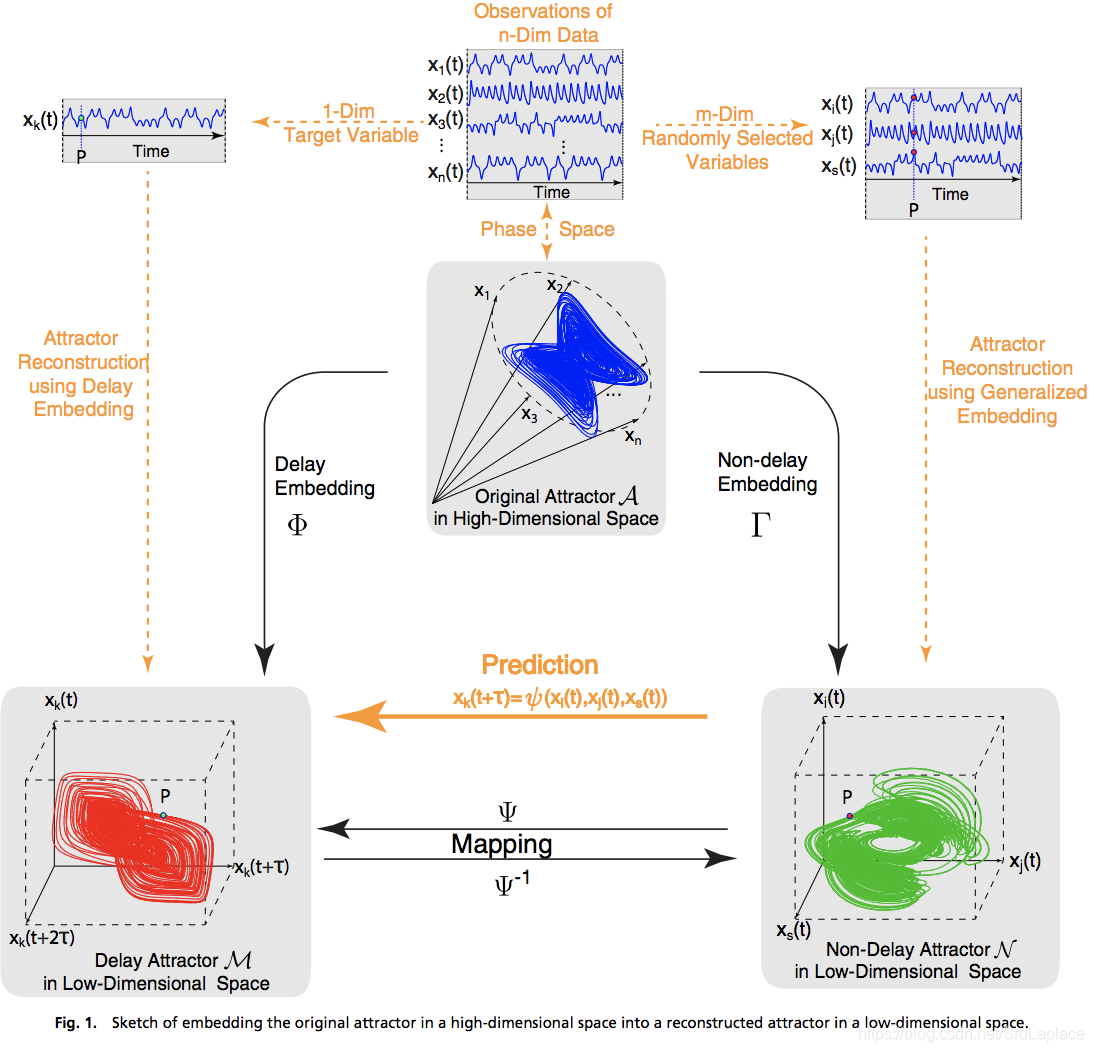
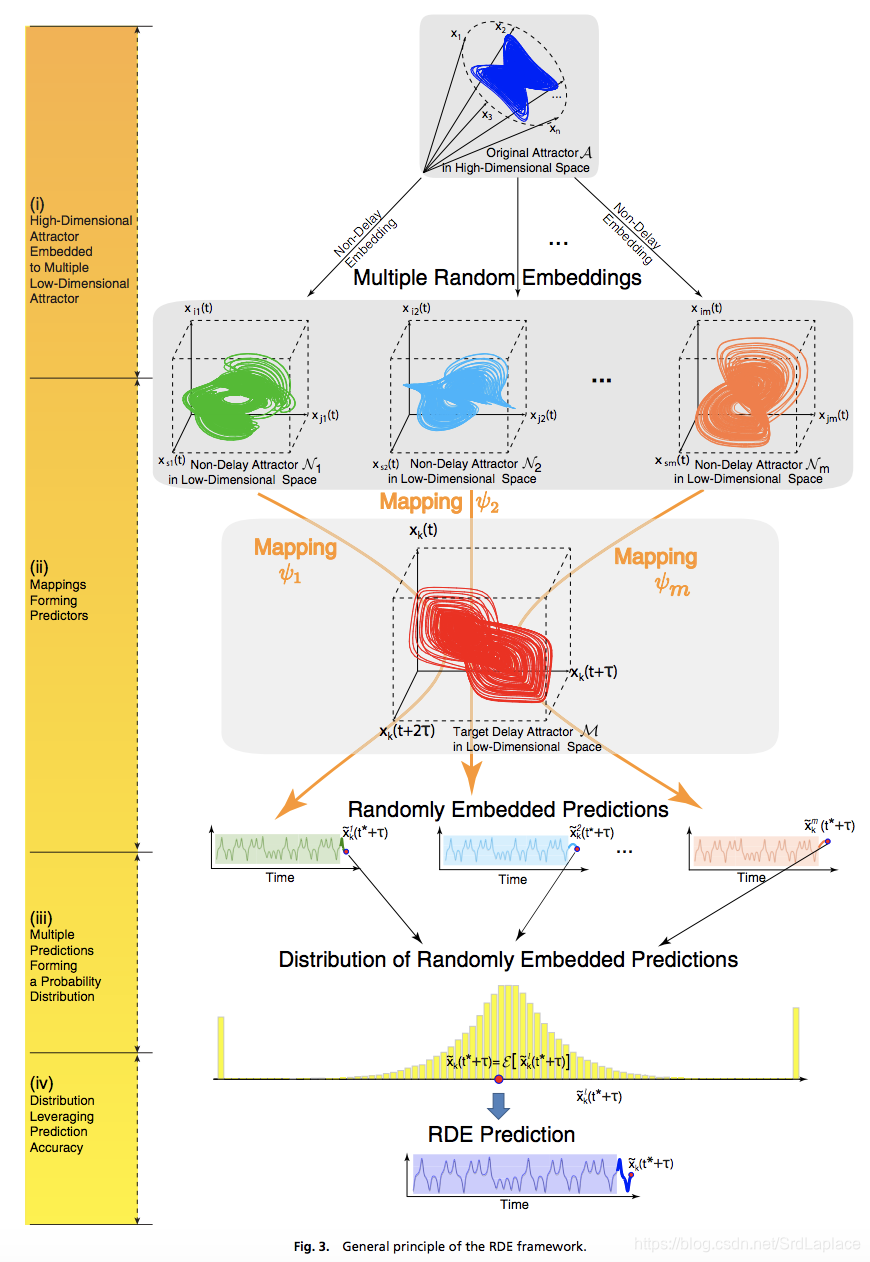
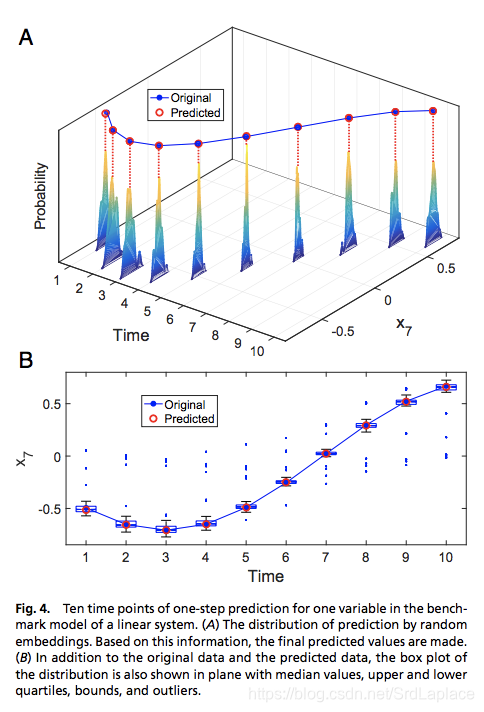
加噪声和选取不同的训练时间长度对结果的影响
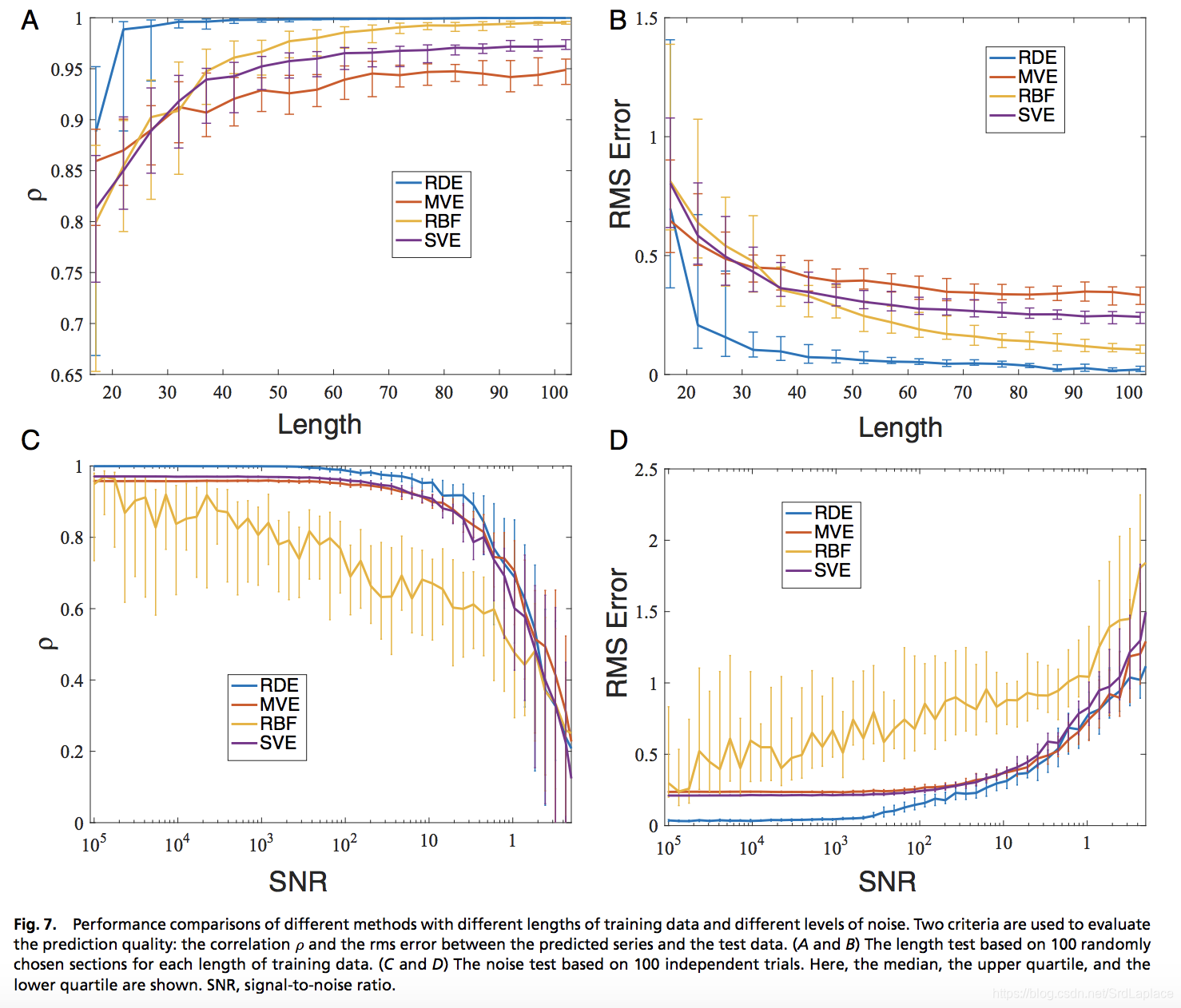
SNR 是信噪比;RDE 是本文的方法(randomly distributed embedding);MVE 是 multiview embedding method;RBF表示RDE采用RBF (radial basis function) network来进行预测的方法; SVE 是 the classic single-variable embedding method。

















 528
528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









