




 本文详细介绍了Linux基础命令,包括vi编辑器的使用、命令行模式快捷键、系统命令如查看进程和端口、yum安装与卸载软件、kill命令的使用等。同时强调了在生产环境中修改配置文件前要先备份,并给出了常见问题的解决方案。
本文详细介绍了Linux基础命令,包括vi编辑器的使用、命令行模式快捷键、系统命令如查看进程和端口、yum安装与卸载软件、kill命令的使用等。同时强调了在生产环境中修改配置文件前要先备份,并给出了常见问题的解决方案。
- 2.1、vi命令解读
- 2.2、命令行模式中的快捷键
- 2.3、常见的系统命令
- 2.4、查看进程端口号
- 2.5、yum安装httpd服务
- 2.6、httpd测试127.0.0.1地址访问
- 2.7、高危命令之kill
- 2.8、yum软件的安装和卸载(卸载的时候不去校验依赖)
- 2.9、wget下载安装包、压缩、解压
一、上次课程回顾
- 博客链接:https://blog.youkuaiyun.com/SparkOnYarn/article/details/104800105
- 举例:usermod -g hadoop -G hadoop,ruoze,root hadoop 解析:ruoze用户的主组是ruoze,并且它还在bigdata,jepson这个组中,嫌性的进行指定。
[root@hadoop001 ~]# id hadoop
uid=1000(hadoop) gid=1000(hadoop) groups=1000(hadoop),0(root)
[root@hadoop001 ~]# usermod -g hadoop -G hadoop,ruoze,root hadoop
[root@hadoop001 ~]# id hadoop
uid=1000(hadoop) gid=1000(hadoop) groups=1000(hadoop),0(root),1001(ruoze)
二、Linux基础命令四
2.1、vi命令
1、图解vi编辑命令:

注意:我们使用vi编辑文件,文件在命令行模式的时候进行拷贝,拷贝到文件中,会出现拷贝内容的丢失;进入到编辑模式的时候进行拷贝,内容才不会丢失。
- so,粘贴的时候必须在编辑模式
2、找error的其它方法:
- 这个是我们之前讲的方法:cat xxx.log | grep -C 10 ERROR > error.log
- 按住shift+:/关键词,进入尾行模式,加上斜杠和关键词,回车自动匹配,按N键找寻下一个关键词。
3、vi下为文件设置行号:
也是进入尾行模式输入:set nu,就可以知道文件所在行数。退出行号:set nonu
4、清空文件内容:
- cat /dev/null > xxx.log
- echo “” > xxx.log 文件中存在一个字节,并不是很好
2.2、命令行模式中的快捷键
| 快捷键 | 释义 |
|---|---|
| dd | 删除当前行 |
| dG | 删除当前光标以下的所有行 |
| ndd | 删除当前光标以下的n行(从当前光标所在行往下数n行) |
| gg | 跳转到第一行的第一个字母 |
| G | 跳转到最后一行的第一个字母 |
清空文件内容:vi rz.log进入到命令行模式,gg跳转到第一行第一个字母,然后dG删除当前光标以下所有行;按i键进入编辑模式,从其它地方拷贝内容到文件中,shift+: 进入尾行模式,输入wq进行保存退出。
注意:不在编辑模式的话,直接进行拷贝会丢失文件内容。
生产场景:从另外一个文本拷贝内容去全局覆盖这个文件
大数据的组件都是xml文件
1、官方默认的配置文件XXXXX 30行
2、windows记事本 editplus 编辑好对应的参数300行
2.3、常见的系统命令
1、未来一个机器上肯定是有很多磁盘的,空间比较小的忽略不计,只要看挂载到根目录或者挂载到其它目录的文件。
[root@hadoop001 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 40G 13G 25G 35% / 系统盘200G
/dev/vdb1 1T 10G XXX /data01 数据盘
/dev/vdb2 1T 10G XXX /data02 数据盘
/dev/vdb3 1T 10G XXX /data02 数据盘
/dev/vdb4 1T 10G XXX /data02 数据盘
devtmpfs 911M 0 911M 0% /dev
tmpfs 920M 0 920M 0% /dev/shm
tmpfs 920M 344K 920M 1% /run
tmpfs 920M 0 920M 0% /sys/fs/cgroup
tmpfs 184M 0 184M 0% /run/user/0
J总公司一台机器系统盘200G,配了10T的数据盘
2、free -m
[root@hadoop ~]# free -m
total used free shared buffers cached
Mem: 3830 3142 687 0 180 1559
-/+ buffers/cache: 1403 2427
Swap: 0 0 0
//我的腾讯云服务器买的2核4G,4G*1024=4096M,出去系统占用,还剩3830兆;used表示已经使用了多少内存,正常使用total-used=free.
total表示系统总物理内存3830m
used表示总计分配给缓存(包含buffers和cached),但其中部分缓存未实际使用
free表示未分配的内存
shared表示共享内存
buffers表示系统分配但未被使用的buffers数量
cached表示系统分配但未被使用的cache的数量
在free命令中显示的buffer和cache,他们都是占用内存
buffer:作为buffer cache的内存,是块设备的读写缓冲区,更靠近存储设备,或者直接就是disk的缓冲区
cached:作为page cache的内存,文件系统的cache,是memory的缓冲区。
如果cache的值很大,说明cache住的文件数很多,如果频繁访问的文件的文件都能被cache住,那么磁盘的读IO势必会非常小。
3、系统负载
top - 17:01:13 up 4 days, 3:16, 1 user, load average: 0.00, 0.01, 0.05
Tasks: 69 total, 1 running, 68 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.7 us, 0.7 sy, 0.0 ni, 98.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 1883724 total, 75604 free, 1218004 used, 590116 buff/cache
KiB Swap: 1048572 total, 1048572 free, 0 used. 489276 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1701 root 10 -10 131084 14148 6544 S 0.7 0.8 49:52.11 AliYunDun
1 root 20 0 43176 3424 2308 S 0.0 0.2 0:02.60 systemd
//一个系统卡不卡就看load average: 0.00,0.01,0.05;就看这三个值,1min,5min,15min级别的负载;J总的经验值,这三个值不要超过10,否则认为此物理服务器。
//主要观察top10进程,某个进程消耗的CPU占多少,去看看某个进程是做什么的
云服务器不算公司资产的,并且一年费用也很高;所以最好下迁到IDC机房。
遇到的问题:
J总公司存在的一种情况,CPU一直在3906%,并且三个级别都是在100,100,100;这表明服务夯住:硬件有问题、代码级别有问题;hbase regionserver的进程,解决办法:万能的重启
扩充内容:
参考J哥博客:http://blog.itpub.net/30089851/viewspace-2131678/
2.4、查看进程、查看端口号
1、ps -ef 打印后台所有运行的进程:
1、最后一行都是会查看自己本身的进程:
[root@hadoop001 ~]# ps -ef|grep ssh
root 2949 1 0 Mar09 ? 00:00:00 /usr/sbin/sshd -D
root 10706 2949 0 15:26 ? 00:00:00 sshd: root@pts/0
root 10975 10708 0 18:25 pts/0 00:00:00 grep --color=auto ssh
//进程用户 进程的pid 进程的父id 进程用户的内容(进程所属的目录)
2、netstat -nlp 打印后台所有的端口号:
- 首先通过名称找到pid,再通过pid找到port
[root@hadoop001 ~]# netstat -nlp|grep 2949
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 2949/sshd
-
比如大数据组件的一个服务,满足运行的条件,
1、启动一个进程:ps -ef
2、可能启动一个port netstat不是必须的 -
当我们通过SecureCRT来连接的的时候,CRT默认的端口号是22,万一哪天端口号变更了,我们首先ps -ef找到pid,再根据netstat来监听到端口号。
2.5、yum安装httpd服务
1、在CentOS系统中安装:yum install httpd
1、启动httpd服务,因为我们的是CentOS7系统,使用service httpd start(这个是CentOS6的系统命令),会指向systemctl start httpd.service;
//至于这个命令为什么要优化呢,service启动服务查看状态只能一个一个进程来,而systemctl可以多个进程一起执行。
service httpd start CentOS6.X、CentOS7.X都可以适用
systemctl status httpd nginx php 只适用于CentOS7.X
[root@hadoop ~]# service httpd start
Redirecting to /bin/systemctl start httpd.service
[root@hadoop ~]# systemctl stop httpd.service
[root@hadoop ~]# systemctl start httpd.service
2、可以查看到父进程是10805
[root@hadoop ~]# ps -ef|grep httpd
root 10805 1 0 22:48 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 10806 10805 0 22:48 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 10807 10805 0 22:48 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 10808 10805 0 22:48 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 10809 10805 0 22:48 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 10810 10805 0 22:48 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
root 10812 10601 0 22:48 pts/0 00:00:00 grep --color=auto httpd
3、我们根据父进程的pid查询得到httpd的端口号就是80
[root@hadoop ~]# netstat -nlp|grep 10805
tcp6 0 0 :::80 :::* LISTEN 10805/httpd
4、测试服务是否部署成功:
http://144.34.179.161:80、http://144.34.179.161两者访问的是一样的
https://144.34.179.161 此种协议默认的端口就是443端口
场景:在CentOS系统上部署大数据组件的时候,发现一个错误,叫做链接拒绝,Connection refused,比如windows的IDEA去访问,如何去验证:ping ip、telnet ip port
1、在windows中打开cmd窗口如下验证到的是没有问题的
C:\Users\Administrator>ping 144.34.179.161
正在 Ping 144.34.179.161 具有 32 字节的数据:
来自 144.34.179.161 的回复: 字节=32 时间=233ms TTL=41
来自 144.34.179.161 的回复: 字节=32 时间=228ms TTL=41
来自 144.34.179.161 的回复: 字节=32 时间=236ms TTL=41
来自 144.34.179.161 的回复: 字节=32 时间=235ms TTL=41
144.34.179.161 的 Ping 统计信息:
数据包: 已发送 = 4,已接收 = 4,丢失 = 0 (0% 丢失),
往返行程的估计时间(以毫秒为单位):
最短 = 228ms,最长 = 236ms,平均 = 233ms
2、windows上配置telnet服务:如下图,需要重启电脑
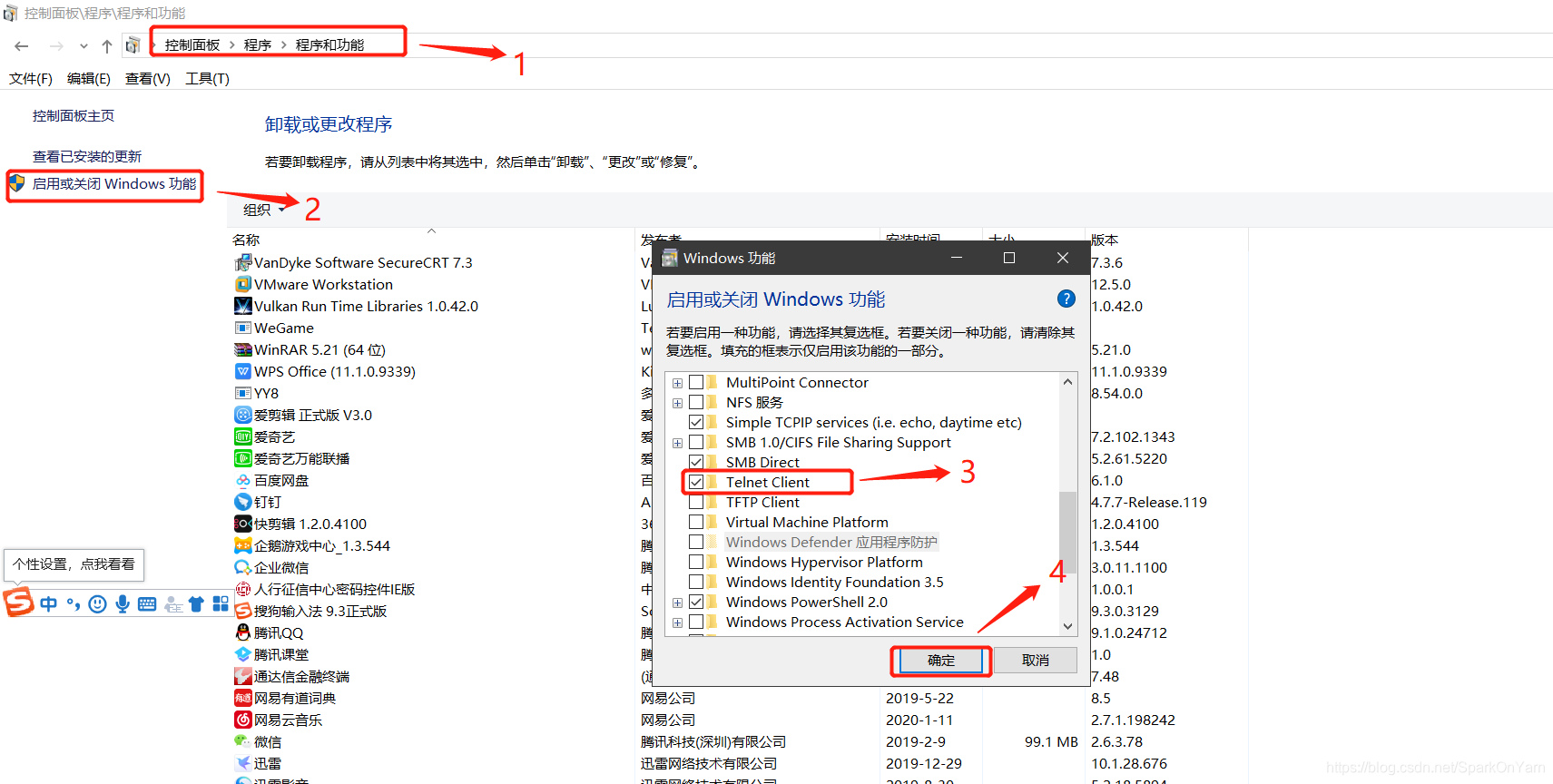
2、linux机器上安装telnet服务:
[root@hadoop001 ~]# yum install -y telnet
[root@hadoop001 ~]# telnet 47.98.238.163 80
Trying 47.98.238.163...
Connected to 47.98.238.163.
Escape character is '^]'.
3、linux中如何识别云主机的内网IP
[root@hadoop ~]# ifconfig
eth0 Link encap:Ethernet HWaddr 52:54:00:B7:5D:8C
inet addr:172.17.0.5 Bcast:172.17.15.255 Mask:255.255.240.0
inet6 addr: fe80::5054:ff:feb7:5d8c/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:1887747 errors:0 dropped:0 overruns:0 frame:0
TX packets:1928101 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:154096543 (146.9 MiB) TX bytes:276296393 (263.4 MiB)
4、windows上查询本机ip:
ipconfig
问题:老板说去A服务器登录,打开XXX软件的web界面?
- 无非就是ps -ef|grep xxx服务对应的pid,然后再使用netstat -nlp|grep pid找到对应的port端口号。
2.6、httpd测试127.0.0.1地址访问
但是:未来在工作中可能遇到的问题:
0.0.0.0:22 代表的是当前的ip
:::22 代表的是当前的ip
125.210.74.170:22 代表的是当前的ip
127.0.0.1:22 只能本地自己访问自己,windows和其它服务器无法进行访问
localhost:22
现在httpd的服务是对外的,我们测试把它修改成127.0.0.1:80
1、测试修改,编辑文件:
vi /etc/httpd/conf/httpd.conf
#Listen 12.34.56.78:80
Listen 127.0.0.1:80
2、service httpd start
3、144.34.179.161无法访问
4、curl http://127.0.0.0:80这样是可以访问的
[root@hadoop conf]# netstat -nlp|grep http
tcp 0 0 127.0.0.1:80 0.0.0.0:* LISTEN 11482/httpd
//只有自己访问自己是不行的,idea开发代码都无法连接搞个毛
重要的注意点:
- 在生产上修改配置文件,首先要对文件进行一个拷贝,cp xxx.conf xxx.conf.20200313来进行保存一遍。
- ps 进程 xxx,夯住了,我们使用top命令进行查看。
2.7、使用kill杀进程
1、测试发现删除父进程,httpd的子进程仍然存在:
[root@hadoop conf]# ps -ef|grep http
root 11482 1 0 00:05 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 11483 11482 0 00:05 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 11484 11482 0 00:05 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 11485 11482 0 00:05 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 11486 11482 0 00:05 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 11487 11482 0 00:05 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
root 11552 11417 0 00:13 pts/0 00:00:00 grep --color=auto http
[root@hadoop conf]# kill -9 11482
[root@hadoop conf]# ps -ef|grep http
apache 11483 1 0 00:05 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 11484 1 0 00:05 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 11485 1 0 00:05 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 11486 1 0 00:05 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 11487 1 0 00:05 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
2、高位命令:
[root@hadoop conf]# ps -ef|grep http
root 11608 1 0 00:19 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 11609 11608 0 00:19 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 11610 11608 0 00:19 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 11611 11608 0 00:19 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 11612 11608 0 00:19 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 11613 11608 0 00:19 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
root 11615 11417 0 00:19 pts/0 00:00:00 grep --color=auto http
[root@hadoop conf]# echo $(pgrep -f http)
11608 11609 11610 11611 11612 11613
[root@hadoop conf]# kill -9 $(pgrep -f http)
[root@hadoop conf]# ps -ef|grep http
root 11652 11417 0 00:19 pts/0 00:00:00 grep --color=auto http
kill -9 进程pid
kill -9 进程pid 进程pid 进程pid
kill -9 $(pgrep -f 匹配关键词)
//建议:大家杀进程之前,先ps找到相关的进程,搞清楚哪些进程是你要杀的,别把别人正在写的数据给kill掉了。J总公司一般不会删除数据,只会把目录进行迁移,
2.8、yum软件的安装和卸载(卸载的时候不要去校验依赖)
- yum update
- yum install -y httpd
- yum remove httpd
- yum research httpd
比如我们过了一段时间之后,忘了安装包的名字:
1、查询我们有什么安装包
[root@hadoop ~]# rpm -qa|grep http
httpd-2.4.6-90.el7.centos.x86_64
httpd-tools-2.4.6-90.el7.centos.x86_64
2、卸载这个安装包
[root@hadoop ~]# rpm -e httpd-2.4.6-90.el7.centos.x86_64
warning: /etc/httpd/conf/httpd.conf saved as /etc/httpd/conf/httpd.conf.rpmsave
3、再次监听
[root@hadoop ~]# rpm -qa|grep http
httpd-tools-2.4.6-90.el7.centos.x86_64
[root@hadoop ~]# rpm -e httpd-tools-2.4.6-90.el7.centos.x86_64
4、卸载的时候还会校验包的依赖性:
[root@hadoop ~]# rpm -qa|grep http
httpd-2.4.6-90.el7.centos.x86_64
httpd-tools-2.4.6-90.el7.centos.x86_64
[root@hadoop ~]# rpm -e httpd-tools-2.4.6-90.el7.centos.x86_64
error: Failed dependencies:
httpd-tools = 2.4.6-90.el7.centos is needed by (installed) httpd-2.4.6-90.el7.centos.x86_64
5、那我们不校验直接把包给干掉,管它是不是什么依赖包呢
rpm -e --nodeps httpd-tools-2.4.6-90.el7.centos.x86_64
2.9、wget下载安装包、压缩、解压
1、wget下载安装包:
- [root@hadoop ~]# wget http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.16.2.tar.gz
-bash: wget: command not found
[root@hadoop ~]# yum install -y wget
2、使用zip压缩文件夹:
zip -r xxx.zip ./* 在文件夹内压缩,只包含文件
zip -r xxx.zip /ruozedata/* 在文件夹外面压缩,解压出来还会有ruozedata这个目录。
3、大数据组件的压缩包几乎都是后缀tar.g
-
tar -xzvf hadoop-2.6.0-cdh5.16.2.tar.gz 解压这个文件夹
-
tar -czvf hadoop-2.6.0-cdh5.16.2.tar.gz hadoop-2.6.0-cdh5.16.2 把hadoop-2.6.0进行压缩
-c, --create create a new archive 建立压缩文档
-v, --verbose verbosely list files processed 显示所有过程
-f, --file=ARCHIVE use archive file or device ARCHIVE -f: 使用档案名字,切记,这个参数是最后一个参数,后面只能接档案名。
-x, --extract, --get extract files from an archive 解压
-z, --gzip, --gunzip, --ungzip filter the archive through gzip 文件带有gizp属性
三、本次课程作业
1、整理vi命令
2、进程和端口号
3、连接拒绝的原因
4、高危命令之kill
5、常用的wget、rpm -qa、rpm -e、rpm -e --nodeps

















 5212
5212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









