




数据库优化方向
- 硬件(物理)
- 系统配置
- 数据库表结构
- SQL语句
从4到1,成本是逐渐增大的,因此数据库的优化上,SQL语句优化是很重要的一个方面。
基本概念
针对SQL的优化有以下基本概念需要掌握:
- 基数
- 选择性
- 直方图
- 回表
- 集群因子
- 表和表之间的关系
基数(Cardinality):某一列唯一键的数量。
例如性别这列,有男女两个不同的唯一键,其基数为2。
基数的高低反映出该例的数据分布情况。
如果某个列基数很低,该例数据分布就会非常不平衡,由于该列数据分布不均衡,会导致SQL索引可能走全表扫描,也可能走索引。
如果SQL语句是单表访问,那么可能走索引,也可能走全表扫描,还有可能走物化视图扫描。走索引的条件:返回表中5%的数据以内的时候走索引,超过5%以上走全表扫描(根本原因在回表,下面有讲到回表)。
数据量大的情况下,基数小,会走全表扫描。
数据量大的情况下,基数大,选择数据超过百分之20,会走全表扫描。
选择性(Seleciivity):基数 / 总行数 * 100%
什么样的列必须建立索引呢?
在进行SQL优化的时候,但看基数是没有意义的,必须对比总行数此案有实际意义,因而引入了选择性。
选择性大于20%,说明该列的数据比较均衡。当一个列出现在where语句中且选择性大于20%,在该列上创建索引能够提升SQL查询性能。
SQL优化核心思想:只有大表才会产生性能问题。
因此在大表建索引是优化方式之一,可以使用V$SQL_PLAN或者自动化脚本抓取表的哪一列出现在where语句中,用于建索引。
直方图(Histogram)
直方图是一种统计信息图,它使用高低不等的纵向条纹或线段表示数据分布情况。
如果没有对基数低的列收集直方图统计信息,基于成本的优化器(CBO)会认为该列数据分布是均衡的。
在做SQL优化的时候,经常需要做的工作就是帮助CBO计算出比较准确的Rows,收集直方图统计信息是一种有效的方式。如果CBO每次计算都可以得到精确的Rows,那么我们就只需要关心业务逻辑、表设计、SQL写法已经如何建立索引了,不需要担心SQL会走错执行计划。
可以使用自动化脚本抓出必须建立直方图的列。
单块读和多块读
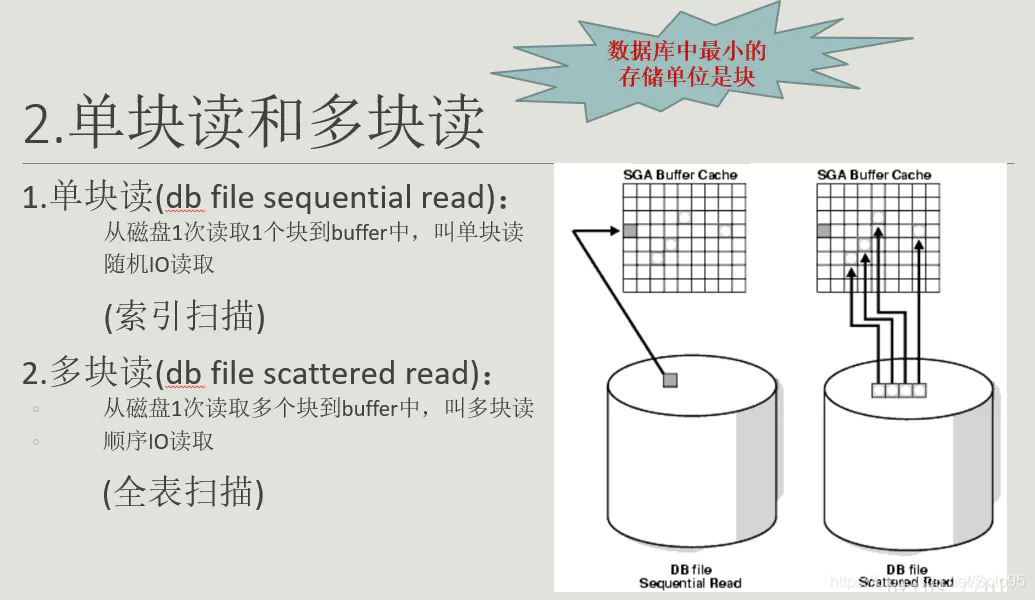
回表(Table Access By Index Rowid)
当对一个列建立索引后,索引会包含该列的键值以及对应行所在的rowid。通过索引中记录的rowid访问表中的数据就叫回表。回表一般是单块读,回表次数太多会严重影响SQL性能,如果回表次数过多,就不应该走索引扫描了,应该走全表扫描。
为什么5%的数据以内的时候走索引,超过5%以上走全表扫描?
根本原因在回表。在回表无法避免的条件下,走索引如果返回数据量太多,必然导致回表次数太多,从而导致性能严重下降。
集群因子(Clustring Factor)
集群因子用于判断索引回表需要消耗的物理I/O次数。
集群因子介于表的块数和表行数之间。
如果集群因子与块数接近,说明数据基本上是有序的,而且其顺序基本与索引一样。这样在进行索引范围或者索引全扫描的时候,回表只需要读取少量的数据块就能完成。
如果集群因子与表记录数接近,说明表的数据和索引顺序差异很大,在进行索引范围扫描或者索引全扫描的时候,回表会读取更多的数据块。
在进行SQL优化的时候,往往会建立合适的组合索引消除回表,或者建立组合索引尽量减少回表次数。
表与表之间的关系
一对一、一对多、多对多。
访问路径
| 项 | 含义 | SQL示例 |
|---|---|---|
full table scan | 全表扫描(多块读):从表中读取所有行 | |
index fast full scan | 索引快速全扫描(多块读):不需要通过rowid获取其他数据 | select id from taxidata where id = '1' |
table access by rowid | 直接通过rowid定位行,即回表 | |
index unique scan | 索引唯一扫描 | select * from taxidata where id = '1' |
index range scan | 索引局部扫描:范围定位行 select * from taxidata where id < '5' | |
index full scan | 索引全扫描:遍历索引扫描 | select id from taxidata |
常见问题
为什么有时候索引全扫描比全表扫描更慢?
取决于数据在哪:
- 数据在内存,走索引比全表扫描更快;
- 数据在磁盘:
索引扫描走的是单块读,随机IO;
全表扫描走的是多块读,顺序IO。
数量级很大的情况下,如果走索引,返回的数据越多,其所需的IO次数也越多。
知道数据库的扫描方式,与SQL优化有什么关系?
在读取数据小的时候,IO操作少,明显索引扫描性能更好;
在读取数据大的时候,IO操作多,索引性能退化,还不如全表扫描。
Explain
在SQL语句前加Explain:
explain select * from taxidata where id = '18763' (id是主键,索引列)
explain select * from taxidata where carid = '18763' (非索引列查找)
通过explain分析我们可以得到:
1.表的读取顺序(多表连接)
2.数据读取操作的操作类型
3.使用了哪些索引
4.表之间的引用
5.每张表有多少行被优化器查询
SQL语句导致全表扫描的一些例子(这些例子都应该避免使用)
- where语句中包含null值判断:
select id from a where num is full - where语句中使用不等关系符
!=<> - where中的连接条件
or,in,not in
or -> union; in ->between and - where后使用like模糊查询
这个不属于全表扫秒,补充的SQL可以优化的地方。
- where语句的判断条件包含表达式运算或者使用参数
select * from taxidatas where speed/2 = '16'(耗时1.859s)
select * from taxidatas where speed = '32'(耗时1.831s)
架构方面的优化
- 使用分区表或者分库(都是大表优化)
- 并行查询
- 历史数据定期归档
- 读写分离
大表优化
大表优化是数据库架构优化的一个重要思想。
因为如果存在大表,数据库的CRUD性能会明显下降。优化方法也很直观,需要把大表拆成小表即分库分表。
- 垂直分表:将一个表按照字段分成多表,每个表存储其中一部分字段。
- 垂直分库:垂直分库是指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,它的核心理念是专库专用。
- 水平分表:在同一个数据库内,把同一个表按照一定规则拆到多个表中。
- 水平分库:把同一个表的数据按照一定规则拆到不同的数据库中,每个库可以放在不同的服务器上。
MySQL优化技巧
MySQL优化主要分为以下四个方面:
设计:存储引擎,字段类型、范式与逆范式
功能:索引、缓存、分区分表
架构:主从复制,读写分离、负载均衡
合理SQL:经验,测试比较(上面的SQL语句优化)、
设计
存储引擎
为项目选择合适的存储引擎,在性能和可靠性上做一些取舍。
字段类型
字段类型应该要满足需求,尽量要满足以下需求。
尽可能小(占用存储空间少)、尽可能定长(占用存储空间固定)、尽可能使用整数。
范式与逆范式
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式。范式是符合某一种设计要求的总结。要想设计一个结构合理的关系型数据库,必须满足一定的范式。
第一范式1NF,原子性
第二范式2NF,消除部分依赖
第三范式3NF,消除传递依赖
逆范式
逆范式是指打破范式,通过增加冗余或重复的数据来提高数据库的性能。
在范式和逆范式之间做一些取舍。
其余部分都是一些直观的优化技巧,这里不再赘述。
参考文献
SQL优化核心思想-异步图书。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









