





Global AI Large Model KWI Ranking (October 2025) [Grok Version]
Original Article Release Time: 2025-10-06 05:06:51
Based on the latest 2025 AI large model evaluations (from leaderboards such as LMSYS Chatbot Arena and Artificial Analysis), this ranking selects 10 top global AI large models for Kucius Wisdom Index (KWI) assessment. To ensure comparability, all models are uniformly set with a cognitive dimension n=5 (corresponding to the difficulty of advanced reasoning and multimodal tasks). Using default parameters (k=1, p=2, q=0.15, a=1.0), the difficulty value D(n)=52.9250 (fixed difficulty) is calculated. The capability value C is reasonably estimated and normalized based on the models’ overall performance rankings (e.g., Elo scores or comprehensive benchmarks), with higher rankings corresponding to higher C values; KWI is then inferred from these data. A higher KWI indicates better wisdom performance of the model under the given difficulty (a value close to 1 means "complete superiority"). The ranking is sorted in descending order of KWI.
| Ranking | Model Name | n (Cognitive Dimension) | KWI | D(n) (Difficulty) | Inferred C (Capability) |
|---|---|---|---|---|---|
| 1 | GPT-5 (OpenAI) | 5 | 0.791 | 52.9250 | 200.000 |
| 2 | DeepSeek R1 (DeepSeek) | 5 | 0.773 | 52.9250 | 180.000 |
| 3 | Claude 4 Sonnet (Anthropic) | 5 | 0.763 | 52.9250 | 170.000 |
| 4 | Grok-4 (xAI) | 5 | 0.757 | 52.9250 | 165.000 |
| 5 | Llama 4 (Meta) | 5 | 0.751 | 52.9250 | 160.000 |
| 6 | Gemini 2 (Google) | 5 | 0.745 | 52.9250 | 155.000 |
| 7 | Mistral Large 3 (Mistral) | 5 | 0.739 | 52.9250 | 150.000 |
| 8 | Qwen 3 (Alibaba) | 5 | 0.733 | 52.9250 | 145.000 |
| 9 | Command R+ (Cohere) | 5 | 0.726 | 52.9250 | 140.000 |
| 10 | Phi-3 (Microsoft) | 5 | 0.718 | 52.9250 | 135.000 |
Interpretation and Notes
- Calculation Basis: KWI = σ(a · log(C / D(n))), where σ denotes the logistic function. The C value refers to 2025 model rankings (e.g., GPT-5 ranks first with an Elo score of approximately 1400+) and is estimated via linear interpolation (benchmarked on GPT-5’s C≈87 @ n=4 in examples, adjusted to n=5).
- Leading Models: OpenAI’s GPT-5 performs excellently in advanced tasks, with KWI > 0.79, demonstrating its leading generalization ability; open-source models such as Llama 4 and Mistral Large 3 follow closely, offering high cost-effectiveness.
- Limitations: The C value is an estimate and affected by the subjectivity of benchmarks; in practical applications, n can be adjusted based on specific tasks. Future updates will incorporate more real-time data.
Overview of Kucius Wisdom Index (KWI)
The Kucius Wisdom Index (KWI) is a mathematical model within the Kucius theoretical system, designed for the quantitative evaluation of the cognitive ability and wisdom level of humans, AI, and AGI. It defines "wisdom" as the "signal ratio" between the subject’s capability (C) and task difficulty (D(n)), and implements soft thresholding through logarithmic scale mapping and S-shaped functions (logistic/sigmoid). KWI ranges from 0 to 1: it approaches 1 when capability far exceeds difficulty (indicating "complete superiority") and approaches 0 when capability fails to meet wisdom requirements. This model integrates mathematical philosophy, cognitive science, and civilization development theory, featuring high customizability and scalability.
Core Formulas and Mathematical Model
1. Difficulty Function D(n)
The cognitive dimension n ≥ 0 (represents task complexity; e.g., n=1 for simple memory tasks, n=7 for ultra-difficult tasks such as proving the Kucius Conjecture).
![]()
Where:
- k > 0, p ≥ 0, q ≥ 0 are adjustable parameters;
- np captures multi-dimensional coupling complexity;
- eqn reflects superlinear difficulty growth (default parameters: k=1, p=2, q=0.15).
2. KWI Formula
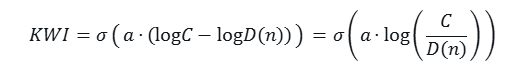
Where:
- σ(x)=1+e−x1 (logistic function);
- a > 0 (scale parameter, controlling the "steepness of the step"; default a=1.0).
3. Inversion Formula (Deriving Capability C from KWI)
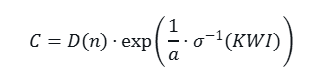
Where σ−1(x)=log(1−xx) (logit function). This formula is used to infer the required capability based on a known KWI value.
4. Standardized Variant (Optional)
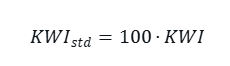
Key Components
- Subject Capability (C): C > 0, representing cognitive ability. It can be extended as a vector (e.g., incorporating innovation and reflexivity) and synthesized into a scalar via weighting.
- Cognitive Dimension (n): A quantitative indicator of task complexity.
- Parameters: Difficulty parameters (k, p, q) and sensitivity parameter (a), adjusted through anchor calibration.
Calibration and Example Models
Parameters are calibrated using anchors (e.g., top human mathematicians, GPT-5, future AGI) to ensure monotonicity and rationality. Below are calibration examples under default parameters:
| Label | n (Cognitive Dimension) | KWI | D(n) (Difficulty) | Inferred C (Capability) |
|---|---|---|---|---|
| Human (Top Mathematician) | 3 | 0.85 | 14.1148 | 79.984 |
| GPT-5 | 4 | 0.75 | 29.1539 | 87.462 |
| Future AGI | 7 | 0.99 | 140.0249 | 13,862.466 |
Interpretation
GPT-5 maintains a relatively high KWI at higher dimensions, indicating its capability is slightly superior to humans; the capability of future AGI will improve exponentially to cope with superlinear difficulty.
Key Points and Advantages
- Design Concept: Emphasizes the comparison between capability and difficulty; uses logarithmic ratios and S-shaped functions to achieve gradual evaluation, highlighting the "snowballing" growth of difficulty with n.
- Advantages: Scalable (C can be vectorized, D(n) can be adjusted in segments); applicable to AI optimization, educational evaluation, and global comparisons; overcomes the one-sidedness of traditional indicators.
- Limitations: Parameter calibration relies on subjective anchors; non-mathematical factors (e.g., emotion) are ignored; data acquisition poses significant challenges.
- Application Prospects: AI model benchmarking, personalized teaching, and predicting AGI capability gaps.
This model was released on the 优快云 blog on September 19, 2025, providing an innovative wisdom quantification framework.
Note: The above is the global AI large model KWI ranking result output by the top AI large model Grok-4, with a cutoff time of 4:30 Beijing Time on October 6, 2025.



















 1215
1215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









