




 本文通过使用Python的pandas、numpy和matplotlib库导入数据,并利用sklearn库进行数据切分及线性回归模型训练,展示了如何从数据预处理到模型评估的完整流程。文章最后通过可视化工具直观地呈现了训练集和测试集上的模型表现。
本文通过使用Python的pandas、numpy和matplotlib库导入数据,并利用sklearn库进行数据切分及线性回归模型训练,展示了如何从数据预处理到模型评估的完整流程。文章最后通过可视化工具直观地呈现了训练集和测试集上的模型表现。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
dataset = pd.read_csv(‘C:\Users\Administrator\Desktop\ml 100day\MLDayTwoData.csv’)
#创建X和Y,注意一点dataframe切片包左不包右
X = dataset.iloc[ : , :1].values
Y = dataset.iloc[ : ,1].values
#由于数据量小没有存在脏数据一目了然,不需要percenttime统计空值异常值等
#直接进行数据切分,注意random_state选的数字一样,那么每次切分所得也都一样
from sklearn.model_selection import train_test_split
#创建切分器对象
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.25,random_state=0)
from sklearn.linear_model import LinearRegression
#创建线型回归对象
lr = LinearRegression()
lr = lr.fit(X_train,Y_train)
#预测结果
Y_pred = lr.predict(X_test)
#Visualization可视化
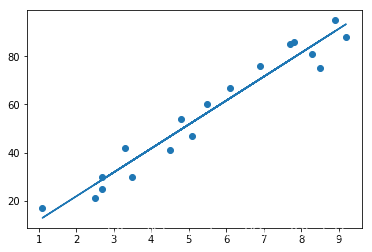
#训练集结果可视化
plt.scatter(X_train,Y_train)
plt.plot(X_train,lr.predict(X_train))
plt.show()
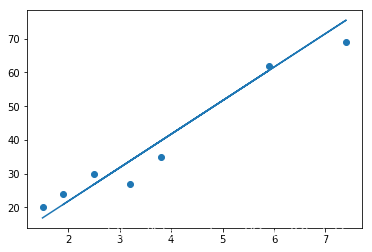
#测试集结果可视化
plt.scatter(X_test,Y_test)
plt.plot(X_test,lr.predict(X_test))
plt.show()

















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









