




Explain 详解
|
Id |
该语句的唯一标识 |
|
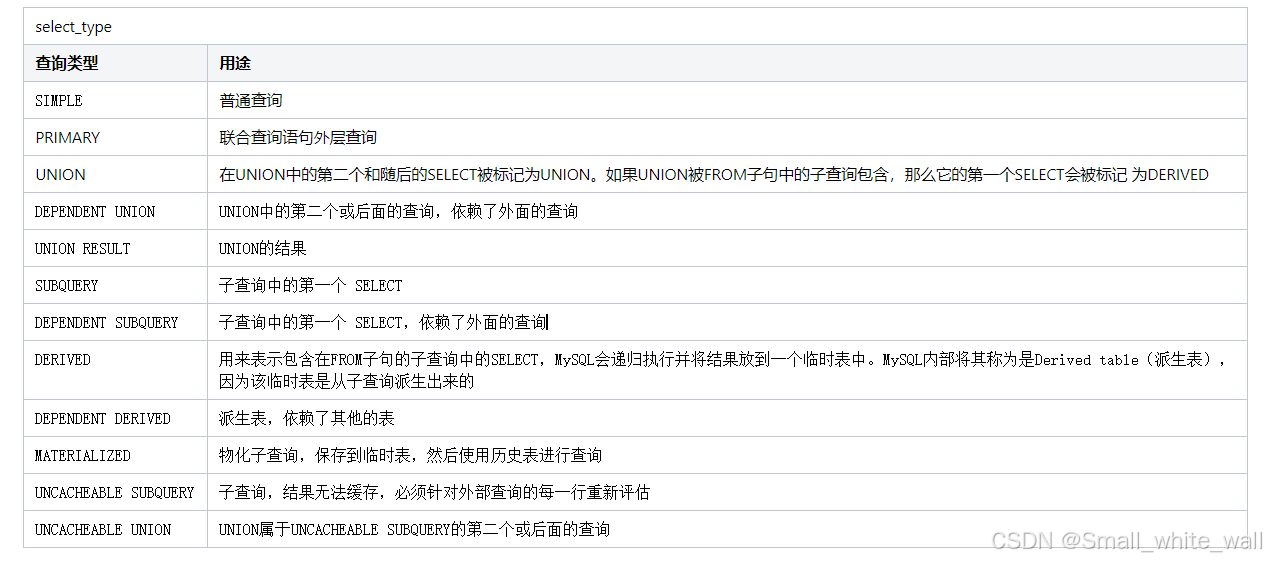
select_type(重点) |
查询类型 |
|
table |
所访问的数据库中表的名称 |
|
partitions |
匹配的分区,查询表有分区时会显示 |
|
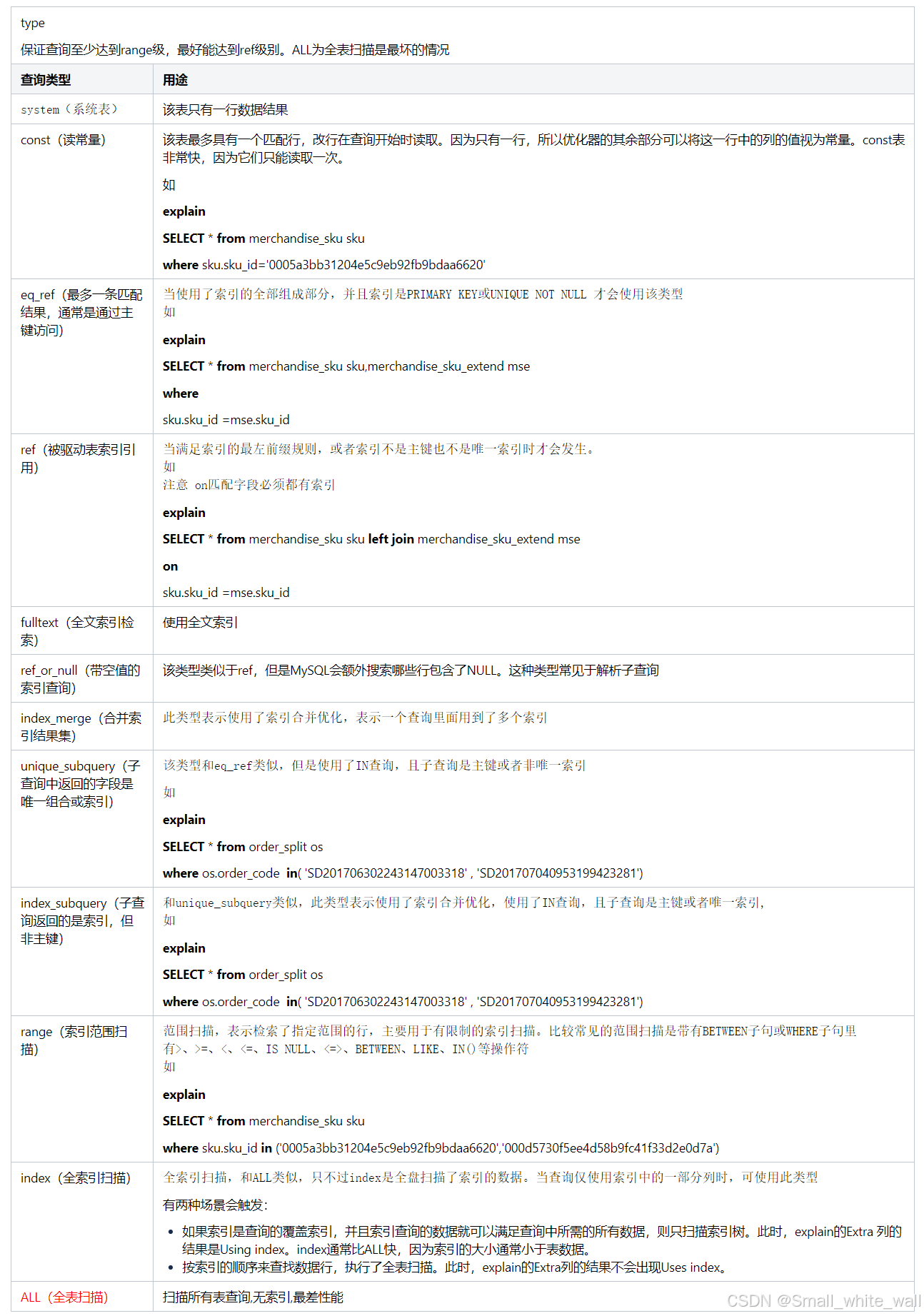
type(重点) |
联合查询使用的类型,是较重要的指标。一般来说,保证查询至少达到range级, 最好能达到ref级别。ALL为全表扫描是最坏的情况,这种情况往往是没用上索引。 结果值从好到坏依次是 |
|
possible_keys |
指出 MySQL 能使用哪个索引在该表中找到该行。如果这个值是空的则表示没有相关的索引。 这时要提高性能,可通过检测where子句,看看是否引用了某些字段,或者检查字段是否适合索引 |
|
key |
MySQL 实际决定使用的键。如果没有索引被选择,键是 NULL |
|
key_len |
显示 MySQL 决定使用的键长度。如果键是 NULL,长度就是NULL。 注意这个值可以反映出一个多主键(复合主键)里的 MySQL 实际使用了哪些部分 |
|
ref |
显示哪个字段或常数与 key 一起被使用 |
|
rows(重点) |
这个值表示 MySQL 要遍历多少数据才能找到所需的结果集,在 InnoDB 上是不准确的,值越小越好 |
|
filtered |
按表条件过滤的行百分比 |
|
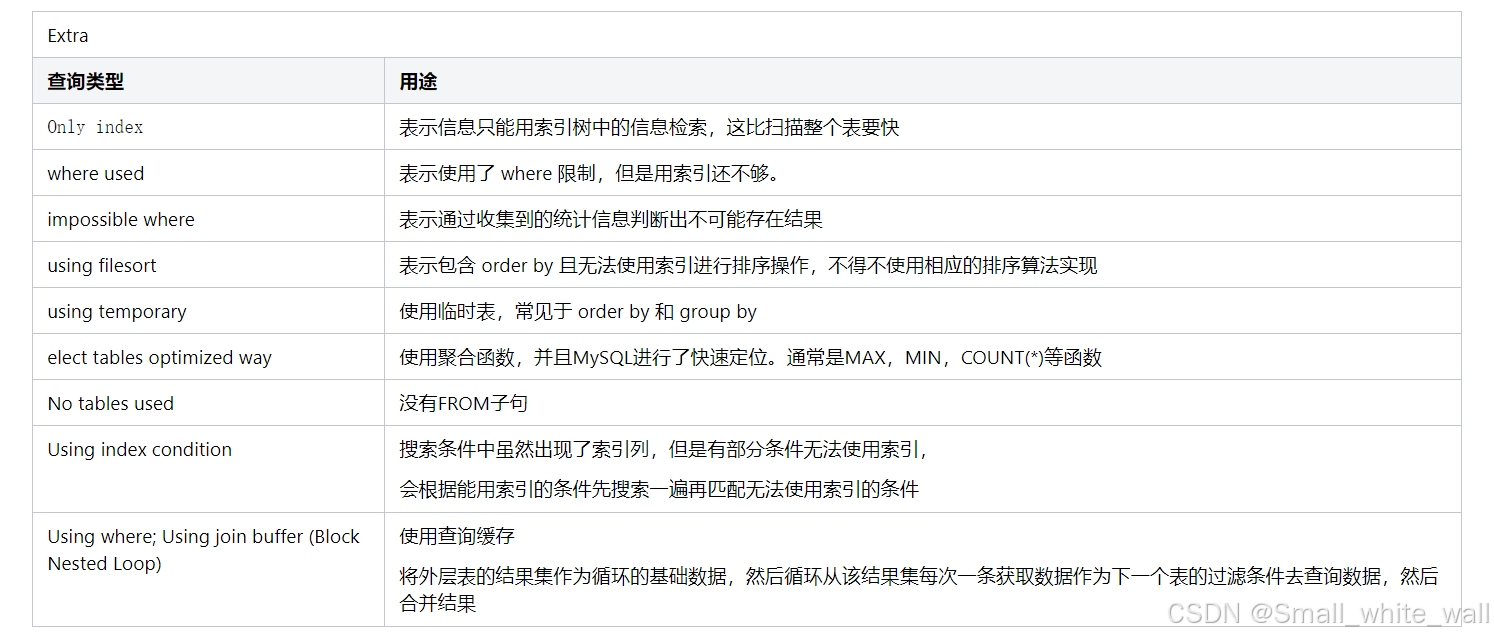
Extra |
附加信息 |
性能调优解释
一、 性能的定义
二、 什么情况下需要性能优化
三、 性能优化
四、 慢查询日志
对于数据类型上的优化
Sql语句的调优
一、SQL语句中IN包含的值不应过多
MySQL对于IN做了相应的优化,即将IN中的常量全部存储在一个数组里面,而且这个数组是排好序的。但是如果数值较多,产生的消耗也是比较大的。例如:select id from table_name where num in(1,2,3),对于连续的数值,能用 between 就不要用 in
二、SELECT语句务必指明字段名称
SELECT *增加很多不必要的消耗(cpu、io、内存、网络带宽);增加了使用覆盖索引的可能性;当表结构发生改变时,前断也需要更新。所以要求直接在select后面接上字段名。
三、当只需要一条数据的时候,使用limit 1
这是为了使EXPLAIN中type列达到const类型
四、给排序字段增加索引,如果排序字段没有用到索引,就尽量少排序
五、如果限制条件中其他字段没有索引,尽量少用or
or两边的字段中,如果有一个不是索引字段,而其他条件也不是索引字段,会造成该查询不走索引的情况。很多时候使用 union all 或者是union(必要的时候)的方式来代替“or”会得到更好的效果
六、尽量用union all代替union
union 和 union all 的差异主要是前者需要将结果集合并后再进行唯一性过滤操作,这就会涉及到排序,增加大量的CPU运算,加大资源消耗及延迟。当然,union all 的前提条件是两个结果集没有重复数据。
七、不使用ORDER BY RAND()
select id from `table_name` order by rand() limit 1000;
上面的sql语句,可优化为
select id from `table_name` t1 join (select rand() * (select max(id) from `table_name`) as nid) t2 on t1.id > t2.nid limit 1000
八、区分in和exists, not in和not exists
区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询。所以IN适合于外表大而内表小的情况;EXISTS适合于外表小而内表大的情况。

















 4592
4592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









