




 本文探讨了大模型部署中的挑战,如内存管理、动态形状和速度问题,以及如何通过模型并行、量化技术、Transformer优化和LMDeploy的量化、推理引擎TurboMind和推理服务apiserver来解决这些问题。
本文探讨了大模型部署中的挑战,如内存管理、动态形状和速度问题,以及如何通过模型并行、量化技术、Transformer优化和LMDeploy的量化、推理引擎TurboMind和推理服务apiserver来解决这些问题。
大模型部署背景
大模型特点
内存开销
- 巨大庞大的参数量。 7B 模型仅权重就需要 14+G 内存
- 采用自回归生成 token,需要缓存 Attention 的 k/v,带来巨大的内存开销
动态shape
- 请求数不固定
- Token逐个生成,且数量不定
相对视觉模型,LLM结构简单
- Transformers结构,大部分时decoder-only
大模型部署挑战
- 设备:存储问题
- 推理:token生成速度;动态shape,让推理不间断
- 服务:提升系统整体吞吐量;降低个体用户响应时间
大模型部署方案
- 技术点:模型并行;低比特量化;transformer计算和访存优化;continuous batch
- 方案

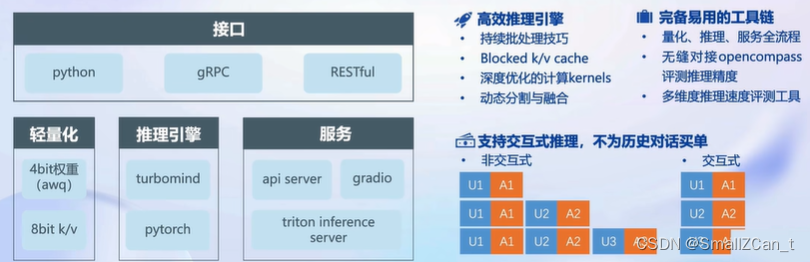
LMDeploy简介
LMDeploy时LLM在英伟达设备上部署的全流程解决方案。包括模型轻量化、推理和服务。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1937
1937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









