



文件索引和搜索系统 (IFD - Intelligent File Discovery)
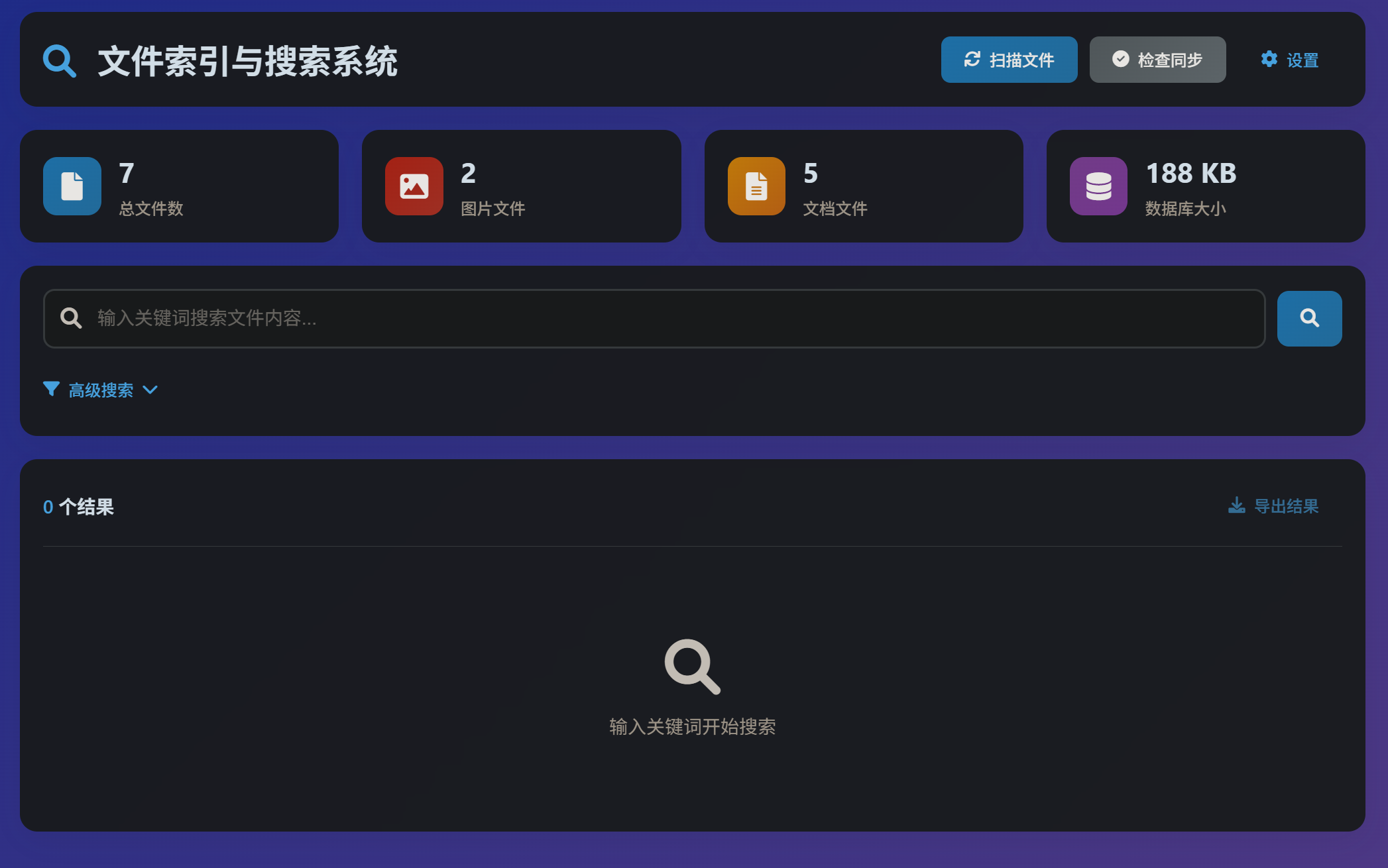
扫描支持多种ocr直接把图片内容拾取
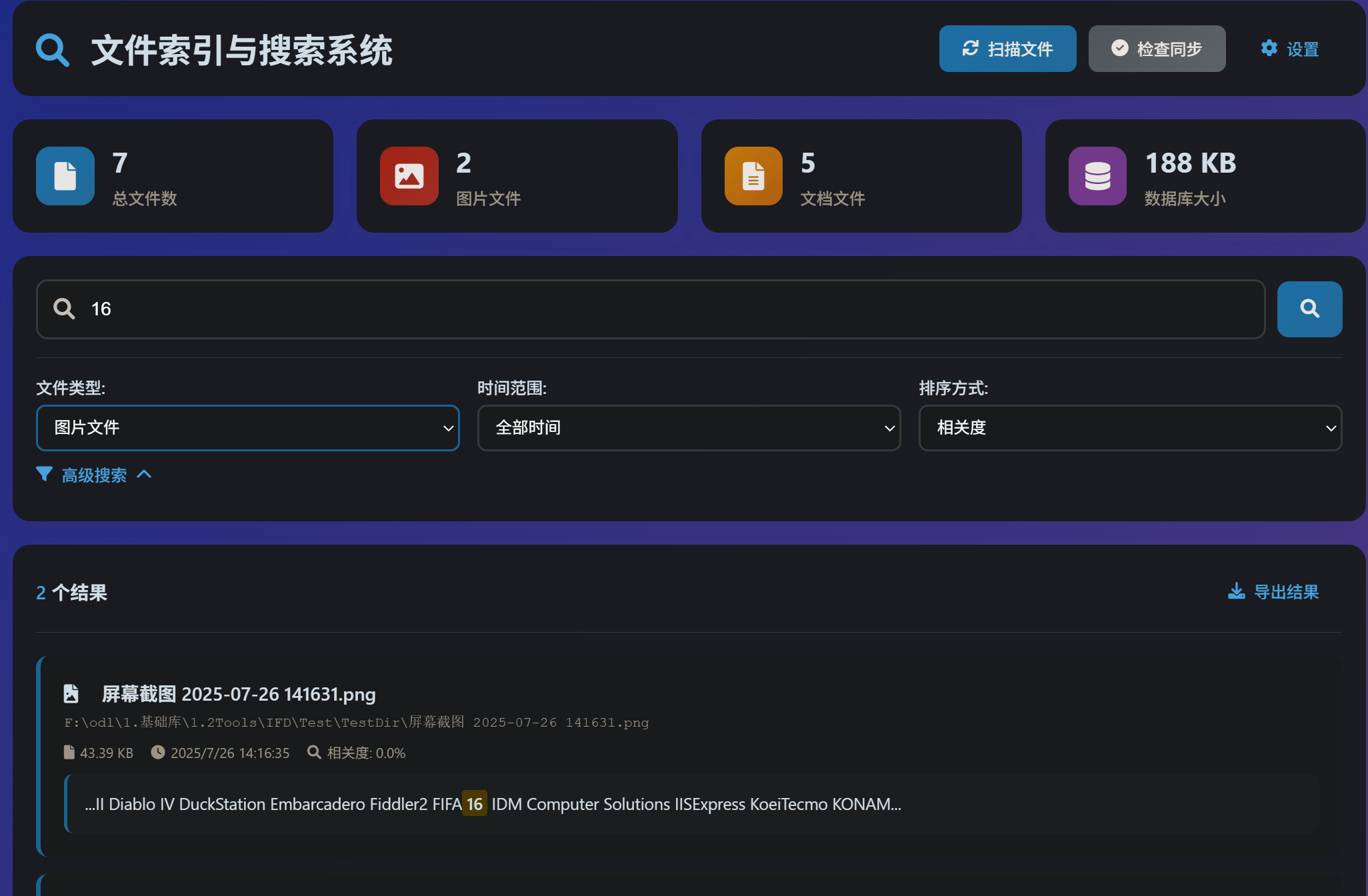
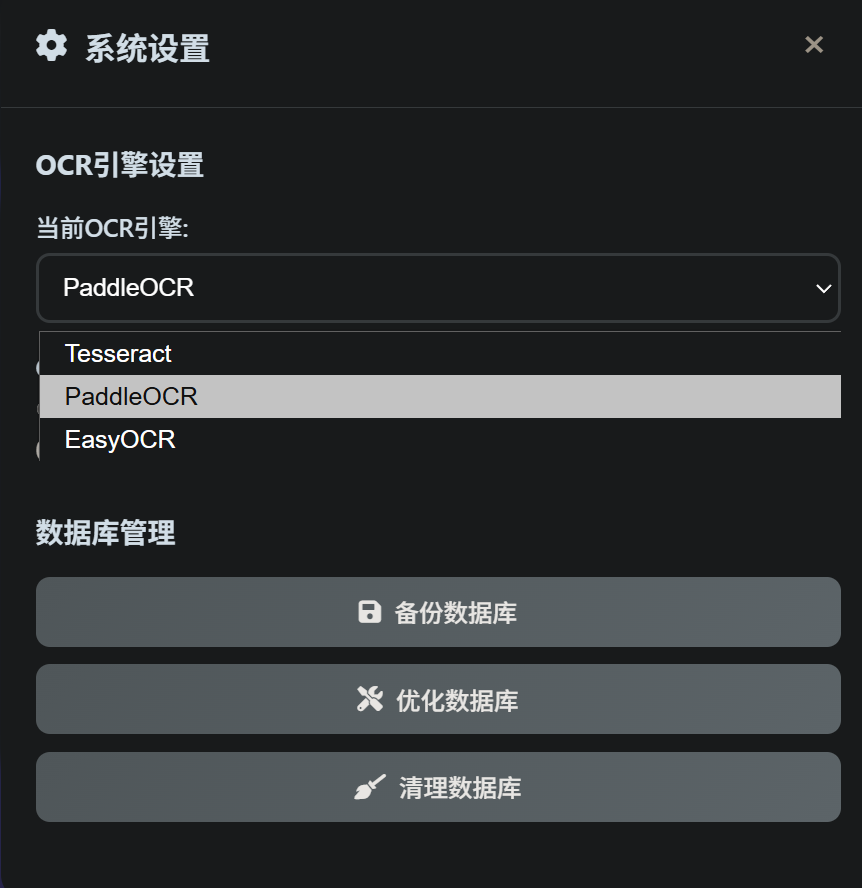
文件检索扫描后(耗时,特别图片识别,中文准确率选paddle,easyocr 中等,Tesseract 低一些,可能我没优化的缘故),入系统库后,直接搜索关键字,可以找到图片上出现过的文字内容,并找到相关文件在哪里。
应用场景:找文件,凭印象找文件,支持TXT, DOC/DOCX, PDF, PPT/PPTX, Excel,JPG, PNG, GIF, BMP (支持中英文)文档内,基本100%可以导入系统,图片识别不敢保证,但基本够用。
文件索引和搜索系统 (IFD - Intelligent File Discovery)
一个智能的文件索引和搜索系统,支持多种文件格式的内容识别和全文搜索。
📋 目录
🚀 功能特性
📁 文件扫描
- 支持递归扫描指定目录
- 自动识别文件类型
- 智能跳过: 基于文件指纹的增量扫描,避免重复处理
- 支持进度显示和实时反馈
🔍 内容识别
- 文档处理: TXT, DOC/DOCX, PDF, PPT/PPTX, Excel
- 图片OCR: JPG, PNG, GIF, BMP (支持中英文)
- 模块化设计: 可轻松更换识别引擎
🗄️ 数据库管理
- 使用SQLite数据库
- 自动创建表结构和索引
- 支持文件哈希去重
- 内容全文索引
- 数据库备份和恢复
- 数据库优化和清理
- 文件同步检查: 自动检测和修正数据库与物理文件的不一致
🔎 搜索功能
- 全文搜索
- 按文件类型搜索
- 按时间范围搜索
- 按文件路径搜索
- 智能内容预览
- 相关度排序
- 高级过滤: 多文件类型、时间范围、排序选项
🌐 Web界面
- 现代化界面: 响应式设计,支持移动端
- 实时搜索: 输入关键词即时搜索
- 高级过滤: 文件类型、时间范围、排序选项
- 结果预览: 文件内容预览
- 导出功能: CSV格式导出搜索结果
- 系统管理: 扫描控制、数据库管理、OCR设置
- 统计信息: 实时文件统计和数据库信息
🖼️ 多OCR引擎支持
- pytesseract: 默认引擎,适合英文/数字/常规文档
- paddleocr: 推荐中文场景,识别率高,首次加载慢
- easyocr: 安装简单,支持多语言,适合快速体验
- 动态切换: 可通过命令行或Web界面切换
🏗️ 系统架构
IFD/
├── src/
│ ├── config.py # 配置管理
│ ├── database.py # 数据库管理
│ ├── scanner.py # 文件扫描器
│ ├── search.py # 搜索引擎
│ ├── api.py # Web API
│ ├── logger_config.py # 日志配置
│ ├── static/ # Web界面
│ │ ├── index.html
│ │ ├── style.css
│ │ └── script.js
│ └── processors/ # 文件处理器
│ ├── base_processor.py
│ ├── text_processor.py
│ ├── doc_processor.py
│ ├── excel_processor.py
│ ├── pdf_processor.py
│ ├── ppt_processor.py
│ ├── image_processor.py
│ └── processor_factory.py
├── data/ # 数据库文件
├── logs/ # 日志文件
├── main.py # 主程序入口
├── cli.py # 命令行工具
├── start_gui.py # Web GUI启动脚本
├── requirements.txt # 依赖包
└── README.md # 说明文档
📦 安装说明
系统要求
- 操作系统: Windows 10/11 (推荐)
- Python: 3.8 或更高版本
- 内存: 建议 4GB 以上
- 磁盘空间: 至少 2GB 可用空间
安装步骤
Windows用户 (推荐):
# 使用批处理脚本自动安装
start_service.bat
手动安装:
# 创建虚拟环境
python -m venv .venv
# 激活虚拟环境
.venv\Scripts\activate # Windows
source .venv/bin/activate # Linux/macOS
# 安装依赖
pip install -r requirements.txt
# 复制配置文件
copy config.env.example .env
配置环境变量
编辑 .env 文件:
# 扫描路径(多个路径用逗号分隔)
SCAN_PATHS=C:\Users\YourName\Documents,D:\Work
# 数据库路径
DATABASE_PATH=./data/file_index.db
# OCR引擎设置
OCR_ENGINE=pytesseract
OCR_CONFIDENCE_THRESHOLD=0.5
# 服务器设置
HOST=127.0.0.1
PORT=8000
OCR引擎安装 (可选)
如果需要图片OCR功能,请安装Tesseract:
Windows:
- 下载并安装 Tesseract
- 将安装路径添加到环境变量
Linux:
sudo apt-get install tesseract-ocr
sudo apt-get install tesseract-ocr-chi-sim # 中文简体
macOS:
brew install tesseract
brew install tesseract-lang # 语言包
🚀 快速开始
1. 启动系统
# 启动Web GUI
python start_gui.py
# 或启动API服务
python main.py
2. 访问Web界面
启动后访问: http://127.0.0.1:8000
3. 基本使用流程
- 配置扫描路径 - 在
.env文件中设置要扫描的目录 - 初始化数据库 - 创建数据库表结构
- 扫描文件 - 扫描并处理文件内容
- 搜索文件 - 使用关键词、文件类型等条件搜索
- 检查同步 - 定期检查数据库与物理文件的同步状态
🛠️ 使用方法
命令行工具
基础操作
# 初始化数据库
python cli.py db-init
# 扫描文件
python cli.py scan
# 搜索文件
python cli.py search -k "关键词"
# 查看统计
python cli.py stats
# 查看配置
python cli.py config
数据库管理
# 重置数据库 (自动备份)
python cli.py db-reset
# 备份数据库
python cli.py db-backup
# 恢复数据库
python cli.py db-restore backup.db
# 优化数据库
python cli.py db-optimize
# 查看数据库信息
python cli.py db-info
# 列出备份文件
python cli.py db-backups
OCR引擎管理
# 查看OCR引擎信息
python cli.py ocr-info
# 设置OCR引擎
python cli.py ocr-set paddleocr
# 查看OCR配置
python cli.py ocr-config
文件同步检查
# 检查并修正文件同步状态
python cli.py check
🌐 Web界面功能
搜索功能
- 实时搜索: 输入关键词即时搜索
- 高级过滤: 文件类型、时间范围、排序选项
- 结果预览: 文件内容预览
- 导出功能: CSV格式导出搜索结果
系统管理
- 扫描控制: 开始/停止文件扫描
- 实时进度: 扫描进度实时显示
- 数据库管理: 备份、优化操作
- OCR设置: 引擎切换、参数配置
统计信息
- 文件统计: 总文件数、图片文件、文档文件
- 数据库信息: 数据库大小、最后扫描时间
- 实时更新: 操作后自动刷新统计
🗄️ 数据库管理
备份和恢复
- 自动备份: 重置数据库时自动创建备份
- 手动备份: 随时创建数据库备份
- 备份恢复: 从备份文件恢复数据库
- 备份管理: 查看备份文件
优化和清理
- 数据库优化: 重建索引、清理空间、删除孤立记录
- 性能监控: 查看数据库大小、记录数等
文件同步检查
- 自动检测: 检测数据库记录与物理文件的不一致
- 自动修正: 自动修正不一致的记录
- 详细报告: 提供详细的同步检查报告
安全特性
- 备份保护: 重要操作前自动备份
- 数据完整性: 外键约束保证数据一致性
- 错误恢复: 操作失败时的回滚机制
🔧 OCR引擎管理
引擎选择
- pytesseract: 默认引擎,适合英文/数字/常规文档,依赖Tesseract本地安装
- paddleocr: 适合中文、复杂场景,需安装
paddlepaddle和paddleocr,识别率高,首次加载慢 - easyocr: 安装简单,支持多语言,适合快速体验
切换方法
- 配置文件设置:
OCR_ENGINE=easyocr - 命令行切换:
python cli.py ocr-set easyocr - 查看当前引擎:
python cli.py ocr-info
依赖安装
pip install pytesseract pillow
pip install paddlepaddle paddleocr
pip install easyocr
优化建议
- 图片模糊、低分辨率、复杂背景会影响识别效果,建议开启图片预处理(默认已开启)
- 可调整
.env中OCR_CONFIDENCE_THRESHOLD提高置信度过滤 - 多引擎对比:如识别效果不理想,可切换引擎尝试
- 详细日志可在
./logs/app.log查看
🌐 API接口
基础操作
# 扫描文件
curl -X POST "http://127.0.0.1:8000/api/scan"
# 搜索文件
curl -X POST "http://127.0.0.1:8000/api/search" \
-H "Content-Type: application/json" \
-d '{"query": "财务报表"}'
# 获取统计
curl "http://127.0.0.1:8000/api/statistics"
数据库管理
# 备份数据库
curl -X POST "http://127.0.0.1:8000/api/db/backup"
# 优化数据库
curl -X POST "http://127.0.0.1:8000/api/db/optimize"
# 获取数据库信息
curl "http://127.0.0.1:8000/api/db/info"
# 获取备份列表
curl "http://127.0.0.1:8000/api/db/backups"
OCR管理
# 获取OCR信息
curl "http://127.0.0.1:8000/api/ocr-info"
# 设置OCR引擎
curl -X POST "http://127.0.0.1:8000/api/ocr-set" \
-H "Content-Type: application/json" \
-d '{"engine": "paddleocr"}'
文件同步检查
# 检查文件同步状态
curl -X POST "http://127.0.0.1:8000/api/check"
📊 数据库结构
files 表
id: 主键file_path: 文件路径 (唯一)file_name: 文件名file_size: 文件大小file_type: 文件类型created_time: 创建时间modified_time: 修改时间file_hash: 文件哈希值is_processed: 是否已处理
file_contents 表
id: 主键file_id: 文件ID (外键)content_type: 内容类型 (text/ocr_text)content: 文件内容
search_index 表
id: 主键file_id: 文件ID (外键)keyword: 关键词position: 位置
🔧 故障排除
常见问题
-
OCR功能不可用
- 检查Tesseract是否正确安装
- 确认环境变量设置
- 尝试切换OCR引擎
-
文件处理失败
- 检查文件是否损坏
- 确认文件格式支持
- 查看日志文件
-
数据库错误
- 检查数据库文件权限
- 确认磁盘空间充足
- 尝试数据库优化或清理
-
备份恢复失败
- 确认备份文件完整性
- 检查备份文件路径
- 验证备份文件格式
-
Web界面无法访问
- 检查端口是否被占用
- 确认防火墙设置
- 查看服务器日志
-
依赖包安装失败
- 检查网络连接
- 使用国内镜像源:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
-
扫描路径配置错误
- 确保路径存在且有访问权限
- 路径中使用正斜杠(/)或双反斜杠(\)
- 多个路径用逗号分隔,不要有空格
获取帮助
- 查看日志:
./logs/app.log - 系统状态:
python cli.py db-info - 配置检查:
python cli.py config - OCR信息:
python cli.py ocr-info
🔧 扩展开发
添加新的文件处理器
- 继承
BaseProcessor类 - 实现必要的方法
- 在
ProcessorFactory中注册
from .base_processor import BaseProcessor
class CustomProcessor(BaseProcessor):
def can_process(self, file_path: str) -> bool:
return file_path.lower().endswith('.custom')
def process(self, file_path: str) -> Dict[str, Any]:
# 实现处理逻辑
pass
def get_supported_extensions(self) -> list:
return ['.custom']
更换OCR引擎
from src.processors.image_processor import ImageProcessor
# 创建新的OCR引擎
class CustomOCREngine:
def image_to_string(self, image, lang=None, config=None):
# 实现OCR逻辑
pass
# 替换OCR引擎
image_processor = ImageProcessor()
image_processor.set_ocr_engine(CustomOCREngine())
📚 文档资源
- API文档: 启动后访问 http://127.0.0.1:8000/docs
- 项目地址: [GitHub Repository]
- 问题反馈: [Issues]
📄 许可证
MIT License
🤝 贡献
欢迎提交Issue和Pull Request!
版本: 1.0
更新时间: 2025-01-26


















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









