







 ROUGE评价算法基于召回率,用于衡量候选摘要与参考摘要的相似度。ROUGE-N计算共同n-gram,直观但区分度有限;ROUGE-L利用最长公共子序列,考虑词序,适用于单文档和短摘要评估。在某些情况下,不同候选摘要可能得分相同,但实际意义不同。
ROUGE评价算法基于召回率,用于衡量候选摘要与参考摘要的相似度。ROUGE-N计算共同n-gram,直观但区分度有限;ROUGE-L利用最长公共子序列,考虑词序,适用于单文档和短摘要评估。在某些情况下,不同候选摘要可能得分相同,但实际意义不同。
ROUGE(
Recall-Oriented Understudy for Gisting Evaluation)
,在2004年
由
ISI
的Chin-Yew
Lin
提出的一种自动摘要评价方法,现被广泛应用于
DUC(
Document Understanding Conference
)的摘要评测任务中。
ROUGE
基于摘要中
n
元词(
n-gram
)的共现信息来评价摘要,是一种面向
n
元词召回率的评价方法。基本思想为由多个专家分别生成人工摘要,构成标准摘要集,将系统生成的自动摘要与人工生成的标准摘要相对比,通过统计二者之间重叠的基本单元(n元语法、词序列和词对)的数目,来评价摘要的质量。通过与专家人工摘要的对比,提高评价系统的稳定性和健壮性。该方法现已成为摘要评价技术的通用标注之一。
ROUGE
准则由一系列的评价方法组成,包括
ROUGE-N(N=1、2、3、4,分别代表基于1元词到4元词的模型)
,
ROUGE-L,ROUGE-S, ROUGE-W,
ROUGE-SU
等。在自动文摘相关研究中,一般根据自己的具体研究内容选择合适的
ROUGE
方法。
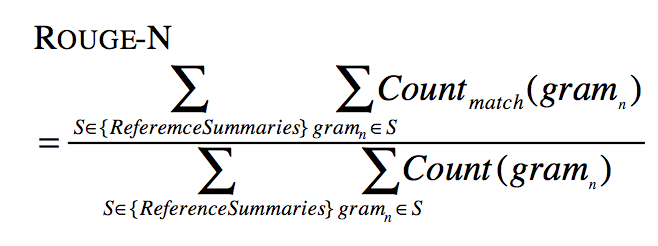
其中,n表示n-gram的长度,{
Reference Summaries}表示参考摘要,即事先获得的标准摘要,![]() 表示候选摘要和参考摘要中同时出现n-gram的个数,
表示候选摘要和参考摘要中同时出现n-gram的个数,![]() 则表示参考摘要中出现的n-gram个数。不难看出,ROUGE公式是由召回率的计算公式演变而来的,分子可以看作“检出的相关文档数目”,即系统生成摘要与标准摘要相匹配的N-gram个数,分母可以看作“相关文档数目”,即标准摘要中所有的
则表示参考摘要中出现的n-gram个数。不难看出,ROUGE公式是由召回率的计算公式演变而来的,分子可以看作“检出的相关文档数目”,即系统生成摘要与标准摘要相匹配的N-gram个数,分母可以看作“相关文档数目”,即标准摘要中所有的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 800
800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









