




无锁编程是一种并发编程的技术,旨在避免使用传统的锁机制来保护共享数据。相比有锁编程,无锁编程可以提供更高的并发性能和可伸缩性。在无锁编程中,线程或进程通过使用原子操作、CAS(Compare-and-Swap)等技术来实现对共享数据的访问和修改,而不需要依赖互斥锁。
无锁编程常用于高并发场景,如网络服务器、多线程应用程序等。它可以减少线程之间的竞争和阻塞,并且能够充分利用多核处理器的计算能力。然而,由于无锁编程对开发者要求较高,在设计和实现上也更加复杂,需要考虑线程安全性、内存模型等因素。
一、无锁编程概述
1.1什么是无锁编程
无锁编程,即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(Non-blocking Synchronization),实现非阻塞同步的方案称为“无锁编程算法”。
为什么要非阻塞同步,使用lock实现线程同步有非常多缺点:
-
产生竞争时,线程被阻塞等待,无法做到线程实时响应
-
dead lock
-
live lock
-
优先级反转
-
使用不当,造成性能下降
假设在不使用 lock 的情况下,实现变量同步,那就会避免非常多问题。尽管眼下来看,无锁编程并不能替代 lock。
实现级别
非同步阻塞的实现分为三个级别:wait-free/lock-free/obstruction-free
(1)wait-free
-
最理想的模式,整个操作保证每一个线程在有限步骤下完毕
-
保证系统级吞吐(system-wide throughput)以及无线程饥饿
-
截止2011年,没有多少详细的实现。即使实现了,也须要依赖于详细CPU
(2)lock-free
-
同意个别线程饥饿,但保证系统级吞吐。
-
确保至少有一个线程可以继续运行。
-
wait-free的算法必然也是lock-free的。
(3)obstruction-free
在不论什么时间点,一个线程被隔离为一个事务进行运行(其它线程suspended),而且在有限步骤内完毕。在运行过程中,一旦发现数据被改动(採用时间戳、版本),则回滚,也叫做乐观锁,即乐观并发控制(OOC)。
事务的过程是:
-
读取,并写时间戳
-
准备写入,版本号校验
-
检验通过则写入,检验不通过,则回滚
lock-free必然是obstruction-free的。
1.2为什么要无锁?
首先是性能考虑。通信项目一般对性能有极致的追求,这是我们使用无锁的重要原因。当然,无锁算法如果实现的不好,性能可能还不如使用锁,所以我们选择比较擅长的数据结构和算法进行lock-free实现,比如Queue,对于比较复杂的数据结构和算法我们通过lock来控制,比如Map(虽然我们实现了无锁Hash,但是大小是限定的,而Map是大小不限定的),对于性能数据,后续文章会给出无锁和有锁的对比。
次要是避免锁的使用引起的错误和问题:
-
死锁(dead lock):两个以上线程互相等待
-
锁护送(lock convoy):多个同优先级的线程反复竞争同一个锁,抢占锁失败后强制上下文切换,引起性能下降
-
优先级反转(priority inversion):低优先级线程拥有锁时被中优先级的线程抢占,而高优先级的线程因为申请不到锁被阻塞。
1.3如何无锁?
在现代的 CPU 处理器上,很多操作已经被设计为原子的,比如对齐读(Aligned Read)和对齐写(Aligned Write)等。Read-Modify-Write(RMW)操作的设计让执行更复杂的事务操作变成了原子操作,当有多个写入者想对相同的内存进行修改时,保证一次只执行一个操作。
RMW 操作在不同的 CPU 家族中是通过不同的方式来支持的:
-
x86/64 和 Itanium 架构通过 Compare-And-Swap (CAS) 方式来实现
-
PowerPC、MIPS 和 ARM 架构通过 Load-Link/Store-Conditional (LL/SC) 方式来实现
在x64下进行实践的,用的是CAS操作,CAS操作是lock-free技术的基础,我们可以用下面的代码来描述:
template <class T>
bool CAS(T* addr, T expected, T value)
{
if (*addr == expected)
{
*addr = value;
return true;
}
return false;
}
在GCC中,CAS操作如下所示:
bool __sync_bool_compare_and_swap (type *ptr, type oldval type newval, ...)
type __sync_val_compare_and_swap (type *ptr, type oldval type newval, ...)
这两个函数提供原子的比较和交换,如果*ptr == oldval,就将newval写入*ptr,第一个函数在相等并写入的情况下返回true,第二个函数的内置行为和第一个函数相同,只是它返回操作之前的值。
后面的可扩展参数(...)用来指出哪些变量需要memory barrier,因为目前gcc实现的是full barrier,所以可以略掉这个参数,除过CAS操作,GCC还提供了其他一些原子操作,可以在无锁算法中灵活使用:
type __sync_fetch_and_add (type *ptr, type value, ...)
type __sync_fetch_and_sub (type *ptr, type value, ...)
type __sync_fetch_and_or (type *ptr, type value, ...)
type __sync_fetch_and_and (type *ptr, type value, ...)
type __sync_fetch_and_xor (type *ptr, type value, ...)
type __sync_fetch_and_nand (type *ptr, type value, ...)
type __sync_add_and_fetch (type *ptr, type value, ...)
type __sync_sub_and_fetch (type *ptr, type value, ...)
type __sync_or_and_fetch (type *ptr, type value, ...)
type __sync_and_and_fetch (type *ptr, type value, ...)
type __sync_xor_and_fetch (type *ptr, type value, ...)
type __sync_nand_and_fetch (type *ptr, type value, ...)
_sync_*系列的built-in函数,用于提供加减和逻辑运算的原子操作。这两组函数的区别在于第一组返回更新前的值,第二组返回更新后的值。
无锁算法感触最深的是复杂度的分解,比如多线程对于一个双向链表的插入或删除操作,如何能一步一步分解成一个一个串联的原子操作,并能保证事务内存的一致性。
1.4从传统到无锁:编程范式的转变
在并发编程的世界中,传统的锁编程曾是保障数据一致性和线程安全的中流砥柱 。就像在一场热闹的集市中,每个摊位是一个共享资源,而锁就是摊位的钥匙,线程则是想要使用摊位的商人。当一个商人拿到钥匙(获取锁)后,就能在摊位上自由交易(访问和修改资源),其他商人只能在一旁等待,直到钥匙被归还(锁被释放)。
这种方式虽然有效,但在多线程高并发的场景下,却逐渐暴露出诸多局限性。
线程阻塞是最直观的问题。当一个线程持有锁时,其他试图获取同一锁的线程就会被阻塞,进入等待状态。这就好比多个商人都想使用同一个摊位,但只有一个人能拿到钥匙,其他人只能干等着,白白浪费时间。在高并发系统中,大量线程的阻塞会导致上下文切换频繁,极大地消耗系统资源,降低了程序的执行效率 。
死锁隐患更是让人头疼。想象一下,两个商人 A 和 B,A 拿着摊位 1 的钥匙,却想要使用摊位 2;B 拿着摊位 2 的钥匙,却想要使用摊位 1。双方都不愿意放弃自己手中的钥匙,又都在等待对方释放钥匙,结果就陷入了僵局,谁也无法继续。在编程中,死锁一旦发生,程序就会陷入停滞,无法正常运行,严重影响系统的稳定性 。
传统锁编程还会带来较大的资源开销。锁的获取、释放以及维护锁的状态都需要消耗系统资源。随着线程数量的增加,这种开销会愈发明显,成为系统性能提升的瓶颈 。
为了解决这些问题,无锁编程应运而生,开启了并发编程的新篇章。它就像是一场创新的集市改革,不再依赖钥匙(锁)来分配摊位,而是通过一种更巧妙的方式,让商人们能够更高效地使用摊位资源。无锁编程摒弃了传统的锁机制,采用原子操作、CAS(Compare-And-Swap)算法等技术,实现了多线程对共享资源的无阻塞访问,让线程在访问共享资源时无需等待锁的释放,大大提高了并发性能 。
二、无锁编程的底层原理剖析
无锁编程具体使用和考虑到的技术方法包括:原子操作(atomic operations), 内存栅栏(memory barriers), 内存顺序冲突(memory order), 指令序列一致性(sequential consistency)和顺ABA现象等等。
在这其中最基础最重要的是操作的原子性或说原子操作。原子操作可以理解为在执行完毕之前不会被任何其它任务或事件中断的一系列操作。原子操作是非阻塞编程最核心基本的部分,没有原子操作的话,操作会因为中断异常等各种原因引起数据状态的不一致从而影响到程序的正确。
2.1原子操作:无锁的基石
原子操作是无锁编程的基石,它确保了指令执行的不可分割性 。就像在建造高楼时,每一块基石都必须坚实稳固,原子操作对于无锁编程也是如此,是构建整个体系的基础。在现代处理器中,简单类型的对齐读写操作通常是原子的,这意味着这些操作要么完全执行,要么完全不执行,不会出现部分执行的情况 。比如对一个int类型变量的赋值操作int a = 10;,在多线程环境下,这个赋值操作要么成功完成,将10赋值给a,要么就没有执行,不会出现只赋了一半值的情况。
而 Read-Modify-Write 操作则更进一步,允许进行更复杂的原子事务性操作 。以经典的i++操作为例,它实际上包含了读取i的值、对值进行加 1 修改、再将修改后的值写回这三个步骤。在传统的非原子操作中,这三个步骤可能会被线程调度打断,导致数据不一致 。但在无锁编程中,通过原子的 Read-Modify-Write 操作,这三个步骤被视为一个整体,不可分割,从而保证了操作的原子性和数据的一致性 。
假设线程 A 和线程 B 都要对共享变量i执行i++操作,如果没有原子操作的保证,可能会出现线程 A 读取i的值后,还没来得及写回,线程 B 就读取了相同的值,最终导致i只增加了 1,而不是 2。但有了原子操作,就能确保两个线程的i++操作都能正确执行,i最终会增加 2 。
2.2CAS 算法:核心机制解析
CAS(Compare-And-Swap)算法是无锁编程的核心机制,它如同无锁编程的 “大脑”,指挥着各个线程有序地访问共享资源 。CAS 算法包含三个参数:V(要更新的变量)、E(预期值)、N(新值) 。其工作原理是:当且仅当变量 V 的值等于预期值 E 时,才会将变量 V 的值更新为新值 N;如果 V 的值和 E 的值不同,那就说明已经有其他线程对 V 进行了更新,当前线程则什么都不做,最后 CAS 返回当前 V 的真实值 。
在一个多线程的计数器场景中,假设有多个线程都要对计数器count进行加 1 操作 。每个线程在执行加 1 操作时,会先读取count的当前值作为预期值 E,然后计算新值 N(即 E + 1),接着使用 CAS 算法尝试将count的值更新为 N 。如果此时count的值仍然等于预期值 E,说明在读取和尝试更新的过程中没有其他线程修改过count,那么更新操作就会成功;反之,如果count的值已经被其他线程修改,不等于预期值 E,更新操作就会失败,线程会重新读取count的当前值,再次尝试 。通过这种不断比较和交换的方式,CAS 算法实现了无锁同步,避免了传统锁机制带来的线程阻塞和性能开销 。
2.3内存屏障与顺序一致性
在多线程环境中,由于处理器的优化和指令重排序等原因,可能会导致内存操作的顺序与程序代码中编写的顺序不一致,从而引发数据一致性问题 。内存屏障就像是一个 “交通警察”,负责维护内存操作的顺序,确保不同线程对内存操作的顺序可见性 。内存屏障通过阻止处理器对其前后的内存操作进行重排序,使得在内存屏障之前的操作一定先于屏障之后的操作完成,从而维持了程序的顺序一致性 。
在一个简单的多线程赋值和读取场景中,线程 A 先对共享变量x进行赋值操作x = 10;,然后对另一个共享变量y进行赋值操作y = 20;;线程 B 则先读取y的值,再读取x的值 。如果没有内存屏障的保证,由于指令重排序,线程 A 的x = 10;和y = 20;操作可能会被重新排序,导致线程 B 读取到的y的值是 20,但读取到的x的值却还是初始值 0,这就破坏了程序的顺序一致性 。但通过在适当的位置插入内存屏障,就可以保证线程 A 的赋值操作按照代码顺序执行,线程 B 读取到的x和y的值也是符合预期的,从而确保了程序的正确性 。
三、无锁队列
无锁队列是lock-free中最基本的数据结构,一般应用场景是资源分配,比如TimerId的分配,WorkerId的分配,上电内存初始块数的申请等等。对于多线程用户来说,无锁队列的入队和出队操作是线程安全的,不用再加锁控制。
3.1无锁队列API
ErrCode initQueue(void** queue, U32 unitSize, U32 maxUnitNum);
ErrCode enQueue(void* queue, void* unit);
ErrCode deQueue(void* queue, void* unit);
U32 getQueueSize(void* queue);
BOOL isQueueEmpty(void* queue);
-
initQueue初始化队列:根据unitSize和maxUnitNum申请内存,并对内存进行初始化。
-
enQueue入队:从队尾增加元素
-
dequeue出队:从队头删除元素
-
getQueueSize获取队列大小:返回队列中的元素数
-
isQueueEmpty队列是否为空:true表示队列为空,false表示队列非空
API使用示例
我们以定时器Id的管理为例,了解一下无锁队列主要API的使用。
初始化:主线程调用
ErrCode ret = initQueue(&queue, sizeof(U32), MAX_TMCB_NUM);
if (ret != ERR_TIMER_SUCC)
{
ERR_LOG("lock free init_queue error: %u\n", ret);
return;
}
for (U32 timerId = 0; timerId < MAX_TMCB_NUM; timerId++)
{
ret = enQueue(queue, &timerId);
if (ret != ERR_TIMER_SUCC)
{
ERR_LOG("lock free enqueue error: %u\n", ret);
return;
}
}
timerId分配:多线程调用
U32 timerId;
ErrCode ret = deQueue(queue, &timerId);
if (ret != ERR_TIMER_SUCC)
{
ERR_LOG("deQueue failed!");
return INVALID_TIMER_ID;
}
timerId回收:多线程调用
ErrCode ret = enQueue(queue, &timerId);
if (ret != ERR_TIMER_SUCC)
{
ERR_LOG("enQueue failed!");
}
3.2核心实现
显然,队列操作的核心实现为入队和出队操作。
(1)入队
入队的关键点有下面几点:
-
通过写次数确保队列元素数小于最大元素数
-
获取next tail的位置
-
将新元素插入到队尾
-
尾指针偏移
-
读次数加1
①最大元素数校验
#include <atomic>
template<typename T>
class LockFreeQueue {
private:
struct Node {
T data;
Node* next;
Node(const T& value) : data(value), next(nullptr) {}
};
std::atomic<Node*> head;
std::atomic<Node*> tail;
std::atomic<int> count;
public:
LockFreeQueue() : head(nullptr), tail(nullptr), count(0) {}
void push(const T& value) {
Node* newNode = new Node(value);
newNode->next = nullptr;
Node* prevTail = tail.exchange(newNode, std::memory_order_acq_rel);
if (prevTail != nullptr)
prevTail->next = newNode;
count.fetch_add(1, std::memory_order_release);
}
bool pop(T& value) {
if (head == nullptr)
return false;
Node* oldHead = head.load(std::memory_order_acquire);
Node* newHead = oldHead->next;
if (newHead == nullptr)
return false;
value = newHead->data;
head.store(newHead, std::memory_order_release);
delete oldHead;
count.fetch_sub(1, std::memory_order_release);
return true;
}
int size() const {
return count.load(std::memory_order_relaxed);
}
};
在入队操作开始,就判断写次数是否超过队列元素的最大值,如果已超过,则反馈队列已满的错误码,否则通过CAS操作将写次数加1。如果CAS操作失败,说明有多个线程同时判断了写次数都小于队列最大元素数,那么只有一个线程CAS操作成功,其他线程则需要重新做循环操作。
②获取next tail的位置
do
{
do
{
nextTail = queueHead->nextTail;
} while (!__sync_bool_compare_and_swap(&queueHead->nextTail, nextTail, (nextTail + 1) % (queueHead->maxUnitNum + 1)));
unitHead = UNIT_HEAD(queue, nextTail);
} while (unitHead->hasUsed);
当前next tail的位置就是即将入队的元素的目标位置,并通过CAS操作更新队列头中nextTail的值。如果CAS操作失败,则说明其他线程也正在进行入队操作,并比本线程快,则需要进行重新尝试,从而更新next tail的值,确保该入队元素的位置正确。
然而事情并没有这么简单,由于多线程的抢占,导致队列并不是按下标大小依次链接起来的,所以要判断一下next tail的位置是否正被占用。如果next tail的位置正被占用,则需要重新竞争next tail,直到next tail的位置是空闲的。
③将新元素插入到队尾
初始化新元素:
unitHead->next = LIST_END;
memcpy(UNIT_DATA(queue, nextTail), unit, queueHead->unitSize);
插入到队尾:
do
{
listTail = queueHead->listTail;
oldListTail = listTail;
unitHead = UNIT_HEAD(queue, listTail);
if ((++tryTimes) >= 3)
{
while (unitHead->next != LIST_END)
{
listTail = unitHead->next;
unitHead = UNIT_HEAD(queue, listTail);
}
}
} while (!__sync_bool_compare_and_swap(&unitHead->next, LIST_END, nextTail));
通过CAS操作判断当前指针是否到达队尾,如果到达队尾,则将新元素连接到队尾元素之后(next),否则进行追赶。
在这里,我们做了优化,当CAS操作连续失败3次后,那么就直接通过next的递推找到队尾,这样比CAS操作的效率高很多。我们在测试多线程的队列操作时,出现过一个线程插入到tail为400多的时候,已有线程插入到tail为1000多的场景。
④尾指针偏移
do
{
__sync_val_compare_and_swap(&queueHead->listTail, oldListTail, nextTail);
oldListTail = queueHead->listTail;
unitHead = UNIT_HEAD(queue, oldListTail);
nextTail = unitHead->next;
} while (nextTail != LIST_END);
在多线程场景下,队尾指针是动态变化的,当前尾可能不是新尾了,所以通过CAS操作更新队尾。当CAS操作失败时,说明队尾已经被其他线程更新,此时不能将nextTail赋值给队尾。
⑤读次数加1
__sync_fetch_and_add(&queueHead->readCount, 1);
写次数加1是为了保证队列元素的数不能超过最大元素数,而读次数加1是为了确保不能从空队列出队。
(2)出队
出队的关键点有下面几点:
-
通过读次数确保不能从空队列出队
-
头指针偏移
-
dummy头指针
-
写次数减1
①空队列校验
do
{
readCount = queueHead->readCount;
if (readCount == 0) return ERR_QUEUE_HAS_EMPTY;
} while (!__sync_bool_compare_and_swap(&queueHead->readCount, readCount, readCount - 1));
读次数为0,说明队列为空,否则通过CAS操作将读次数减1。如果CAS操作失败,说明其他线程已更新读次数成功,必须重试,直到成功。
②头指针偏移
U32 readCount;
do
{
listHead = queueHead->listHead;
unitHead = UNIT_HEAD(queue, listHead);
} while (!__sync_bool_compare_and_swap(&queueHead->listHead, listHead, unitHead->next));
如果CAS操作失败,说明队头指针已经在其他线程的操作下进行了偏移,所以要重试,直到成功。
③dummy头指针
我们可以看出,头元素为head->next,这就是说队列的第一个元素都是基于head->next而不是head,这样设计是有原因的。
考虑一个边界条件:在队列只有一个元素条件下,如果head和tail指针指向同一个结点,这样入队操作和出队操作本身就需要互斥了。通过引入一个dummy头指针来解决这个问题,如下图所示:
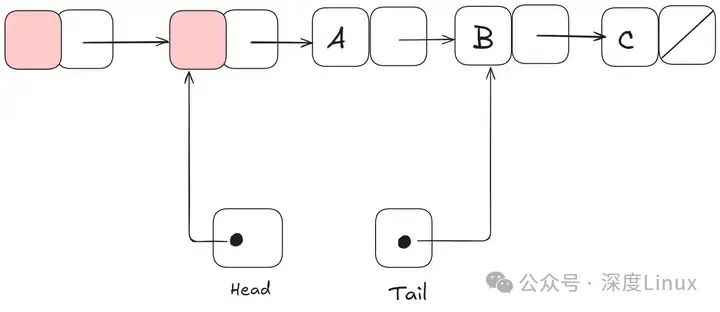
④写次数减1
__sync_fetch_and_sub(&queueHead->writeCount, 1);
出队操作结束前,要将写次数减1,以便入队操作能成功。
四、无锁编程技术
事实证明,当你试图满足无锁编程的无阻塞条件时,会出现一系列技术:原子操作、内存屏障、避免ABA问题,等等。从这里开始,事情很快变得棘手了。
4.1原子的 Read-Modify-Write 操作
所谓原子操作是指,通过一种看起来不可分割的方式来操作内存:线程无法看到原子操作的中间过程。在现代的处理器上,有很多操作本身就是的原子的。例如,对简单类型的对齐的读和写通常就是原子的。
Read-Modify-Write(RMW)操作更进一步,它允许你按照原子的方式,操作更复杂的事务。当一个无锁的算法必须支持多个写入者时,原子操作会尤其有用,因为多个线程试图在同一个地址上进行RMW时,它们会按“一次一个”的方式排队执行这些操作。我已经在我的博客中涉及了RMW操作了,如实现 轻量级互斥量、递归互斥量 和 轻量级日志系统。
RMW 操作的例子包括:Win32上 的 _InterlockedIncrement,iOS 上的 OSAtomicAdd32 以及 C++11 中的 std::atomic<int>::fetch_add。需要注意的是,C++11 的原子标准不保证其在每个平台上的实现都是无锁的,因此最好要清楚你的平台和工具链的能力。你可以调用 std::atomic<>::is_lock_free 来确认一下。
不同的 CPU 系列支持 RMW 的方式也是不同的。例如,PowerPC 和 ARM 提供 load-link/store-conditional 指令,这实际上是允许你实现你自定义的底层 RMW 操作。常用的 RMW 操作就已经足够了。
如上面流程图所述,即使在单处理器系统上,原子的 RMW 操作也是无锁编程的必要部分。没有原子性的话,一个线程的事务会被中途打断,这可能会导致一个错误的状态。
4.2Compare-And-Swap 循环
或许,最常讨论的 RMW 操作是 compare-and-swap (CAS)。在Win32上,CAS 是通过如 _InterlockedCompareExchange 等一系列指令来提供的。通常,程序员会在一个事务中使用 CAS 循环。这个模式通常包括:复制一个共享的变量至本地变量,做一些特定的工作(改动),再试图使用 CAS 发布这些改动。
void LockFreeQueue::push(Node* newHead)
{
for (;;)
{
// Copy a shared variable (m_Head) to a local.
Node* oldHead = m_Head;
// Do some speculative work, not yet visible to other threads.
newHead->next = oldHead;
// Next, attempt to publish our changes to the shared variable.
// If the shared variable hasn't changed, the CAS succeeds and we return.
// Otherwise, repeat.
if (_InterlockedCompareExchange(&m_Head, newHead, oldHead) == oldHead)
return;
}
}
这样的循环仍然有资格作为无锁的,因为如果一个线程检测失败,意味着有其它线程成功—尽管某些架构提供一个 较弱的CAS变种 。无论何时实现一个CAS循环,都必须十分小心地避免 ABA 问题。
4.3顺序一致性
顺序一致性(Sequential consistency)意味着,所有线程就内存操作的顺序达成一致。这个顺序是和操作在程序源代码中的顺序是一致的。
一种实现顺序一致性的简单(但显然不切实际)的方法是禁用编译器优化,并强制所有线程在单个处理器上运行。即使线程在任意时间被抢占和调度,处理器也永远不会看到自己的内存影响。
某些编程语言甚至可以为在多处理器环境中运行的优化代码提供顺序一致性。在C ++ 11中,可以将所有共享变量声明为具有默认内存排序约束的C ++ 11原子类型。
std::atomic X(0), Y(0);
int r1, r2;
void thread1()
{
X.store(1);
r1 = Y.load();
}
void thread2()
{
Y.store(1);
r2 = X.load();
}
因为 C ++ 11 原子类型保证顺序一致性,所以结果 r1 = r2 = 0 是不可能的。为此,编译器会在后台输出其他指令——通常是 内存围栏 和/或 RMW 操作。与程序员直接处理内存排序的指令相比,那些额外的指令可能会使实现效率降低。
4.4内存保序
正如前面流程图所建议的那样,任何时候做多核(或者任何对称多处理器)的无锁编程,如果你的环境不能保证顺序一致性,你都必须考虑如何来防止 内存重新排序。
在当今的架构中,增强内存保序性的工具通常分为三类,它们既防止 编译器重新排序 又防止 处理器重新排序:
-
一个轻型的同步或屏障指令
-
一个完全的内存屏障指令
-
提供获取或释放语义的内存操作
获取语义可防止按照程序顺序对其进行操作的内存重新排序,而释放语义则可防止对其进行操作前的内存重新排序。这些语义尤其适用于存在生产者/消费者关系的情况,其中一个线程发布一些信息,而另一个线程读取它。
不同的处理器有不同的内存模型
在内存重新排序方面,不同的CPU系列具有不同的习惯。每个CPU供应商都记录了这些规则,并严格遵循了硬件。例如,PowerPC 和 ARM 处理器可以相对于指令本身更改内存存储的顺序,但是通常,英特尔和 AMD 的 x86 / 64 系列处理器不会。
有人倾向于将这些特定于平台的细节抽象出来,尤其是C ++ 11为我们提供了编写可移植的无锁代码的标准方法。但是目前,我认为大多数无锁程序员至少对平台差异有所了解。如果需要记住一个关键的区别,那就是在x86 / 64指令级别上,每次从内存中加载都会获取语义,并且每次存储到内存都将提供释放语义–至少对于非SSE指令和非写组合内存 。因此,过去通常会编写可在x86 / 64上运行但 在其他处理器上无法运行 的无锁代码。
如果你对硬件如何处理内存重新排序的细节感兴趣,我建议看看《Is Pararllel Programming Hard》的附录C。无论如何,请记住,由于编译器对指令的重新排序,也会发生内存重新排序。
五、无锁编程的优势与应用场景
5.1性能飞跃:高并发下的卓越表现
在高并发场景中,无锁编程的性能优势格外显著。以一个简单的计数器为例,在传统锁编程中,每次对计数器的更新都需要获取锁,这会导致大量线程等待,造成上下文切换频繁 。假设一个应用中有 100 个线程同时对计数器进行 10000 次加 1 操作,使用传统的synchronized关键字实现的锁编程,在高并发情况下,线程的阻塞和上下文切换会使得执行时间明显增加 。而采用无锁编程,利用AtomicInteger类提供的原子操作,线程无需等待锁的释放,能够无阻塞地执行加 1 操作 。
通过实际测试,在同样的硬件环境和线程数量下,无锁编程实现的计数器操作,其执行时间相较于传统锁编程大幅缩短,系统吞吐量显著提升 。这是因为无锁编程减少了锁竞争带来的开销,让 CPU 能够更专注于实际的业务计算,大大提高了 CPU 的利用率 。在一些对吞吐量要求极高的互联网应用中,如电商平台的订单计数、社交平台的点赞计数等,无锁编程能够轻松应对高并发的读写操作,保证系统的高效运行 。
5.2避免死锁:稳定性的保障
死锁是传统锁编程中一个令人头疼的问题,它会导致程序陷入无限期的等待,无法继续执行 。在一个多线程的文件读写系统中,线程 A 持有文件读取锁,试图获取文件写入锁;而线程 B 持有文件写入锁,试图获取文件读取锁,双方都不释放自己持有的锁,就会陷入死锁状态 。而无锁编程从根本上避免了死锁的产生,因为它不依赖锁机制来实现线程同步 。
无锁编程使用原子操作和 CAS 算法,线程在访问共享资源时,无需等待锁的获取,而是通过不断尝试原子操作来更新资源 。这种方式使得线程之间不会因为等待锁而相互阻塞,从而杜绝了死锁的发生 。在复杂的分布式系统中,无锁编程的这一优势尤为重要,它能够确保系统在高并发和复杂业务逻辑下的稳定性,减少因死锁导致的系统故障和数据不一致问题 。
5.3应用领域大扫描
无锁编程在众多领域都有着广泛的应用,其独特的优势使其成为解决高并发和性能问题的有力工具 。
在高性能计算领域,无锁编程能够充分发挥多核处理器的并行计算能力,提高计算效率 。在科学计算中,如气象模拟、分子动力学模拟等,需要处理大量的数据和复杂的计算任务,无锁编程可以减少线程之间的同步开销,让各个核心能够高效地协同工作,加速计算过程 。
数据库系统也常常运用无锁编程来提升并发性能 。在多线程并发访问数据库时,传统的锁机制会导致大量线程阻塞,降低数据库的读写性能 。而无锁编程通过原子操作和无锁数据结构,实现了对数据库资源的高效访问,提高了数据库的并发处理能力,能够更好地满足高并发业务的需求 。
缓存系统同样依赖无锁编程来实现快速的数据读写 。以Redis为例,它在处理大量并发请求时,采用了无锁的数据结构和原子操作,确保了数据的一致性和高效读写,使得缓存系统能够快速响应请求,减轻后端数据库的压力 。
在消息传递和事件驱动系统中,无锁编程能够避免线程阻塞,提高系统的响应速度和可伸缩性 。在分布式消息队列中,多个生产者和消费者并发地进行消息的发送和接收,无锁编程保证了消息的高效传递和处理,使得系统能够快速响应各种事件,满足实时性要求较高的应用场景 。
六、无锁编程实践困境
6.1编程复杂度提升
无锁编程虽然带来了性能上的优势,但也极大地提升了编程的复杂度,对开发者提出了更高的要求 。在无锁编程中,开发者需要深入理解底层硬件和操作系统的并发机制,这是因为无锁编程依赖于原子操作、内存屏障等底层技术来实现线程安全,而这些技术与硬件的特性密切相关 。不同的处理器架构可能对原子操作的支持和实现方式有所不同,开发者需要清楚地了解这些差异,才能正确地编写无锁代码 。
无锁编程的代码逻辑往往更加复杂。以实现一个无锁队列为例,在传统的锁编程中,使用锁来保证队列操作的线程安全,代码逻辑相对简单,只需要在关键操作前后加锁和解锁即可 。但在无锁编程中,需要使用 CAS 算法等技术来实现无锁的入队和出队操作,这涉及到复杂的指针操作和状态判断 。每次入队操作都需要通过 CAS 算法尝试将新节点插入到队列尾部,如果插入失败,还需要根据失败的原因进行相应的处理,可能需要重新获取队列的状态并再次尝试插入 。这种复杂的逻辑使得代码的编写和维护难度大幅增加,容易出现逻辑错误,对开发者的编程能力和经验是一个巨大的挑战 。
6.2ABA 问题及解决方案
ABA 问题是无锁编程中一个较为棘手的问题,它可能导致程序出现意想不到的错误 。假设一个共享变量的初始值为 A,线程 1 读取到这个值 A 后,由于某些原因被阻塞 。在这期间,线程 2 将变量的值从 A 改为 B,然后又改回 A 。当线程 1 恢复执行时,它通过 CAS 操作检查变量的值,发现仍然是 A,就会认为变量没有被修改过,从而继续执行后续的操作 。但实际上,变量已经经历了两次变化,这可能会导致程序的逻辑出现错误 。
在一个无锁的链表结构中,当进行节点删除操作时就可能出现 ABA 问题 。假设链表的初始状态是 A -> B -> C,线程 1 想要删除节点 A,它读取到节点 A 的指针,准备进行删除操作 。但此时线程 2 介入,先删除了节点 A,然后又重新插入了一个值为 A 的新节点,链表变为 A -> B -> C(这里的新 A 节点和原来的 A 节点不是同一个对象) 。线程 1 继续执行删除操作时,由于 CAS 操作检查到节点 A 的指针没有变化,就会误以为删除操作可以正常进行,但实际上它删除的是新插入的节点 A,这就破坏了链表的结构,导致数据不一致 。
为了解决 ABA 问题,通常采用带有版本号的 CAS 操作 。以 Java 中的AtomicStampedReference类为例,它在进行 CAS 操作时,不仅会比较引用值,还会比较一个时间戳(版本号) 。每次变量发生变化时,时间戳也会相应地增加 。在上述链表删除节点的例子中,使用AtomicStampedReference来管理链表节点的引用,当线程 1 读取节点 A 的引用和时间戳后,线程 2 进行删除和重新插入操作时,时间戳会增加 。线程 1 执行删除操作时,通过 CAS 操作比较引用和时间戳,发现时间戳已经改变,就知道变量已经被修改过,从而避免了错误的删除操作 。除了版本号,还可以使用原子标记引用(如AtomicMarkableReference),它通过一个标记位来记录变量是否被修改过,也能有效地解决 ABA 问题 。
ABA问题可以俗称为“调包问题”,我们先看一个生活化的例子:
你拿着一个装满钱的手提箱在飞机场,此时过来了一个火辣性感的美女,然后她很暖昧地挑逗着你,并趁你不注意的时候,把用一个一模一样的手提箱和你那装满钱的箱子调了个包,然后就离开了,你看到你的手提箱还在那,于是就提着手提箱去赶飞机了。
我们再看一个CAS化的例子:
若线程对同一内存地址进行了两次读操作,而两次读操作得到了相同的值,通过 "值相同" 来判定 "值没变"是不可靠的。因为在这两次读操作的时间间隔之内,另外的线程可能已经多次修改了该值,这样就相当于欺骗了前面的线程,使其认为 "值没变",实际上值已经被篡改过了。
下面是 ABA 问题发生的过程:
-
T1 线程从共享的内存地址读取值 A;
-
T1 线程被抢占,线程 T2 开始运行;
-
T2 线程将共享的内存地址中的值由 A 改成 B,然后又改成 A;
-
T1 线程继续执行,读取共享的内存地址中的值 A,认为没有改变,然后继续执行
由于 T1 并不知道两次读取的值 A 已经被 "隐性" 的修改过,所以可能产生无法预期的结果;当 CAS操作循环执行时,存在多个线程交错地对共享的内存地址进行处理,如果实现的不正确,将有可能遇到 ABA 问题。
6.3调试困难与策略
无锁编程的调试难度远远大于传统的锁编程,这是无锁编程在实践中面临的又一挑战 。由于无锁编程依赖于多线程并发执行,线程之间的执行顺序和时间片分配是不确定的,这使得问题难以复现 。一个在测试环境中偶尔出现的问题,可能在再次运行时就不会出现,这给定位和解决问题带来了极大的困难 。
无锁编程中线程执行顺序的不确定性也增加了跟踪和调试的难度 。在传统的锁编程中,由于锁的存在,线程的执行顺序相对容易跟踪,开发者可以通过在关键代码处添加日志,清晰地了解线程的执行流程 。但在无锁编程中,多个线程可能同时对共享资源进行操作,线程之间的执行顺序交错复杂,很难通过简单的日志来跟踪每个线程的具体操作和执行顺序 。
为了应对这些调试困难,可以借助一些专业的调试工具 。在 Java 开发中,Java Mission Control就是一个强大的调试工具,它可以监控和分析 Java 应用程序的性能和运行状态,帮助开发者查看线程的执行情况、内存使用情况等 。通过该工具,能够直观地看到各个线程在不同时间点的状态和执行的代码片段,有助于定位无锁编程中线程竞争和数据不一致等问题 。详细的日志分析也是一种有效的策略 。在无锁代码中,合理地添加日志,记录关键操作的执行时间、操作前后的变量值以及线程的 ID 等信息,通过对这些日志的分析,可以更深入地了解程序的执行过程,从而发现潜在的问题 。

















 1098
1098

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









