 人工智能领域工具、资源及研究成果汇总
人工智能领域工具、资源及研究成果汇总






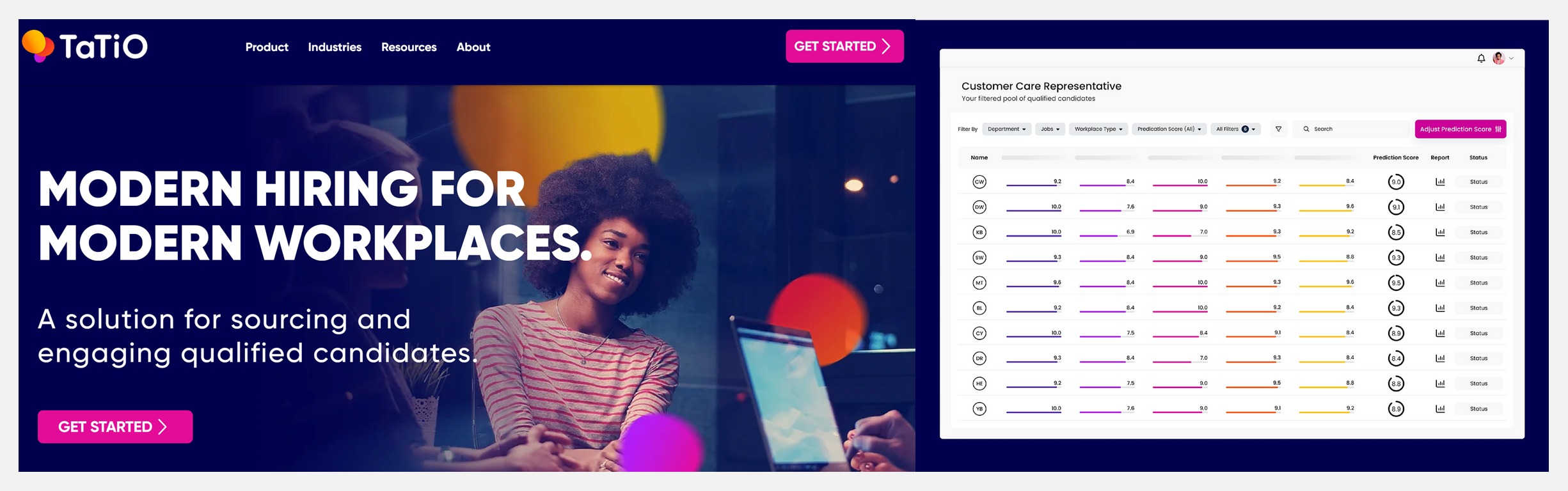
📢 TaTiO:人工智能招聘平台,获530万美元融资
https://www.calcalistech.com/ctechnews/article/bjhqxus7j
TaTiO 是一家人工智能招聘平台,利用其AI模型寻找和审核求职者,并向雇主提供预审合格的候选人进行面试,帮助公司选用合格的工人填补空缺职位,可以减少50%的雇佣时间和30%的雇佣成本。近日,TaTiO 宣布获得了530万美元的天使轮融资。
TaTiO 寻找潜在的候选人并模拟工作任务,使用AI跟踪并分析每位候选人的行为,生成一份包含岗位预测分数的报告,并在第一次面试之前提交给雇主作为评估参考。此外 TaTiO 还会不断了解雇主的偏好,提高他们的求职者与雇佣者的比例。
工具&框架
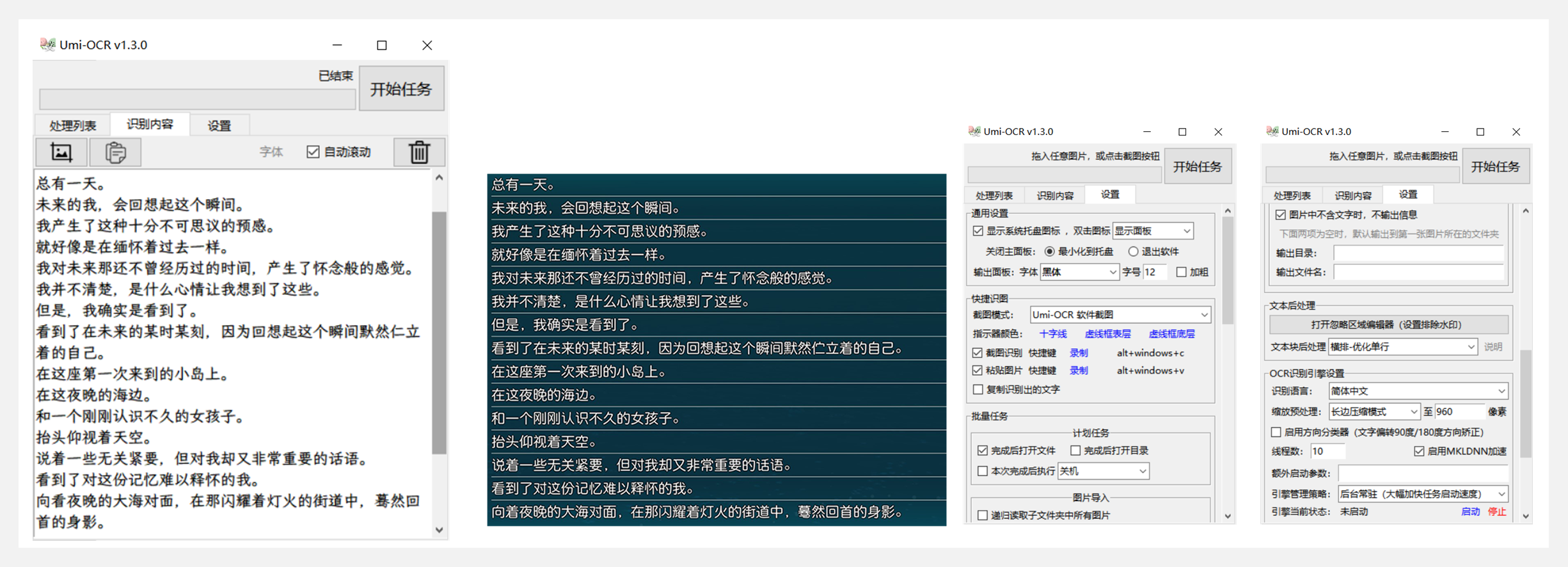
🚧 『Umi-OCR』批量图片转文字工具
https://github.com/hiroi-sora/Umi-OCR
OCR批量图片转文字识别软件,带界面,离线运行。可排除图片中水印区域的干扰,提取干净的文本。基于PaddleOCR实现。
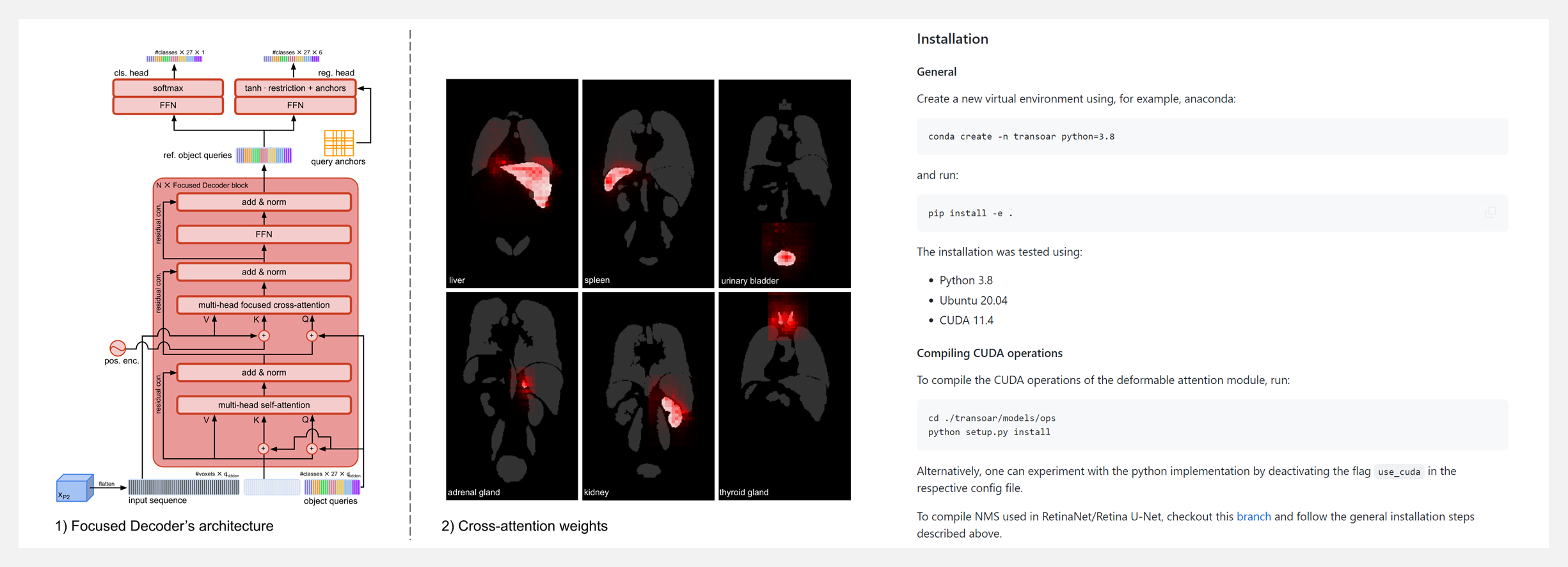
🚧 『TransOAR』3D医学影像检测Transformer库
https://github.com/bwittmann/transoar
TransOAR 项目最初是为基于 Transformer 的医学影像问题器官检测而开发的,包含了三种三维检测 Transformer 的代码,即 Focused Decoder,DETR 和 Deformable DETR。
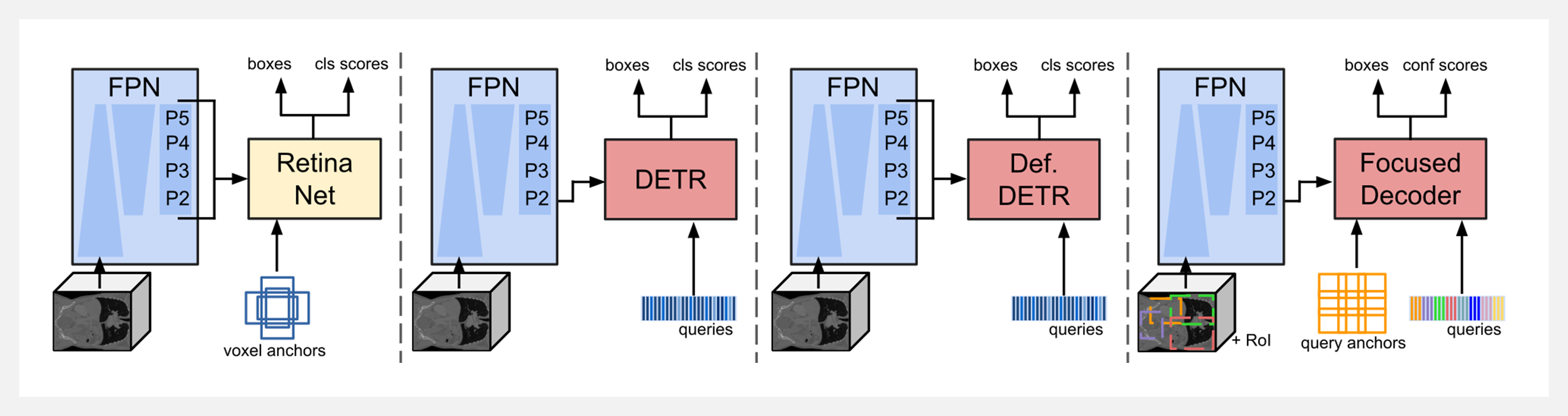
此外,工具在训练管道中采用了来自nnDetection的RetinaNet/Retina U-Net,以确保与传统的基于CNN的检测器的结果的可比性。
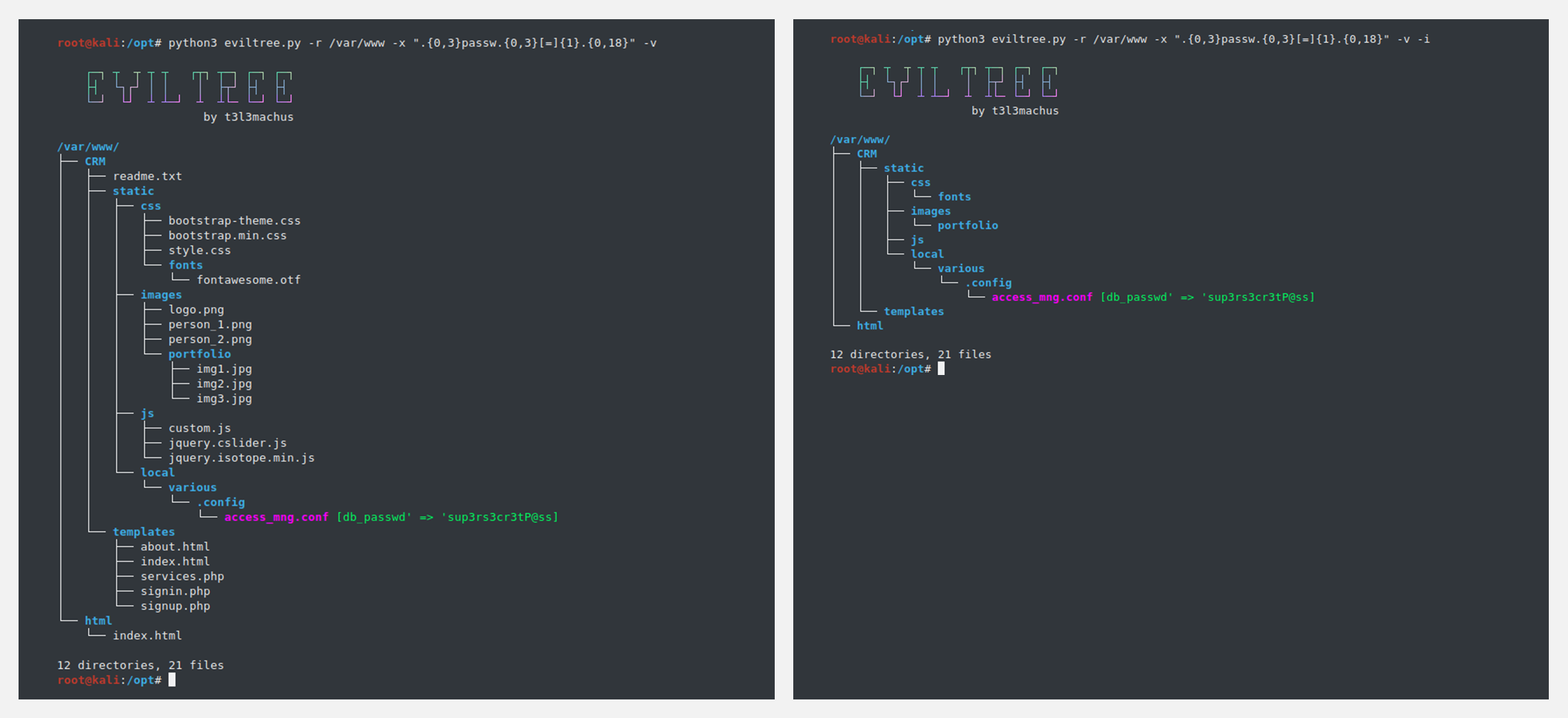
🚧 『EvilTree』经典tree命令的Python重制版
https://github.com/t3l3machus/eviltree
EvilTree 是一个独立的 Python3 的经典命令『tree』的翻版,具有在文件中搜索用户提供的关键字/regex的额外功能,突出显示那些包含匹配的文件,以及这些文件在文件夹的层次结构中的位置。
🚧 『Stanford Nimble』深度学习物理引擎
https://github.com/keenon/nimblephysics
Nimble是斯坦福大学开发的工具库,是目前流行的物理引擎DART的一个可解析微分版本。借助于Nimble,你可以在PyTorch神经网络中,使用很多功能,包括动力学的快速雅各布运算,以及使用物理时间步长作为非线性计量。

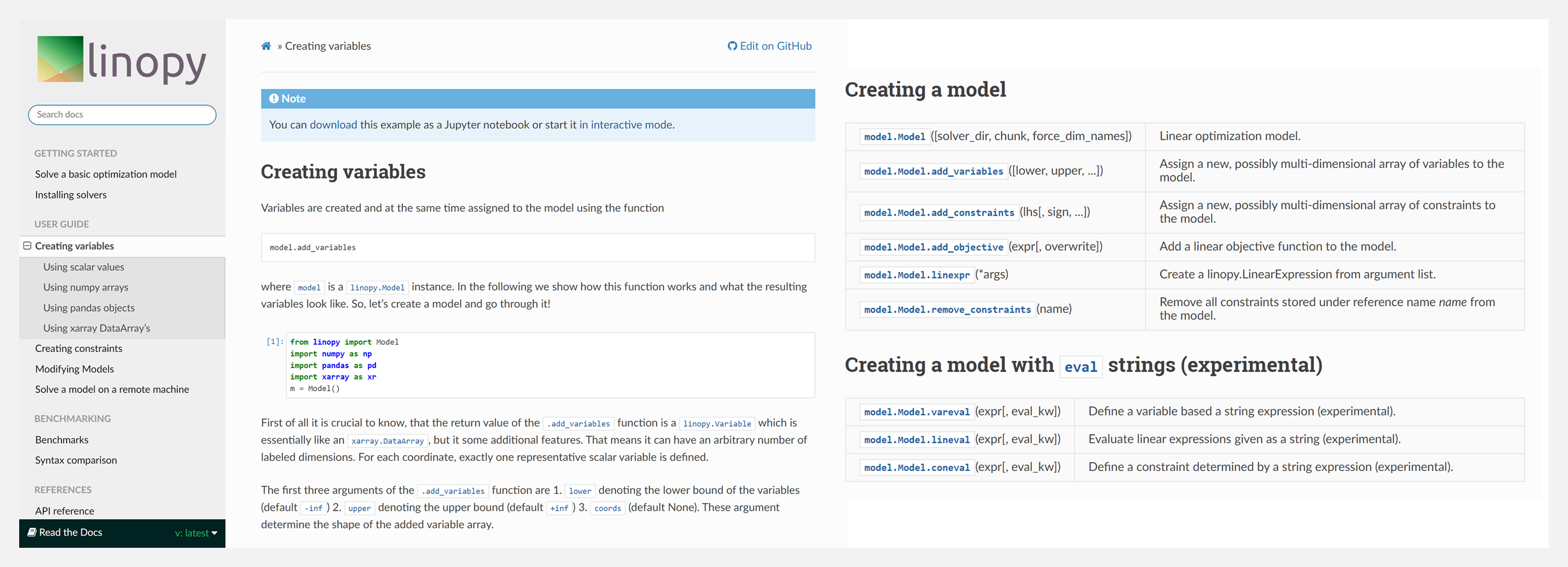
🚧 『linopy』使用现实世界的数据进行线性或混合整数优化
https://github.com/PyPSA/linopy
https://linopy.readthedocs.io/en/latest/
linopy 是一个开源的 Python 包,它实现了现实世界数据的线性或混合整数优化。它构建了 xarray 和 pandas 等数据分析工具库之间的桥梁。该项目旨在使python中的线性编程变得简单、高度灵活和高性能。
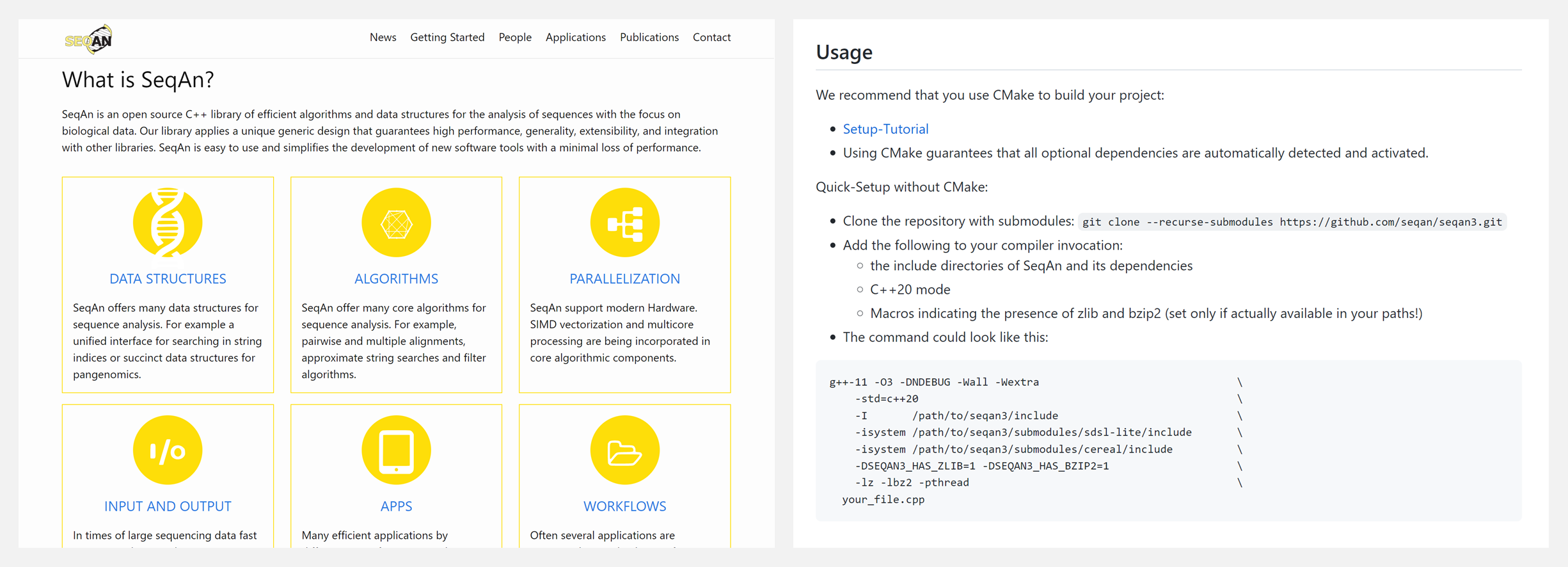
🚧 『SeqAn3』现代C++生物序列分析模板库
https://github.com/seqan/seqan3
SeqAn3 用于分析生物序列的流行的 SeqAn 模板库的新版本。它通过提供通用的算法和数据结构来实现高性能解决方案的快速开发。SeqAn3 具备序列表示和转换、全文索引和高效搜索、序列比对、常用文件格式的输入/输出等特点。
博文&分享
👍 『Google数据科学课程』
🧭 Learn Python basics for data analysis / Python数据分析基础
https://learndigital.withgoogle.com/digitalunlocked/course/learn-python-basics-for-data-analysis
本课程旨在讲解 Python 编程语言的基础知识,尤其是如何用于数据分析。包含以下内容:
- Set up Your Python Work Environment(设置Python工作环境)
- Handle Fundamental Functions and Objects(基本函数和对象操作)
- Organize Objects and Manage Program Flow Within a Project(在项目中组织对象并管理程序流)
- Use Specialized Python Libraries(使用特殊Python库)

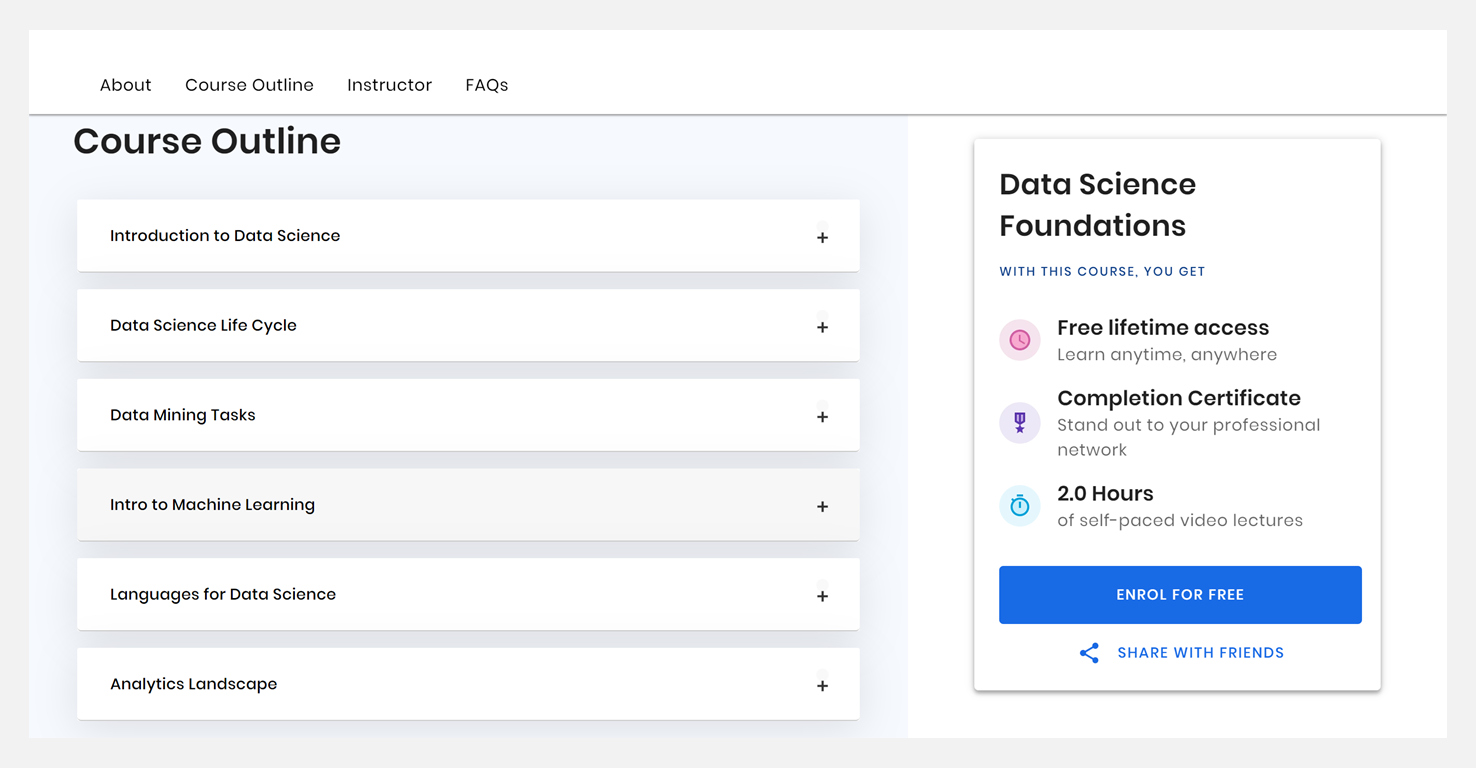
🧭 Data Science Foundations / 数据科学基础
https://learndigital.withgoogle.com/digitalunlocked/course/data-science-foundations
数据科学可以从结构化数据&非结构化数据中提取有效信息。由于数据的增长和技术的发展,数据科学领域出现了巨大的增长。本课程将全面介绍数据科学和数据分析的相关基础知识。
- Introduction to Data Science(数据科学导论)
- Data Science Life Cycle(数据科学生命周期)
- Data Mining Tasks(数据挖掘任务)
- Intro to Machine Learning(机器学习简介)
- Languages for Data Science(数据科学语言)
- Analytics Landscape(分析环境)
🧭 Data Science with Python / Python数据科学实战
https://learndigital.withgoogle.com/digitalunlocked/course/data-science-with-python
这个 Python 数据科学计划让学习者全面了解数据分析工具和技术,帮助学习者获得有关数据分析、可视化、NumPy、SciPy、网络抓取和自然语言处理的知识。如果你希望成为数据科学家,那从这里开始刚刚好:
- Course Introduction(课程介绍)
- Introduction to Data Science(数据科学概论)
- Python Libraries for Data Science(用于数据科学的Python库)
- Data Wrangling(数据整理)
- Feature Engineering(特征工程)
- Exploratory Data Analysis(探索性数据分析)
- Feature Selection(特征选择)
- Practice Project(实践项目)
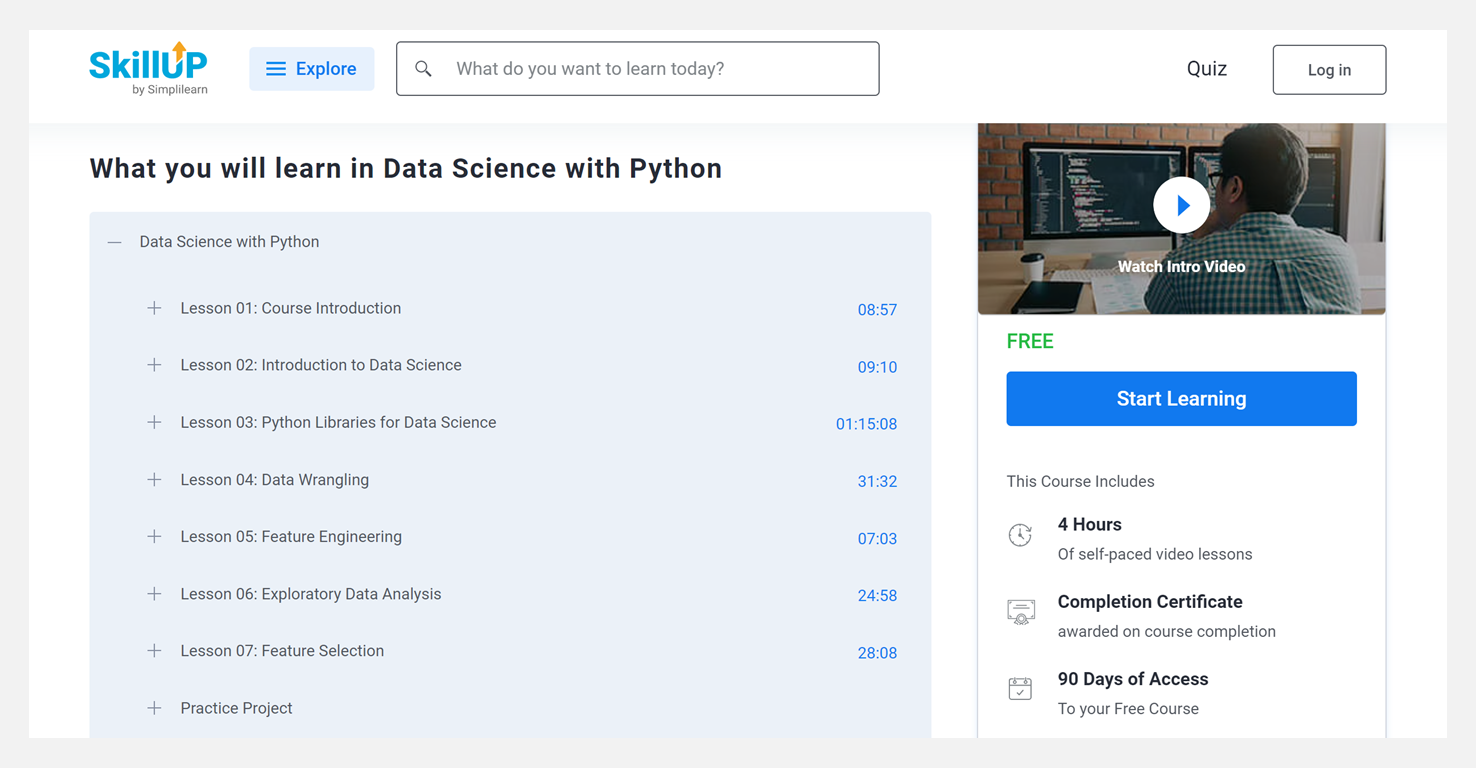
🧭 Machine Learning Crash Course / 机器学习快速入门
https://learndigital.withgoogle.com/digitalunlocked/course/machine-learning-crash-course
课程教授机器学习的基础知识,以及Google 研究人员的视频讲座、专为 ML 新手编写的文本、算法的交互式可视化和真实案例研究。课程设计通过大量编码练习将内容付诸实践。
- ML Concepts(机器学习概念)
- ML Engineering(机器学习工程)
- ML Systems in the Real World(现实世界中的机器学习系统)
数据&资源
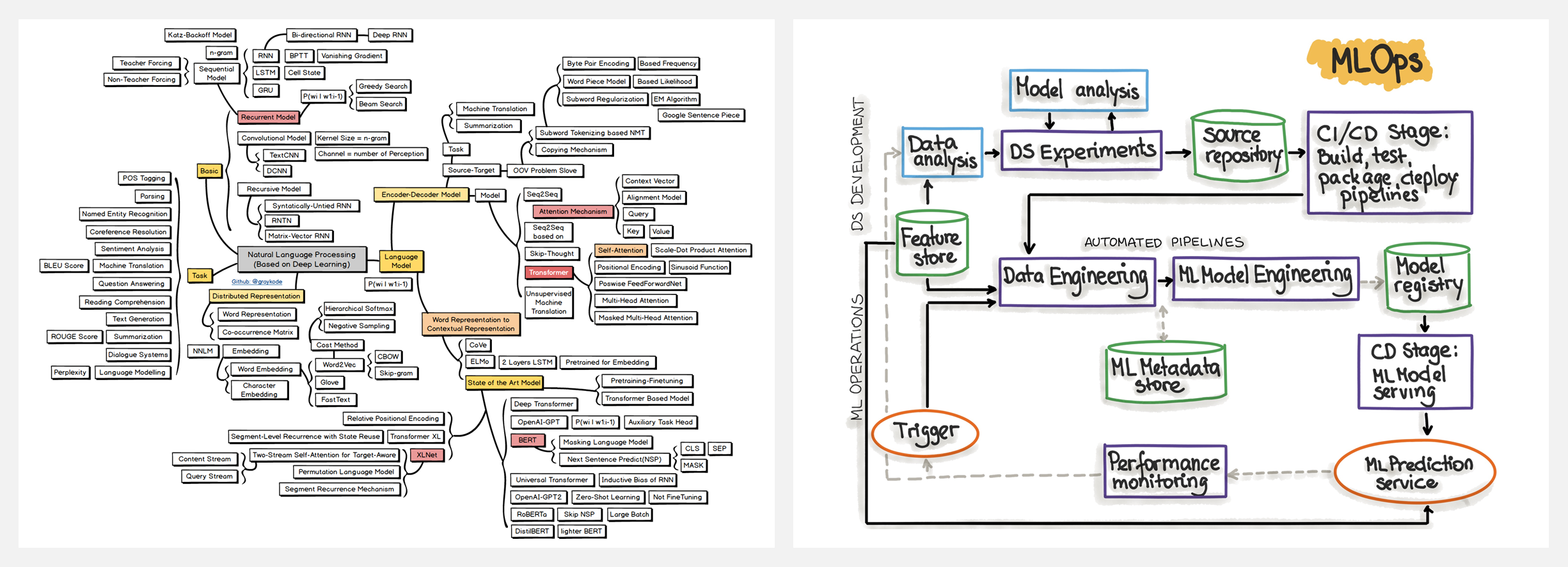
🔥 『ResourceBank CV NLP MLOPS 2022』计算机视觉,自然语言处理和机器学习运维学习资源库
https://github.com/ashishpatel26/ResourceBank_CV_NLP_MLOPS_2022
该计划每天汇总教育资源,使用户可以在一个地方获得他们想要的所有数据。以下选取了『自然语言处理学习路径』『机器学习应用学习路径』以及部分主题资源的截图,详细信息可以查看上方链接。
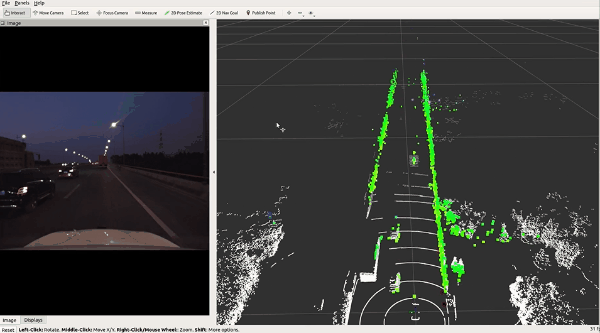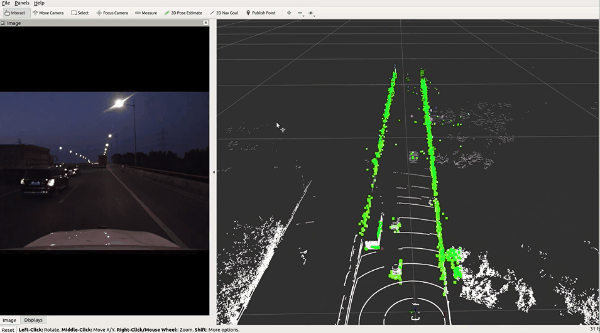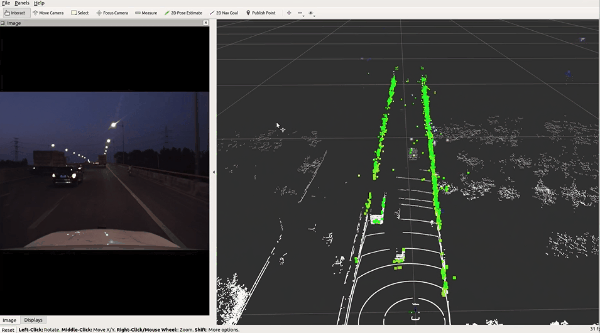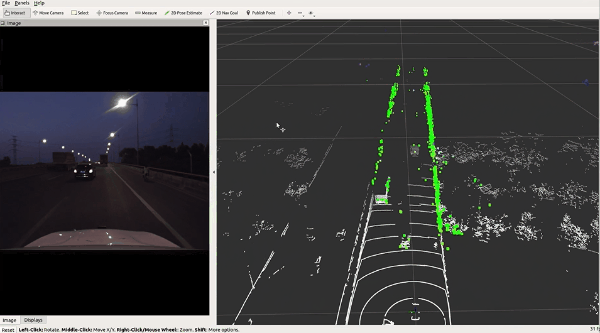
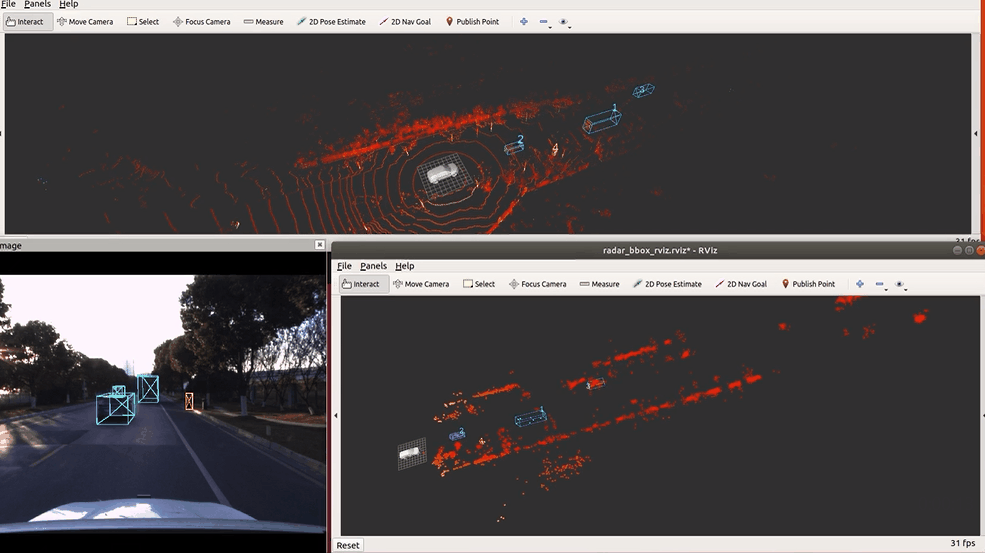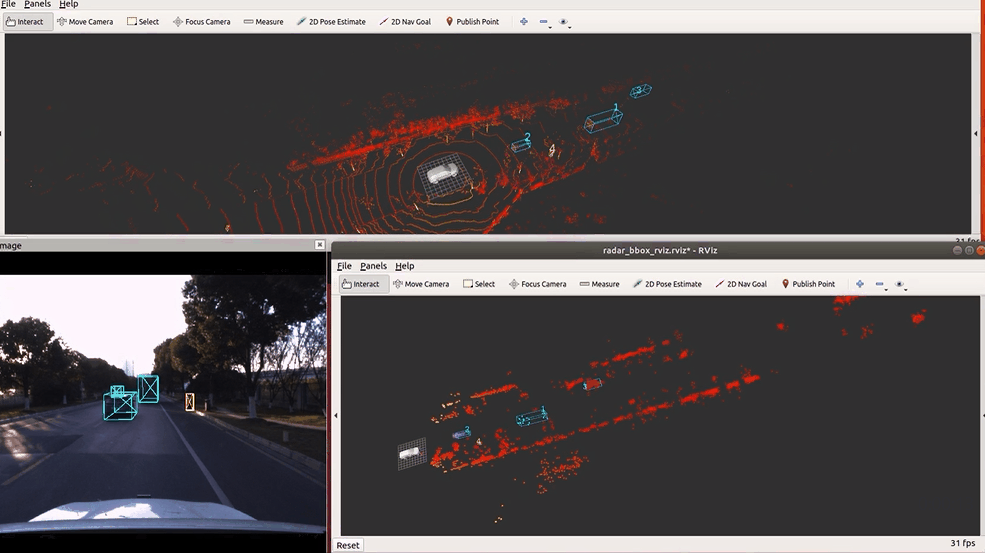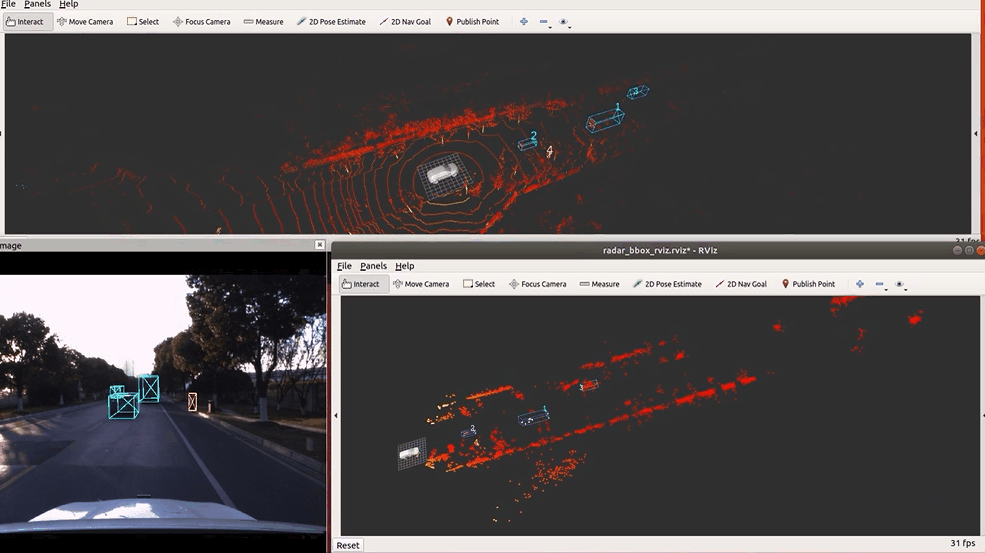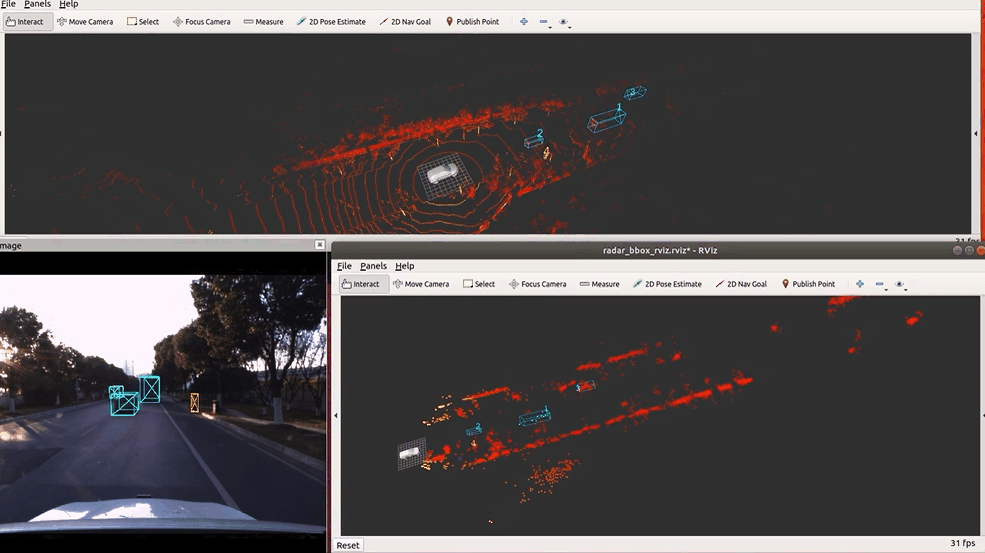
🔥 『TJ4DRadSet』 面向无人驾驶的4D雷达数据集
https://github.com/TJRadarLab/TJ4DRadSet
Repo 提供了 TJ4DRadSet 的描述和获取。论文已被 IEEE ITSC 2022 接受!数据集会后陆续发布。
研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。
科研进展
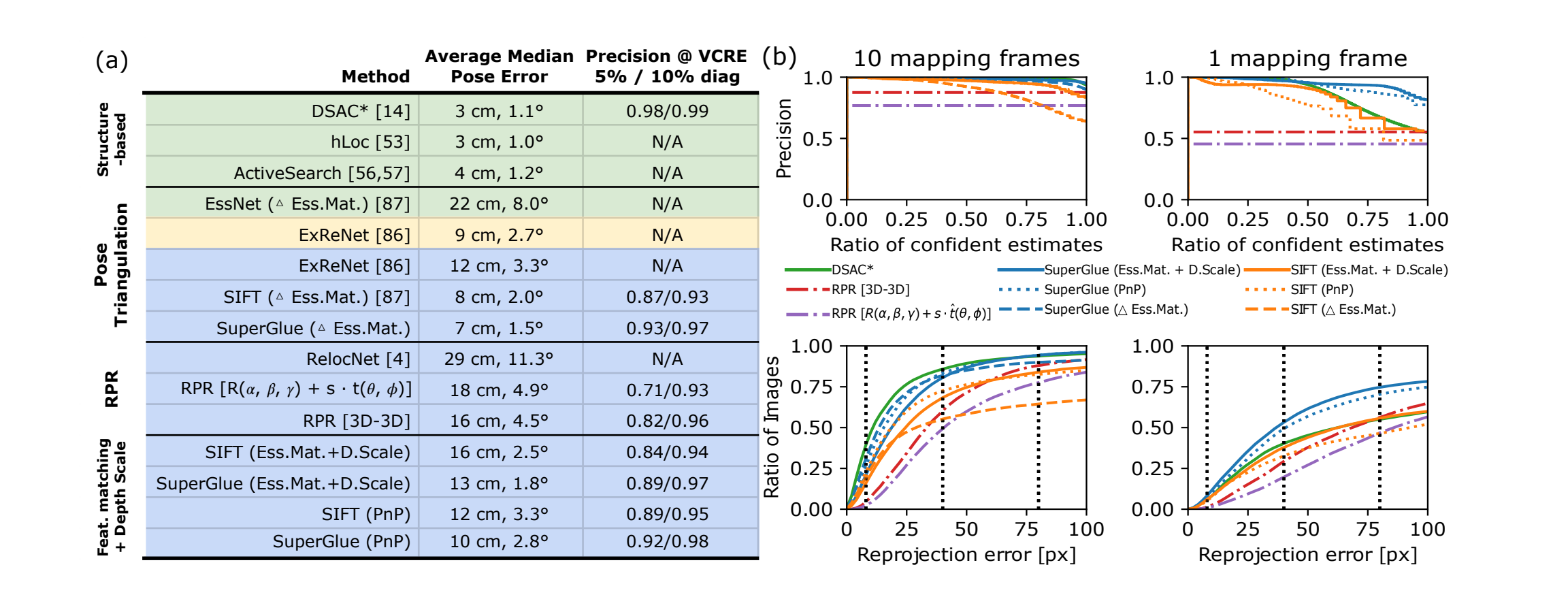
- 2022.10.11 『深度估计』 Map-free Visual Relocalization: Metric Pose Relative to a Single Image
- 2022.02.14 『语义对应』CATs++: Boosting Cost Aggregation with Convolutions and Transformers
- 2022.08.31 『运动合成』 MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model
⚡ 论文:Map-free Visual Relocalization: Metric Pose Relative to a Single Image
论文时间:11 Oct 2022
领域任务:Depth Estimation, Depth Prediction, 深度估计,深度预测
论文地址:https://arxiv.org/abs/2210.05494
代码实现:https://github.com/nianticlabs/map-free-reloc
论文作者:Eduardo Arnold, Jamie Wynn, Sara Vicente, Guillermo Garcia-Hernando, Áron Monszpart, Victor Adrian Prisacariu, Daniyar Turmukhambetov, Eric Brachmann
论文简介:Can we relocalize in a scene represented by a single reference image?/我们能在一个由单一参考图像代表的场景中重新定位吗?
论文摘要:我们能在一个由单一参考图像代表的场景中重新定位吗?标准的视觉重定位需要数以百计的图像和比例校准来建立一个特定于场景的三维地图。相比之下,我们提出了无地图重定位,即只使用场景的一张照片来实现即时的、尺度化的重定位。现有的数据集不适合作为无地图重定位的基准,因为它们侧重于大场景或其有限的可变性。因此,我们构建了一个新的数据集,其中有655个小景点,如雕塑、壁画和喷泉,在全球范围内收集。每个地方都有一张作为重新定位锚的参考图像,以及几十张已知的、有度量的相机姿势的查询图像。该数据集的特点是不断变化的条件、鲜明的视角变化、不同地方的高差异性,以及与参考图像的视觉重合度较低或没有重合度的查询。我们确定了两个可行的现有方法系列,以提供基线结果:相对姿势回归,以及结合单幅图像深度预测的特征匹配。虽然这些方法在我们的数据集中的一些有利场景中表现出合理的性能,但无地图的重新定位被证明是一个挑战,需要新的、创新的解决方案。
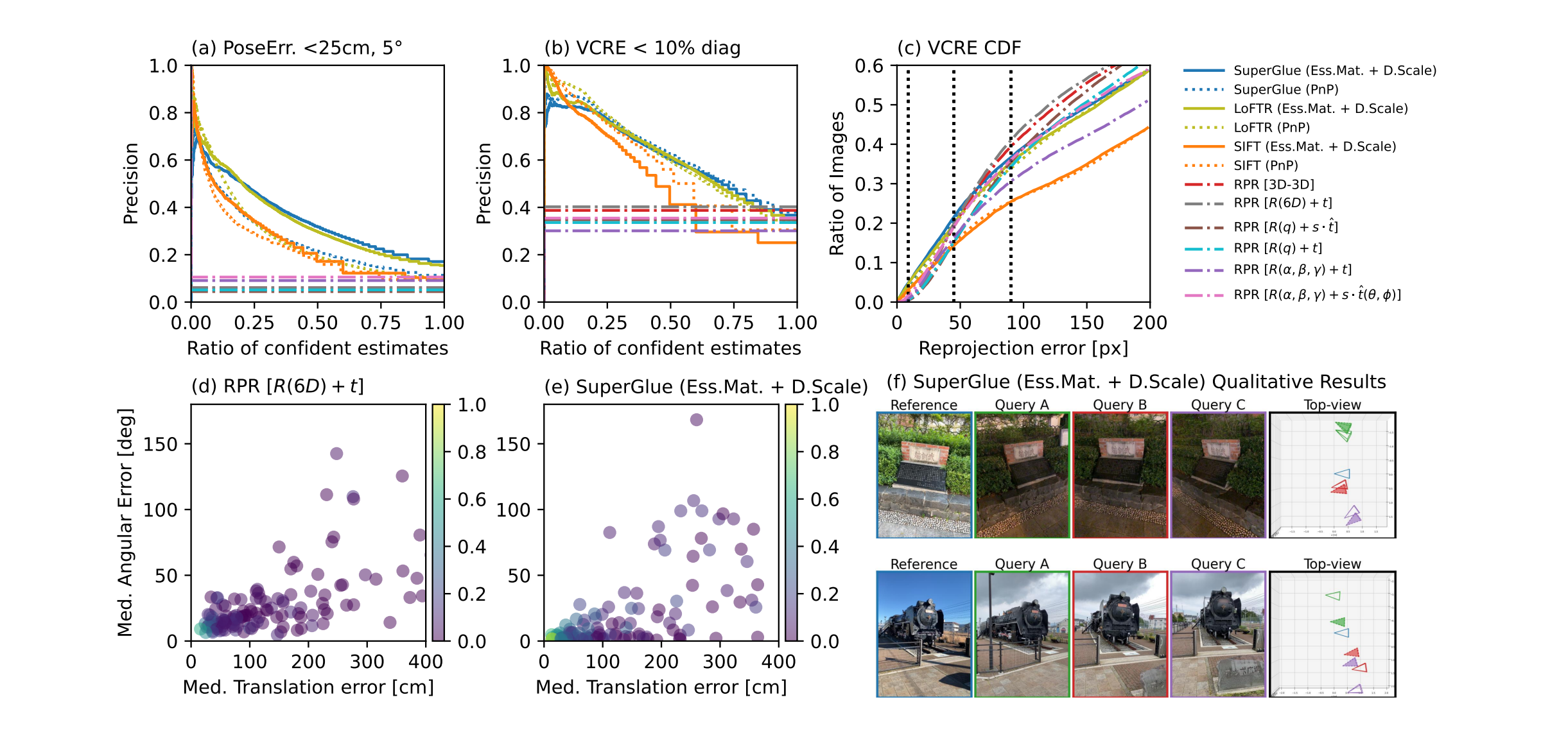
⚡ 论文:CATs++: Boosting Cost Aggregation with Convolutions and Transformers
论文时间:14 Feb 2022
领域任务:Semantic correspondence,语义对应
论文地址:https://arxiv.org/abs/2202.06817
代码实现:https://github.com/KU-CVLAB/CATs-PlusPlus
论文作者:Seokju Cho, Sunghwan Hong, Seungryong Kim
论文简介:Cost aggregation is a highly important process in image matching tasks, which aims to disambiguate the noisy matching scores./成本汇总是图像匹配任务中的一个非常重要的过程,其目的是消除嘈杂的匹配分数。
论文摘要:成本聚合是图像匹配任务中的一个非常重要的过程,其目的是消除嘈杂的匹配分数。现有的方法通常通过手工制作或基于CNN的方法来解决这个问题,这些方法要么对严重的变形缺乏鲁棒性,要么继承了CNN的局限性,即由于有限的感受野和不适应性而无法区分错误的匹配。在本文中,我们引入了带有变形器的成本聚合(CATs)来解决这个问题,在一些架构设计的帮助下,探索初始相关图之间的全局共识,使我们能够充分享受自我注意机制的全局接收域。同时,为了缓解CATs可能面临的一些限制,即使用标准变换器引起的高计算成本,其复杂性随着空间和特征维度的大小而增长,这限制了它只适用于有限的分辨率,并导致相当有限的性能,我们提出CATs++,一个CATs的扩展。我们提出的方法在很大程度上超过了以前最先进的方法,为所有的基准设定了新的先进性,包括PF-WILLOW、PF-PASCAL和SPair-71k。我们进一步提供了广泛的消融研究和分析。
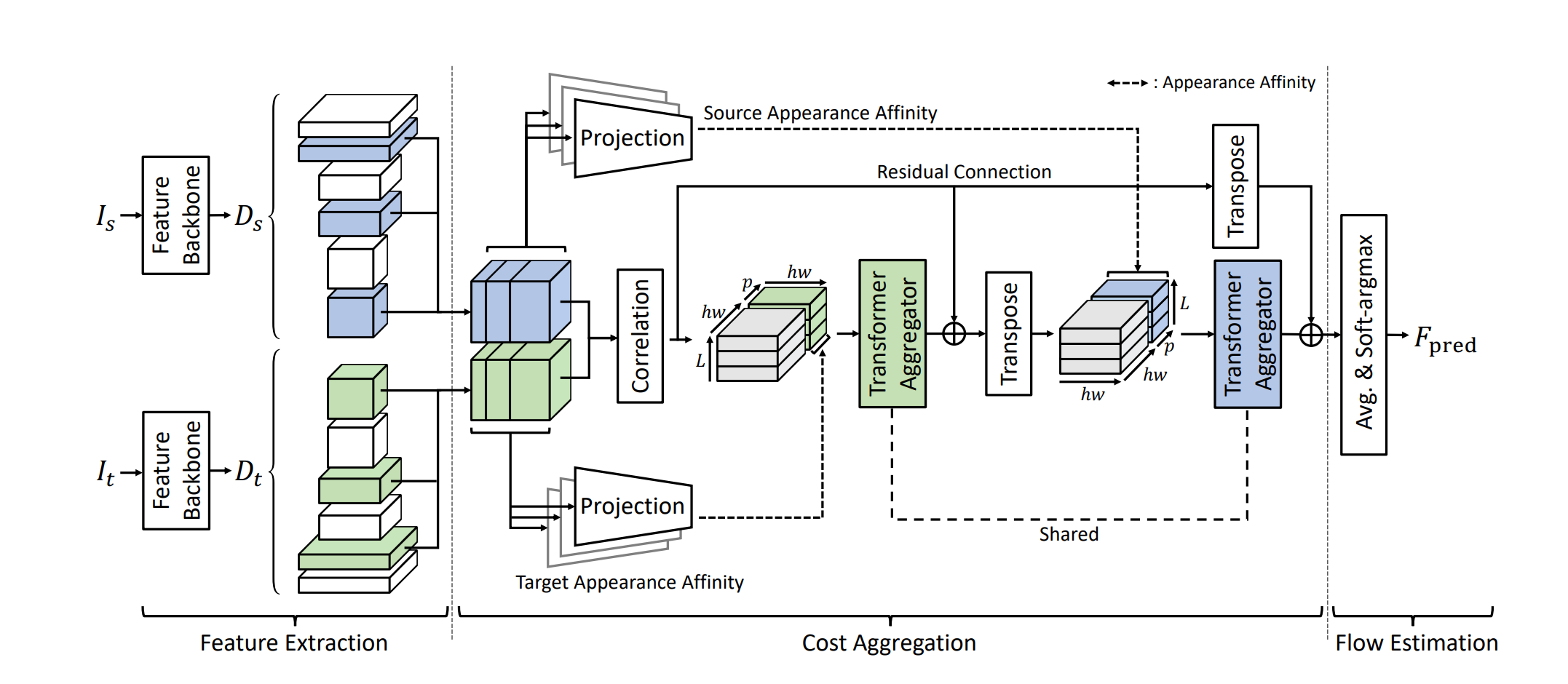
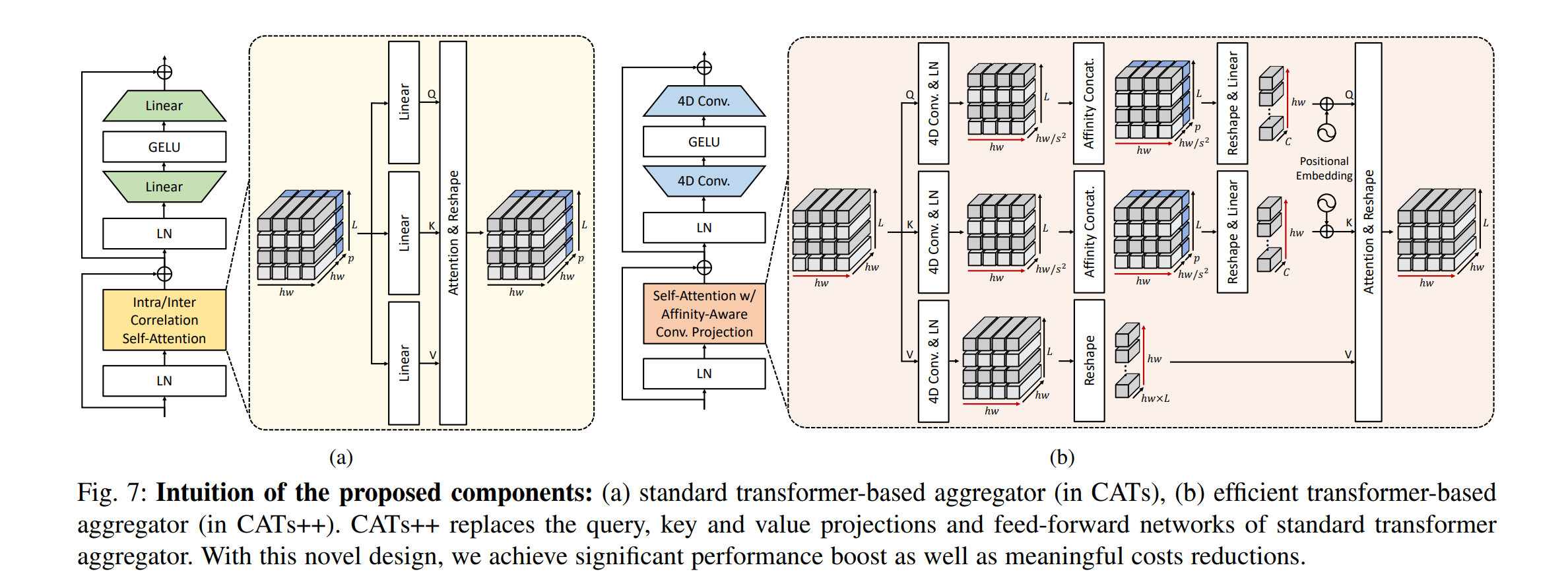
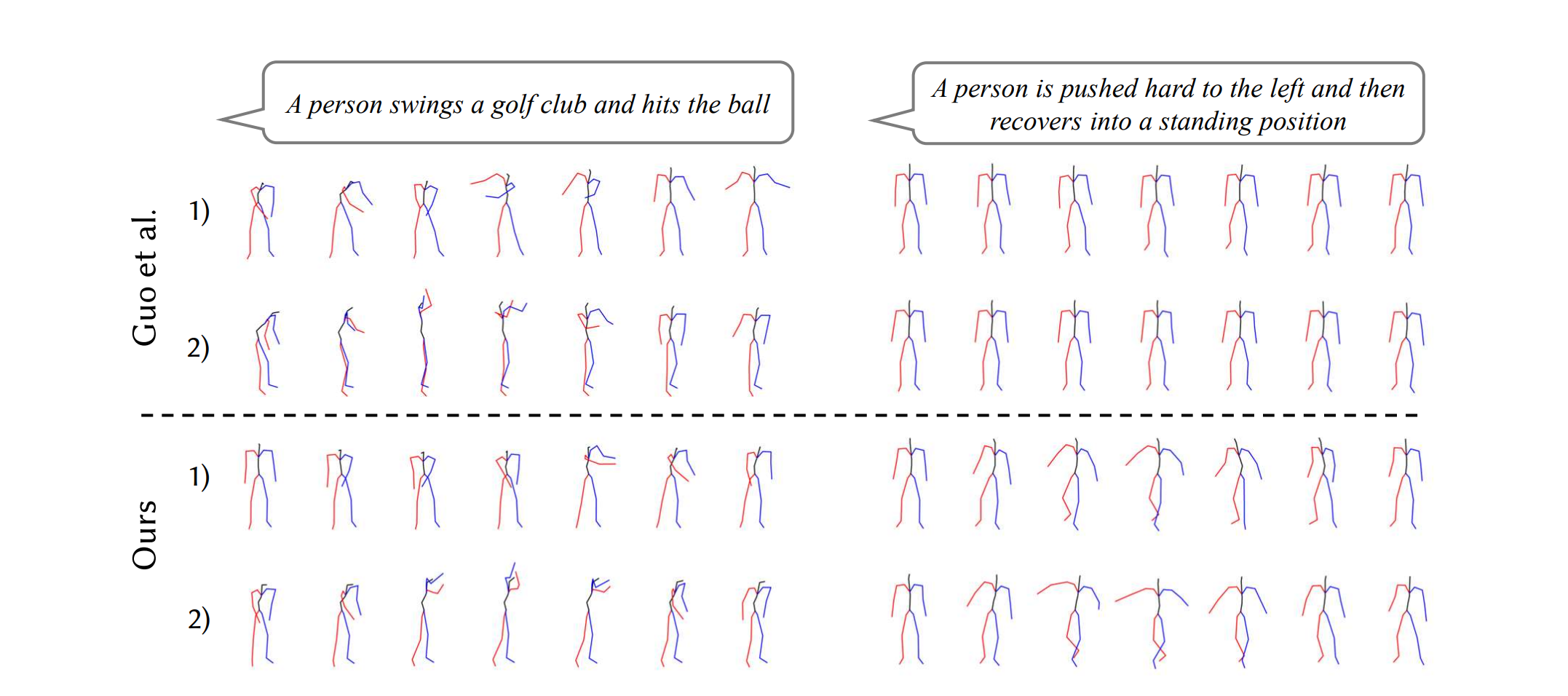
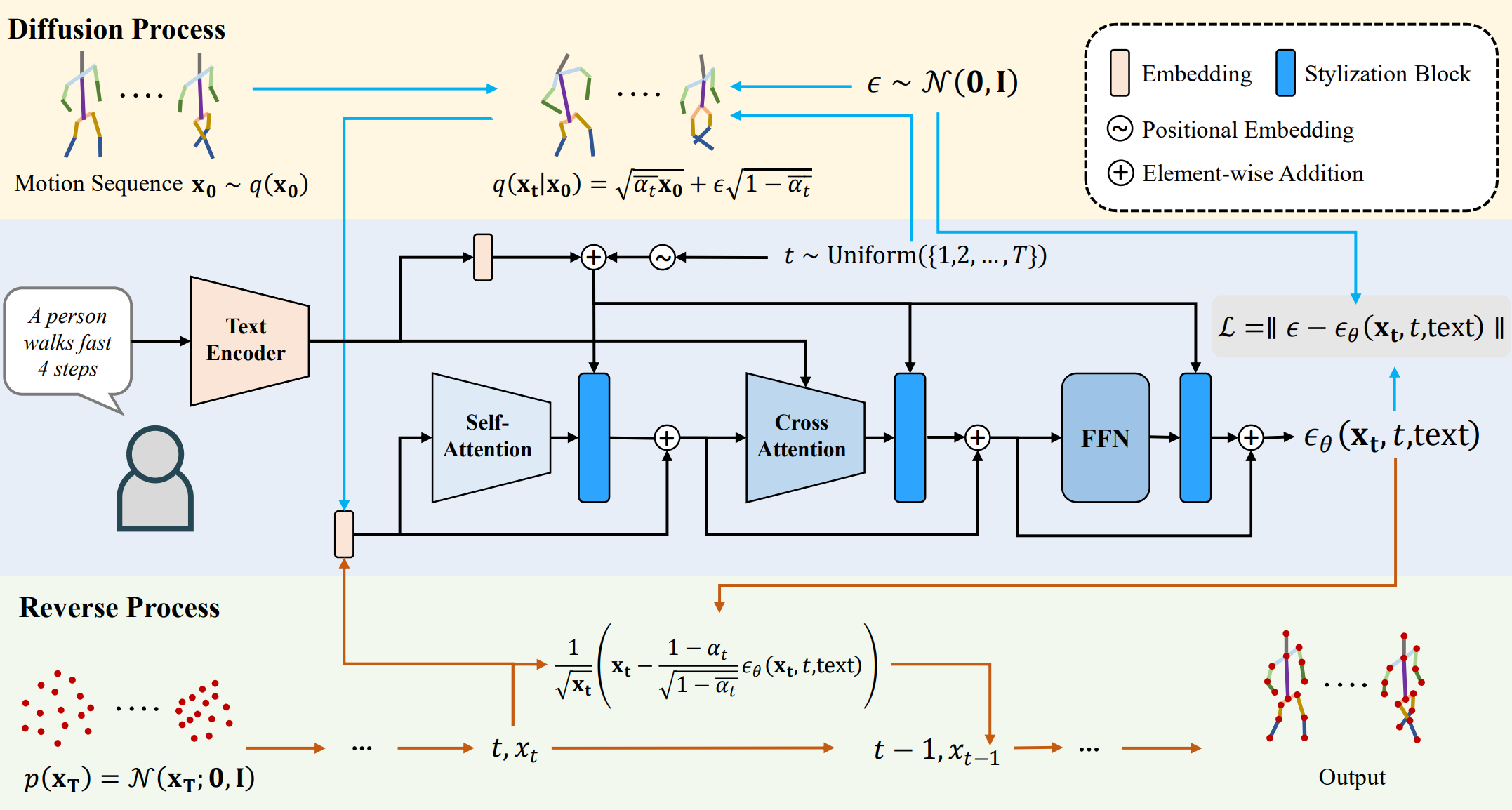
⚡ 论文:MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model
论文时间:31 Aug 2022
领域任务:Denoising, Motion Synthesis, 去噪,运动合成
论文地址:https://arxiv.org/abs/2208.15001
代码实现:https://github.com/mingyuan-zhang/MotionDiffuse
论文作者:Mingyuan Zhang, Zhongang Cai, Liang Pan, Fangzhou Hong, Xinying Guo, Lei Yang, Ziwei Liu
论文简介:Instead of a deterministic language-motion mapping, MotionDiffuse generates motions through a series of denoising steps in which variations are injected./MotionDiffuse通过一系列去噪步骤生成运动,而不是确定的语言–运动映射,在这些步骤中注入了变化。
论文摘要:人类运动建模对许多现代图形应用非常重要,这些应用通常需要专业技能。为了消除外行人的技能障碍,最近的运动生成方法可以直接生成以自然语言为条件的人类运动。然而,要在各种文本输入的情况下实现多样化和精细化的动作生成,仍然是一个挑战。为了解决这个问题,我们提出了MotionDiffuse,这是第一个基于扩散模型的文本驱动的动作生成框架,它比现有的方法展示了几个理想的特性。1)概率性映射。MotionDiffuse通过一系列的去噪步骤生成动作,而不是确定的语言-动作映射,在这些步骤中注入了变化。2)逼真的合成。MotionDiffuse善于对复杂的数据分布进行建模,并生成生动的运动序列。3) 多层次的操纵。MotionDiffuse对身体部位的精细指令和任意长度的运动合成做出反应,并有时间变化的文本提示。我们的实验表明,MotionDiffuse在文本驱动的运动生成和动作条件下的运动生成方面,以令人信服的优势胜过现有的SoTA方法。定性分析进一步证明了MotionDiffuse对综合运动生成的可控性。主页:https://mingyuan-zhang.github.io/projects/MotionDiffuse.html
我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!
◉ 点击 日报合辑,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。
◉ 点击 电子月刊,快速浏览月度合辑。
◉ 点击 这里 ,回复关键字 日报 免费获取AI电子月刊与论文 / 电子书等资料包。



















 865
865

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}