




 本文介绍了LightGBM,微软开发的高效GBDT模型,强调其在大数据场景下的优势,如训练速度提升、低内存消耗和准确性增强。文章详细讲解了LightGBM的优化点,如直方图算法、决策树生长策略和并行支持,以及其在类别特征处理和通信优化上的改进。
本文介绍了LightGBM,微软开发的高效GBDT模型,强调其在大数据场景下的优势,如训练速度提升、低内存消耗和准确性增强。文章详细讲解了LightGBM的优化点,如直方图算法、决策树生长策略和并行支持,以及其在类别特征处理和通信优化上的改进。

- 作者:韩信子@ShowMeAI
- 教程地址:https://www.showmeai.tech/tutorials/34
- 本文地址:https://www.showmeai.tech/article-detail/195
- 声明:版权所有,转载请联系平台与作者并注明出处
引言
之前ShowMeAI对强大的boosting模型工具XGBoost做了介绍(详见ShowMeAI文章图解机器学习 | XGBoost模型详解)。本篇我们来学习一下GBDT模型(详见ShowMeAI文章 图解机器学习 | GBDT模型详解)的另一个进化版本:LightGBM。
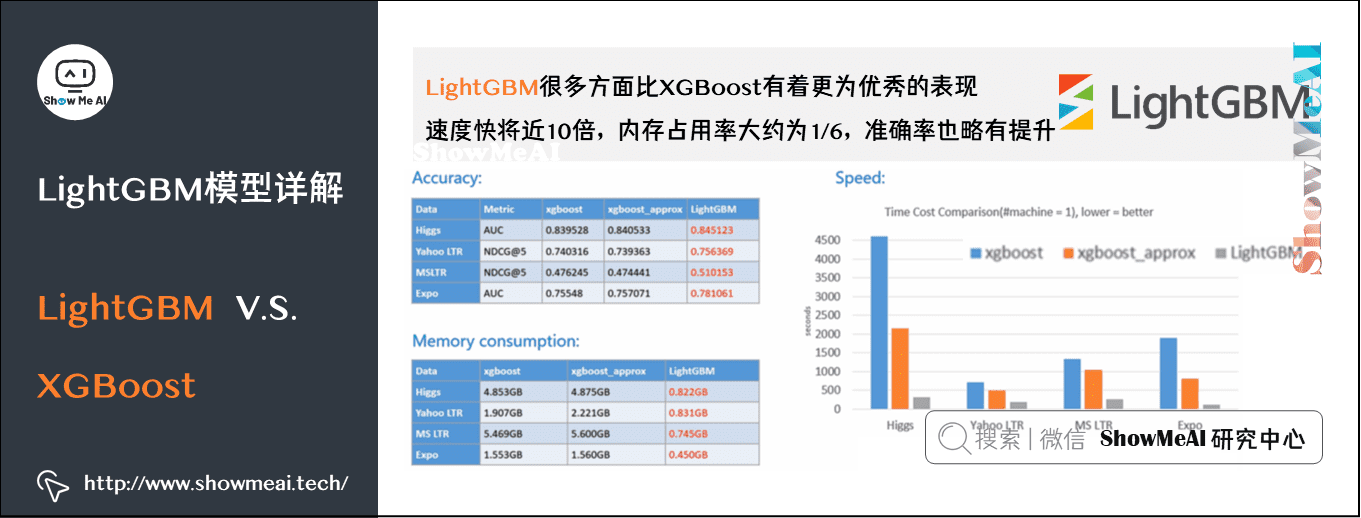
LightGBM是微软开发的boosting集成模型,和XGBoost一样是对GBDT的优化和高效实现,原理有一些相似之处,但它很多方面比XGBoost有着更为优秀的表现。官方给出的这个工具库模型的优势如下:
- 更快的训练效率
- 低内存使用
- 更高的准确率
- 支持并行化学习
- 可处理大规模数据
- 支持直接使用category特征
下图是一组实验数据,在这份实验中,LightGBM比XGBoost快将近10倍,内存占用率大约为XGBoost的1/6,准确率也略有提升。
1.LightGBM动机
互联网领域的算法应用,通常背后都有海量的大数据。深度学习中一系列神经网络算法,都是以mini-batch的方式喂数据迭代训练的,总训练数据量不受内存限制。
但我们用到的机器学习算法,比如GBDT(参考ShowMeAI文章 GBDT详解)在每一次迭代的时候,都需要遍历整个训练数据多次。
- 如果把整个训练数据一次性装进内存,会明显限制训练数据的大小。
- 如果不装进内存,反复地读写训练数据又会消耗非常大的时间。
面对工业级海量的数据,普通的GBDT算法无法满足需求。LightGBM提出的主要原因之一,就是为了解决上述大数据量级下的GBDT训练问题,以便工业实践中能支撑大数据量并保证效率。
2.XGBoost优缺点
我们之前介绍过强大的XGBoost(详见ShowMeAI文章图解机器学习 | XGBoost模型详解),但XGBoost也依旧存在一些缺点,LightGBM针对其中的一部分进行了调整优化。XGB优缺点归纳如下:
1)精确贪心算法
轮迭代时,都需要遍历整个训练数据多次。如果把整个训练数据装进内存则会限制训练数据的大小;如果不装进内存,反复地读写训练数据又会消耗非常大的时间。
G a i n = 1 2 [ G L 2 H L + λ + G R 2 H R + λ − ( G L + G R ) 2 H L + H R + λ − γ ] Gain=\frac{1}{2}\left [ \frac{G_{L}^{2}}{H_{L}+\lambda} + \frac{G_{R}^{2}}{H_{R}+\lambda} - \frac{\left(G_{L}+G_{R}\right)^{2}}{H_{L}+H_{R}+\lambda} - \gamma \right ] Gain=21[HL+λGL2+HR+λG
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1483
1483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











