




自23年4月升级为智能开发平台以来,网易CodeWave一直注重在低代码+AIGC领域的探索和积累,并始终走在业内前列。在这篇文章中,专家们分享了CodeWave+AI从企业“用得到”到“用得好”的思考与实践过程,并被InfoQ人工智能领域垂直号“AI前线”转载。
低代码 +AIGC 在很多人眼里貌似是一个很“新”的领域,怎么就深水区了?去年在同样的时间点,我们规划并上线了多种低代码 +AIGC 的能力,回顾过去,我们也发现了很多问题。
目录
一、回 顾
为了解决低代码的几大问题:低代码平台的使用门槛太高,效率太低,开发质量不高,我们在 2023 年结合 网易CodeWave 相继完成了多种 AI 能力的研发,并成功商业交付了多个项目,如:
(一)自然语言生成逻辑
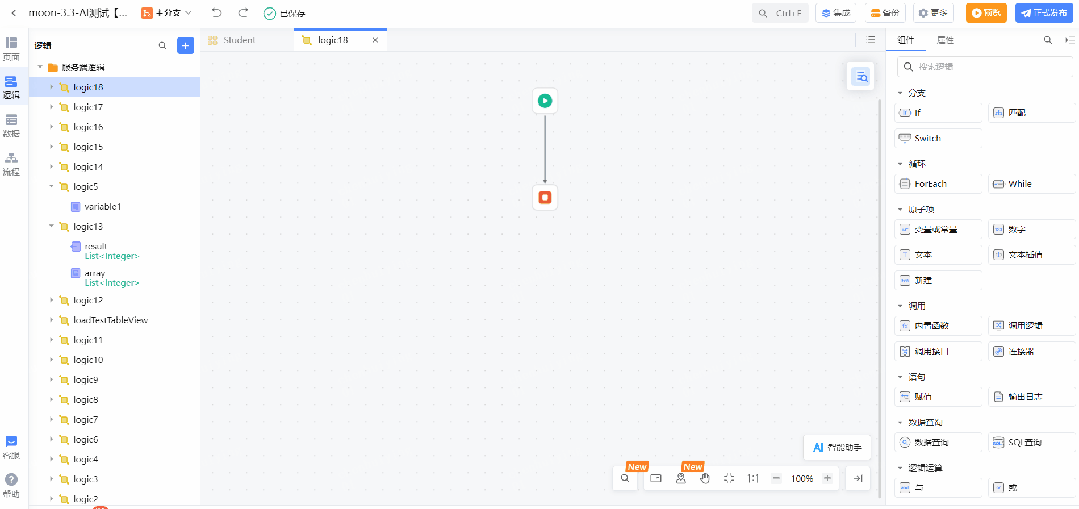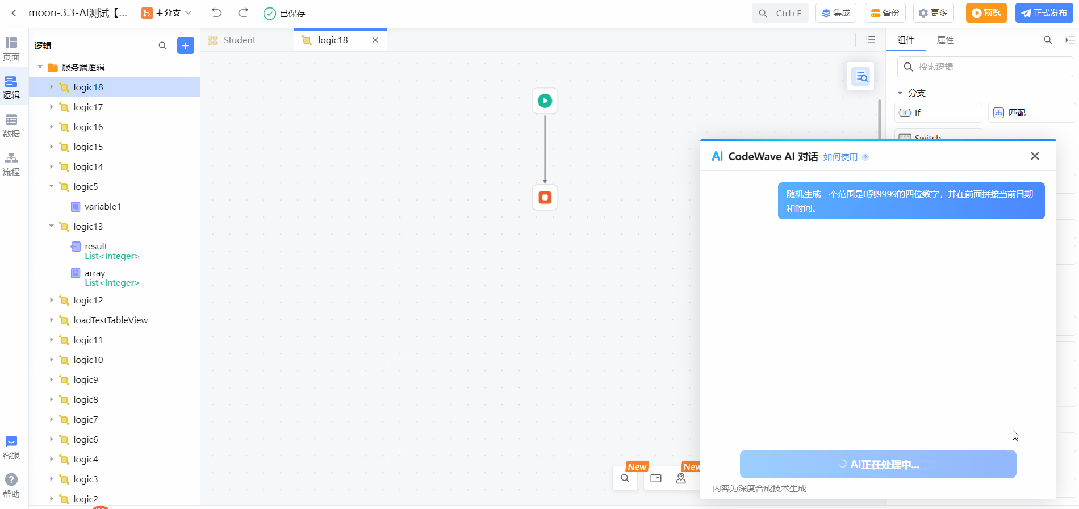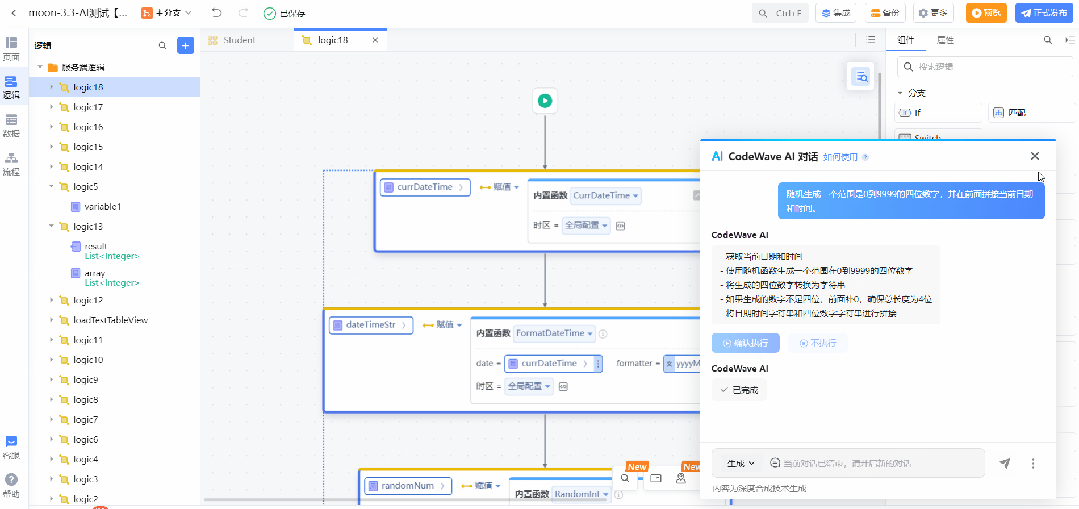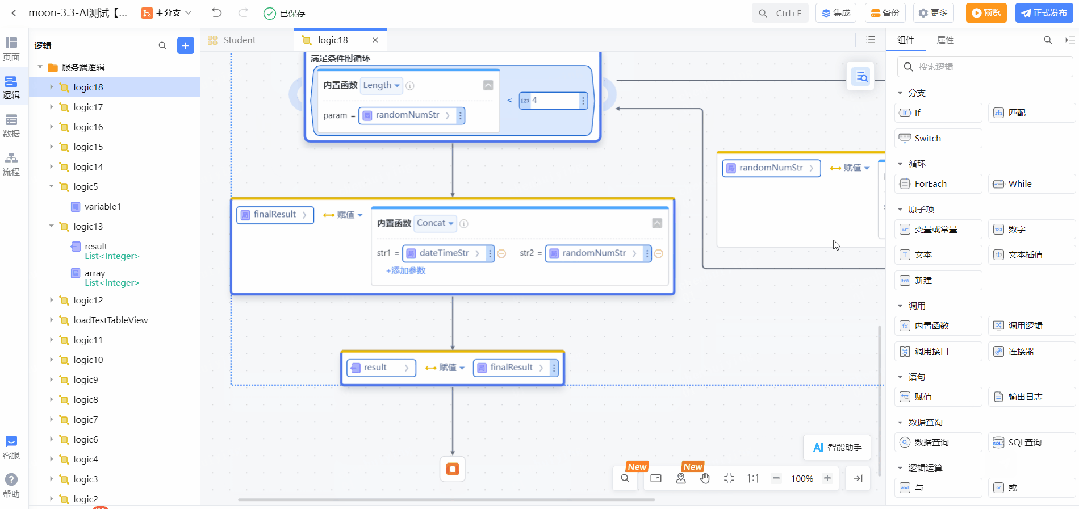
设计稿转低代码
(二)代码推荐
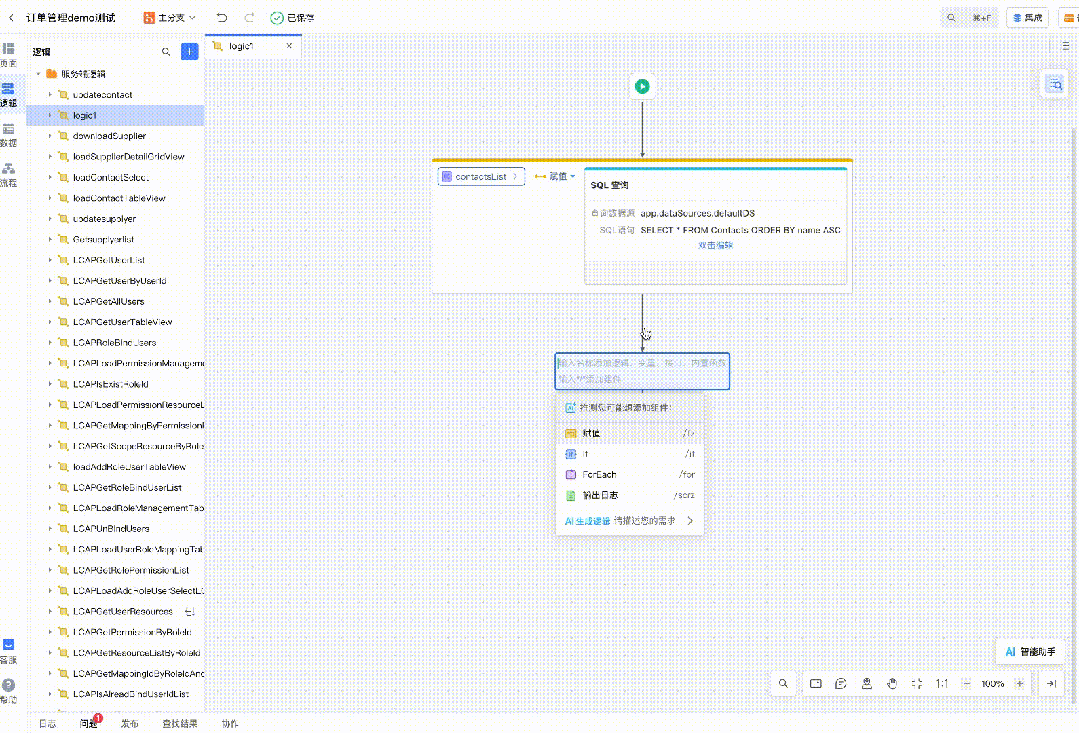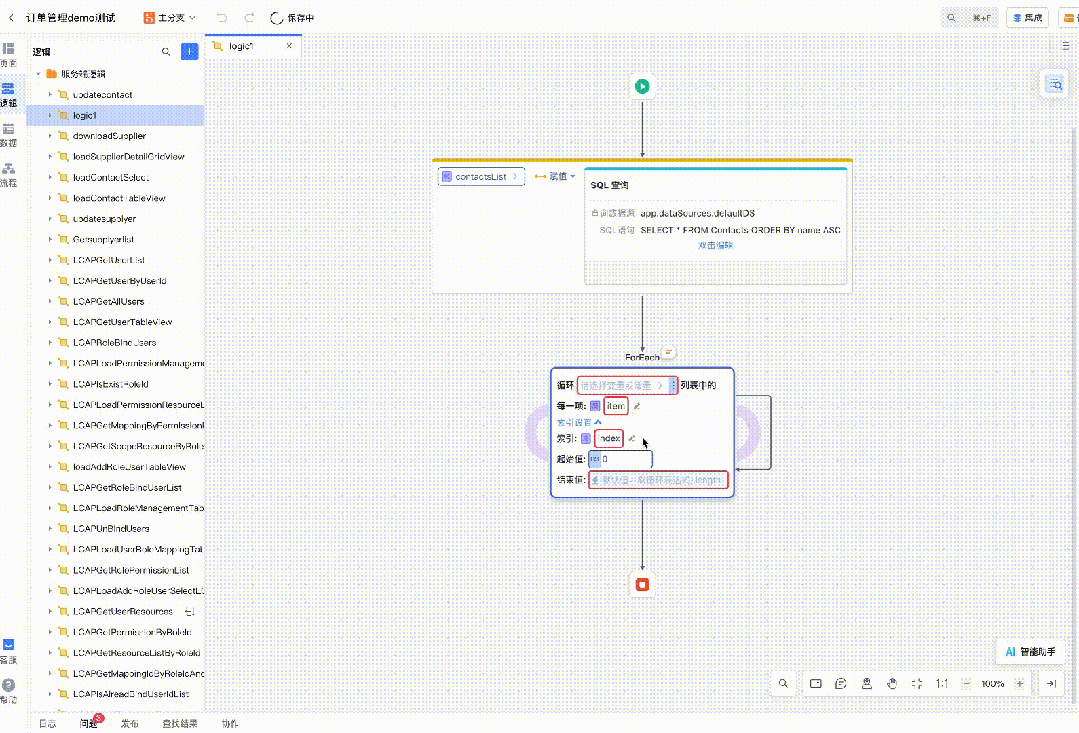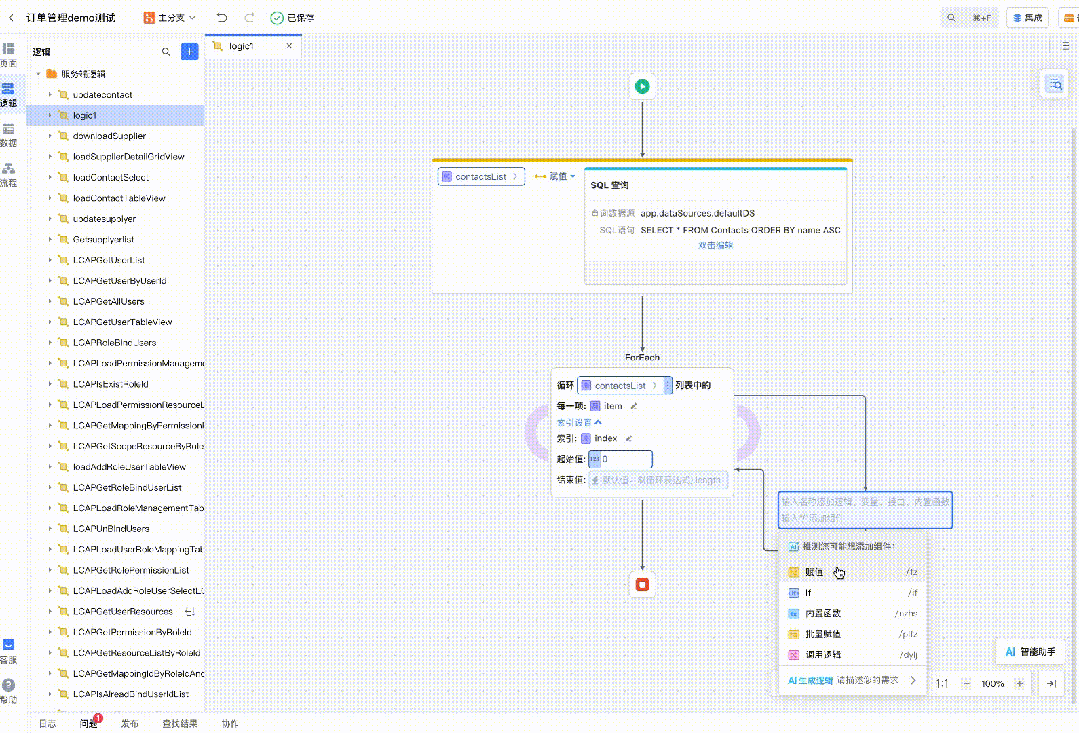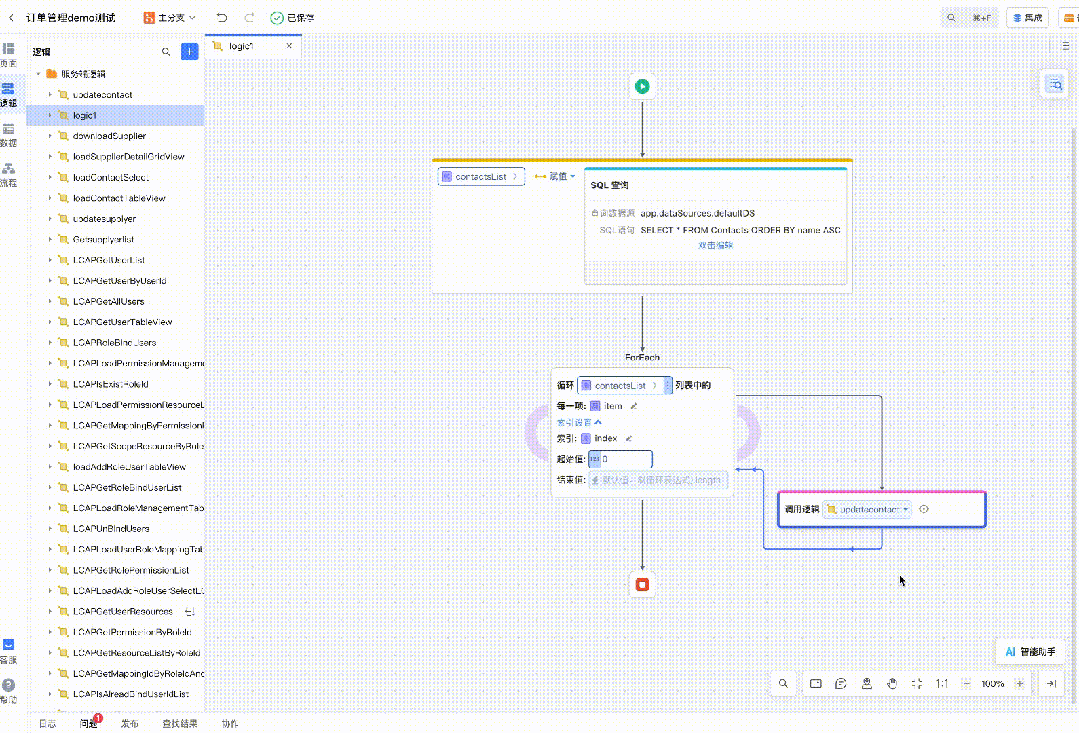
以及图片转低代码、代码解读等等。

今年4月,获InfoQ 【AIGC 最佳技术服务商 TOP10】
对这些技术感兴趣的可以看《如何做一个 GPT 干不掉的低代码产品》。这些 AI 功能为我们带来了巨大的声誉,多次在国内高级别技术会议露脸,并荣获了不少大小奖,以至于团队内(包括我)一直沾沾自喜,完全没有意识到,作为一款商业产品,当时的部分产品能力是达不到商业交付标准的。客户认为产品看起来很酷,但实际产品体验过程中,发现对于它在真实业务使用中能达到什么效果,难以有很好的预期。
同时我们也发现,市面上多款低代码产品,在今年上半年做出了几乎不逊色于我们的产品体验,所以我们陷入更深的思考:我们的壁垒到底在哪?
二、问 题
-
在多个场景下,低代码 +AIGC 效果差。线上数据表明,目前整体的采纳率只有 40% 左右,虽然已经大幅度高于 AI copilot 类产品(业内一般在 20%-25% 左右),但离我们标榜的“ NASL 大模型”数据还差的很远
-
对低代码的准确度、功能预期难以估量,导致交付困难。很多项目我们自己都会问用户,你们低代码 AI 怎么样才能给我们验收?
-
低代码的 AI 提效难以度量。每当用户问,低代码 + AI 到底提升了我们多少效率?我们难以应答。
-
低代码跟 AI 能力割裂。我们发现在产品中,AI 生成的内容难以在低代码中调试修改,同时并没有跟用户当前的操作上下文相关,感觉像是“为了 AI 而 AI”。
三、目 标
-
重新思考自然语言编程的产品技术能力,发现准确率上不去的原因,保证核心场景的准确率,从而提升使用效果,提升低代码编程的体验。
-
保证 AI 能力可度量,可量化。
-
在产品上,保证 AI 生成物的可干预和可调试,避免 AI 生成的部分难以维护。
-
从概念性 AI 功能,转变为具体的产品提效点,融入到开发过程中,设计更好的 AI 跟编辑器的结合体验。
下面我会从整体的 AI 效果评测,以及细分的自然语言编程和设计稿转页面方向去谈谈,如何更加深入的打磨我们的 AI 产品。
四、数据驱动的 AI 工程闭环
(一)数据驱动
我们都知道 AI 产品需要构建起自己的数据飞轮,才可以在快速构建产品的核心壁垒。CodeWave 通过以下方式构建 CodeWave AI 能力的数据飞轮。
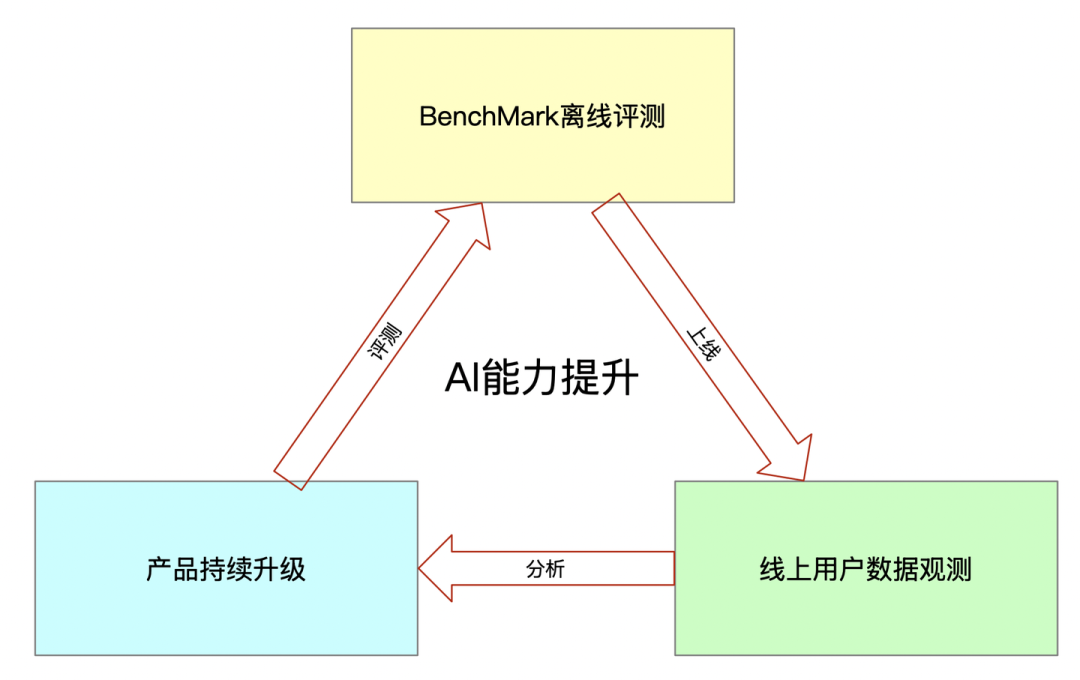
在其中,最重要的点是对 AI 能力的评测。If you can not measure it, you cannot improve it. 这是我工作初期,我老板经常挂在口头的一句话。即使对那如何度量我们的 AI 能力呢,我们从两个角度去展开分析
-
评测 AI 的基础能力
-
评测 AI 的服务指标
(二)通过 BenchMark 来评测 AI 基础能力
那我们如何“度量”我们的 AI 能力呢,答案就是通过 BenchMark 的测评来完成。我们通过两套 BenchMark 来评测 AI 的能力:
-
评测 AI 通用能力的通用 BenchMark
为了评估 AI 的基础能力,我们会构建通用 BenchMark 来进行 AI 能力的评估,以便于了解 CodeWave AI 能够做到的下限和上限。
通用 BenchMark 主要是指一些通用的 AI 编程能力的评测,与实际客户场景无关的评测。
这类 BenchMark 我们会采用包括 HumanEval 在内的多个编程领域经典数据集,也会通过大模型合成类似的大量通用 AI 能力指令数据,基于此来评价目前 AI 的基础能力。
在自然语言编程场景里,基于 HumanEval 评测集,CodeWave AI 能力做到了 GPT4o 的 80% 以上水平。
-
评测 AI 在业务场景表现的领域 BenchMark
在通用能力评测的基础上,我们同时会构建预备业务属性的领域 BenchMark,来评测用户在使用场景里真实使用 AI 的体验。
为了保证评测的相对科学,我们会通过人工构造和筛选的方式来构建领域 BenchMark 用例,以确保用例在各个主要场景中有比较合理的覆盖度。
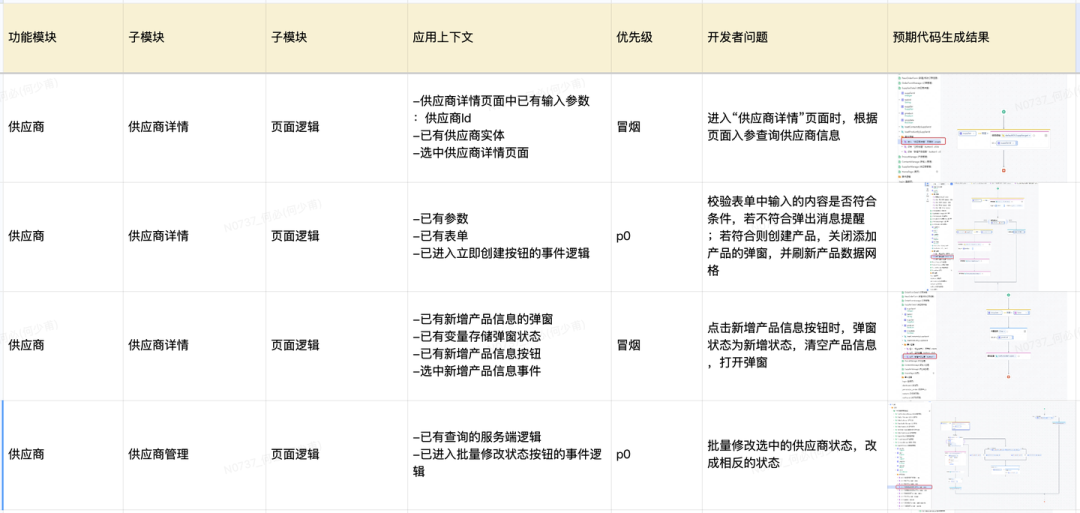
CodeWave AI 在逻辑生成领域评测集下的评测结果,页面逻辑的正确率达到 80%,而服务端逻辑的完全正确率达到 90%。
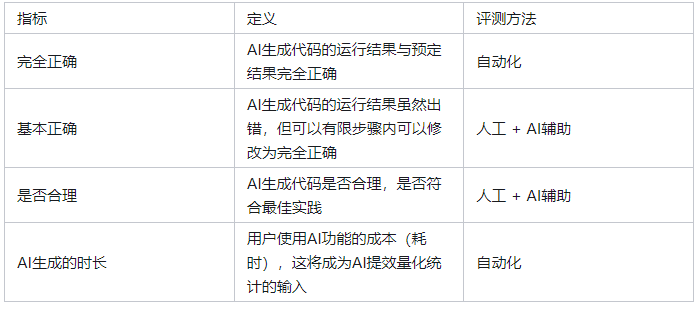
评测的指标也不仅仅只是评测是否正确,还会就合理性,和生成时长进行综合评测,以下为评测的指标示意:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4467
4467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









