




 本文详细介绍了使用Python的webdriver组件爬取东方财富网数据的步骤,包括安装webdriver、匹配Chrome驱动、定位网页元素、编写爬虫代码及执行后的数据清洗。实例展示了如何从股吧抓取用户评论。
本文详细介绍了使用Python的webdriver组件爬取东方财富网数据的步骤,包括安装webdriver、匹配Chrome驱动、定位网页元素、编写爬虫代码及执行后的数据清洗。实例展示了如何从股吧抓取用户评论。
本文重要通过Python的webdriver组件来实现爬虫网络数据。
步骤一:安装webdriver组件,具体方法可以参考相关文章
PS:webdriver需要与当前使用Chrome版本向匹配
步骤二:下载Chrome的驱动chromedriver,具体方法可以参考相关文章
PS:chromedriver需要与当前使用Chrome版本向匹配
步骤三:打开需要爬虫的网络,本文使用东方财富网为例
测试网址:中银基金股吧
http://guba.eastmoney.com/list,zg80048752,f_1.html
步骤四:定位需要获取的元素
打开浏览器的开发者模式工具,然后定位到需要爬的数据行,如下图:
爬取数据均在div中
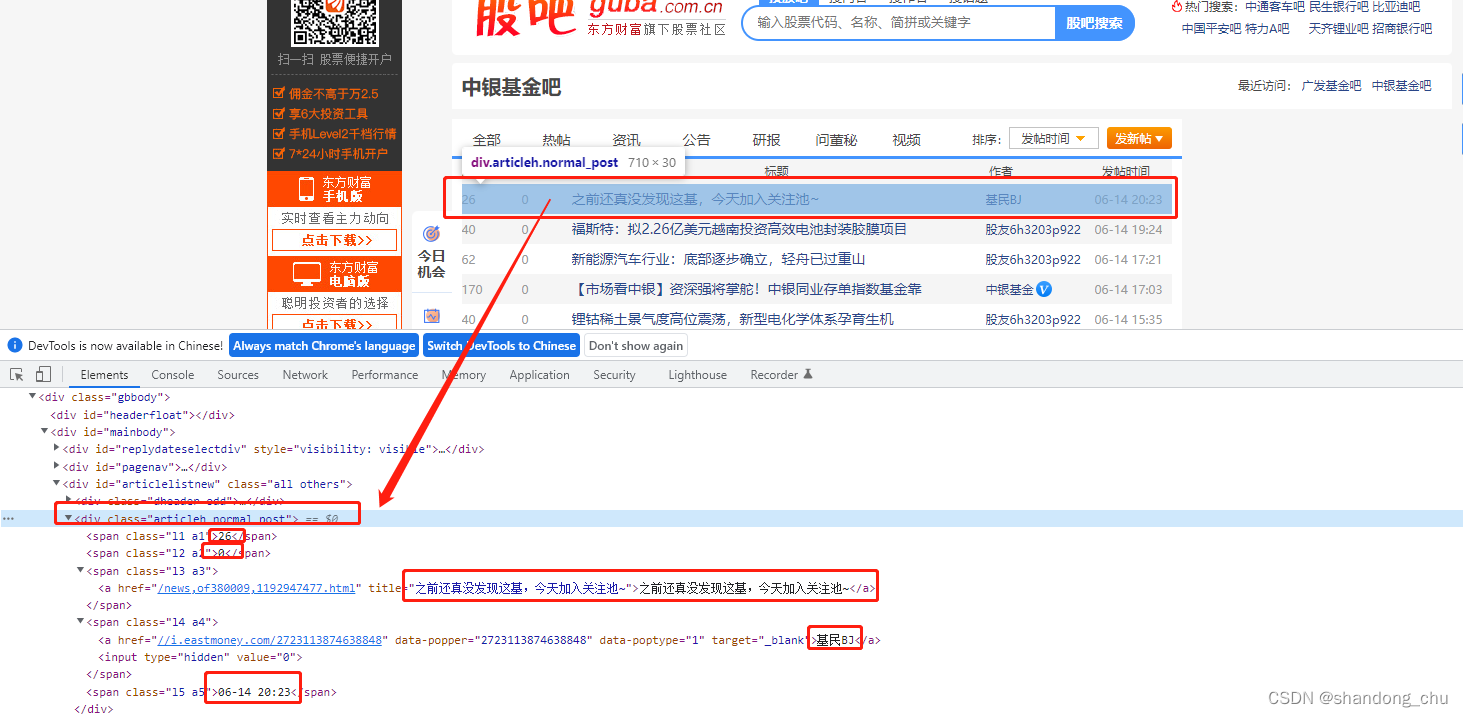
步骤五:编写爬取代码
import copy
import time
from openpyxl import Workbook
from lxml import etree
from selenium import webdriver
def main(url,filename):
# url = r'http://guba.eastmoney.com/list,zg80048752,f_1.html'
wb = Workbook() #定义Excel对象
sheet = wb.active #定义一个sheet页
sheet.append(['阅读','评论','标题','作者','发帖时间']) #定义sheet页的第一行
#以下为加载Chrome的驱动
dirver = webdriver.Chrome(executable_path=r' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









